本文主要是介绍分享MSSQL、MySql、Oracle的大数据批量导入方法及编程手法细节,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1:MSSQL
SQL语法篇:
|
|
SQL示例:
| 1 2 3 4 5 6 |
|
由于C#提供了SqlBulkCopy,所以非DBA的我们,更多会通过程序来调用:
C#代码篇:
C#代码调用示例及细节,以下代码摘录自CYQ.Data:
![]()
using (SqlBulkCopy sbc = new SqlBulkCopy(con, (keepID ? SqlBulkCopyOptions.KeepIdentity : SqlBulkCopyOptions.Default) | SqlBulkCopyOptions.FireTriggers, sqlTran)){sbc.BatchSize = 100000;sbc.DestinationTableName = SqlFormat.Keyword(mdt.TableName, DalType.MsSql);sbc.BulkCopyTimeout = AppConfig.DB.CommandTimeout;foreach (MCellStruct column in mdt.Columns){sbc.ColumnMappings.Add(column.ColumnName, column.ColumnName);}sbc.WriteToServer(mdt);}
![]()
有5个细节:
1:事务:
如果只是单个事务,构造函数可以是链接字符串。
如果需要和外部合成一个事务(比如先删除,再插入,这在同一个事务中)
就需要自己构造Connection对象和Transaction,在上下文中传递来处理。
2:插入是否引发触发器
通过SqlBulkCopyOptions.FireTriggers 引入
3:其它:批量数、超时时间、是否写入主键ID。
可能引发的数据库Down机的情况:
在历史的过程中,我遇到过的一个大坑是:
当数据的长度过长,数据的字段过短,产生数据二进制截断时,数据库服务竟然停掉了(也许是特例,也许不是)。
所以小心使用,尽力做好对外部数据做好数据长度验证。
2:MySql
关于MySql的批量,这是一段悲催的往事,有几个坑,直到今天,才发现并解决了。
SQL语法篇:
|
|
示例篇:
| 1 2 |
|
虽然MySql.Data.dll 提供了MySqlBulkLoader,但是看源码只是生成了个Load Data 并用ADO.NET执行,
核心大坑的生成*.csv数据文件的竟然没提供,所以自己生成语句并执行就好了,不需要用它。
C#代码篇:
以下代码摘自CYQ.Data,是一段今天才修正好的代码:
![]()
private static string MDataTableToFile(MDataTable dt, bool keepID, DalType dalType){string path = Path.GetTempPath() + dt.TableName + ".csv";using (StreamWriter sw = new StreamWriter(path, false, new UTF8Encoding(false))){MCellStruct ms;string value;foreach (MDataRow row in dt.Rows){for (int i = 0; i < dt.Columns.Count; i++){#region 设置值ms = dt.Columns[i];if (!keepID && ms.IsAutoIncrement){continue;}else if (dalType == DalType.MySql && row[i].IsNull){sw.Write("\\N");//Mysql用\N表示null值。}else{value = row[i].ToString();if (ms.SqlType == SqlDbType.Bit){int v = (value.ToLower() == "true" || value == "1") ? 1 : 0;if (dalType == DalType.MySql){byte[] b = new byte[1];b[0] = (byte)v;value = System.Text.Encoding.UTF8.GetString(b);//mysql必须用字节存档。}else{value = v.ToString();}}else{value = value.Replace("\\", "\\\\");//处理转义符号}sw.Write(value);}if (i != dt.Columns.Count - 1)//不是最后一个就输出{sw.Write(AppConst.SplitChar);}#endregion}sw.WriteLine();}}if (Path.DirectorySeparatorChar == '\\'){path = path.Replace(@"\", @"\\");}return path;}
![]()
以上代码是产生一个csv文件,用于被调用,有两个核心的坑,费了我不少时间:
1:Bit类型数据导不进去?
2:第1行数据自增ID被重置为1?
这两个问题,网上搜不到答案,放纵到今天,觉的应该解决了,然后就把它解决了。
解决的思路是这样的:
A:先用Load Data OutFile导出一个文件,再用Load Data InFile导入文件。
一开始我用记事本打开看了一下,又顺手Ctrl+S了一下,结果发现问题和我的一样,让我怀疑竟然
直到今天,重新导出,中间不看了,直接导入,发现它竟然又正常的,于是,思维一转:
B:把自己生成的文件和命令产生的文件,进行了十六进制比对,结果发现:
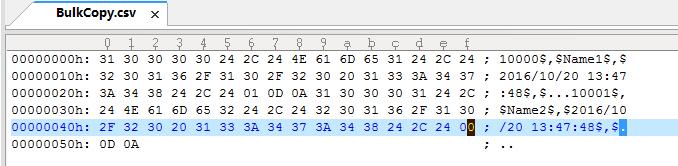
Bit类型自己生成的的数据:是0,1,在十六进制下显示是30、31。
命令产生的数据在十六进制是00、01,查了下资料,发现MySql的Bit存档的Bit是二进制。
于是,把0,1用字节表示,再转字符串,再存档,就好了。
于是这么一段代码产生了(网上的DataTable转CSV代码都是没处理的,都不知道他们是怎么跑的,难道都没有定义Bit类型?):
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
另外关于Null值,用\N表示。
解决完第一个问题,剩下就是第二个问题了,为什么第一个行代码的主键会被置为1?
还是比对十六进制,结果惊人的发现:
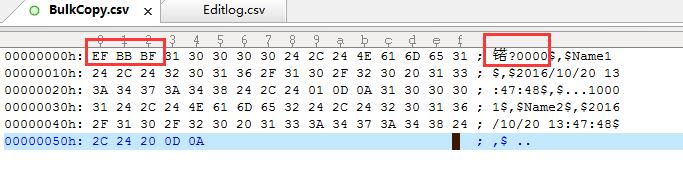
是BOM头,让它错识别了第一个主键值,所以被忽略主键,用了第1个自增值1替代了。
这也解释了为什么只要重新保存的数据都有Bug的原因。
于是,解决的方法就是StreaWrite的时候,不生成BOM头,怎么处理呢?
于是就有了以下的代码:
| 1 2 3 4 |
|
通过New一个Encoding,并指定参数为false,替代我们常规的System.Text.Encoding.UTF8Encoding。
这些细节很隐秘,不说你都猜不道。。。
3:Oracle
SQL语法篇
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
以上配置存档成一个CTL文件,再由以下的命令调用:
| 1 |
|
C#语法篇:
.NET里大概有三种操作Oracle的手法:
1:System.Data.OracleClient (需要安装客户端)没有带批量方法(还区分x86和x64)。
2:Oracle.DataAccess (需要安装客户端)带批量方法(也区分x86和x64)。
3:Oracle.ManagedDataAccess (不需要安装客户端)没带批量方法(不区分x86和x64,但仅支持.NET 4.0或以上)
Oracle.DataAccess 带的批量方法叫:OracleBulkCopy,由于使用方式和SqlBulkCopy几乎一致,就不介绍了。

如果调用程序所在的服务器安装了Oracle客户端,可以进行以下方法的调用:
流程如下:
1:产生*.cvs数据文件,见MySql中的代码,一样用的。
2:产生*.ctl控制文件,把生成的Load Data 语句存档成一个*.ctl文件即可。
3:用sqlidr.exe执行CTL文件,这里悲催的一点是,不能用ADO.NET调用,只能用进程调用,所以,这个批量只能单独使用。
调用进程的相关代码:
![]()
bool hasSqlLoader = false;private bool HasSqlLoader() //检测是否安装了客户端。{hasSqlLoader = false;Process proc = new Process();proc.StartInfo.FileName = "sqlldr";proc.StartInfo.CreateNoWindow = true;proc.StartInfo.UseShellExecute = false;proc.StartInfo.RedirectStandardOutput = true;proc.OutputDataReceived += new DataReceivedEventHandler(proc_OutputDataReceived);proc.Start();proc.BeginOutputReadLine();proc.WaitForExit();return hasSqlLoader;}void proc_OutputDataReceived(object sender, DataReceivedEventArgs e){if (!hasSqlLoader){hasSqlLoader = e.Data.StartsWith("SQL*Loader:");}}//已经实现,但没有事务,所以暂时先不引入。private bool ExeSqlLoader(string arg){try{Process proc = new Process();proc.StartInfo.FileName = "sqlldr";proc.StartInfo.Arguments = arg;proc.Start();proc.WaitForExit();return true;}catch{}return false;}
![]()
总结:
随着大数据的普及,数据间的批量移动必然越来频繁的被涉及,所以不管是用SQL脚本,还是自己写代码,或是用DBImport工具,都将成必备技能之一了!
鉴于此,分享一下我在这一块费过的力和填过的坑,供大伙参考!
一条sql 在MySQL中是如何执行的_一条sql语句在mysql中如何执行的-CSDN博客 https://blog.csdn.net/m0_66572126/article/details/141310260?spm=1001.2100.3001.7377&utm_medium=distribute.pc_feed_blog_category.none-task-blog-classify_tag-4-141310260-null-null.nonecase&depth_1-utm_source=distribute.pc_feed_blog_category.none-task-blog-classify_tag-4-141310260-null-null.nonecase不支持?
这篇关于分享MSSQL、MySql、Oracle的大数据批量导入方法及编程手法细节的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





