本文主要是介绍PaddleSpeech MFA:阿米娅中文音色复刻计划,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PaddleSpeech:阿米娅中文音色复刻计划
本篇项目是对iterhui大佬项目[PaddleSpeech 原神] 音色克隆之胡桃的复刻,使用的PaddleSpeech的版本较新,也针对新版本的PaddleSpeech做了许多配置之上的更新并加入了自己对语音的对齐、配置、训练其它任何语音音色的模块。
本篇项目旨在利用PaddleSpeech框架实现音色克隆技术,目标是复制并生成游戏《明日方舟》中的干员阿米娅(Amiya)的中文语音音色。
1. 配置 PaddleSpeech 开发环境
安装 PaddleSpeech 并在 PaddleSpeech/examples/other/tts_finetune/tts3 路径下配置 tools,下载预训练模型
In [ ]
# # 配置 PaddleSpeech 开发环境
!git clone https://gitee.com/paddlepaddle/PaddleSpeech.git
%cd /home/aistudio/
%cd PaddleSpeech
!pip install . --user -i https://mirror.baidu.com/pypi/simple
# # 下载 NLTK
# %cd /home/aistudio
# !wget -P data https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
# !tar zxvf data/nltk_data.tar.gzIn [ ]
# 查看paddlespeech是否正常安装,如果未安装,重新运行上一单元格。
!pip show paddlespeechIn [ ]
# 安装必要库
!pip install prettytable
!pip install soundfile
!pip install librosa
!pip install paddleaudio==1.0.1
!pip install h5py
!pip install loguru
!pip install python_speech_features
!pip install jsonlines
!pip install kaldiioIn [7]
# 删除软链接
# aistudio会报错: paddlespeech 的 repo中存在失效软链接
# 执行下面这行命令!!
!find -L /home/aistudio -type l -deleteIn [ ]
# 配置 MFA & 下载预训练模型
%cd /home/aistudio
!bash env.shIn [ ]
# 配置 MFA & 下载模型及词典
!mkdir -p tools
%cd tools
# mfa tool
!wget https://github.com/MontrealCorpusTools/Montreal-Forced-Aligner/releases/download/v1.0.1/montreal-forced-aligner_linux.tar.gz
!tar xvf montreal-forced-aligner_linux.tar.gz
!cp montreal-forced-aligner/lib/libpython3.6m.so.1.0 montreal-forced-aligner/lib/libpython3.6m.so
# pretrained mfa model(预置的对齐模型和词典)
!mkdir -p aligner
%cd aligner
!wget https://paddlespeech.bj.bcebos.com/MFA/ernie_sat/aishell3_model.zip
!unzip aishell3_model.zip
!wget https://paddlespeech.bj.bcebos.com/MFA/AISHELL-3/with_tone/simple.lexicon
%cd ../../In [ ]
# 拷贝mfa词典重构模型压缩包到指定目录
!cp /home/aistudio/data/data260888/mandarin_pinyin_g2p.zip -d /home/aistudio/tools/montreal-forced-aligner/pretrained_models/mandarin_pinyin_g2p.zip2 数据集配置
本项目数据集提供了完整的wav、labelx以及MFA对齐标注文件
如果要自行对齐,请去PaddleSpeech查阅完整资料或参考后面的示例
Finetune your own AM based on FastSpeech2 with multi-speakers dataset.
解压文件中的
音频
work/dataset/阿米娅/wav/xx.wav
和标签
work/dataset/阿米娅/wav/labels.txt
对齐的textgrid
work/dataset/阿米娅/textgrid/newdir/xx.TextGrid
本项目采用阿米娅的声音完成
2.1 解压现有阿米娅音色数据集
In [ ]
%cd /home/aistudio/
!unzip /home/aistudio/data/data260882/dataset.zip -d work/2.2 新音色数据集制作
制作MFA对齐标注文件
想要复刻自己找的语音音色提前要做的准备:
- 准备wav语音文件(建议30个文件以上,每个文件大约几秒的语音)
- 准备label.txt文件(该文件每行以“|”分割。左侧中文文字,右侧中文拼音,每个拼音后跟1、2、3、4表示音调,如下图)
- 按照以下目录格式存放指定文件:

制作过程:
- 使用label.txt文件生成各语音文件的lab文件
- 使用wav语音文件及对应lab拼音文件(将所有wav语音文件及对应lab拼音文件放在一个文件夹tmp中使用,注意不包含label.txt文件及其他任何文件)、mfa词典重构模型压缩包生成lexicon/txt字典文件(也可以使用别人上传的比较全的字典文件)
- 使用wav语音文件及对应lab拼音文件(将所有wav语音文件及对应lab拼音文件放在一个文件夹tmp中使用,注意不包含label.txt文件及其他任何文件)、lexicon/txt字典文件、mfa对齐模型压缩包生成对应textgrid文件
- 整理数据集文件目录,得到最终能直接拿来训练的数据集(下图中的txt文件为lab文件更改拓展名后得到,不确定是否能直接将lab代替txt使用,有兴趣的可以试一下)
最终能直接拿来训练的数据集目录结构:
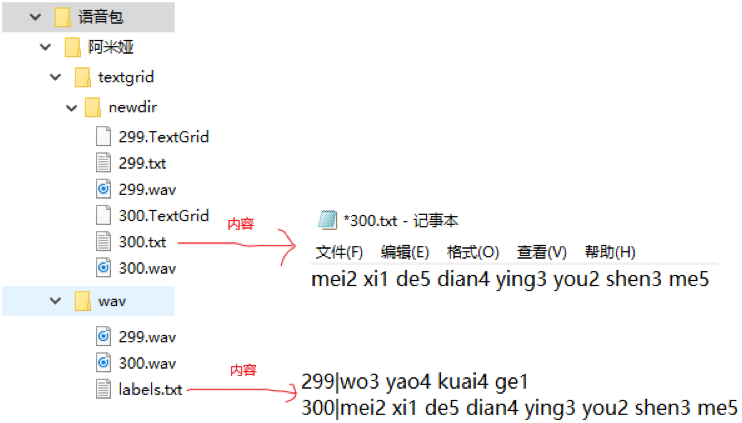
In [24]
# 生成lab文件
def txt2lab(txtPath, outPath="/home/aistudio/work/dataset/阿米娅/tmp/"):if not os.path.exists(outPath):os.makedirs(outPath)labelPath = txtPath + "labels.txt"with open(labelPath, "r") as f:lines = f.readlines()for line in lines:line = line.strip()name, pinyin = line.split("|")[0], line.split("|")[1]with open(outPath + name + ".lab", "w") as w:w.write(pinyin)os.system("cp {} {}".format(txtPath + name + ".wav", outPath + name + ".wav"))txt2lab("/home/aistudio/work/dataset/阿米娅/wav/")In [ ]
%cd /home/aistudio/tools/montreal-forced-aligner/bin/
# # 生成字典1(工具实现)
!mfa_generate_dictionary /home/aistudio/tools/montreal-forced-aligner/pretrained_models/mandarin_pinyin_g2p.zip /home/aistudio/work/dataset/阿米娅/tmp /home/aistudio/work/dataset/阿米娅/a.lexicon# # 生成词典2(手动实现)
# # 代码片段2:生成小字典# #全量字典:拼音->音素
# dictionary = r'D:\download\tmp\dictionary.txt'
# def getDictionary(dictionary = dictionary):
# """
# :param dictionary: 字典文件,每一行包含一个拼音及对应的音素,例如 "bao1 b ao1\nbeng1 b e1 ng\n"
# :return: 字典:key是拼音,value是拼音及对应的音素,例如 key=bao1,value='bao1 b ao1\n'
# """
# word2phone = {}
# with open(dictionary, 'r') as f:
# line = f.readline()
# while line:
# key,value = line.split(' ',1)
# word2phone[key] = line
# line = f.readline()
# return word2phone# #生成对齐的小字典
# def getTinyDictionaryByFile(corpusPath=r'.\data_thchs30\data',outputFile = 'tinyDictionary.txt'):
# """
# inputFilePath:.lab文件。音频文件及对应的拼音文件所在目录,拼音文件一个汉字一个拼音,拼音间空格分隔如“bian4 hua1”。
# outputFile: 当前音频文件对应的所有文字的拼音形成的小字典,如“bao1 b ao1\n”
# """
# dictionary = getDictionary()
# pattern = re.compile(r'(.*)\.lab$') #只从lab文件找所有的拼音
# tinyDict = {}
# notExistsWord = ''
# for root, dirPath, files in os.walk(corpusPath):
# for readfile in files: ##遍历inputFilePath目录下的所有文件
# if pattern.match(readfile) is not None: #找出.lab文件
# with open(root+"\\"+readfile,'r') as rf: #读取出.lab文件中的所有拼音
# line = rf.readline()
# while line:
# wordList = line.split() #读取拼音
# for word in wordList:
# if word in dictionary.keys():
# tinyDict[word] = dictionary[word]
# else:notExistsWord += word + ' ' + root+"\\"+readfile+'\n';
# line = rf.readline()
# with open(outputFile, 'w') as wf:##结果写入outputFile
# for key in tinyDict:
# wf.write(tinyDict[key])
# if notExistsWord !='': print(notExistsWord)In [ ]
# # 解决mfa tool运行时缺失文件的问题
# 查找libgfortran.so.3
!find / -name libgfortran.so.3
# 添加环境变量(临时添加)
!export LD_LIBRARY_PATH="The path you found":$LD_LIBRARY_PATH
# 如:export LD_LIBRARY_PATH=/home/user/miniconda3/envs/paddle/lib/python3.9/site-packages/paddle/libs/:$LD_LIBRARY_PATHIn [ ]
# 生成textgrid文件
!mfa_align /home/aistudio/work/dataset/阿米娅/tmp /home/aistudio/tools/aligner/simple.lexicon /home/aistudio/tools/aligner/aishell3_model.zip /home/aistudio/work/dataset/阿米娅/textgrid/newdir
%cd /home/aistudio/2.3 编写执行cmd函数代码
In [31]
import subprocess# 命令行执行函数,可以进入指定路径下执行
def run_cmd(cmd, cwd_path):p = subprocess.Popen(cmd, shell=True, cwd=cwd_path)res = p.wait()print(cmd)print("运行结果:", res)if res == 0:# 运行成功print("运行成功")return Trueelse:# 运行失败print("运行失败")return False2.4 配置各项参数
In [9]
import os# 试验路径
exp_dir = "/home/aistudio/work/exp"
# 配置试验相关路径信息
cwd_path = "/home/aistudio/PaddleSpeech/examples/other/tts_finetune/tts3"
# 可以参考 env.sh 文件,查看模型下载信息
pretrained_model_dir = "models/fastspeech2_mix_ckpt_1.2.0"# # 同时上传了 wav+标注文本 以及本地生成的 textgrid 对齐文件
# 输入数据集路径
data_dir = "/home/aistudio/work/dataset/阿米娅/wav"
# 如果上传了 MFA 对齐结果,则使用已经对齐的文件
mfa_dir = "/home/aistudio/work/dataset/阿米娅/textgrid"
new_dir = "/home/aistudio/work/dataset/阿米娅/textgrid/newdir"# 输出文件路径
wav_output_dir = os.path.join(exp_dir, "output")
os.makedirs(wav_output_dir, exist_ok=True)dump_dir = os.path.join(exp_dir, 'dump')
output_dir = os.path.join(exp_dir, 'exp')
lang = "zh"2.5 检查数据集是否合法
In [10]
# check oov
cmd = f"""python3 local/check_oov.py \--input_dir={data_dir} \--pretrained_model_dir={pretrained_model_dir} \--newdir_name={new_dir} \--lang={lang}
"""In [11]
# 执行该步骤
run_cmd(cmd, cwd_path)python3 local/check_oov.py --input_dir=/home/aistudio/work/dataset/阿米娅/wav --pretrained_model_dir=models/fastspeech2_mix_ckpt_1.2.0 --newdir_name=/home/aistudio/work/dataset/阿米娅/textgrid/newdir --lang=zh运行结果: 0 运行成功
True
2.6 生成 Duration 时长信息
In [12]
cmd = f"""
python3 local/generate_duration.py \--mfa_dir={mfa_dir}
"""In [9]
!cp -r /home/aistudio/PaddleSpeech/utils /home/aistudio/PaddleSpeech/examples/other/tts_finetune/tts3/local/In [ ]
!pip install praatio
!pip install yacsIn [14]
# 执行该步骤
run_cmd(cmd, cwd_path)python3 local/generate_duration.py --mfa_dir=/home/aistudio/work/dataset/阿米娅/textgrid运行结果: 0 运行成功
True
2.7 数据预处理
In [15]
cmd = f"""
python3 local/extract_feature.py \--duration_file="./durations.txt" \--input_dir={data_dir} \--dump_dir={dump_dir}\--pretrained_model_dir={pretrained_model_dir}
"""In [ ]
!pip install inflectIn [ ]
import sys
sys.path.append("/home/aistudio/PaddleSpeech/build/lib")
print(sys.path)In [66]
import paddlespeech
from paddlespeech.t2s.datasets.data_table import DataTableIn [17]
# 执行该步骤
run_cmd(cmd, cwd_path)33 1
100%|██████████| 33/33 [00:07<00:00, 4.27it/s]16%|█▌ | 5/32 [00:00<00:00, 49.52it/s]
All frames seems to be unvoiced, this utt will be removed. Done
100%|██████████| 32/32 [00:00<00:00, 194.00it/s] 100%|██████████| 1/1 [00:00<00:00, 2.89it/s] 100%|██████████| 1/1 [00:00<00:00, 300.04it/s]0%| | 0/1 [00:00<?, ?it/s]
Done
100%|██████████| 1/1 [00:00<00:00, 3.36it/s] 100%|██████████| 1/1 [00:00<00:00, 327.12it/s]
Donepython3 local/extract_feature.py --duration_file="./durations.txt" --input_dir=/home/aistudio/work/dataset/阿米娅/wav --dump_dir=/home/aistudio/work/exp/dump --pretrained_model_dir=models/fastspeech2_mix_ckpt_1.2.0运行结果: 0 运行成功
True
2.8 准备微调环境
In [18]
cmd = f"""
python3 local/prepare_env.py \--pretrained_model_dir={pretrained_model_dir} \--output_dir={output_dir}
"""In [19]
# 执行该步骤
run_cmd(cmd, cwd_path)
python3 local/prepare_env.py --pretrained_model_dir=models/fastspeech2_mix_ckpt_1.2.0 --output_dir=/home/aistudio/work/exp/exp运行结果: 0 运行成功
True
2.9 微调并训练
不同的数据集是不好给出统一的训练参数,因此在这一步,开发者可以根据自己训练的实际情况调整参数,重要参数说明:
训练轮次: epoch
- epoch 决定了训练的轮次,可以结合 VisualDL 服务,在 AIstudio 中查看训练数据是否已经收敛,当数据集数量增加时,预设的训练轮次(100)不一定可以达到收敛状态
- 当训练轮次过多(epoch > 200)时,建议新建终端,进入/home/aistudio/PaddleSpeech/examples/other/tts_finetune/tts3 路径下, 执行 cmd 命令,AIStudio 在打印特别多的训练信息时,会产生错误
配置文件:
/home/aistudio/PaddleSpeech/examples/other/tts_finetune/tts3/conf/finetune.yaml
In [39]
# 将默认的 yaml 拷贝一份到 exp_dir 下,方便修改
import shutil
in_label = "/home/aistudio/PaddleSpeech/examples/other/tts_finetune/tts3/conf/finetune.yaml"
shutil.copy(in_label, exp_dir)'/home/aistudio/work/exp/finetune.yaml'
In [32]
epoch = 100
config_path = os.path.join(exp_dir, "finetune.yaml")cmd = f"""
python3 local/finetune.py \--pretrained_model_dir={pretrained_model_dir} \--dump_dir={dump_dir} \--output_dir={output_dir} \--ngpu=1 \--epoch={epoch} \--finetune_config={config_path}
"""In [ ]
!pip install --user paddlepaddle-gpu==2.3.2In [ ]
# 执行该步骤
# 如果训练轮次过多,则复制上面的cmd到终端中运行
# python3 local/finetune.py --pretrained_model_dir=models/fastspeech2_mix_ckpt_1.2.0 --dump_dir=/home/aistudio/work/exp/dump --output_dir=/home/aistudio/work/exp/exp --ngpu=1 --epoch=250 --finetune_config=/home/aistudio/work/exp/finetune.yaml
run_cmd(cmd, cwd_path)3 生成音频
输入我们需要生成的文字,即可生成对应的音频文件
3.1 文本输入
In [53]
text_dict = {"0": "博士!早上好!","1":"源石被发现之后,人们发掘出一种通过它来施放一系列令物质改变原有性状的技术,这种技术被称为源石技艺,常被俗称为“法术”。源石技艺所运用的能源,一般被认为来自于源石本身。而人是否能施放法术,以及所能施放法术的形式、强度、效果等,通常受到先天具备的素质、后天对源石技艺的学习能力这两方面因素的制约。"
}In [54]
# 生成 sentence.txt
text_file = os.path.join(exp_dir, "sentence.txt")
with open(text_file, "w", encoding="utf8") as f:for k,v in sorted(text_dict.items(), key=lambda x:x[0]):f.write(f"{k} {v}\n")3.2 调训练的模型
In [55]
# 找到最新生成的模型
def find_max_ckpt(model_path):max_ckpt = 0for filename in os.listdir(model_path):if filename.endswith('.pdz'):files = filename[:-4]a1, a2, it = files.split("_")if int(it) > max_ckpt:max_ckpt = int(it)return max_ckpt3.2 生成语音
In [56]
# 配置一下参数信息
model_path = os.path.join(output_dir, "checkpoints")
ckpt = find_max_ckpt(model_path)cmd = f"""
python3 /home/aistudio/PaddleSpeech/paddlespeech/t2s/exps/fastspeech2/../synthesize_e2e.py \--am=fastspeech2_mix \--am_config=models/fastspeech2_mix_ckpt_1.2.0/default.yaml \--am_ckpt={output_dir}/checkpoints/snapshot_iter_{ckpt}.pdz \--am_stat=models/fastspeech2_mix_ckpt_1.2.0/speech_stats.npy \--voc="hifigan_aishell3" \--voc_config=models/hifigan_aishell3_ckpt_0.2.0/default.yaml \--voc_ckpt=models/hifigan_aishell3_ckpt_0.2.0/snapshot_iter_2500000.pdz \--voc_stat=models/hifigan_aishell3_ckpt_0.2.0/feats_stats.npy \--lang=mix \--text={text_file} \--output_dir={wav_output_dir} \--phones_dict={dump_dir}/phone_id_map.txt \--speaker_dict={dump_dir}/speaker_id_map.txt \--spk_id=0 \--ngpu=1
"""In [ ]
!pip install timer
!pip install opencc==1.1.6In [ ]
# 由于版本兼容问题,微调训练使用paddlepaddle-gpu==2.3.2,调模型生成语音使用paddlepaddle-gpu==2.6.0
!pip install --user paddlepaddle-gpu==2.6.0In [ ]
run_cmd(cmd, cwd_path)3.4 语音展示
In [59]
import IPython.display as ipdipd.Audio(os.path.join(wav_output_dir, "0.wav"))<IPython.lib.display.Audio object>
In [60]
ipd.Audio(os.path.join(wav_output_dir, "1.wav"))<IPython.lib.display.Audio object>
In [61]
ipd.Audio("/home/aistudio/work/dataset/阿米娅/wav/3星结束行动.wav")<IPython.lib.display.Audio object>
这篇关于PaddleSpeech MFA:阿米娅中文音色复刻计划的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





