本文主要是介绍论文阅读:Segment Any Point Cloud Sequences by Distilling Vision Foundation Models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概要
Motivation
整体架构流程
技术细节
小结
论文地址:[2306.09347] Segment Any Point Cloud Sequences by Distilling Vision Foundation Models (arxiv.org)
代码地址:GitHub - youquanl/Segment-Any-Point-Cloud: [NeurIPS'23 Spotlight] Segment Any Point Cloud Sequences by Distilling Vision Foundation Models
概要
视觉基础模型 (VFMs) 的最新进展为通用且高效的视觉感知开辟了新的可能性。在这项工作中,论文中介绍了 一个新颖的框架Seal,利用 VFM 来分割不同的汽车点云序列。Seal 表现出三个吸引人的特性:
- 可扩展性:VFMs 直接提炼成点云,消除了在预训练期间 2D 或 3D 中的注释需求;
- 一致性:空间和时间关系在相机到激光雷达和点到段阶段都强制执行,促进了跨模态表示学习;
- 通用性:Seal 能够将知识转移以现成的方式转移到涉及不同点云的下游任务,包括来自真实/合成、低/高分辨率、大/小规模和干净/损坏的数据集的任务。
在实现以下目标的同时,能够学习有用的特征:
- 利用原始点云作为输入,从而消除对半或弱标签的需要,并降低标注成本。
- 利用驾驶场景中固有的空间和时间线索来增强表示学习。
- 确保可推广到不同的下游点云,超出预训练阶段使用的点云。
从跨模态表征学习的最新进展中获得灵感,并以VFMs的成功为基础,从VFMs中提取语义丰富的知识,以支持具有挑战性的汽车点云上的自监督表示学习。该论文的核心思想是利用LiDAR和相机传感器之间的2D-3D对应,构建高质量的对比样本进行跨模态表征学习。
Motivation
- 现有的点云分割模型严重依赖于用于训练的大型带注释的数据集,即点云标记的劳动密集型性质;
- 不同传感器之间存在显著的配置差异(如波束数、摄像机角度、发射速率),这种局限性不可避免地阻碍了点云分割的可扩展性;
- LiDAR与摄像机之间往往很难实现完美的校准。
整体架构流程
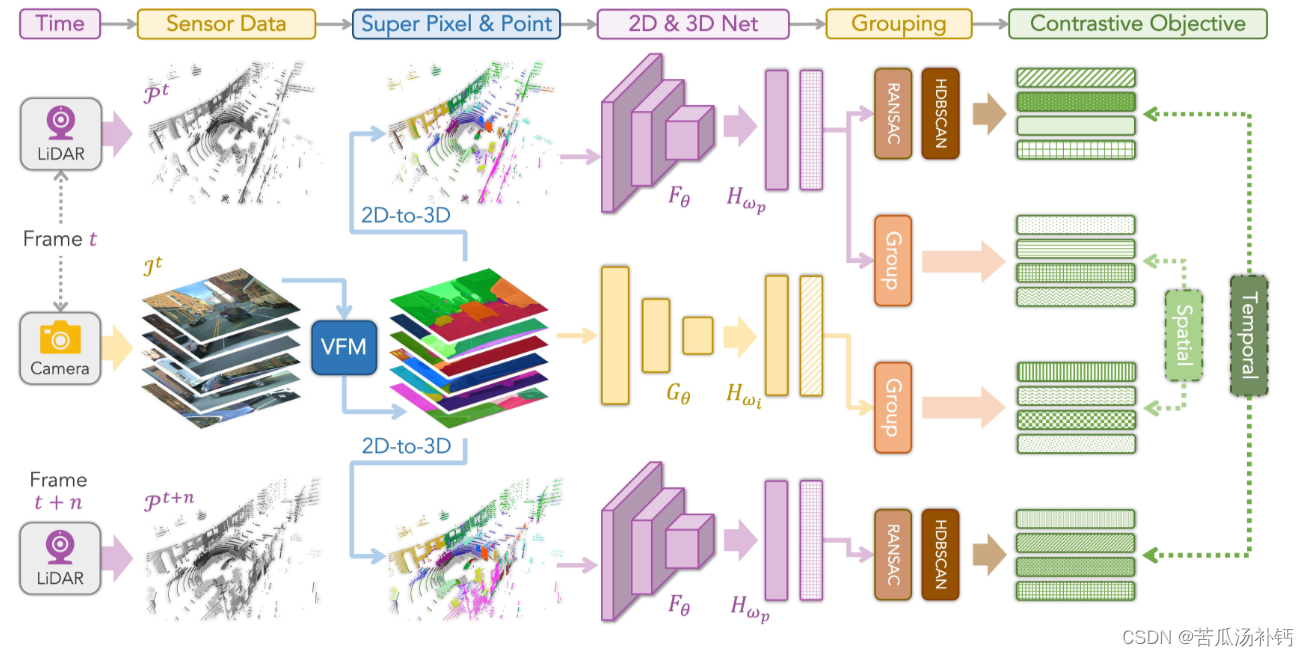
Seal通过超像素驱动的对比学习,从VFMs到点云在摄像机视图上蒸馏语义感知。[第1行]由SLIC和VFMs生成的语义超像素(Semantic superpixels),其中每个颜色代表一个“语义块”(segment)。[第2行]语义超点(Semantic superpoints)通过camera-LiDAR对应将超像素投影到3D进行聚合。[第3行]由SLIC和不同的VFMs驱动的框架的 linear probing 结果的可视化。
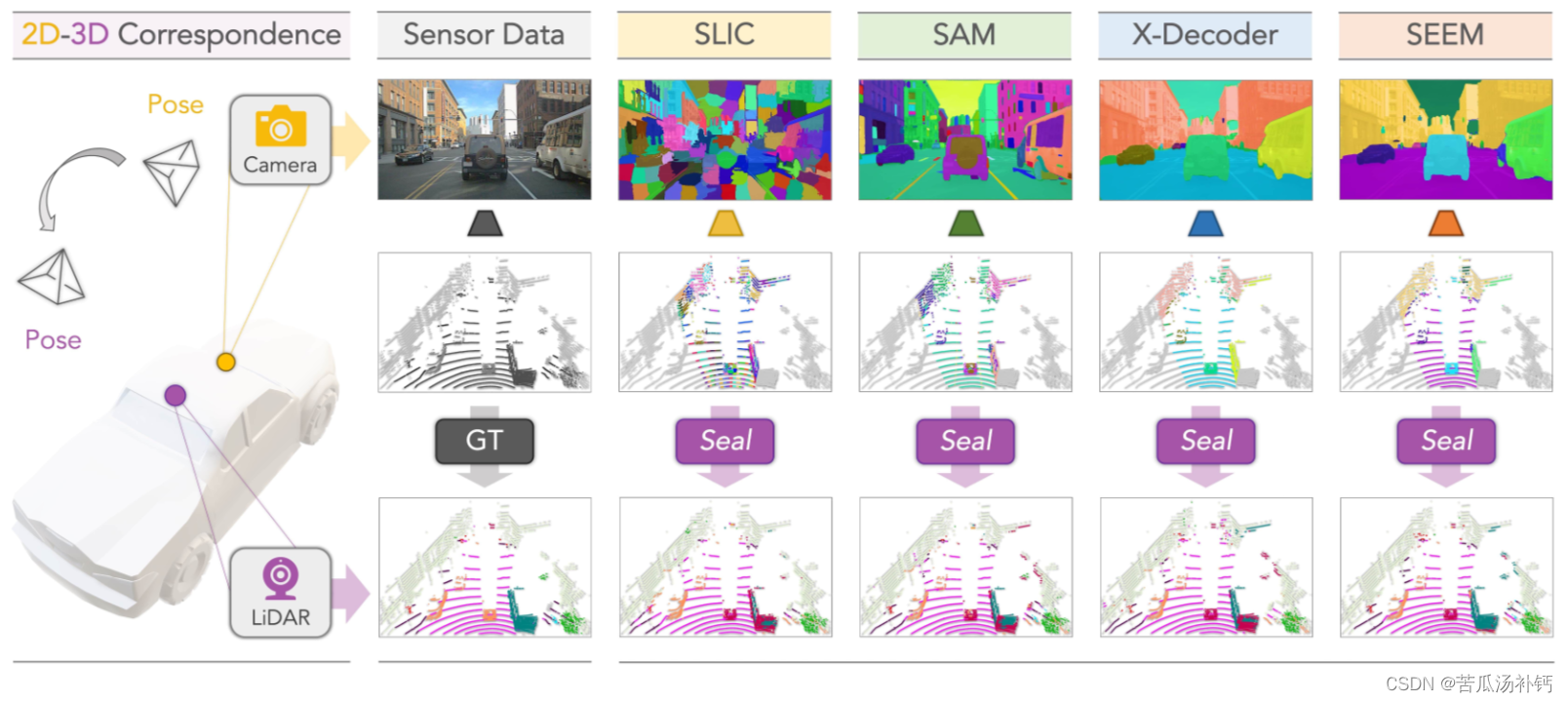
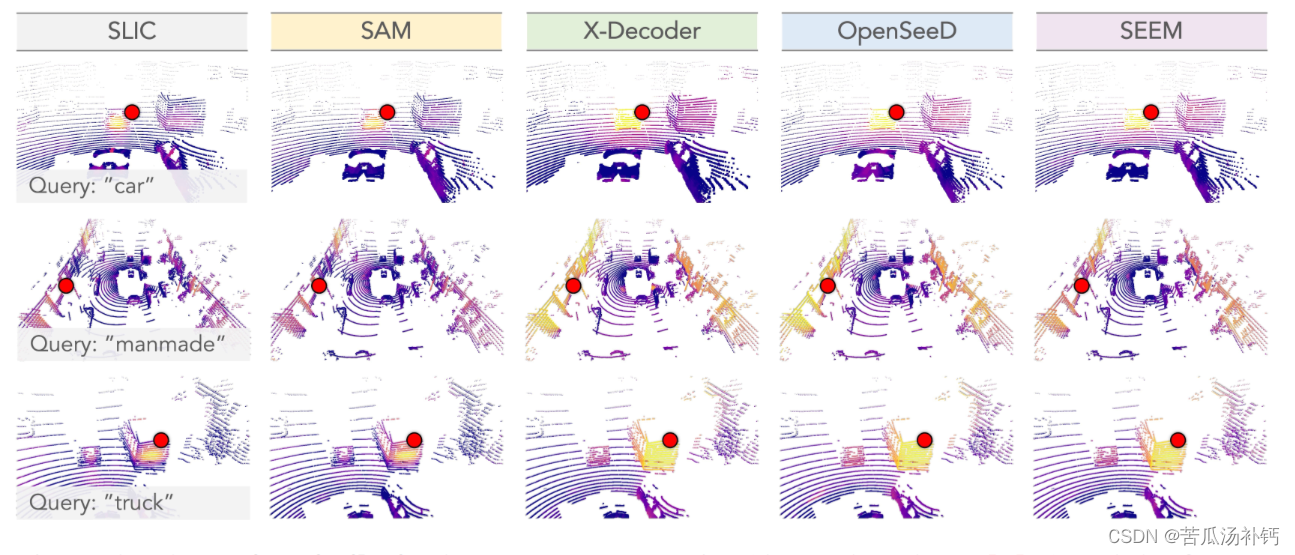
技术细节
语义超点时间一致性依赖于来自点云的精确几何信息,并利用实例跨不同时间戳的不同视图来学习时间一致的表示。考虑到最坏的情况,LiDAR和相机传感器之间的2D-3D对应变得不可靠,这种几何约束仍然可以有效地缓解在不准确的交叉传感器校准和同步中出现的潜在误差。此外,本文的point-to-segment正则化机制可以对空间信息进行聚合,从而在lidar获取的场景中起到更好的区分实例的作用,例如“car”和“truck”。正如本文将在下面的章节中展示的,本文的实验结果能够验证提出的一致性正则化目标的有效性和优越性。
使用MinkUNet作为3D骨干,以0.10m大小的圆柱体素(cylindrical voxels)作为输入。2D骨干是用MoCoV2预训练的ResNet-50。使用带动量的SGD和余弦退火scheduler,在32 batch size的两个GPUs上对分割网络进行50个epochs的预训练。为了进行微调,在nuScenes和SemanticKITTI上采用了与SLidR完全相同的数据分割、扩展和验证协议,并在其他数据集上采用了类似的过程。训练目标是最小化交叉熵损失和Lovasz-Softmax损失的组合。
小结
本文提出了Seal,是利用二维视觉基础模型在大规模3D点云上进行自监督表示学习的首次尝试。这是一个可伸缩的、一致的、可泛化的框架,旨在捕获语义感知的空间和时间一致性,从而能够从汽车点云序列中提取信息特征。
在11个不同的点云数据集上进行的大量实验证明了Seal的有效性和优越性。Seal在线性探测后在nuScenes上实现了显著的45.0% mIoU,超过了随机初始化36.9% mIoU,比现有技术高出6.1% mIoU。此外,Seal 在所有 11 个测试点云数据集上的 20 个不同的小样本微调任务中显示出比现有方法显着的性能提升。跨11个不同数据配置的点云数据集对下游任务的linear probing和微调方面明显优于以前的最先进的(SoTA)方法。
这篇关于论文阅读:Segment Any Point Cloud Sequences by Distilling Vision Foundation Models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
