distilling专题
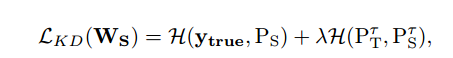
蒸馏Knowledg Distilling
文章目录 蒸馏基础知识Distilling the Knowledge in a Neural Network 2015-HintonDeep mutual learning 2017Improved Knowledge Distillation via Teacher Assistant 2019FitNets:Hints for thin deep nets 2015-ICLR蒸馏的分类
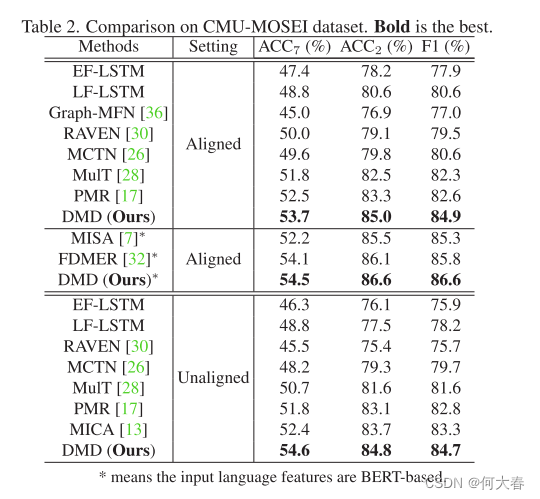
Decoupled Multimodal Distilling for Emotion Recognition 论文阅读
Decoupled Multimodal Distilling for Emotion Recognition 论文阅读 Abstract1. Introduction2. Related Works2.1. Multimodal emotion recognition2.2. Knowledge distillation3. The Proposed Method3.1. Multimod
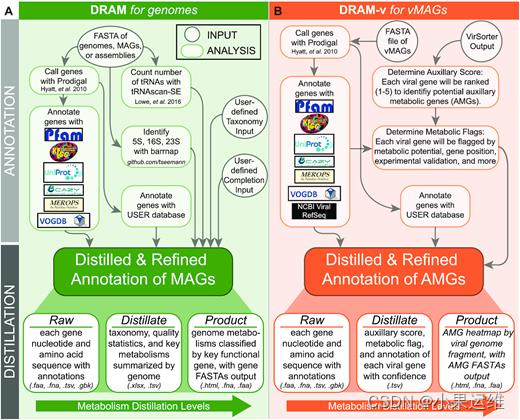
DRAM(Distilling and Refining Annotations of Metabolism,提取和精练代谢注释)工具安装和使用
先看文章介绍吧:DRAM for distilling microbial metabolism to automate the curation of microbiome function | Nucleic Acids Research | Oxford Academic (oup.com) 1、安装 默认使用conda安装吧,也建议使用conda,pip安装其实都差不多,但
《Distilling the Knowledge in a Neural Network》知识蒸馏论文解读
问题:由于网络结构的复杂,进行预测的代价过高,难以将网络部署到轻量级设备用户中。 解决方法:利用知识蒸馏进行模型压缩,实现轻量级网络。 接下来以这篇论文为基础来认识知识蒸馏。 1、软标签和硬标签 描述:硬标签就是指我们在预测时正确的值为1,错误的值为0。而软标签则认为错误的标签不可能都是零,因为对错误标签而言总有着自己的差距,如下面所示。 硬标签

Distilling the Knowledge in a Neural Network【论文解析】
Distilling the Knowledge in a Neural Network 知识蒸馏 摘要1 引言 摘要 提高几乎任何机器学习算法性能的一种非常简单的方法是在相同的数据上训练许多不同的模型,然后对它们的预测进行平均处理[3]。不幸的是,使用整个模型集合进行预测既繁琐又可能过于计算密集,特别是如果单独的模型是庞大的神经网络,这将使其无法部署到大量用户那里。Carua

Distilling the Knowledge in a Neural Network学习笔记
1.主要内容是什么: 这篇论文介绍了一种有效的知识迁移方法——蒸馏,可以将大型模型中的知识转移到小型模型中,从而提高小型模型的性能。这种方法在实际应用中具有广泛的潜力,并且可以应用于各种不同的任务和领域。 论文中首先介绍了蒸馏的基本原理。大型模型通常通过softmax输出层产生类别概率,而蒸馏则通过提高softmax的温度来产生更软化的概率分布。在蒸馏过程中,使用大型模型生成的高温软目标分

基于图像的虚拟试衣:Parser-Free Virtual Try-On via Distilling Appearance Flows(2021)
Paper Parser-Free Virtual Try-On via Distilling Appearance Flows 算法比较 WUTON和PF-AFN比较 WUTON 通过训练基于人体分析的老师网络来指导学生网络,让学生网络模拟基于人体分析的老师网络。学生网络输入中除外没有人体分析,老师网络和学生网络结构的输入输出完全相同。PF_AFN 学生网络和导师网络的输入输出完全不
论文阅读-DISTILLING KNOWLEDGE FROM READER TORETRIEVER FOR QUESTION ANSWERING
论文链接:https://arxiv.org/pdf/2012.04584.pdf 目录 方法 交叉注意机制 交叉注意力得分作为段落检索的相关性度量 用于段落检索的密集双编码器 将交叉注意力分数提取到双编码器 数据集 方法 我们的系统由两个模块组成,即检索器和阅读器,遵循开放域问答的标准管道。 给定一个输入问题,这些模块用于分两步生成答案
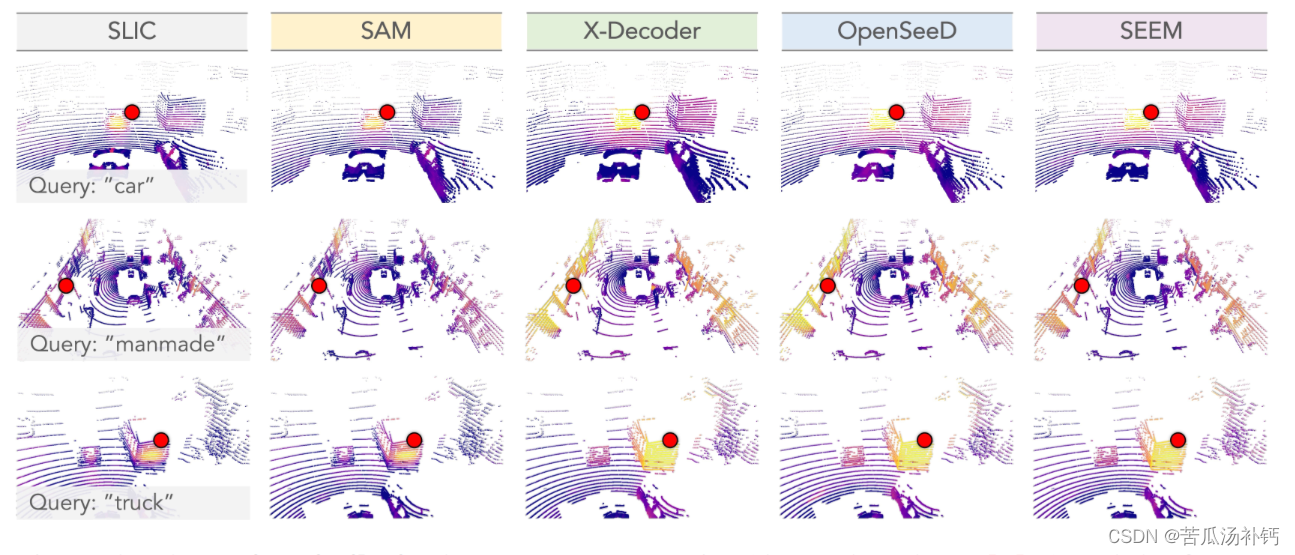
论文阅读:Segment Any Point Cloud Sequences by Distilling Vision Foundation Models
目录 概要 Motivation 整体架构流程 技术细节 小结 论文地址:[2306.09347] Segment Any Point Cloud Sequences by Distilling Vision Foundation Models (arxiv.org) 代码地址:GitHub - youquanl/Segment-Any-Point-Cloud: [NeurIPS
论文阅读:Segment Any Point Cloud Sequences by Distilling Vision Foundation Models
论文地址:[2306.09347] Segment Any Point Cloud Sequences by Distilling Vision Foundation Models (arxiv.org) 代码地址:GitHub - youquanl/Segment-Any-Point-Cloud: [NeurIPS'23 Spotlight] Segment Any Point Cloud S
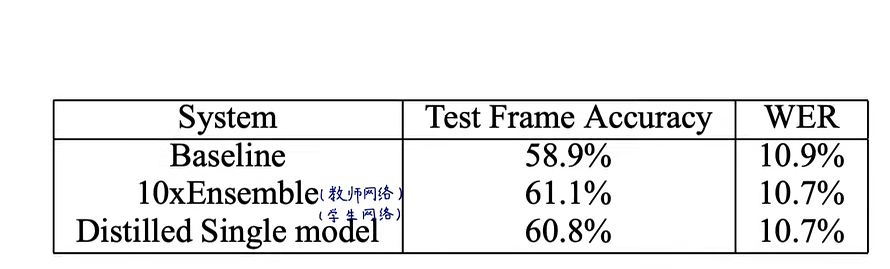
知识蒸馏(Distilling the Knowledge in a Neural Network)论文
知识蒸馏(Distilling the Knowledge in a Neural Network) 三大作者 深度学习教父 Geoffery Hinton 谷歌灵魂人物 oriol Vinyals 谷歌核心人物 Jeff Dean Abstract 多模型集成能提升机器学习性能是指多个性能较差的模型集合在一起可以提升整体的性能。同样集成模型也会出现部署笨重、算力高