本文主要是介绍蘑菇数据集数据挖掘探索-数据处理、SVM、决策树、神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
蘑菇数据集数据挖掘探索-数据处理、SVM、决策树、神经网络
- 背景介绍与实验目标
- 背景介绍
- 实验目标
- 数据挖掘分析与建模
- 分析流程
- 数据初步探索与分析
- 数据预处理
- 数据缺失值处理
- 数据编码
- 模型及算法构建
- 决策树模型
- sklearn的高斯朴素贝叶斯算法
- 神经网络算法
- SVM支持向量机算法
- 调参分析
- 实验结果
- 算法对比
- 性能评估
- 小结
背景介绍与实验目标
背景介绍
误食野生蘑菇中毒事件时有发生,误食毒蘑菇是我国食物中毒事件中导致死亡的最主要原因,而且蘑菇形态千差万别,对于非专业人士,无法从外观、形态、颜色等方面区分有毒蘑菇与可食用蘑菇,没有一个简单的标准能够将有毒蘑菇和可食用蘑菇区分开来。
要了解蘑菇是否可食用,必须采集具有不同特征属性的蘑菇是否有毒进行分析。本文根据UCI的Mushroom Data Set数据集,总样本数为8124,其中6513个样本做训练,1611个样本做测试。并且,其中可食用有4208样本,占51.8%;有毒的样本为3916,占48.2%。每个样本描述了蘑菇的22个属性,比如形状、气味等等。对蘑菇的22种特征属性进行分析,从而得到蘑菇可使用性模型,更好的预测出蘑菇是否可食用。
实验目标
本文旨在根据数据使用 sklearn 的决策树算法,朴素贝叶斯算法, 神经网络,SVM进行分析实现以下目标:
- 对训练集和测试集针对属性的不同特征和意义进行正确的编码
- 使用数据集训练模型(对于各个模型尽量找出最优的参数组合),在测试 集上评估分类器的性能
- 决策树、朴素贝叶斯、SVM, 神经网络选出最优参数后, 再分别进行 10次 K-次交叉验证法, 比较各种分类器的性能,并对比结果
最终达到以下结果:
- 根据采集到的蘑菇数据,通过模型对数据进行训练学习
- 运用蘑菇数据的测试集,识别出其是否为有毒蘑菇
- 对模型进行调参、优化与分析
数据挖掘分析与建模
分析流程
本次数据挖掘实验建模的总体流程主要包括以下步骤:
- 数据进行初步的探索分析,了解数据基本内容,进行数据简单的可视化分析
- 对数据进行预处理,填充缺失值并根据特征属性进行相应的编码
- 在步骤(2)得到处理后数据的基础上使用 sklearn 的决策树算法,朴素贝叶斯算法, 神经网络,SVM建立模型,对蘑菇可使用性建立模型进行模型分
- 对步骤(3)搭建的模型进行参数调整,找出各个模型的的最优参数组合
- 在步骤(4)的基础上对各个模型分别进行10次K-次交叉验证法, 比较各种分类器的性能,并对比结果
数据初步探索与分析
- 导入相关库与模块
import pandas as pd
import numpy as np
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as snsdata = pd.read_csv(open('agaricus-lepiota.data'))- 由于原始文件并没有列名,给原始文件加入列名
columns = ["classes","cap-shape", "cap-surface", "cap- color", "bruises", "odor", "gill-attachment","gill-spacing", "gill-size", "gill-color", "stalk-shape", "stalk-root", "stalk-surface-above-ring","stalk-surface-below-ring", "stalk-color-above-ring", "stalk-color-below-ring", "veil-type", "veil-color","ring-number", "ring-type", "spore-print-color", "population", "habitat"]
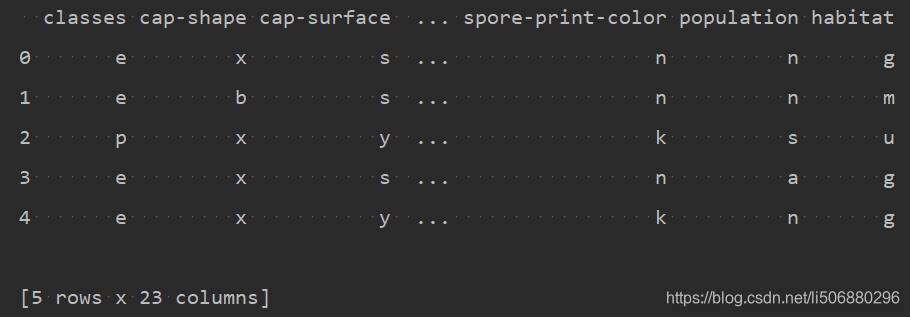
data.columns = columns- 利用data.head()查看前五个数据,对数据有初步了解
print(data.head())
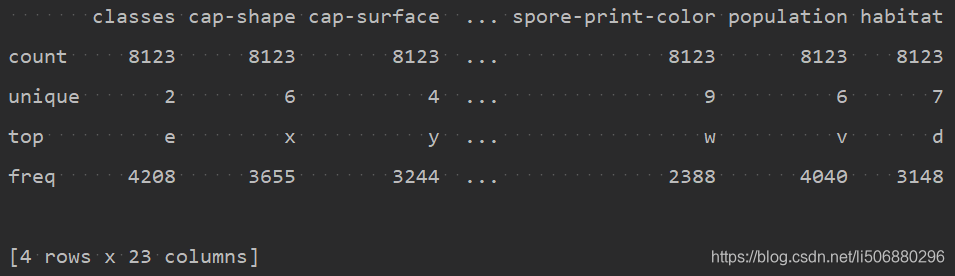
查看数据的基本类型内容
data_describe = data.describe()
print(data_describe)
- 查看数据中是否存在缺失值
print(data.isnull().sum())
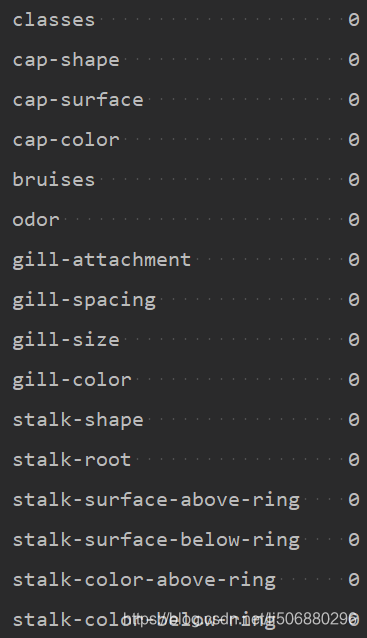
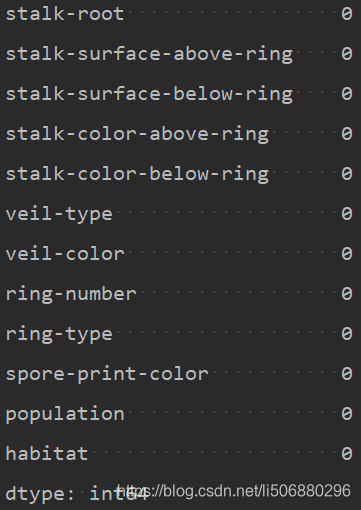
但事实上在stalk-root中存在?缺失值,无法检验出,参考各种补充缺失值的方法,由于移除会使得大量数据被删除,我们使用填充法来补充缺失值。这将在数据预处理板块进行进一步说明。
- 查看所有数据列数据类型,得出都为object类型标称型属性
data_dtypes = data.dtypes
print(data_dtypes)
- 对数据进行简单的可视化处理,以某种特征为例,绘制直方图,对比是否有毒,进行简单的分析与猜想。
以菌盖颜色(’cap-color’)为例:
1. import matplotlib.pyplot as plt
2. import matplotlib as mpl
3. import seaborn as sns
4. cap_colors = data['cap-color'].value_counts()
5. m_height = cap_colors.values.tolist()
6. cap_colors.axes
7. cap_color_labels = cap_colors.axes[0].tolist()
8. print(m_height)
9. print(cap_color_labels)
10. def autolabel(rects,fontsize=14):
11. for rect in rects:
12. height = rect.get_height()
13. ax.text(rect.get_x() + rect.get_width()/2, 1*height,'%d' % int(height),ha='center', va='bottom',fontsize=fontsize)
14.
15. ind = np.arange(10)
16. width = 0.7
17.
18. colors = ['#DEB887', '#778899', '#DC143C', '#FFFF99', '#f8f8ff', '#F0DC82', '#FF69B4', '#D22D1E', '#C000C5', 'g']
19. fig, ax = plt.subplots(figsize=(10, 7))
20. cap_colors_bars = ax.bar(ind, m_height, width, color=colors)
21.
22. ax.set_xlabel("Cap Color", fontsize=20)
23. ax.set_ylabel('Quantity', fontsize=20)
24. ax.set_title('Mushroom Cap Color Quantity', fontsize=22)
25. ax.set_xticks(ind)
26. ax.set_xticklabels(('brown', 'gray', 'red', 'yellow', 'white', 'buff', 'pink', 'cinnamon', 'purple', 'green'),fontsize=12)
27. autolabel(cap_colors_bars)
28. plt.show()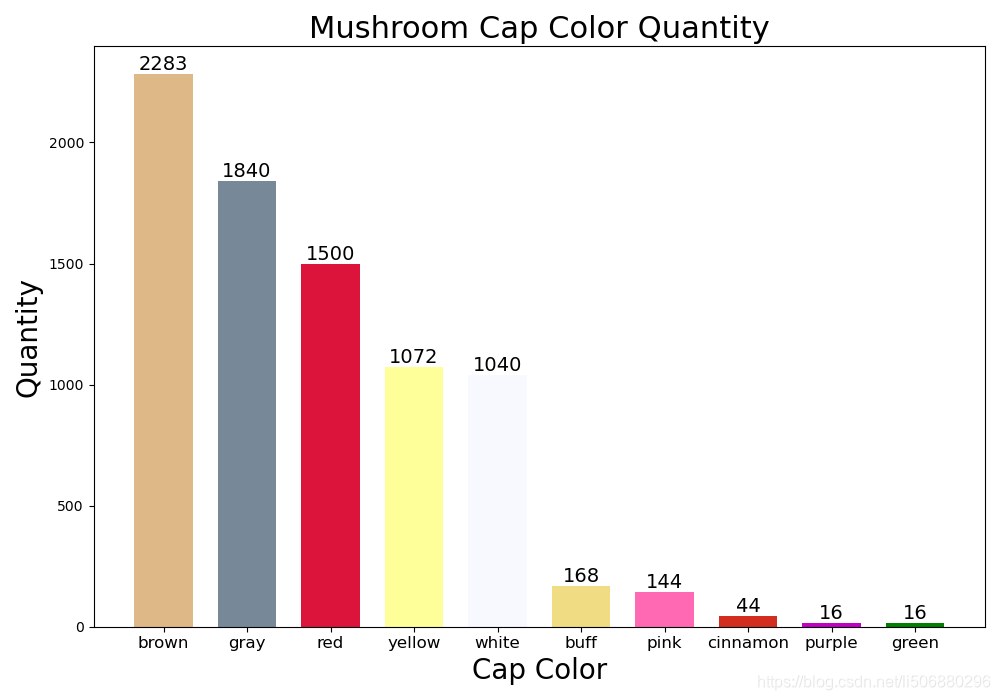
可以看出以菌盖颜色为分界,棕、灰、红、黄、白的蘑菇占大多数,但是具体菌盖颜色与是否有毒之间的关系我们可以也通过直方图大致做出一个分析猜想。
1. import matplotlib.pyplot as plt
2. import matplotlib as mpl
3. import seaborn as sns
4. cap_colors = data['cap-color'].value_counts() #计算各种颜色的数量
5. m_height = cap_colors.values.tolist()
6. cap_colors.axes
7. cap_color_labels = cap_colors.axes[0].tolist()
8. print(m_height)
9. print(cap_color_labels)
10. def autolabel(rects,fontsize=14):
11. for rect in rects:
12. height = rect.get_height()
13. ax.text(rect.get_x() + rect.get_width()/2, 1*height,'%d' % int(height),
14. ha='center', va='bottom',fontsize=fontsize)
15.
16. ind = np.arange(10)
17. width = 0.7
18. # 创建两个列表,分别为各颜色有毒蘑菇的数量和个颜色食用菌的数量
19. poisonous_cc = []
20. edible_cc = []
21.
22. for capColor in cap_color_labels:
23. size = len(data[data['cap-color'] == capColor].index) # 各颜色蘑菇总数
24. edibles = len(data[(data['cap-color'] == capColor) & (data['classes'] == 'e')].index) # 各颜色食用菌的数量
25. edible_cc.append(edibles)
26. poisonous_cc.append(size - edibles)
27. print(edible_cc)
28. print(poisonous_cc)
29.
30. width = 0.4
31. fig, ax = plt.subplots(figsize=(14, 8))
32. edible_bars = ax.bar(ind, edible_cc, width, color='#FFB90F') # 画食用菌的bars
33. # 有毒菌在食用菌右侧移动width个单位
34. poison_bars = ax.bar(ind + width, poisonous_cc, width, color='#4A708B')
35.
36. ax.set_xlabel("Cap Color", fontsize=20)
37. ax.set_ylabel('Quantity', fontsize=20)
38. ax.set_title('Edible and Poisonous Mushrooms Based on Cap Color', fontsize=22)
39. ax.set_xticks(ind + width / 2)
40. ax.set_xticklabels(('brown', 'gray', 'red', 'yellow', 'white', 'buff', 'pink', 'cinnamon', 'purple', 'green'),
41. fontsize=12)
42. ax.legend((edible_bars, poison_bars), ('edible', 'poisonous'), fontsize=17)
43. autolabel(edible_bars, 10)
44. autolabel(poison_bars, 10)
45. plt.show()得到结果如下图
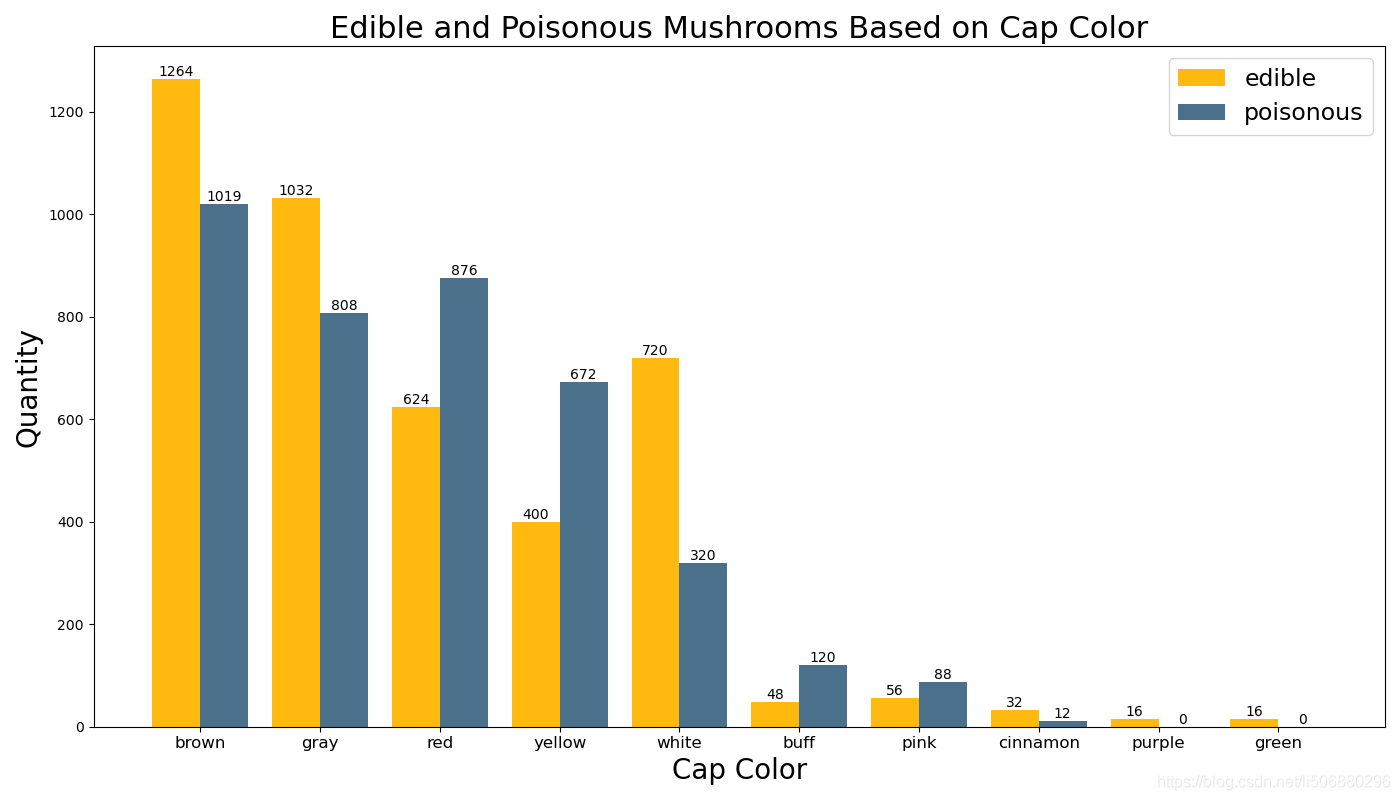
综合以上两个柱状图可以得出红色、黄色、褐色、粉色这些颜色比较鲜艳的蘑菇有毒的几率更大,棕色、灰色的蘑菇比较常见,但是否可食用需要更进一步的分析判断。
以蘑菇气味(’ odor’)为例:
再次运用以上代码,得到:
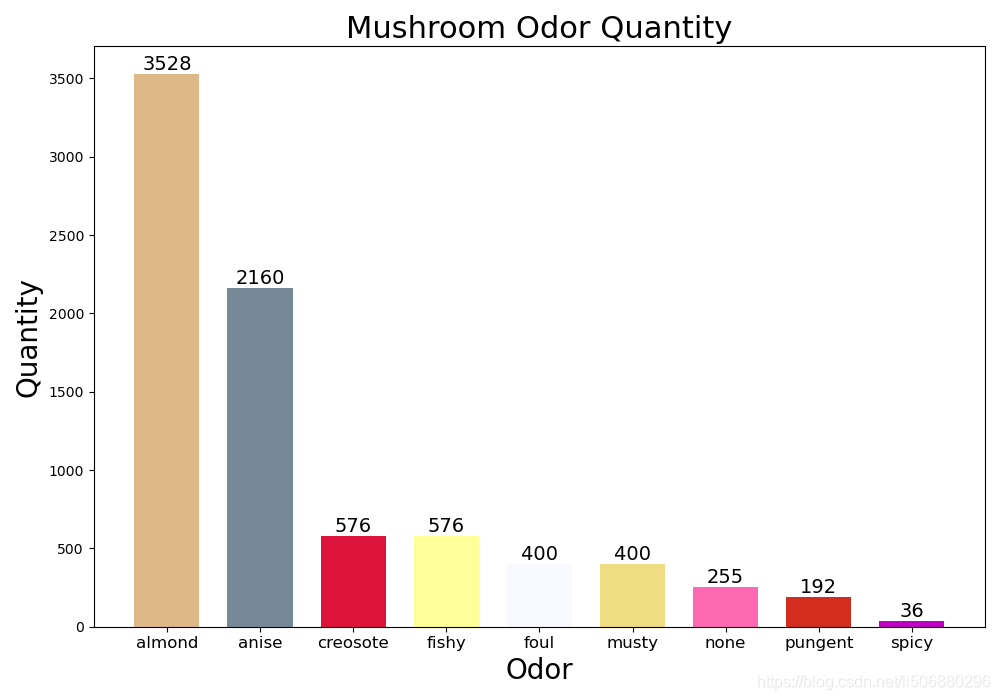
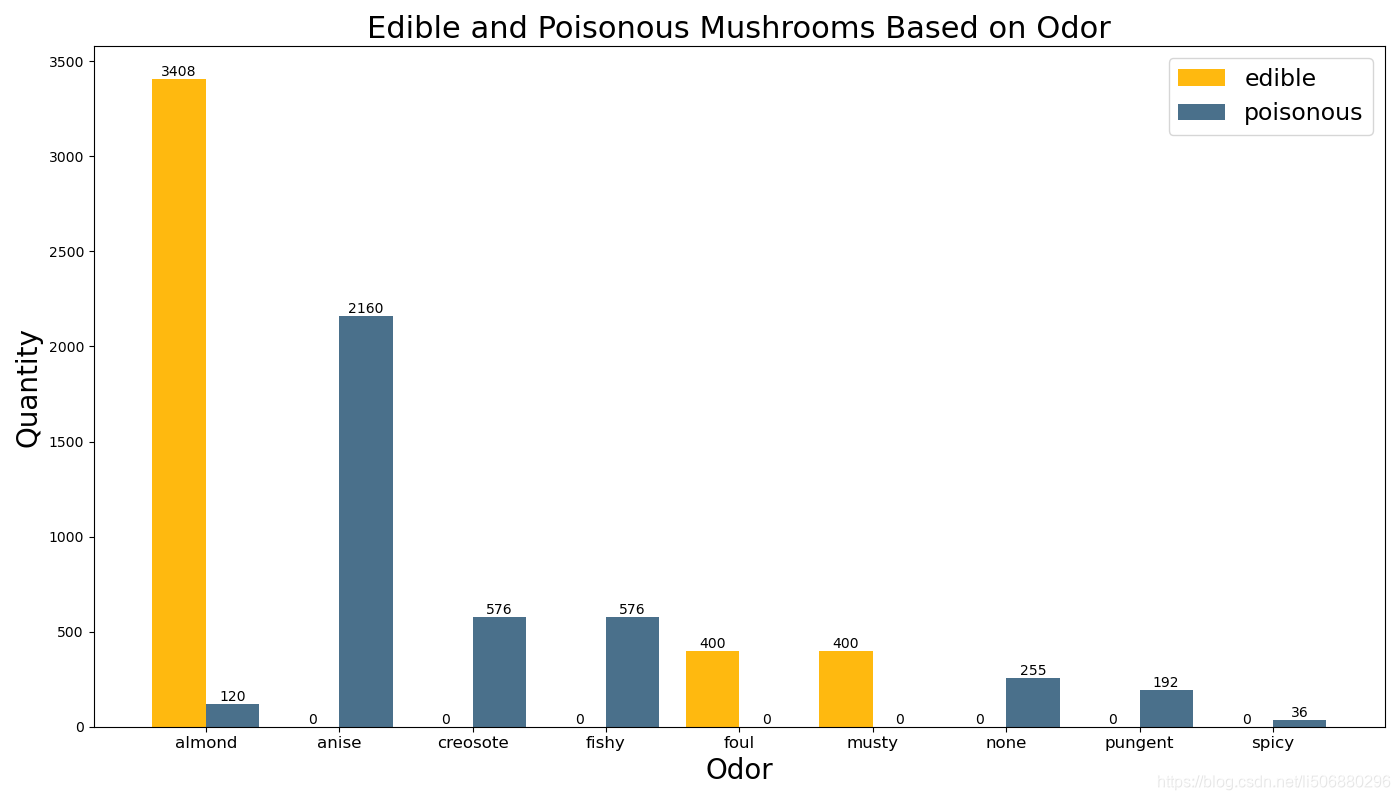
由上面两个条形图可以分析出杏仁味almond的蘑菇数比较多,且大部分可使用,臭味的foul、霉味的musty的蘑菇也几乎可以食用,而茴芹味anise、杂酚油味creosote、鱼腥味fishy、无味none、气味刺鼻pungent、气味呛人spicy的蘑菇几乎全部有毒不可食用。
综上可以大略看出,蘑菇的气味比蘑菇的菌盖颜色更好辨认蘑菇是否可食用,我们对这个数据又有了进一步更直观简洁的认识。
- 再利用相关性,简单分析下各个特征属性与有毒的相关性
1. # 7 各特征与有毒相关性分析画图
2. def analysis_poison(data,index_name):
3. data["classes"].replace({"p":1,"e":0},inplace=True)
4. return data.groupby([index_name])["classes"].sum() / pd.value_counts(data[index_name])
5. # pd.value_counts(a)
6. # analysis_poison(dataset[["class","cap-color"]],"cap-color")
7.
8. plt.close()
9. plt.figure(figsize=(16,30))
10. i = 1
11. danger=[]
12. for index_name in data.columns[1:]:
13. result = analysis_poison(data[["classes",index_name]],index_name)
14. ax = plt.subplot(6,4,i)
15. ax.set_title(index_name)
16. result.plot(kind="bar",color='#778899')
17. temp = result[result > 0.75]
18. temp = temp.rename(index=lambda x:":".join([index_name,x]))
19. danger.append(temp)
20. # plt.bar(range(len(result)),result.data)
21. i += 1
22.
23. plt.show()得出下图结果:
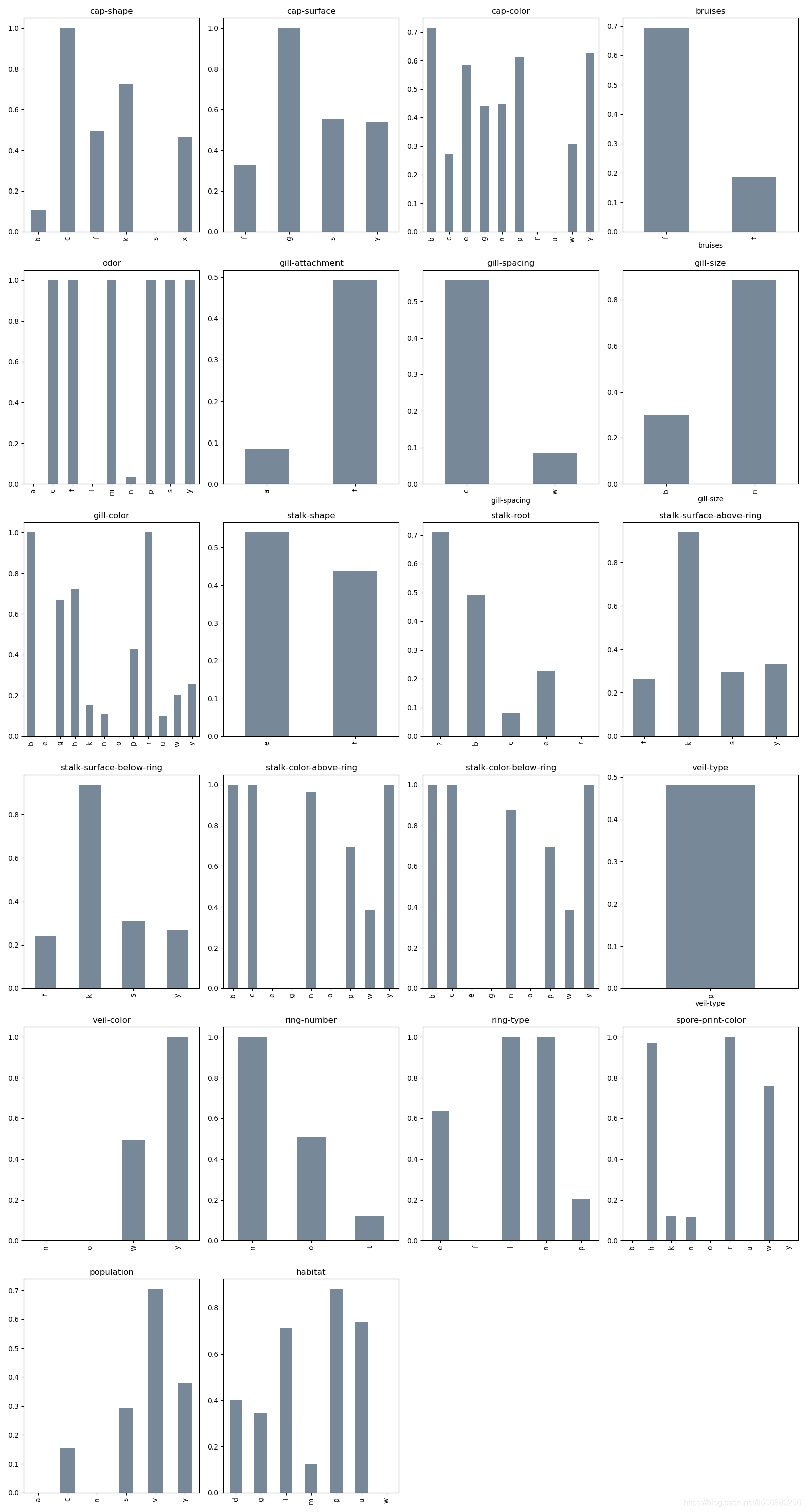
从上图中可以分析出蘑菇的气味odor、蘑菇孢子印花颜色spore-print-color、蘑菇耳颜色gill-color是比较明显的关联性较强的识别是否有毒特性的特征属性,是比较好的作为关联性观察的特征。
数据预处理
由2.2对数据的初步探索分析我们可以得知,mushroom数据所有的属性均为标称型object属性,且有三个属性的特征数小于三,故我选择运用LabelEncoder和OneHotEncoder对他们进行重新的编码。
数据缺失值处理
因为在stalk-root中存在?缺失值,无法检验出,参考各种补充缺失值的方法,由于移除会使得大量数据被删除,我们使用填充法来补充缺失值。因为整体样本量大,且缺失值为离散的有意义的,这里我选用的是用前面一行的值来替换缺失值。
data.replace('?', np.nan).fillna(method='pad')
数据编码
因为mushroom数据所有特征属性均为object标称型属性,且数据均为离散具有意义我采用一下编码方式:
- 首先给其中特征数小于3的进行LabelEncoder编码
1. labelencoder=LabelEncoder()
2. for col in ["classes","bruises","gill-size","stalk-shape","veil-type"]:
3. data[col] = labelencoder.fit_transform(data[col])
4. # print(data)- 再给其余属性进行OneHotEncoder编码
1. a = ["cap-shape", "cap-surface", "cap-color", "odor", "gill-attachment",
2. "gill-spacing", "gill-color", "stalk-root","stalk-surface-above-ring",
3. "stalk-surface-below-ring","stalk-color-above-ring","stalk-color-below-ring",
4. "veil-color","ring-number","ring-type","spore-print-color","population","habitat"]
5. enc = OneHotEncoder(sparse=False)
6. for i in a:
7. A = data.loc[:, [i]].values.tolist()
8. enc.fit(A)
9. result = enc.transform(A)
10. nattr = len(result[0])
11. attr_list = []
12. for j in range(nattr):
13. data.loc[:, str(i) + str(j)] = 0
14. attr_list.append(str(i) + str(j))
15. data.loc[:, attr_list] = result- 再将Label赋给Y,剩余的属性值赋给X
1. Y = data["classes"]
2. # print(Y)
3. data.drop("classes", axis=1, inplace=True, )
4. X = data.drop(a, axis=1)
5. # print(X)从而得到最终的预处理过后的数据。
模型及算法构建
经过数据预处理之后,进行数据划分,将数据划分为训练集和测试集
1. #将数据划分为训练集和测试集
2. trainX, testX, trainY, testY = train_test_split(x,y,test_size=0.33,random_state=4)下面进行4个模型的构建:
决策树模型
- 建立决策树模型
1. def decision_tree(trainX, trainY, testX, testY):
2. # start = time.time()
3. param = {'criterion':['entropy'],'max_depth':list(range(7,12)),'min_samples_split':list(range(8,12))}
4. grid = GridSearchCV(tree.DecisionTreeClassifier(),param_grid=param,cv=5)#寻找最优参数
5. grid.fit(trainX,trainY)
6. print('最优分类器:',grid.best_params_,'最优分数:', grid.best_score_)#最优参数下1次交叉验证的结果
7. # start2 = time.time()
8. clf = tree.DecisionTreeClassifier(**grid.best_params_)
9. clf.fit(trainX, trainY)
10. score = clf.score(testX, testY)
11. print("Test score on test data:", score)
得到
最优分类器: {‘criterion’: ‘entropy’, ‘max_depth’: 7, ‘min_samples_split’: 8} 最优分数: 0.9998163452708907
Test score on test data: 1.0
- 下载graphviz,更改环境路径path后利用graphviz画出决策树图
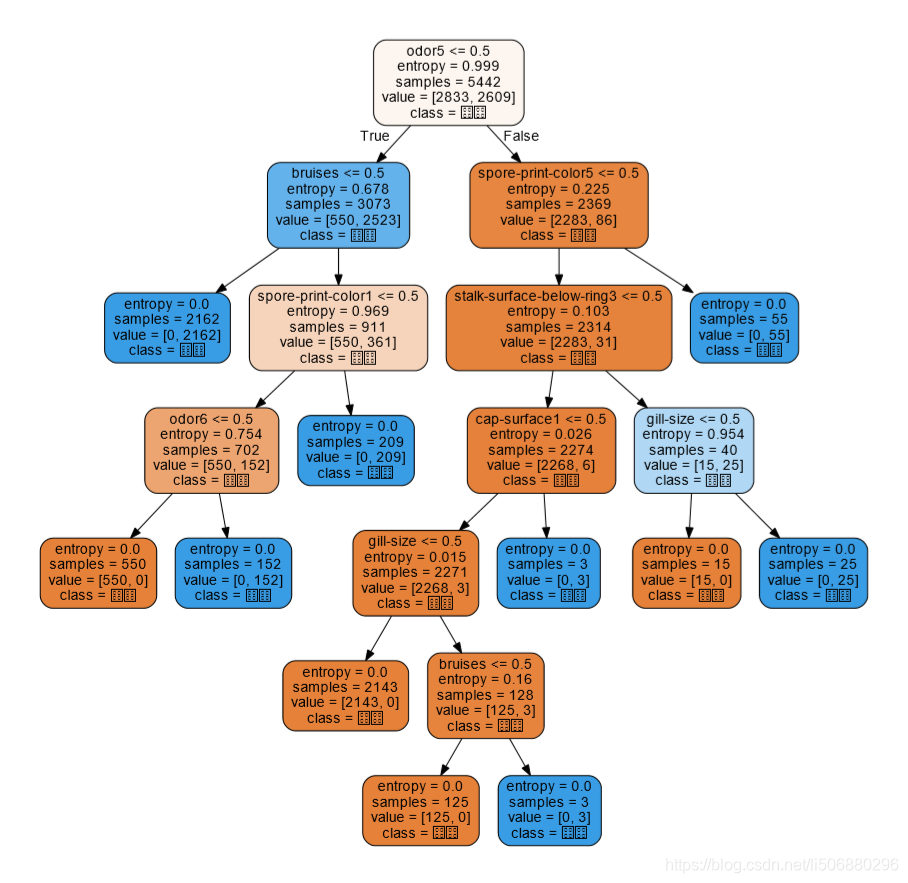
sklearn的高斯朴素贝叶斯算法
建立sklearn的高斯朴素贝叶斯模型
1. from sklearn.naive_bayes import GaussianNB
2. from sklearn.naive_bayes import MultinomialNB
3. from sklearn.preprocessing import StandardScaler
4. def naivebayes2(trainX,trainY,testX,testY):
5. # start = time.time()
6. scaler = StandardScaler()
7. scaler.fit(trainX)#寻找最优参数
8. trainX2 = scaler.transform(trainX)
9. # print( '最优参数寻找时间:', time.time() - start)
10. # start2 = time.time()
11. testX2 = scaler.transform(testX)
12. clf = GaussianNB().fit(trainX2, trainY)
13. pred = clf.predict(testX2)
14.
15. from sklearn.metrics import accuracy_score
16. accuracy = accuracy_score(pred, testY)
17. print("accuracy of GaussianNB:", accuracy)
18. # print('运行时间:', time.time() - start2)
19. return accuracy
20.
21. naivebayes2(trainX,trainY,testX,testY)得到
accuracy of GaussianNB: 0.9429317418873555
神经网络算法
建立神经网络模型
1. #神经网络
2. def neural_network():
3. # start = time.time()
4. scaler = StandardScaler()#归一化处理
5. scaler.fit(trainX)
6. trainX1 = scaler.transform(trainX)
7. param = {'hidden_layer_sizes': [(20, 10), (10, 5)]}
8. grid = GridSearchCV(MLPClassifier(), param_grid=param, cv=5)
9. grid.fit(trainX1, trainY)
10. print('最优分类器:', grid.best_params_, '最优分数:', grid.best_score_)
11. # start2 = time.time()
12. testX1 = scaler.transform(testX)
13. print("Score of NN is", grid.score(testX1, testY))
14. return grid.best_score_得到
最优分类器: {‘hidden_layer_sizes’: (20, 10)} 最优分数: 0.9996325217414789
Score of NN is 1.0
SVM支持向量机算法
建立SVM支持向量机模型
1. #SVM支持向量机
2.
3. import math
4. #计算Gamma
5. def calGamma(X):#随机抽取样本点,对距离进行排序,找到所有距离最远的gamma
6. N = X.shape[0]
7. L = np.array(range(N))
8. np.random.shuffle(L)
9. d = []
10. for i in range(1,round(N*0.01)):
11. for j in range(round(N*0.01) + 1, round(N*0.02)):
12. xi = X[L[i],:]
13. xj = X[L[j],:]
14. d.append(sum((np.power(xi - xj,2))))
15. d.sort()
16. idx = len(d)
17. dn = d[round((idx-1)*0.1)]
18. df = d[round((idx-1)*0.9)]
19. gamma = 1/(2*(df - dn)/(2*(math.log(df)-math.log(dn))))
20. return gamma
21.
22. def SVM(trainX,trainY,testX,testY):
23. # start = time.time()
24. from sklearn.svm import SVC,LinearSVC
25. scaler = StandardScaler() # 标准化
26. scaler.fit(trainX)
27. trainX3 = scaler.transform(trainX)
28. gamma = calGamma(trainX3) # 由训练与算法评估.py文件得到
29. # print( '最优参数寻找时间:', time.time()-start)
30. # start2 = time.time()
31. testX3 = scaler.transform(testX)
32. model = SVC(C=45, kernel='rbf', gamma = gamma)
33. model.fit(trainX3, trainY)
34. print("Score of the svm on the test data:", model.score(testX3, testY))
35. # print('运行时间:', time.time() - start2)
36. return model.score(testX3, testY)得到
Score of the svm on the test data: 0.999627004848937
调参分析
实验结果
- 决策树模型
最优分类器: {‘criterion’: ‘entropy’, ‘max_depth’: 7, ‘min_samples_split’: 7, ‘splitter’: ‘random’} 最优分数: 0.9998163452708907
Test score on test data: 1.0 - sklearn的高斯朴素贝叶斯算法
accuracy of GaussianNB: 0.9429317418873555 - 神经网络算法
最优分类器: {‘activation’: ‘logistic’, ‘hidden_layer_sizes’: (100, 50)} 最优分数: 1.0
Score of NN is 1.0 - SVM支持向量机算法
Score of the svm on the test data: 1.0
算法对比
综上实验进行分析对比四类算法,sklearn的高斯朴素贝叶斯算法没有太多的参数可以调整,因此贝叶斯算法的成长空间并不是太大,对于贝叶斯计算出来的结果与其他模型相比也明显降低。显然sklearn的高斯朴素贝叶斯算法相较于其他三种算法效果并不佳。
其他三种算法在运行速度上决策树和SVM向量机的速度较快,神经网络相对较慢。
从最优分数上来看,神经网络算法与SVM支持向量机的最优分数最高。
性能评估
接下来我们利用10折k倍交叉验证法进行模型的性能评估
1. #K倍交叉验证法
2. from sklearn.model_selection import KFold
3. import matplotlib.pyplot as plt
4. def KF(data2, k=10):
5. kf = KFold(n_splits=k)
6. #print(kf)
7. #print(kf.split(train_data))
8. n = 1
9. train_X = []
10. train_Y = []
11. test_X = []
12. test_Y = []
13. # print(data1[0])
14. for i,j in kf.split(data2[0]):
15. #print(len(data), len(test_data[0]), len(test_data[1]))
16. #print(n, 'K折划分:%s %s' % (i, j))#得到K折划分索引
17. #print(i,j)
18. train_X.append(data2[0].iloc[i, :])
19. #print(test_data[1].loc[i])
20. train_Y.append(data2[1].iloc[i])
21. test_X.append(data2[0].iloc[j, :])
22. test_Y.append(data2[1].iloc[j])
23. n += 1
24. return train_X, train_Y, test_X, test_Y
25.
26.
27. def kflod():
28. # print(KF(data2))
29. #print(data)
30. #算法模型构建及实验结果:
31. #五种算法:决策树、SVM、sklearn朴素贝叶斯、general朴素贝叶斯、神经网络
32. kf = KF(data2)
33. #print(kf[0])
34. clf = ['decision_tree', 'naivebayes2', 'neural_network', 'SVM']
35. #print(eval(clf[3])(kf[0][2], kf[1][2], kf[2][2], kf[3][2]))
36. fig = plt.figure()
37. for i in range(4):
38. Score = []
39. ax = fig.add_subplot(2, 2, i+1)
40. # print('---------------------------------------')
41. # print(clf[i])
42. # eval(clf[i])(kf[0][2], kf[1][2], kf[2][2], kf[3][2])
43. for j in range(10):
44. score = eval(clf[i])(kf[0][j], kf[1][j], kf[2][j], kf[3][j])
45. Score.append(score)
46. print(i, j, clf[i])
47. ax.boxplot(Score)
48. ax.set_title(clf[i])画出如下箱线图:
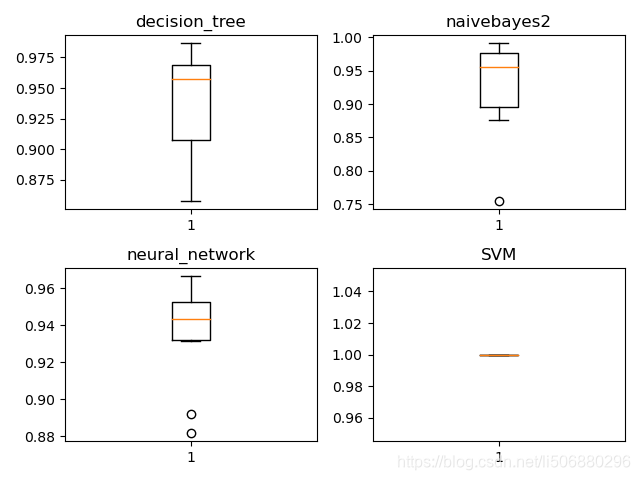
由上可以看出SVM支持向量机的性能较好,decision_tree决策树的最大最小分数跨度比较大,朴素贝叶斯与神经网络性能差不多。
小结
这篇关于蘑菇数据集数据挖掘探索-数据处理、SVM、决策树、神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




