决策树专题

决策树的实现原理与matlab代码
很久不写博客了,感觉很长一段时间只是一味的看书,疏不知一味地看书、写代码会导致自己的思考以及总结能力变得衰弱。所以,我决定还是继续写博客。废话不多说了,今天想主要记录数据挖掘中的决策树。希望能够将自己的理解写得通俗易懂。 决策树是一种对实例分类的树形结构,树中包含叶子节点与内部节点。内部节点主要是数据中的某一特性,叶子节点是根据数据分析后的最后结果。 先看一组数据: 这组数据的特性包含

机器学习(西瓜书)第 4 章决策树
4.1 决策树基本流程 决策树模型 基本流程 在第⑵种情形下,我们把当前结点标记为叶结点,并将其类别设定为该结点所含样本最多的类别;在第⑶种情形下,同样把当前结点标记为叶结点,但将其类别设定为其父结点所含样本最多的类别.注意这两种情形的处理实质不同:情形⑵是在利用当前结点的后验分布,而情形⑶则是把父结点的样本分布作为当前结点的先验分布. 基本算法 由算法4 .2可看出,决策树学习

【机器学习-监督学习】决策树
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈Python机器学习 ⌋ ⌋ ⌋ 机器学习是一门人工智能的分支学科,通过算法和模型让计算机从数据中学习,进行模型训练和优化,做出预测、分类和决策支持。Python成为机器学习的首选语言,依赖于强大的开源库如Scikit-learn、TensorFlow和PyTorch。本专栏介绍机器学习的相关算法以及基于Python的算法实现。

Spark2.x 入门:决策树分类器
一、方法简介 决策树(decision tree)是一种基本的分类与回归方法,这里主要介绍用于分类的决策树。决策树模式呈树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。学习时利用训练数据,根据损失函数最小化的原则建立决策树模型;预测时,对新的数据,利用决策树模型进行分类。 决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的剪枝。
第L5周:机器学习:决策树(分类模型)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目标: 1. 决策树算法是一种在机器学习和数据挖掘领域广泛应用的强大工具,它模拟人类决策过程,通过对数据集进行逐步的分析和判定,最终生成一颗树状结构,每个节点代表一个决策或一个特征。决策树的核心思想是通过一系列问题将数据集划分成不同的类别或值,从而实现对未知数据的预测和分类。这一算法的开发灵感源自人类在解决问题

机器学习项目——基于机器学习(决策树 随机森林 朴素贝叶斯 SVM KNN XGBoost)的帕金森脑电特征识别研究(代码/报告材料)
完整的论文代码见文章末尾 以下为核心内容和部分结果 问题背景 帕金森病(Parkinson’s Disease, PD)是一种常见的神经退行性疾病,其主要特征是中枢神经系统的多巴胺能神经元逐渐丧失,导致患者出现运动障碍、震颤、僵硬等症状。然而,除运动症状外,帕金森病患者还常常伴有一系列非运动症状,其中睡眠障碍是最为显著的非运动症状之一。 脑电图(Electroencephalogram, E

分类预测|基于蜣螂优化极限梯度提升决策树的数据分类预测Matlab程序DBO-Xgboost 多特征输入单输出 含基础模型
分类预测|基于蜣螂优化极限梯度提升决策树的数据分类预测Matlab程序DBO-Xgboost 多特征输入单输出 含基础模型 文章目录 一、基本原理1. 数据准备2. XGBoost模型建立3. DBO优化XGBoost参数4. 模型训练5. 模型评估6. 结果分析与应用原理总结 二、实验结果三、核心代码四、代码获取五、总结 分类预测|基于蜣螂优化极限梯度提升决策树的数据分类

《西瓜书》第四章 决策树 笔记
文章目录 4.1 基本流程4.1.1 组成4.1.2 目的4.1.3 策略4.1.4 算法 4.2 划分选择4.2.1信息增益-ID3决策树4.2.1.1 信息熵4.2.1.1 信息增益 4.2.2 增益率-C4.5决策树4.2.3 基尼指数-CART决策树4.2.3.1 基尼值4.2.3.2 基尼指数 4.3 剪枝处理4.3.1 预剪枝4.3.2 后剪枝 4.4 连续与缺失值4.4.1
基于SSM的“基于决策树算法的大学生就业预测系统”的设计与实现(源码+数据库+文档)
基于SSM的“基于决策树算法的大学生就业预测系统”的设计与实现(源码+数据库+文档) 开发语言:Java 数据库:MySQL 技术:SSM 工具:IDEA/Ecilpse、Navicat、Maven 系统展示 系统用户用例图 学校基础信息管理 毕业生基础数据 招聘信息 数据可视化展现 历年对比预测 用户管理 个人中心 日志管理 摘要 计算机

5.sklearn-朴素贝叶斯算法、决策树、随机森林
文章目录 环境配置(必看)头文件引用1.朴素贝叶斯算法代码运行结果优缺点 2.决策树代码运行结果决策树可视化图片优缺点 3.随机森林代码RandomForestClassifier()运行结果总结 环境配置(必看) Anaconda-创建虚拟环境的手把手教程相关环境配置看此篇文章,本专栏深度学习相关的版本和配置,均按照此篇文章进行安装。 头文件引用 from sklear

使用SQL SERVER BI软件实际实验决策树模型的步骤详解
实验步骤的简单过程 前提条件是环境配置完成,并且将实验数据已经导入到SQL Server中,即SSMS(SQL Server Management Studio),本人的数据是放到BI数据库下的表中。(如下图所示,数据已经导入) 打开软件,然后新建项目。 实验步骤主要是集中在右侧的解决方案资源管理器。(从上到下每一步依次进行右键新建) 新建数据源:

决策树----第一部分(熵)
建立决策树的关键,即在当前状态下选择哪个属性作为分类依据。根据不同的目标函数,建立决策树主要有一下三种算法。 ID3 (J. Ross Quinlan-1975)核心:信息熵 (信息增益算法) C4.5—ID3的改进,核心:信息增益比 CART(Breiman-1984),核心:基尼指数 下面是对熵的介绍 熵表示随机变量的不确定性的度量,熵越大,随机变量的不确定性


《机器学习》周志华-CH4(决策树)
4.1基本流程 决策树是一类常见的机器学习方法,又称“判别树”,决策过程最终结论对应了我们所希望的判定结果。 一棵决策树 { 一个根结点 包含样本全集 若干个内部结点 对应属性测试,每个结点包含的样本集合根据属性测试结果划分到子结点中 若干个叶结点 对应决策结果 一棵决策树 \begin{cases} 一个根结点 &包含样本全集 \\ 若干个内部结点 & 对应属性测试,每个结点包含的样本


手写决策树ID3算法(python)
决策数(Decision Tree)在机器学习中也是比较常见的一种算法,属于监督学习中的一种。看字面意思应该也比较容易理解,相比其他算法比如支持向量机(SVM)或神经网络,似乎决策树感觉“亲切”许多。 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失值不敏感,可以处理不相关特征数据。 缺点:可能会产生过度匹配的问题。 使用数据类型:数值型和标称型。 简单介绍完毕,让我们来通过一个例子让决策

机器学习——决策树模型
决策树原理 算法概述 从根节点开始一步步走到叶子节点(决策) 所有数据最终都会落到叶子节点,既可以做分类也可以做回归 例如上例,输入一个数据后,先判断他的年龄,然后再判断性别 在决策树中,根节点的决策效果较强——即能够明显的将数据划分(分类的效果最好) 因此,对于每个节点特征的选取,为决策树需要解决的核心内容 树的组成 根节点:第一个选择点 叶子节点:最终的决策结果 非叶子

决策树和随机森林介绍
hello大家好,俺是没事爱瞎捣鼓又分享欲爆棚的叶同学!!!今天我来给大家介绍一下决策树与随机森林,说起随机森林俺还有件很久远的丑事,之前有关课的结课作业就是用模型训练并预测,那时我比较天真,想着先玩,然后随便在网上找个代码糊弄糊弄就行了,然后到答辩那天我站在讲台上说出:“本次预测用了随机森林”,讲的绘声绘色,那自信的差点把自己都骗了哈哈哈哈,然后俺讲完,老师点评时,望着手中的报告笑着说了句:“你

【人工智能 | 机器学习 | 理论篇】决策树(decision tree)
文章目录 1. 基本流程2. 划分选择2.1 信息增益2.2 增益率2.3 基尼系数 3. 剪枝处理3.1 预剪枝3.2 后剪枝 4. 连续与缺失值4.1 连续值处理4.2 缺失值处理 5. 多变量决策树 1. 基本流程 二分类任务决策树流程: 决策树:包含 1个根结点、若干个内部结点、若干个叶结点。叶结点对应决策结果,内部结点对应属性测试 决策树训练过程 决策树训练时,

《机器学习》 决策树 ID3算法
目录 一、什么是决策树? 1、概念 2、优缺点 3、核心 4、需要考虑的问题 二、决策树分类标准,ID3算法 1、什么是ID3 算法 2、ID3算法怎么用 1)熵值计算公式 2)用法实例 三、实操 ID3算法 1)求出play标签的熵值 2)分别计算天气、温度、湿度、风、play的信息增益 • 求outlook 总熵值及信息增益 • 求temperature 总熵值及

数学建模~~~预测方法--决策树模型
目录 0.直击重点 1.决策树概念 2.节点特征的选择算法 3.基尼系数的计算 4.决策树的分类 5.模型的搭建 6.模型的改进和评价 ROC曲线 参数调优 GridSearch网格搜索 使用搜索结果重新建模 0.直击重点 这个文章,我们从三个维度进行说明介绍: 第一维度:介绍基本的概念,以及这个决策树的分类和相关的这个算法和基尼系数的计算方法,通过给定

机器学习:随机森林决策树学习算法及代码实现
1、概念 随机森林(Random Forest)是一种集成学习方法,它通过构建多个决策树来进行分类或回归预测。随机森林的核心原理是“集思广益”,即通过组合多个弱学习器(决策树)的预测结果来提高整体模型的准确性和健壮性。 2、集成学习(Ensemble Learning): 集成学习是一种机器学习方法,它结合多个学习器的预测结果来提高整体模型的性能。随机森林是集

机器学习之-决策树理解
是什么? 决策树是非参数有监督的算法,所谓非参数就是统计总体分布形式未知或虽已知却不能用有限个参数刻画的统计问题,这种解释有点晦涩,用我们普通人的视角理解就是,给我们一些数据,没有对应的ax+b中的a值和b值,通过数据的分布从而反推a和b,进一步来预测数据的分布; 就比如说,给我们一些数据,例如: 对于如上数据,survived表示y标签,除了y标签以外是x标签;如果找到

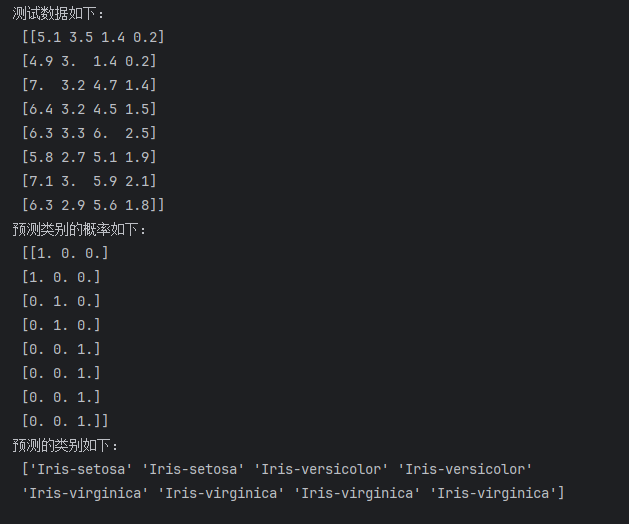
机器学习:决策树分类代码实现
1、概念 决策树分类是一种监督学习算法,用于分类问题,即预测离散标签。其核心原理是通过树状图模型来模拟决策过程,从而对数据进行分类。 2、数据准备: 收集数据集,并对其进行清洗和预处理。 将数据集分为特征(X)和目标变量(y) datas=pd.read_excel("电信客户流失数据.xlsx")data=datas.iloc[:,:
【机器学习】朴素贝叶斯 决策树 随机森林 线性回归
机器学习分类算法 朴素贝叶斯 条件概率公式 P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A \mid B)=\frac{P(A \cap B)}{P(B)} P(A∣B)=P(B)P(A∩B) 在B条件发生的情况下,A发生的概率。 事件 A 发生的概率定义为事件 A 发生的情况数除以所有可能情况的总数。 P(A) =(事件 A 发生的情况数)/(所有可能情况