本文主要是介绍【论文笔记】SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:https://arxiv.org/abs/2304.14340
1.引言
目前的3D目标检测工作都使用模态的密集表达(如BEV、体素、点云),但由于我们只对实例/物体感兴趣,这种密集表达是冗余的。此外,背景噪声对检测有害,且将多模态对齐到同一空间很耗时。
相反,稀疏表达很高效且能达到SotA性能。通常,使用稀疏表达的方法使用物体查询表示物体或实例,并与原始图像和点云特征交互。
本文提出SparseFusion(如下图所示),使用稀疏候选对象产生稀疏表达,使3D目标检测性能高而耗时少。该方法是第一个使用稀疏候选对象和稀疏融合输出的图像-激光雷达融合3D目标检测方法。首先对各模态分别进行3D目标检测,并投影到相同的3D空间。使用轻量级注意力模块融合实例级的特征,但各单一模态的缺点可能导致融合阶段的负转移。本文在并行检测分支的输入端之前使用跨模态信息转移方法,以解决这一问题。在nuScenes上,SparseFusion能有最快的速度和最好的性能。

2.相关工作
目前的多模态3D目标检测工作可分为4类:
密集+稀疏→密集:如Frustum-PointNet,使用2D感兴趣区过滤密集点云。
密集+密集→密集:如PointPainting、PointAugmenting将点云投影到图像上获取图像特征与点云特征拼接;BEVFusion将密集图像特征按照估计的深度提升到激光雷达坐标系。
稀疏+密集→稀疏:如TransFusion使用激光雷达提取稀疏实例级特征,并使用密集图像特征细化。
密集+密集→稀疏:使用查询从密集图像特征和点云BEV特征提取稀疏实例级表达(如UVTR),但不同模态存在域间隙(domain gap),需要堆叠大量的Transformer构成解码器。
本文提出新的一类方法,即稀疏+稀疏→稀疏方法。先从各模态提取稀疏表达,再融合生成语义丰富且定位精确的稀疏表达。
3.方法
如下图所示为本文的网络结构。各模态分别检测得到实例级特征后,使用自注意力模块融合。此外,在并行检测分支前使用几何转移模块和语义转移模块,以减小模态间的负面转移。
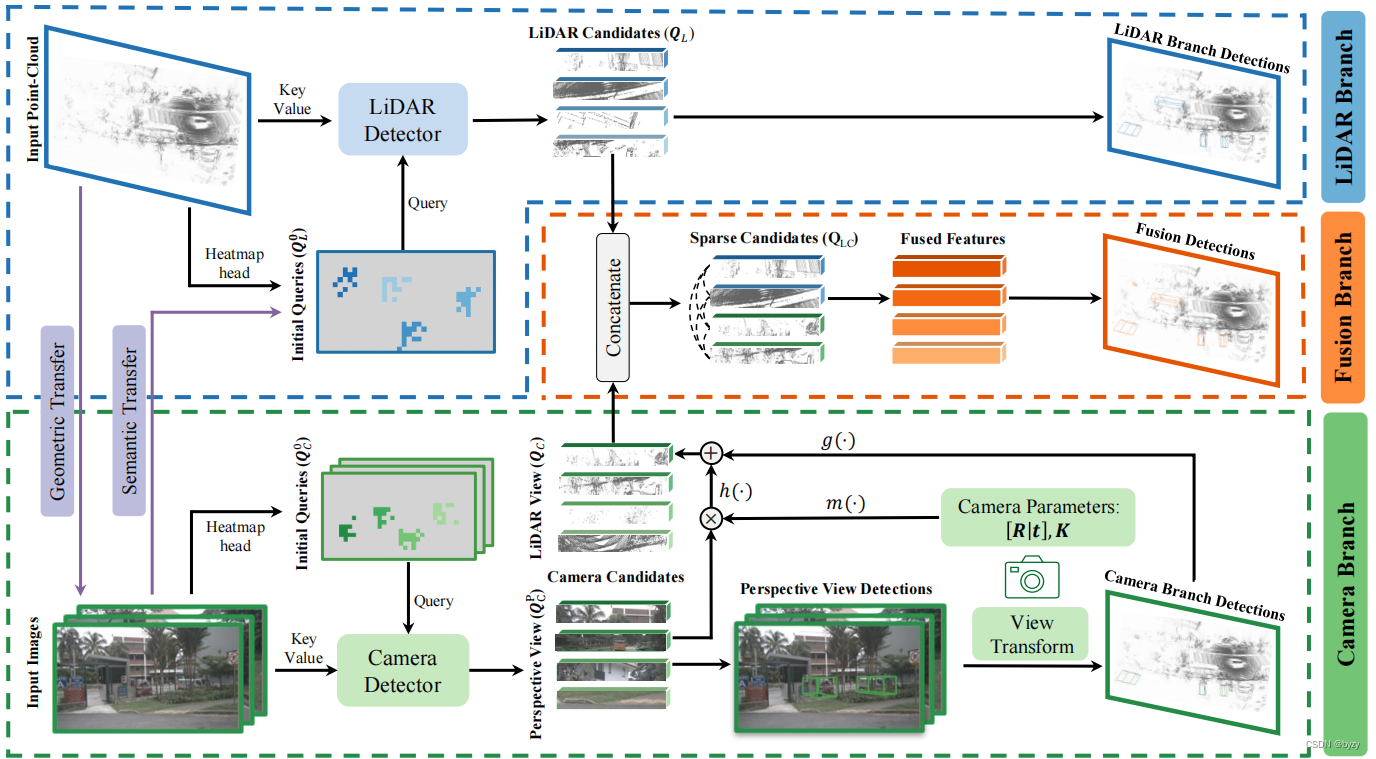
3.1 稀疏表达融合
获取各模态的候选对象
激光雷达候选对象: 使用Transfusion-L并仅使用一个解码层进行检测。激光雷达主干从点云提取BEV特征图后,初始化 N L N_L NL个物体查询 Q L 0 = { q L , i 0 } i = 1 N L , q L , i 0 ∈ R C Q_L^0=\{q_{L,i}^0\}_{i=1}^{N_L},q_{L,i}^0\in\mathbb{R}^C QL0={qL,i0}i=1NL,qL,i0∈RC及其对应的BEV 2D参考点 p L 0 = { p L , i 0 } i = 1 N L , p L , i 0 ∈ R 2 p_L^0=\{p_{L,i}^0\}_{i=1}^{N_L},p_{L,i}^0\in\mathbb{R}^2 pL0={pL,i0}i=1NL,pL,i0∈R2。使用交叉注意力将这些查询与BEV特征交互,以更新物体查询 Q L = { q L , i } i = 1 N L , q L , i ∈ R C Q_L=\{q_{L,i}\}_{i=1}^{N_L},q_{L,i}\in\mathbb{R}^C QL={qL,i}i=1NL,qL,i∈RC。这些更新的查询 Q L Q_L QL就是激光雷达的实例级特征,作为后续融合模块的激光雷达候选对象。此外,还使用检测头为每个查询分类和回归激光雷达坐标系下的边界框。
相机候选对象: 使用Deformable-DETR加3D检测头处理多视图图像。同样初始化 N C N_C NC个物体查询 Q C 0 = { q C , i 0 } i = 1 N C , q C , i 0 ∈ R C Q_C^0=\{q_{C,i}^0\}_{i=1}^{N_C},q_{C,i}^0\in\mathbb{R}^C QC0={qC,i0}i=1NC,qC,i0∈RC及其对应的图像2D参考点 p C 0 = { p C , i 0 } i = 1 N C , p C , i 0 ∈ R 2 p_C^0=\{p_{C,i}^0\}_{i=1}^{N_C},p_{C,i}^0\in\mathbb{R}^2 pC0={pC,i0}i=1NC,pC,i0∈R2。对每个视图 v v v,使用可变形注意力机制让查询与图像特征交互。各视图的输出组成更新后的查询 Q C P = { q C , i P } i = 1 N C , q C , i P ∈ R C Q_C^P=\{q_{C,i}^P\}_{i=1}^{N_C},q_{C,i}^P\in\mathbb{R}^C QCP={qC,iP}i=1NC,qC,iP∈RC(上标 P P P表示该查询在透视图上)。这些查询作为后续融合模块的相机候选对象输入。
各模态网络结构、初始化方法、预测头的具体细节见附录。
视图变换
将相机候选对象转换到与激光雷达候选对象所处的相同空间中。由于候选对象的特征位于高维隐空间中,坐标变换是不可行的。解决方案是将相机候选对象的表达解耦,即将特征分解为类别与3D边界框的表达,其中类别具有视图不变性,而3D边界框随视图变化而变化。
首先将候选实例特征输入相机分支的预测头,输出的3D边界框记为 b P b^P bP。给定相机 v v v的外参矩阵 [ R v ∣ t v ] [R_v|t_v] [Rv∣tv]和内参矩阵 K v K_v Kv,可将边界框转换到激光雷达坐标系,记为 b L b^L bL。最后使用MLP g ( ⋅ ) g(\cdot) g(⋅)将边界框编码得到高维边界框嵌入。此外,还使用MLP m ( ⋅ ) m(\cdot) m(⋅)将拉长的相机参数编码为相机嵌入。相机嵌入会与初始的实例特征相乘并与边界框嵌入相加: q C , i L = g ( b i L ) + h ( q C , i P ⋅ m ( R v , t v , K v ) ) q_{C,i}^L=g(b^L_i)+h(q_{C,i}^P\cdot m(R_v,t_v,K_v)) qC,iL=g(biL)+h(qC,iP⋅m(Rv,tv,Kv))其中 h ( ⋅ ) h(\cdot) h(⋅)为MLP,用于编码透视图中的查询特征,在丢弃视图相关信息的同时保存与视图无关的信息。最后, Q C L = { q C , i L } Q_C^L=\{q_{C,i}^L\} QCL={qC,iL}(上标 L L L表示查询位于激光雷达空间)被自注意力从多个相机聚合信息更新查询,得到激光雷达空间下的图像实例特征 Q C Q_C QC。
稀疏候选对象融合
经过上述变换,各候选对象的特征均表达了激光雷达坐标系下的边界框和类别。接下来,将候选对象合并: Q L C = { q L C , i } i = 1 N C + N L = { f L ( q L , i ) } i = 1 N L ∪ { f C ( q C , i ) } i = 1 N C Q_{LC}=\{q_{LC,i}\}_{i=1}^{N_C+N_L}=\{f_L(q_{L,i})\}_{i=1}^{N_L}\cup\{f_C(q_{C,i})\}_{i=1}^{N_C} QLC={qLC,i}i=1NC+NL={fL(qL,i)}i=1NL∪{fC(qC,i)}i=1NC其中 f L ( ⋅ ) , f C ( ⋅ ) f_L(\cdot),f_C(\cdot) fL(⋅),fC(⋅)为可学习的投影层。然后使用自注意力模块进行融合,将各模态的检测的优点结合起来。自注意力的输出被用于最终的分类和边界框回归。
3.2 跨模态信息转移
为避免模态缺陷带来的负面转移,在并行检测分支前引入几何和语义信息转移模块,如下图所示。
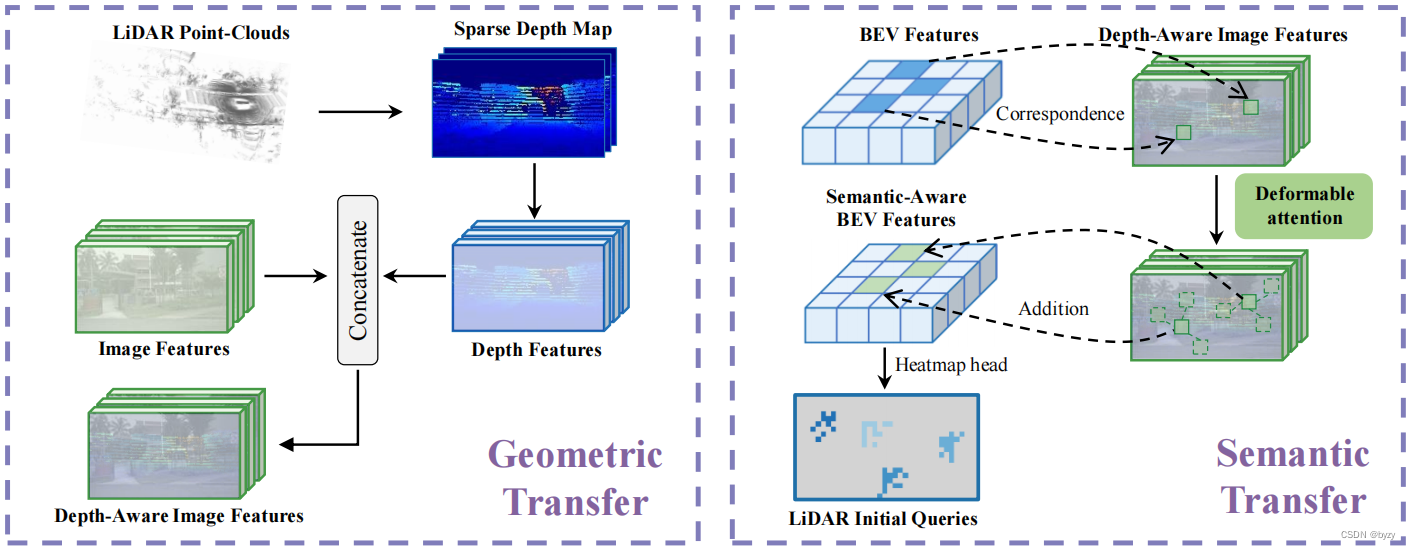
激光雷达到相机的几何转移
将激光雷达点云投影到多视图图像上获取稀疏深度图。多视图的稀疏深度图被共享编码器处理得到深度特征,并与图像特征拼接用于后续检测。这样可以补偿图像缺乏的深度信息。
图像到激光雷达的语义转移
将激光雷达点云投影到图像上获取图像特征后,使用最大池化获取多尺度特征,并通过相加与BEV特征组合。通过可变形注意力将查询与多尺度图像特征交互。更新的查询会替换BEV特征中的原始查询,得到语义感知的BEV特征,该特征会用于查询初始化。(详见附录B.1节)
3.3 目标函数
对初始化查询使用高斯Focal损失: L init = L G F o c a l ( Y ^ L , Y L ) + L GFocal ( Y ^ C , Y C ) L_\text{init}=L_{GFocal}(\hat{Y}_L,Y_L)+L_\text{GFocal}(\hat{Y}_C,Y_C) Linit=LGFocal(Y^L,YL)+LGFocal(Y^C,YC)其中 Y ^ L , Y ^ C \hat{Y}_L,\hat{Y}_C Y^L,Y^C分别为激光雷达和相机模态逐类的密集预测热图, Y L , Y C Y_L,Y_C YL,YC为相应的真值。
接着,使用匈牙利算法分别匹配各检测器的检测结果和真值,并对分类使用focal损失,对边界框回归使用L1损失。对于相机分支的检测器,真实边界框位于各视图的相机坐标系下;激光雷达检测器、视图变换后的结果与融合检测器的真实边界框位于激光雷达坐标系下。检测损失为:
L detect = γ L detect camera + L detect trans + L detect LiDAR + L detect fusion L_\text{detect}=\gamma L_\text{detect}^\text{camera}+L_\text{detect}^\text{trans}+L_\text{detect}^\text{LiDAR}+L_\text{detect}^\text{fusion} Ldetect=γLdetectcamera+Ldetecttrans+LdetectLiDAR+Ldetectfusion
整个模型的损失函数为 L = α L init + β L detect L=\alpha L_\text{init}+\beta L_\text{detect} L=αLinit+βLdetect
4.实验
4.2 实施细节
分别对激光雷达与图像进行独立的数据增广,其中激光雷达使用随机旋转、缩放、平移和翻转;图像使用随机缩放和水平翻转。
训练时先训练激光雷达检测分支(结果作为激光雷达单一模态的baseline),然后固定参数训练整个模型。还使用了CBGS以平衡类别分布。
4.3 结果与比较
测试时,未使用数据增广和模型集成。实验表明SparseFusion的性能能超过激光雷达baseline和其余融合方法,且速度也能达到融合方法中的最快。
4.4 分析
性能分解
从模型中各检测器的结果可见:
-
SparseFusion中激光雷达检测器的性能超过了激光雷达baseline,因为语义转移弥补了点云的缺陷。
-
SparseFusion中的图像检测器在仅使用一个解码层的情况下,性能也能大幅超过SotA方法PETR(含6个解码层),这可归因于几何转移。
-
通过聚合多视图信息,视图变换轻微提高了检测的性能。
这些高精度检测结果表明,在模态融合时不会导致负面转移。
各模态目标召回率
定义:若某查询对应的检测结果与真实边界框的距离小于阈值,且类别正确,则称该物体被召回。
结果表明,虽然绝大多数情况下,激光雷达检测器的召回数更高,但对某些类别和远距离物体,相机检测器也有较高的召回率。
4.5 消融研究
稀疏融合策略
将自注意力融合方法替换为下面三种方案:
- 不进行实例交叉融合,直接输入MLP解码;
- 将激光雷达候选对象作为查询,将图像候选对象作为键/值,进行交叉注意力融合;
- 利用最优传输,学习相机候选对象到激光雷达候选对象的分布变换。然后通过通道拼接两个模态的候选对象进行融合(详见附录)。
实验表明,MLP方法没有进行跨实例和跨模态交互;交叉注意力不能完全利用图像分支补偿激光雷达的缺陷;最优传输方法不能学习到各模态实例特征的对应关系。因此,自注意力融合方法简单而最有效。
信息转移
去掉几何转移或语义转移均会导致性能下降,且去掉后者的性能下降更显著。这表明各模态的缺点的确会导致负转移,且本文的信息转移方式(尤其是语义转移)能解决这一问题。
视图变换
去掉视图变换模块,直接使用自注意力融合各模态的候选对象特征,性能会略有下降。
并行检测器
本文还设计了顺序检测的方法,先进行激光雷达检测,再进行相机检测:相机检测器继承激光雷达检测器的输出查询。具体考虑两种变体:
- 使用激光雷达检测器输出查询的3D位置和实例特征作为相机的初始查询;
- 仅使用3D位置,从图像初始化查询特征。
实验表明,上述方法均会带来性能的下降,表明并行检测器的优势。
附录
A.额外实验
A.1 逐类结果
相比激光雷达baseline,图像模态的引入能对所有类别带来性能提升,且能很好地区分形状相似的类别(如摩托车和自行车)。
A.3 实验细节
稀疏融合的最优传输: 将激光雷达候选对象的分布建模如下: p L ( q L , i ) = s L , i ∑ i = 1 N L s L , i , i = 1 , 2 , ⋯ , N L p_L(q_{L,i})=\frac{s_{L,i}}{\sum_{i=1}^{N_L}s_{L,i}},i=1,2,\cdots,N_L pL(qL,i)=∑i=1NLsL,isL,i,i=1,2,⋯,NL其中 s L , i s_{L,i} sL,i是激光雷达检测器第 i i i个实例的分类置信度。类似地建模图像候选对象的分布: p C ( q C , i ) = s C , i ∑ i = 1 N C s C , i , i = 1 , 2 , ⋯ , N C p_C(q_{C,i})=\frac{s_{C,i}}{\sum_{i=1}^{N_C}s_{C,i}},i=1,2,\cdots,N_C pC(qC,i)=∑i=1NCsC,isC,i,i=1,2,⋯,NC其中 s C , i s_{C,i} sC,i是相机检测器视图变换后第 i i i个实例的分类置信度。建立代价矩阵 C = [ c i j ] , i = 1 , 2 , ⋯ , N L , j = 1 , 2 , ⋯ , N C C=[c_{ij}],i=1,2,\cdots,N_L,j=1,2,\cdots,N_C C=[cij],i=1,2,⋯,NL,j=1,2,⋯,NC,其中 c i j c_{ij} cij是第 i i i个激光雷达实例和第 j j j个相机实例在BEV平面上的距离。使用IPOT算法求解 p L ( q L , i ) p_L(q_{L,i}) pL(qL,i)和 p C ( q C , i ) p_C(q_{C,i}) pC(qC,i)之间的最优传输问题,输出最优传输计划 T ∗ T^* T∗: T ∗ = arg min T ∈ R + N L × N C < C , T > , s . t . T ⋅ 1 N C = p L , T T ⋅ 1 N L = p C T^*=\argmin_{T\in R_+^{N_L\times N_C}}<C,T>,\ \ \ \ \ \ s.t.\ \ \ \ T\cdot\mathbf{1}_{N_C}=p_L,T^T\cdot\mathbf{1}_{N_L}=p_C T∗=T∈R+NL×NCargmin<C,T>, s.t. T⋅1NC=pL,TT⋅1NL=pC且 T T T的每一行被归一化( T ^ i j = T i j / ∑ j = 1 N C T i j \hat{T}_{ij}=T_{ij}/\sum_{j=1}^{N_C}T_{ij} T^ij=Tij/∑j=1NCTij)。然后将激光雷达候选对象 Q L Q_L QL与用 T ^ \hat{T} T^加权的相机候选对象 Q C Q_C QC沿通道维度拼接,并输入前馈网络得到 N L N_L NL个融合的实例特征。
B.结构细节
B.1 网络结构
激光雷达检测器: 初始化的激光雷达查询 Q L 0 Q_L^0 QL0首先输入自注意力模块,然后与激光雷达的BEV特征进行交叉注意力交互,并将输出通过前馈网络得到激光雷达候选对象 Q L Q_L QL。自注意力和交叉注意力均为查询、键和值添加了可学习位置编码(位置编码器的输入为相应的BEV坐标)。最后,激光雷达视图检测头使用 Q L Q_L QL预测激光雷达坐标系下的边界框及其类别。
图像检测器: 初始化的图像查询 Q C 0 Q_C^0 QC0首先输入自注意力模块,然后与多尺度图像特征进行可变形注意力交互。可变形注意力中,查询仅与相应视图的图像特征交互。输出通过前馈网络得到透视图的相机候选对象 Q C P Q_C^P QCP。同样地,自注意力和可变形注意力均为查询、键和值添加了可学习位置编码(位置编码器的输入为相应视图的图像坐标)。最后,透视图检测头使用 Q C P Q_C^P QCP预测相机坐标系下的边界框及其类别。
视图变换: 视图变换包含两个部分,即特征投影和多视图聚合。特征投影就是将相机参数和投影后的边界框进行编码,并与原始实例特征组合,见3.1节变换部分的公式。多视图聚合基于自注意力实现,即将所有视图的相机实例特征 Q C L = { q C , i L } i = 1 N C Q_C^L=\{q_{C,i}^L\}_{i=1}^{N_C} QCL={qC,iL}i=1NC输入自注意力和前馈网络中。自注意力的位置编码使用了视图变换前的图像坐标和视图变换后的BEV坐标。更新后的查询作为相机候选对象 Q C Q_C QC。同样使用一个激光雷达视图检测头预测激光雷达坐标系下的边界框及其类别。
融合分支: 可学习的投影层 f L ( ⋅ ) , f C ( ⋅ ) f_L(\cdot),f_C(\cdot) fL(⋅),fC(⋅)为FC层加LayerNorm。合并后的候选对象 Q L C Q_{LC} QLC被自注意力和前馈网络处理,得到融合的实例特征 Q F Q_F QF。位置编码使用BEV坐标学习得到。最后,使用一个激光雷达视图检测头预测激光雷达坐标系下的边界框及其类别。
几何转移: 将激光雷达点云投影到多视图图像上得到稀疏深度图后,与相应视图的图像特征组合,算法如下:
输入:视图 v v v的多尺度图像特征 F C , v = [ F C , v l ] l = 1 L F_{C,v}=[F_{C,v}^l]_{l=1}^L FC,v=[FC,vl]l=1L和稀疏深度图 D v D_v Dv。
输出:视图 v v v的多尺度深度感知图像特征图 F ^ C , v = [ F ^ C , v l ] l = 1 L \hat{F}_{C,v}=[\hat{F}_{C,v}^l]_{l=1}^L F^C,v=[F^C,vl]l=1L。
1. F D = Stem ( D v ) F_D=\text{Stem}(D_v) FD=Stem(Dv)
2. F ^ C , v = [ ] \hat{F}_{C,v}=[] F^C,v=[]
3. for l = 1 , 2 , ⋯ , L l=1,2,\cdots,L l=1,2,⋯,L do
4. F D = Residual-Block l ( F D ) F_D=\text{Residual-Block}_l(F_D) FD=Residual-Blockl(FD)
5. F D = Concatenate ( F D , F C , v l ) F_D=\text{Concatenate}(F_D,F_{C,v}^l) FD=Concatenate(FD,FC,vl) # 沿通道维度拼接
6. F D = Conv 3 × 3 l ( F D ) F_D=\text{Conv}_{3\times3}^l(F_D) FD=Conv3×3l(FD)
7. 将 F D F_D FD作为 F ^ C , v l \hat{F}_{C,v}^l F^C,vl添加到列表 F ^ C , v \hat{F}_{C,v} F^C,v中
8. return F ^ C , v \hat{F}_{C,v} F^C,v
其中 Stem ( ⋅ ) \text{Stem}(\cdot) Stem(⋅)为 3 × 3 3\times3 3×3卷积+BatchNorm+ReLU; Residual-Block ( ⋅ ) \text{Residual-Block}(\cdot) Residual-Block(⋅)是残差块,下采样比例为2。注意该算法是使用相同的网络参数,独立地在各视图上进行的。
语义转移: 给定密集BEV特征 F L ∈ R H × W × C F_L\in\mathbb{R}^{H\times W\times C} FL∈RH×W×C,仅有很少的位置被激光雷达点覆盖,对于被激光雷达点覆盖的 ( x j , y j ) (x_j,y_j) (xj,yj)位置( x j ∈ { 1 , 2 , ⋯ , H } , y ∈ { 1 , 2 , ⋯ , W } x_j\in\{1,2,\cdots,H\},y\in\{1,2,\cdots,W\} xj∈{1,2,⋯,H},y∈{1,2,⋯,W}),取该柱体点高度的中值 z j z_j zj,并将 ( x j , y j , z j ) (x_j,y_j,z_j) (xj,yj,zj)投影到多视图图像上,获取相应位置的图像特征(使用最大池化聚合多尺度特征),与BEV ( x j , y j ) (x_j,y_j) (xj,yj)处的特征相加。相加后的特征作为查询,使用可变形注意力和前馈网络与多尺度图像特征再次交互(各视图分别进行)。位置编码使用图像2D坐标。若 ( x j , y j , z j ) (x_j,y_j,z_j) (xj,yj,zj)能投影到多个视图,则使用最大池化从多视图聚合更新查询。更新后的查询会替代BEV ( x j , y j ) (x_j,y_j) (xj,yj)处的原始特征,得到语义感知的BEV特征 F ^ L \hat{F}_L F^L,用于激光雷达检测器的查询初始化。
B.2 检测头
本文使用了两种检测头,即激光雷达视图检测头和透视图检测头。
透视图检测头: 用于相机检测器。使用6个独立的MLP,分别预测类别、图像上的2D位置偏移量、物体深度、3D边界框尺寸、绕垂直轴(相机 Y Y Y轴)的旋转角(正余弦表达)和水平面2D速度(相机的 X O Z XOZ XOZ平面)。
透视图检测头: 用于激光雷达检测器、视图变换、融合分支。同样使用6个独立的MLP,分别预测类别、BEV上的2D位置偏移量、物体中心高度、3D边界框尺寸、绕垂直轴(激光雷达 Z Z Z轴)的旋转角(正余弦表达)和水平面2D速度(激光雷达的 X O Y XOY XOY平面)。
B.3 查询初始化
激光雷达检测器的初始化: 将3D边界框的中心投影到BEV上,使用高斯核生成热图 Y ∈ [ 0 , 1 ] H × W × K Y\in[0,1]^{H\times W\times K} Y∈[0,1]H×W×K( K K K为类别数),且
Y x , y , k i = exp ( x − c x , i L ) 2 + ( y − c y , i L ) 2 2 σ i 2 Y_{x,y,k_i}=\exp\frac{(x-c_{x,i}^L)^2+(y-c_{y,i}^L)^2}{2\sigma_i^2} Yx,y,ki=exp2σi2(x−cx,iL)2+(y−cy,iL)2其中 k i k_i ki为第 i i i个物体的类别, ( c x , i L , c y , i L ) (c_{x,i}^L,c_{y,i}^L) (cx,iL,cy,iL)为BEV上的中心坐标, σ i \sigma_i σi是与物体大小相关的标准差。多个高斯核覆盖时使用每个位置的最大值。预测热图 Y ^ \hat{Y} Y^上最高置信度的 N L N_L NL个位置 p L , i 0 p^0_{L,i} pL,i0和相应的类别 { k i } i = 1 N L \{k_i\}_{i=1}^{N_L} {ki}i=1NL被取出,并从语义增强的BEV特征图 F ^ L \hat{F}_L F^L中获取特征,与可学习的类别编码 { e k i L } i = 1 N L \{e_{k_i}^L\}_{i=1}^{N_L} {ekiL}i=1NL相加得到初始激光雷达查询特征 Q L 0 Q_L^0 QL0。
相机检测器的初始化: 将3D边界框的中心投影到多视图图像上,并根据物体大小确定投影到哪一个尺度的特征图上。投影时,设定多尺度的边界框大小阈值 { T i } i = 1 L \{T_i\}_{i=1}^{L} {Ti}i=1L,其中 T 1 = 0 , T L = + ∞ T_1=0,T_L=+\infty T1=0,TL=+∞,若边界框长和宽中的最大值位于 T i T_i Ti和第 T i + 1 T_{i+1} Ti+1之间,则将该物体分配给第 i i i尺度。之后,类似激光雷达分支,为每个尺度生成热图。从多视图、多尺度热图中获得最高置信度的位置 p C 0 p_C^0 pC0和相应的类别 { k i } i = 1 N C \{k_i\}_{i=1}^{N_C} {ki}i=1NC后,从深度感知的图像特征 F ^ C \hat{F}_C F^C中采样特征,并与类别编码 { e k i C } i = 1 N C \{e_{k_i}^C\}_{i=1}^{N_C} {ekiC}i=1NC相加得到初始相机查询特征 Q C 0 Q_C^0 QC0。
这篇关于【论文笔记】SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




