sparsefusion专题
【论文笔记】SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection
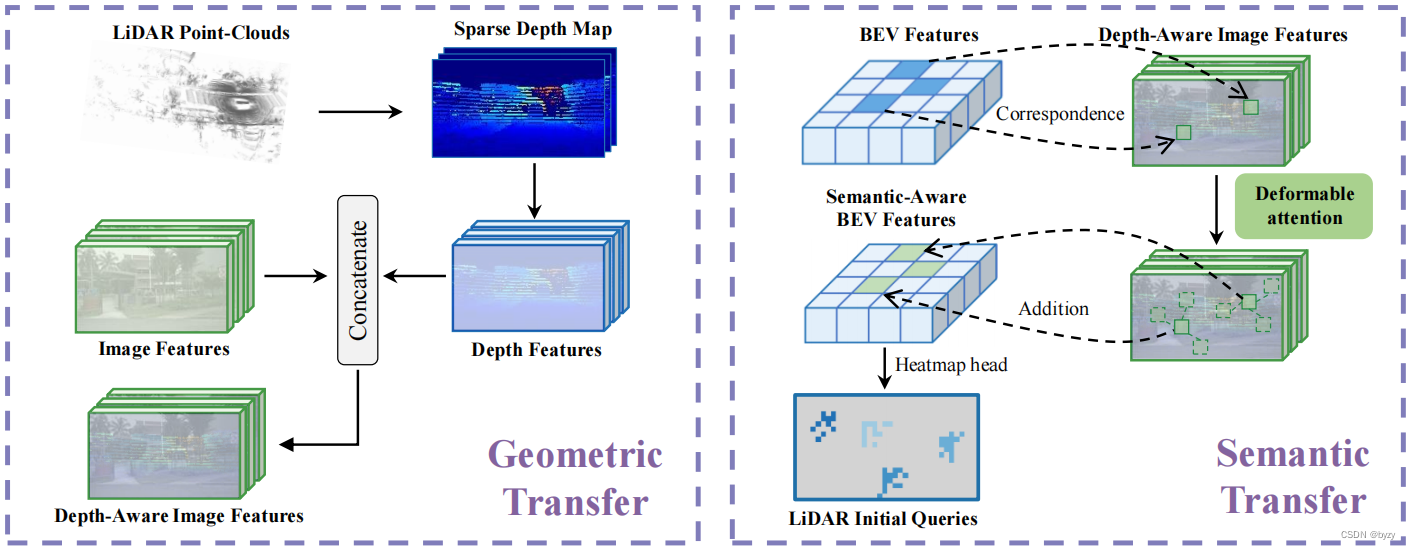
原文链接:https://arxiv.org/abs/2304.14340 1.引言 目前的3D目标检测工作都使用模态的密集表达(如BEV、体素、点云),但由于我们只对实例/物体感兴趣,这种密集表达是冗余的。此外,背景噪声对检测有害,且将多模态对齐到同一空间很耗时。 相反,稀疏表达很高效且能达到SotA性能。通常,使用稀疏表达的方法使用物体查询表示物体或实例,并与原始图像和点云特征交互