本文主要是介绍Nat. Mach. Intell 2022 | TransMut+:基于transformer的用于预测peptide–HLA class I binding 并优化疫苗设计中的突变多肽,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文标题:A transformer-based model to predict peptide–HLA class I binding and optimize mutated peptides for vaccine design
论文地址:A transformer-based model to predict peptide–HLA class I binding and optimize mutated peptides for vaccine design | Nature Machine Intelligence
Webserver: https://issubmission.sjtu.edu.cn/TransPHLA-AOMP/index.html
Datasets: https://github.com/a96123155/TransPHLA-AOMP/tree/master/Dataset
Code: https://github.com/a96123155/TransPHLA-AOMP
一、问题
人白细胞抗原(Human leukocyte antigen,HLA)能够识别并结合外源肽,将其呈递给特定的免疫细胞,然后启动免疫反应,目前还缺乏一种自动程序来优化与目标HLA等位基因有更高亲和力的突变肽。
只有当肽被呈递给外细胞表面的HLA分子,形成peptide - HLA (pHLA)复合物,然后被T细胞识别时,才能触发强大的免疫反应。
HLA一般分为两类:HLA I类(HLA-I)和HLA II类(HLA-II)
HLA-I由3个I位点编码,在所有有核细胞表面表达,而HLA-II只能在专业抗原呈递细胞中表达。
论文主要关注HLA-I分子(以下简称HLA)。HLA主要结合长度为8-10个氨基酸的短肽,因为结合槽的两端被保守的酪氨酸残基阻断,其中以9-mer肽最为常见。然后,其中一些pHLA被呈递到细胞表面供CD8+ T细胞识别。已鉴定出含有11-14个氨基酸的肽结合物。考虑到该方法的综合适用性,研究纳入了长度为8-14个氨基酸的肽。
由于HLA分子在人群中具有高度的特异性和多态性,因此只有一小部分肽能被呈递到HLA分子中。确定在个体的HLA类型中选择哪些肽显示对表位选择至关重要。实现这一目标的第一步是验证肽和HLA等位基因之间的亲和力(多肽与其结合的HLA等位基因之间的亲和力与其能否被呈现密切相关)。现有的方法虽然对含有9个氨基酸的肽段的预测精度高达90%,但对其他长度的肽段的预测能力仍不令人满意。因为9-mer比长度为13和14的肽有更多的pHLA结合数据用于训练。
肽疫苗设计的原则是抗原肽与特定HLA结合形成肽- HLA - TCR复合物,从而引发t细胞免疫应答。理论上,抗原肽应该选择性地与高亲和力的特定HLA等位基因结合。
识别新抗原的过程:首先,建立高通量测序技术和生物信息学pipelines来表征原发肿瘤的非同义突变,然后开发计算方法来预测突变肽与HLA等位基因的结合概率。该过程相对复杂。因此,自动优化突变肽(automatically optimized mutated peptides, AOMP)程序的开发将是新抗原设计领域的一个巨大突破。
二、模型方法
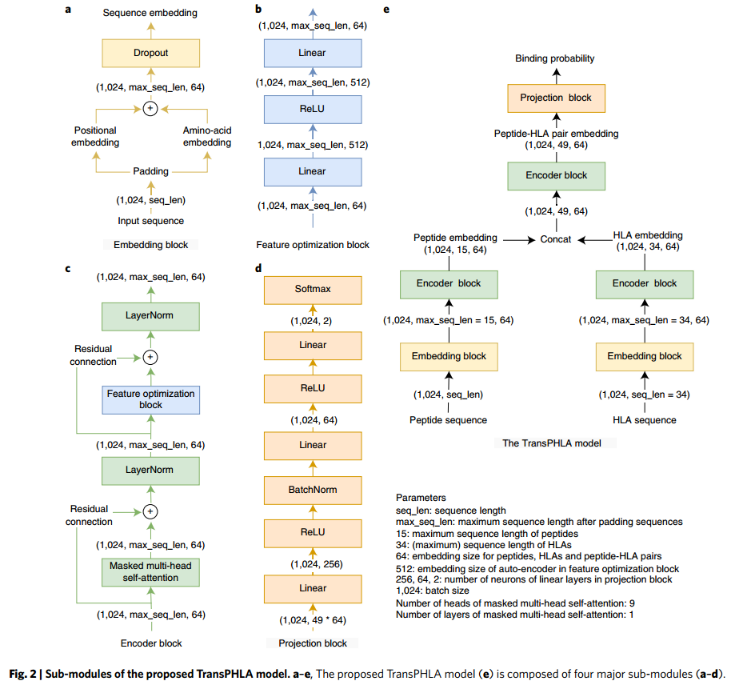
1、Model
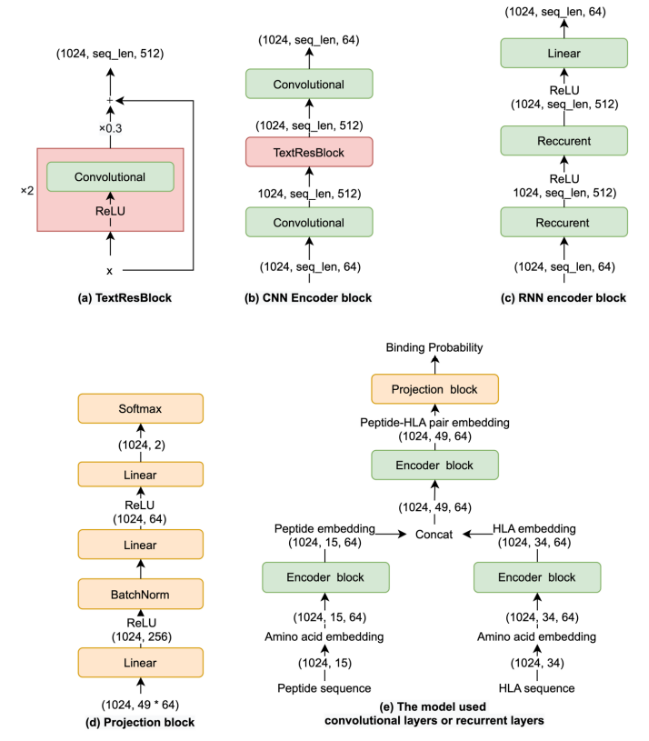
模型由四个子模块组成(就是一个transformer):a. Sequence Embedding ; c.Encoder Block; b.Feature optimization block; d.Projection block;
还开发了一个AOMP程序,用于基于TransPHLA获得的注意机制的肽疫苗设计。
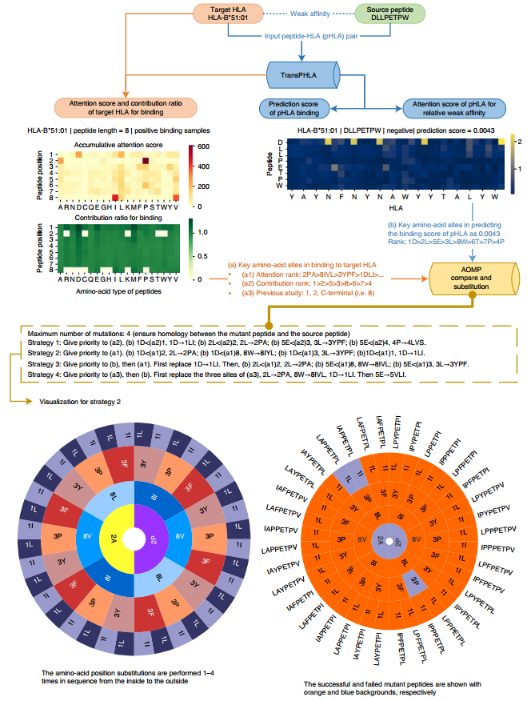
当用户提供包含源肽和目标HLA等位基因的一对时,AOMP程序可以搜索与目标HLA等位基因亲和力较高且不超过4个突变位置的突变肽。该程序既保证突变肽与靶HLA等位基因的亲和性,又保证突变肽与源肽的同源性,从而触发交叉免疫。使用两种策略测试了所有366种不同HLA和肽结合物长度的组合。
第一种策略为每个组合随机选择10个由TransPHLA正确预测的阴性P-HLA,共选择3,660个true negative P-HLA,3633个源肽成功找到了与HLA等位基因结合的优化突变肽,其中93.4%的源肽被IEDB14推荐的方法验证,有88.8%与其源肽同源性超过80%(1-2个突变位点)。
另一种策略只考虑由TransPHLA预测的阴性P-HLA,而不考虑ground-truth标签。3635个源肽成功找到了与HLA等位基因结合的优化突变肽,其中93.7%的源肽被IEDB14推荐的方法验证,有89.5%与其源肽同源性超过80%(1-2个突变位点),这为疫苗设计提供前景。
2、Dataset
pHLA结合数据(正样本)来自Anthem(https://github.com/17shutao/Anthem/ tree/master/Dataset)下载。负样本的产生方式与之前的研究类似:对于每个结合体长度和每个HLA等位基因,负样本的肽是从IEDB HLA免疫肽组的源蛋白中随机选择的序列片段。虽然可能会产生假阴性肽,但这种肽的可能性和比例都很低,可以忽略。
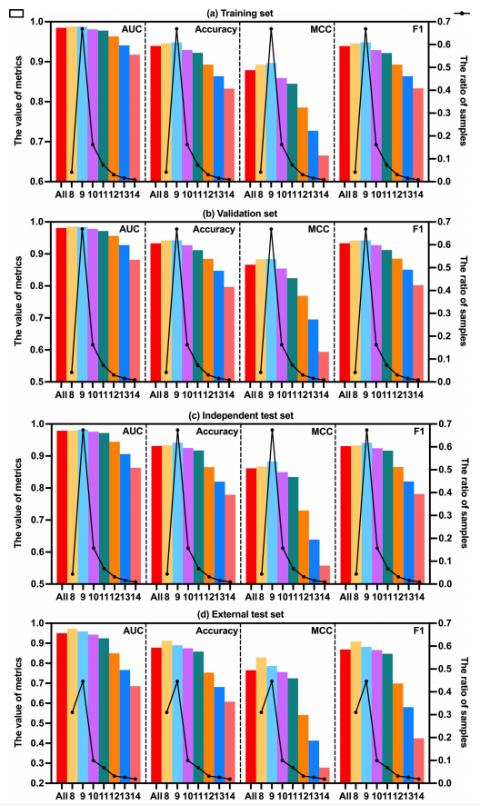
训练和测试集的数据来源相同:(1)四个公共HLA结合数据库(IEDB, EPIMHC, MHCBN和SYFPEITHI),(2)先前发表的研究中通过质谱鉴定的同种异体特异性HLA配体,(3)来自其他pHLA结合预测工具训练数据集的肽结合体。外部测试集通过Anthem进行实验验证。检查并删除一些错误或重复的样品。不同数据集的性能与样本数量比较(柱体为指标,曲线为数量占比)
3、Performance evaluation metrics.
ACC、MCC、F1

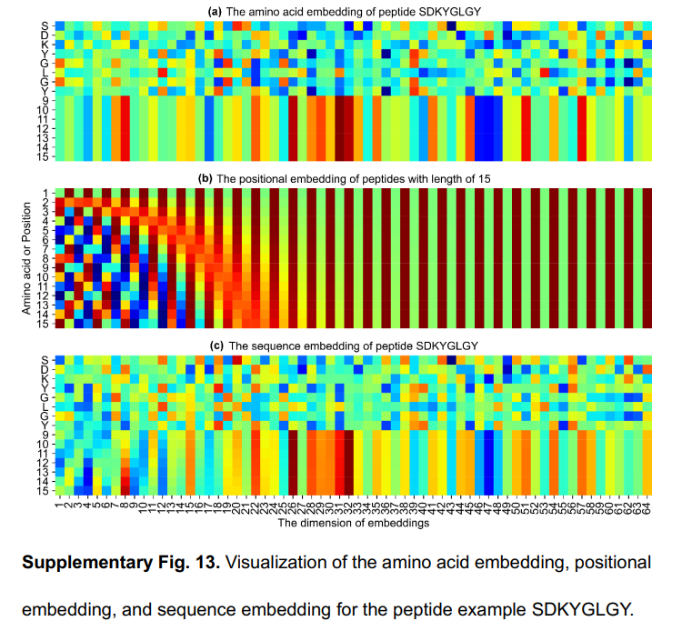
肽和HLA等位基因序列分别填充到最大长度15和34,以处理可变的输入长度。然后使用字符embedding模型为每个氨基酸创建一个独特的embedding,维数定义为dX。以肽SDKYGLGY为例,其长度为8。6种不同氨基酸的embedding方式不同,填充padding方式相同。最后,将氨基酸嵌入和位置嵌入相加,得到序列嵌入(c):
还尝试了RNN、CNN(transformer性能最好):
三、AOMP program
旨在基于对特定HLA等位基因亲和力较弱的特定源肽寻找高亲和力的突变肽。
根据TransPHLA获得的注意力得分设计了四种定向突变策略(实列中提到)。注意力得分不仅代表了pHLA结合的模式,还揭示了肽序列上对与目标HLA等位基因结合或不结合重要的关键氨基酸位点。为了有效的疫苗设计,我们还考虑了突变肽和源肽的同源性(通过序列相似度计算突变肽与源肽之间的同源性),实验表明,用Python中的difflib模块计算的相似度与blast结果非常接近。1个、2个、3个和4个氨基酸位点的同源性平均突变率分别为90%、80%、70%和61%。因此,我们将源肽氨基酸位点的突变数量限制在不超过4个。
对于366个HLA-肽长度组合中的每一个,在每个肽位置建立了20个氨基酸的结合贡献矩阵。为了适应新的或未知的HLA -肽长度组合,建立一个通用的结合贡献矩阵(366+1)。在web服务器上提供了这367个贡献矩阵及其可视化热图。另一方面,在预测亲和力相对较弱的pHLA时,利用TransPHLA获得的注意力评分来计算肽上各氨基酸位点的贡献矩阵。如果用户需要,还提供了pHLA的注意力得分热图。
计算两个贡献率矩阵。矩阵元素值越大,对应的氨基酸位点结合或不结合越关键。直观地说,由于氨基酸位点对非结合预测的贡献更大,如果用其他对结合预测贡献更大的氨基酸取代它们,那么突变肽更有可能与目标HLA等位基因具有更高的亲和力.
主要思路是比较源肽上对弱亲和力影响较大的氨基酸位点和靶HLA-肽长度上对高亲和力影响较大的氨基酸位点。然后根据比较结果进行相应的氨基酸替换。其过程如下:
(1)预测源肽与目标HLA的结合评分;(2)根据自注意机制找到一些最重要的氨基酸位点;(3)用一些可能对结合预测更有帮助的氨基酸取代弱亲和pHLA的这些重要位点;(4)选择一些最佳候选突变进行评价。
对于源肽和目标HLA等位基因(特定的pHLA),将四种策略产生的突变肽合并并去除重复。然后,TransPHLA筛选并保留能够与目标HLA等位基因结合的突变肽。
示例:
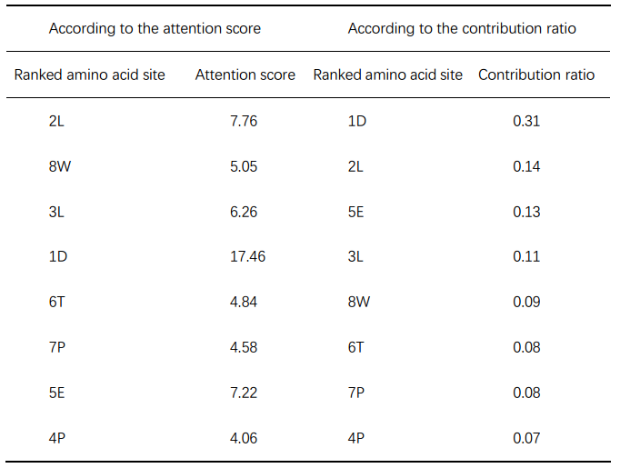
HLA- B*51:01(即目标HLA)和DLLPETPW(即源肽)组成,经TransPHLA预测为阴性非结合样本,预测评分为0.0043。对目标HLA、肽长为8的阳性样本,获得TransPHLA正确分类的注意评分矩阵。根据注意评分矩阵,计算HLA-B*51:01在8个不同肽位(即总共160个氨基酸位点)的20个氨基酸结合的两个贡献矩阵。图(a)显示了结合的累积注意得分矩阵,它描述了20个氨基酸在不同肽位的累积注意得分,每个元素代表了氨基酸位点对结合的贡献。图(b)显示了结合的贡献比矩阵,它描述了特定氨基酸位点对肽的所有160个氨基酸位点的相对贡献比。利用TransPHLA预测HLA- B*51:01(即目标HLA)和DLLPETPW(即源肽),得到注意力评分矩阵(c)。由于AOMP突变任务的源肽和目标HLA通常是低亲和的,而通过AOMP的目的是寻找与目标HLA亲和度较高的突变肽,因此将该矩阵作为与目标HLA低亲和度的贡献矩阵。此外,还计算了肽上每个氨基酸位点对低亲和力的贡献比例(d)。
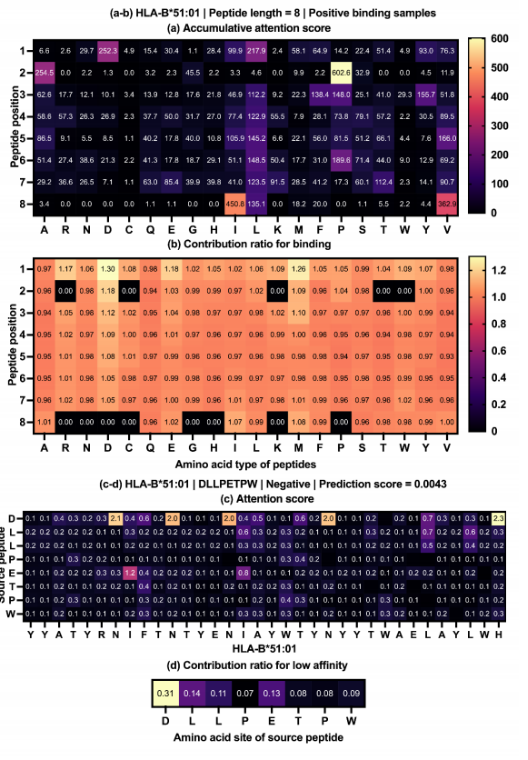
由于氨基酸位点对低亲和力预测的贡献更大,如果用其他对结合预测贡献更大的氨基酸取代它们,那么突变肽更有可能与目标HLA具有更好的亲和力。对肽的关键结合氨基酸位点进行排序(表3):
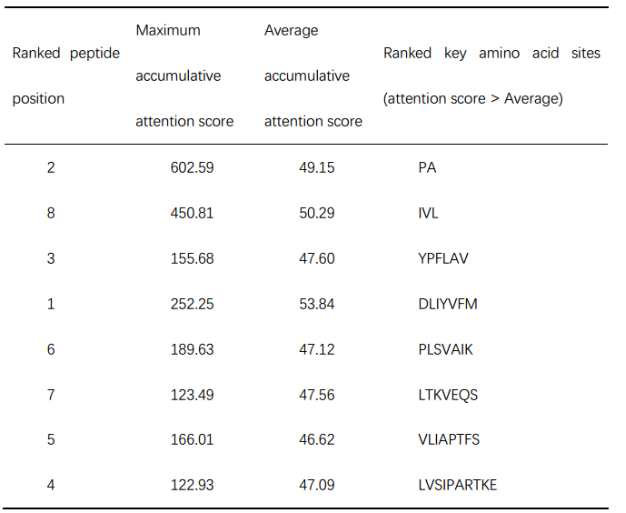
基于贡献比矩阵的关键氨基酸位点的汇总。前4列为HLA-B*51:01的贡献比矩阵,肽长为8,描述了结合的关键氨基酸位点(表4):
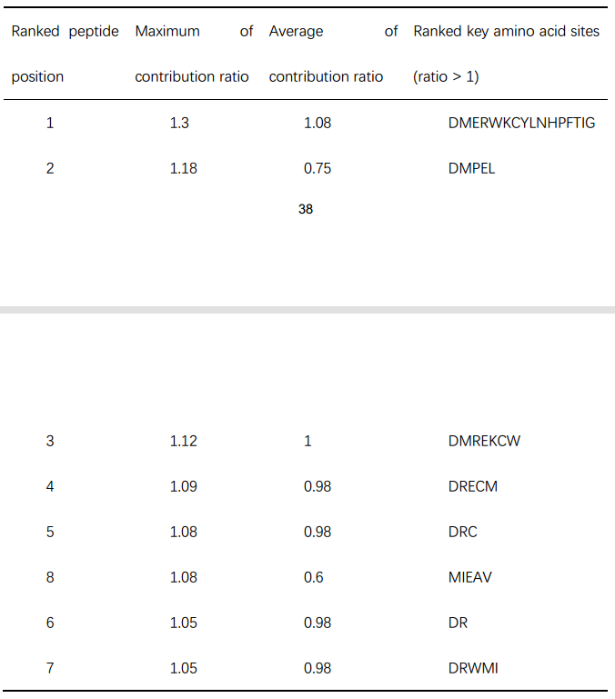
根据源肽DLLPETPW对HLA-B*51:01低亲和力的总关注评分和贡献比排序的氨基酸位点汇总(表5):
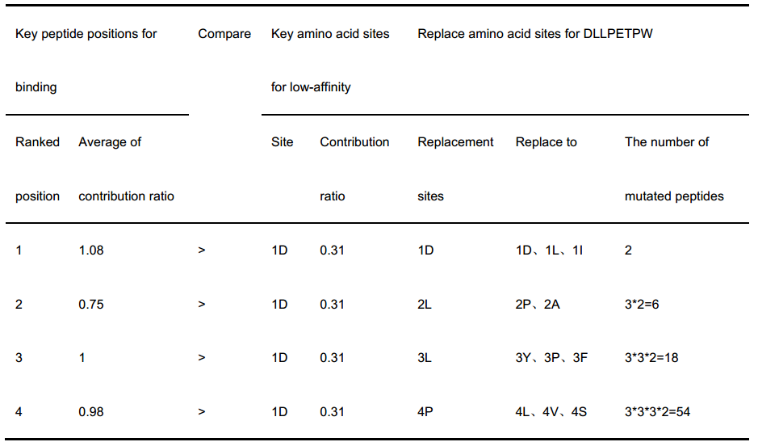
在两种贡献率矩阵上比较了低亲和力和结合的关键肽位置。确定肽的具体替代位置后,使用累积注意评分最高的3个氨基酸位点进行结合替代。根据表4提供的贡献率矩阵对关键结合位点进行排序,首先选择排名为1的1-st位,该位对HLA-B*51:01结合的平均贡献率为1.08。然后,根据表3,根据累积注意评分矩阵,得到结合1- 1位上的关键氨基酸,包括1D、1L、1I、1Y、1V、1F和1M。比较(1)DLLPETPW上最关键的低亲和力1D位点的贡献比为0.31,(2)与HLA-B*51:01结合的1- 1肽位的平均贡献比为1.08 。由于0.31 < 1.08,根据结合的累积注意评分,将DLLPETPW中的1D位点替换为1- 1肽位的前3个关键氨基酸,分别为1D、1L、1I(表a第一行)
(1) 根据负样本注意力贡献最大位置,选择肽的关键结合氨基酸位点(表3位置attention score>average的氨基酸),然后图a中选择正样本中对应位置氨基酸对于预测贡献度前3个进行可选替换。然后根据负样本注意力贡献次大位置,同样步骤,一共进行4次突变。一共有54个突变。
(2)第一种策略使用两个贡献率矩阵比较低亲和和结合关键位点的贡献率,确定需要突变的位点。相比之下,第二种策略使用图(a)和图(c)两个注意力得分矩阵来选择需要突变的位置,其余步骤与策略1相同。
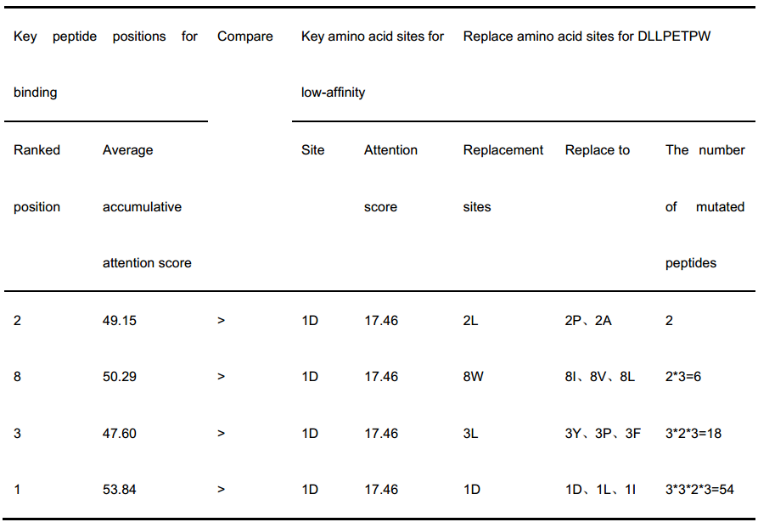
(3)在大多数情况下,前两种策略是binding的累计注意得分和贡献率大于低亲和力的注意得分和贡献率(所有正样本均被TransPHLA正确预测,而低亲和力的注意评分矩阵仅针对源肽靶HLA样本),策略3的第一次突变直接替换了源肽上最关键的低亲和力位点,即首先将DLLPETPW的1D位点替换为1D, 1L, 1T。然后,使用策略2进行剩余的三个突变步骤。
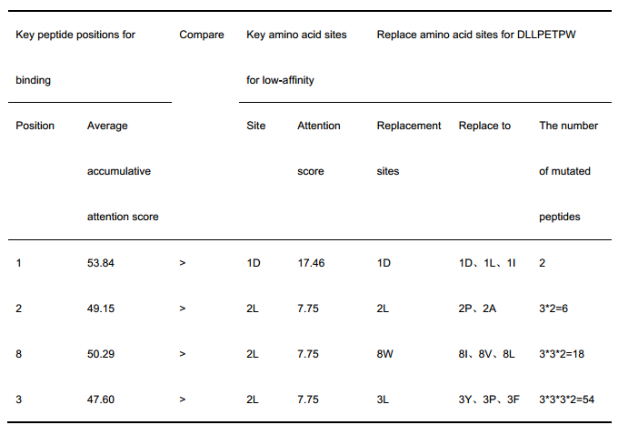
(4)现有研究都证实了肽的第2位(锚位点)、最后一个位置和第一个位置是与HLA结合的关键位点。第四种策略优先替换这三个位点,然后替换尚未发生突变的最关键的低亲和位点。因此优先替换这三个位点,然后替换尚未发生突变的最关键的低亲和位点。
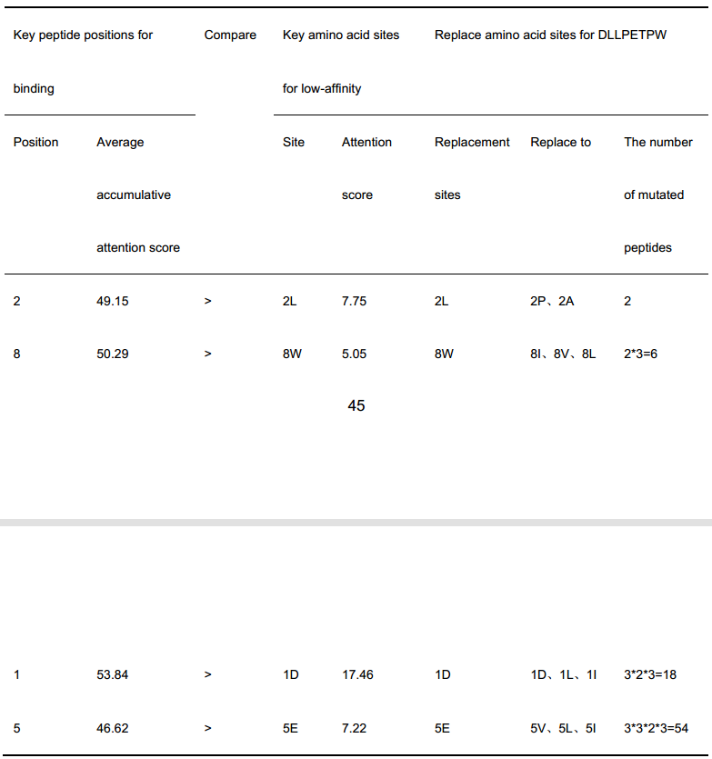
综合以上4种策略,DLLPETPW共产生206个不同的突变肽。
四、实验
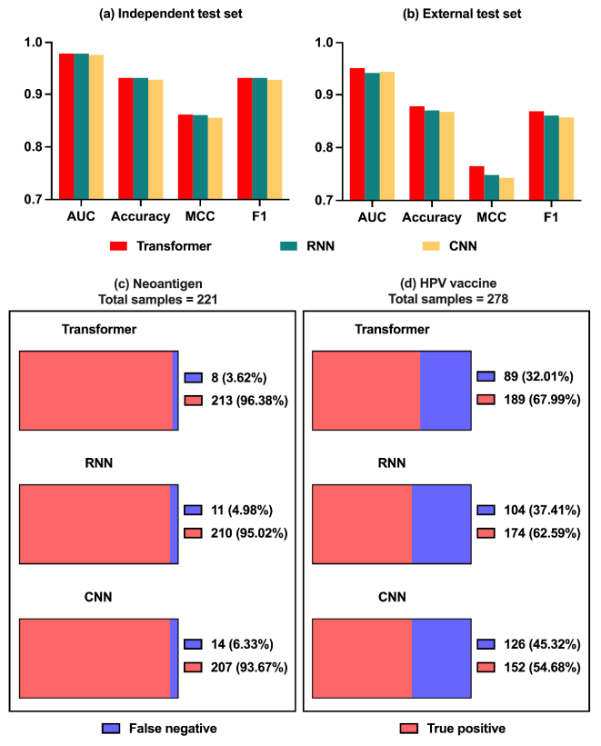
1、Comparison of TransPHLA with existing methods.
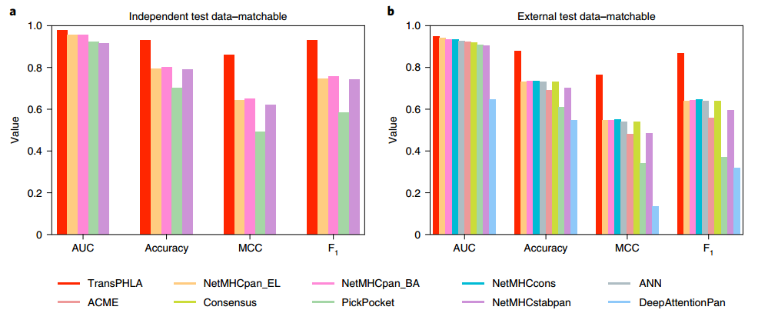
在图a、b中,不同方法的性能比较所使用的数据都是一致的,因此可以比较公平的预测性能。
在图4c、d中,两种方法预测的HLA等位基因和肽长度不同。
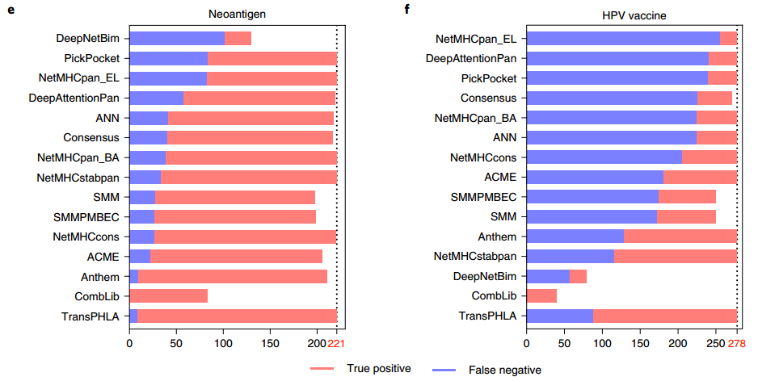
为了鉴定新抗原,收集近期工作中非小细胞肺癌、黑色素瘤、卵巢癌和胰腺癌的新抗原数据,包括221个实验验证的pHLA结合物。不同方法对这些数据的对比结果如图e所示。这些结果表明,TransPHLA能够筛选出96.4%的新抗原。虽然CombLib达到了100%的准确度,但它只支持9-mer肽,这限制了它的应用。其余10种方法的性能低于TransPHLA,并且可能受到可预测的hla或肽长度的限制。先前的研究从HPV16蛋白E6和E7中获得278个实验验证的pHLA结合物,由8-11-mer肽组成。不同方法对这些数据的对比结果如图f所示。虽然TransPHLA的筛选率只有68%,但它仍然比其他方法具有更高的性能:
2、TransPHLA uncovers the underlying patterns of pHLA binding.
通过注意力分数来探讨pHLA的约束规则。有证据表明,该肽的c端、n端和锚位点是与HLA结合的关键位点,它们总是位于肽序列的第一、最后和第二位置。确认这些位置的注意力得分:

分析阳性和阴性样品上的氨基酸类型对不同肽位结合和不结合的贡献(图b)。结果表明,pHLA 的结合和不结合受到肽的不同成分的影响。此外,分析了20个氨基酸在不同肽位对所有366个HLA -肽长度组合的结合或不结合的影响:
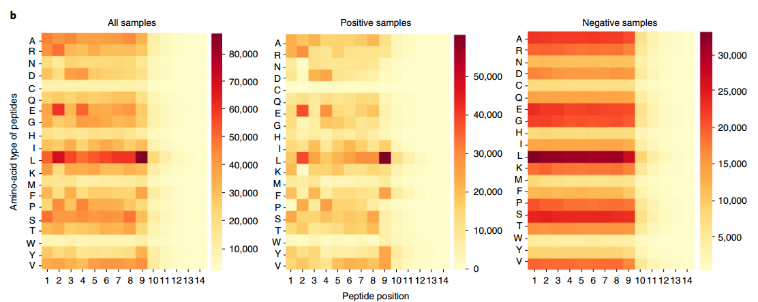
TransPHLA在不同肽位的氨基酸类型上发现了与先前研究相似的模式。对于HLA-A11:01, TransPHLA识别了第9位(第9个K)上有K (Lys)的肽的锚定残基,对于HLA-B40:01,关键残基-第2个E (Glu)和第9个L (Leu) -被成功地鉴定出来。
对于HLA-B57:03,疏水残基通常形成结合袋,通过第9个L、第9个F (Phe)和第9个W (Trp)确定了这种偏好,这与PDB 2BVP54中的结构一致。对于HLA-A68:01, 4HWZ55表明肽的第9个K和第9个R (Arg)残基对结合有很大贡献。对于HLA-B*44:02,第二个E的关键作用已被1M6O56证明。所有这些结果都得到了前人研究的支持,证明了方法的有效性。
3、AOMP program.
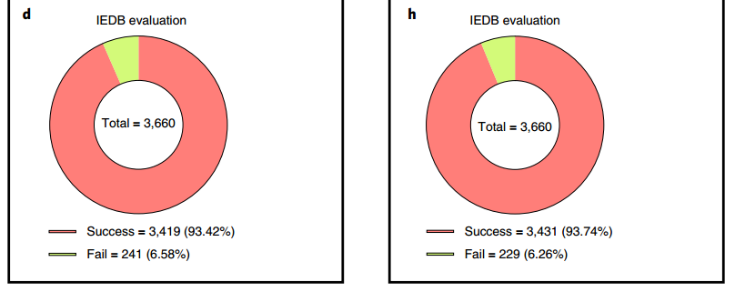
使用IEDB推荐的NetMHCpan_BA14来验证两种策略下3,660个phla的突变结果。结果如图6d、h所示,两种策略的成功率分别为93.42%和93.74%。第二种策略的性能略好于第一种策略,因为第二种策略的评估样本中含有结合性phla,而AOMP更容易为它们生成结合突变phla。第一种策略可以更准确地评估非结合phla的AOMP成功突变的概率,而第二种策略可以更好地揭示实际情况下AOMP的成功突变率,因为实践中ground-truth标签是未知的。
这篇关于Nat. Mach. Intell 2022 | TransMut+:基于transformer的用于预测peptide–HLA class I binding 并优化疫苗设计中的突变多肽的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






