本文主要是介绍数据仓库结构设计与实施-拆书稿(维度建模理论),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
拆书稿-数据仓库结构设计与实施

本篇文章内容目录
第一部分:数据仓库总体结构(原书第二章)
1 金字塔结构
2 元数据与模型
3 映像
4 数据仓库三要素
5 多维总计方阵
6 方阵和数据集市的区别
第二部分:数据仓库设计与应用开发(原书第五章)
数据仓库层次结构
数据仓库概念设计
数据仓库逻辑设计
数据仓库物理设计
正文开始
第一部分:数据仓库总体结构(原书第二章)
1 金字塔结构
金字塔从底层向上,体现出强大的收敛与聚合功能,层面越高越能高度地概括更丰富、更有意义的信息;层面越低,数据体量越大,细节程度越高,信息越具体。每个层面相互依托又互相关联。

数据仓库的金字塔结构和层次1
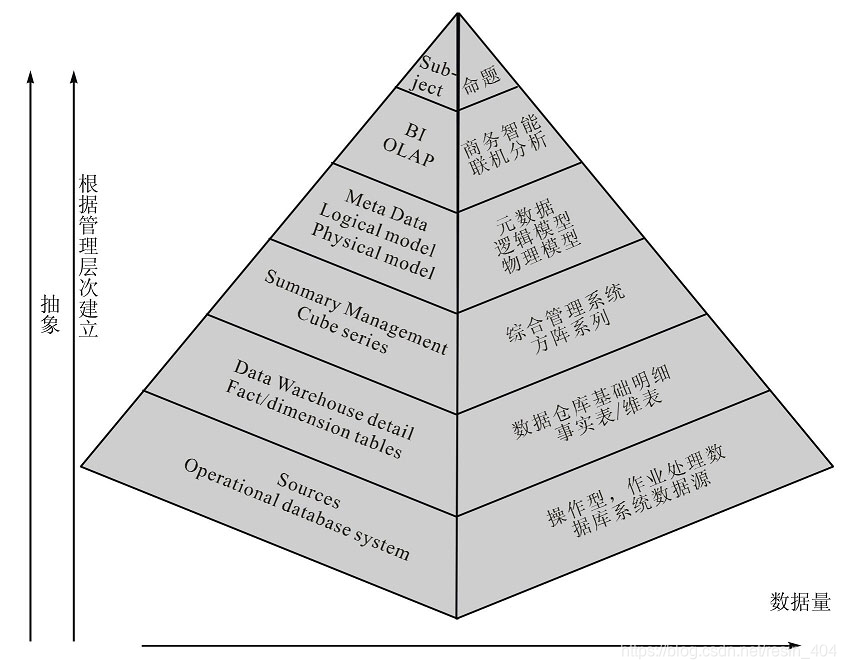
数据仓库的金字塔结构和层次2

数据仓库结构生态图
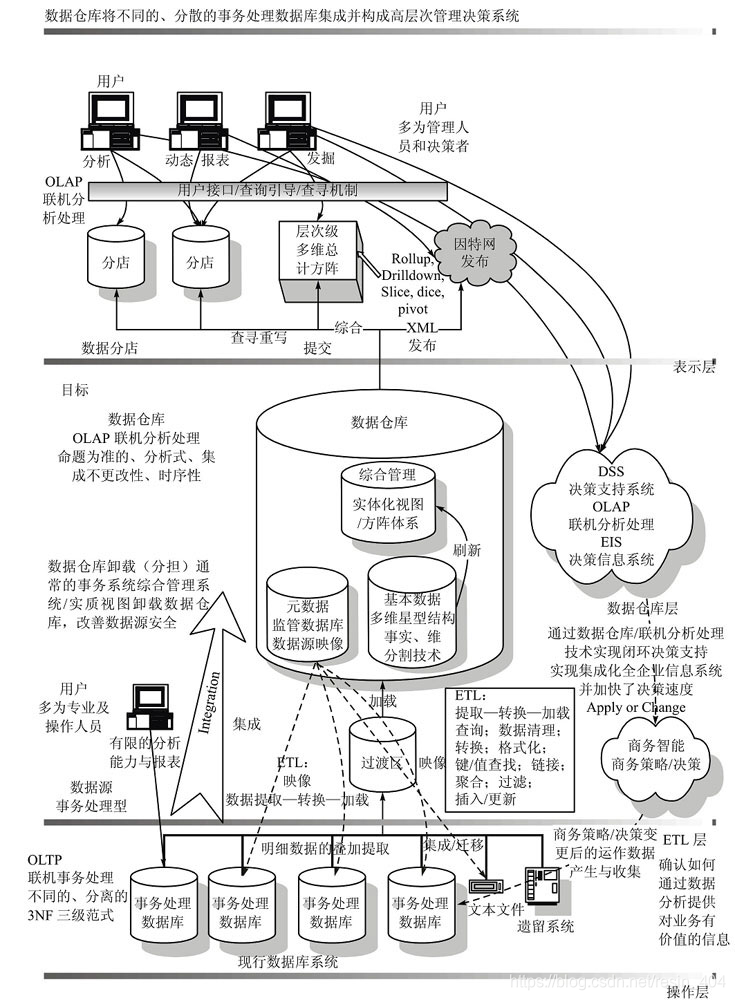
其中上图中有一个概念叫:过渡区,它为什么存在?并且有什么存在的价值?
① 为什么存在?
- 提前可以做数据预处理
来自数据源的数据在到达数据仓库之前,需要经过一些中间处理过程,而ETL常常是批量执行,是一些通用任务,无法完成定制化个性统计需求。而在数据源到数据仓库中间建立过渡区,可以针对特定数据进行预处理。例如:过滤空值、过滤多余字段、进行数据类型转换等等。
② 存在的价值?
- 第一、数据源和数据仓库进行隔离
- 第二、过渡区可作为数据接收切面,接纳不同数据源,数据仓库只需要从过度区获取数据。架构清晰
- 第三、过度区可以在数据允许的条件下提供数据支持,减少数据源数据提取的压力。
2 元数据与模型
分类:元数据主要有两种类型的模型
- 数据模型
- 应用模型
元数据定义: 说明数据的数据。像数据库中的数据字典,或者数据表与表之间的关系。
作用:用于描述从操作型系统到分析型系统的映射,描述数据源、数据更新、总计数据的算法和数据提取的频率。
模型的建立流程: 概念模型 、逻辑模型、物理模型
3 映像
映像是一系列结构化处理过程,能够引导数据从一个或者多个源系统到达目标系统。在这一过程当中存在一系列必要的转换处理。
映像包括:
- 源定义
- 目标定义
- 转换定义
在转换过程中就可以添加数据预处理,过滤多余数据项,也可以完成数据转换映射。
个人理解:在此过程中,通过此元数据管理,可以做一部分的规范化处理。例如: 源表和目标表的格式规范化(统一格式:数据库模式名_表名),完成转换后输出的数据集命名规范,转换过程中数据集的分隔符规范等等。
数据映像从数据源到目标

4 数据仓库三要素

5 多维总计方阵
是从数据仓库的事实表和有关维表中通过汇总、运算处理产生出来的综合数据,从结构和形式上更接近于最终用户对管理决策支持分析的要求,是为用户提供的具有多维数据查询和分析能力的视图。

创建方阵是将综合信息带给用户的必经之路,通过预先费时的计算和链接操作而生成的完好方阵系列,而不是在联机执行时间临时处理。方阵的存在大大减少了访问时间和复杂性,也降低了成本。
方阵的类型
- 多维联机分析处理方阵
- 虚拟方阵
- 奠基石式方阵–基础方阵
- 嵌入式方阵
- 稀疏方阵
6 方阵和数据集市的区别
数据集市
- 数据集市是按照需求定制化建立的,代表的数据价值只局限于需求的边界范围内。
- 针对性较强,可能在市场,营销,账务等业务线的数据集市都是不同的。不可重用,没有灵活性。并且容易产生数据孤岛,数据价值表现的很局限。
- 数据集市的种类统计粒度可能不同,不利于数据分析
从上面定义可知,数据集市的统计边界更小一点,可能只是针对某个业务线,某个部门。而方阵是基于整个数据仓库,通过整个数据仓库的相关表来进行统计汇总。
第二部分:数据仓库设计与应用开发(原书第五章)
数据仓库层次结构

数据仓库概念设计
概念模型是建立模型的初始阶段,主要描述与业务有关的重要实体以及相互之间的关系。
该阶段主要是确定系统建模的边界和范围。和行业经验和业务流程息息相关,在建模范围内,确定实体有哪些,梳理实体间的关系
具体方法可以参照5W1H: who、what、when、where、why、how
结果:实体关系图(不需要添加实体的属性)
数据仓库逻辑设计
梳理业务规则,对概念模型做进一步细化
确定实体的详细属性,实体间关系以及是否存在关系约束
数据仓库物理设计
从性能、访问、开发等多个方面考虑,做系统的实现。
该阶段完成:
- 类型长度的定义
- 字段的其他详细定义: 飞空,默认值
- 约束的定义: 主键,外键
这篇关于数据仓库结构设计与实施-拆书稿(维度建模理论)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








