本文主要是介绍【生成模型】解决生成模型面对长尾类型物体时的问题 RE-IMAGEN: RETRIEVAL-AUGMENTED TEXT-TO-IMAGE GENERATOR,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
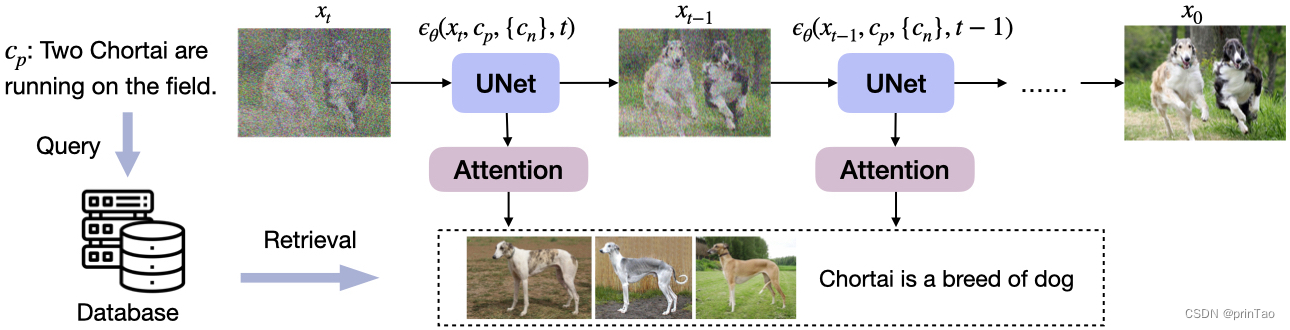
尽管最先进的模型可以生成常见实体的高质量图像,但它们通常难以生成不常见实体的图像,例如“Chortai(狗)”或“Picarones(食物)”。为了解决这个问题,我们提出了检索增强文本到图像生成器(Re-Imagen),这是一种生成模型,它使用检索到的信息来生成高保真和忠实的图像,即使对于罕见或看不见的实体也是如此。给定文本提示,Re-Imagen 访问外部多模态知识库来检索相关(图像、文本)对,并将它们用作生成图像的参考。
Re-Imagen 在两个图像生成基准上取得了新的 SoTA FID 结果,例如 COCO (即,FID = 5.25)和 WikiImage(即,FID = 5.82),无需微调。为了进一步评估模型的功能,我们引入了 EntityDrawBench,这是一个新的基准,可跨多个视觉域评估从频繁到罕见的各种实体的图像生成。对 EntityDrawBench 的人类评估表明,Re-Imagen 在照片真实感方面的表现与最佳先前模型相当,但具有明显更好的现实世界忠实度,尤其是在不太频繁的实体上。

内容
通过在多模态知识库中搜索实体信息来减轻这种限制,而不是试图记住实体的外观稀有实体。
它包含三个独立的生成阶段(实现为 U-Nets (Ronneberger et al.,2015))以逐渐产生高分辨率(即, 1024
×
第1024章)特别是,我们在由 Imagen 使用的图像文本数据集构建的数据集上训练 Re-Imagen (Saharia等人,2022),其中每个数据实例基于文本与数据集中的前 k 个最近邻相关联-只有BM25分数。
无分类器指导 Ho 和 Salimans ( 2021 )首先提出了无分类器指导来权衡多样性和样本质量。这种采样策略由于其简单性而被广泛使用。
模型的架构 ,其中我们将 UNet 分解为下采样编码器 (DStack) 和上采样解码器 (UStack)。具体来说,DStack以图像、文本和时间步作为输入,生成特征图,
当我们对检索到的< image, text >对进行编码时,我们共享相同的 DStack 编码器(使用t设置为零),这会产生一组特征图。
然后,我们使用多头注意力模块 (Vaswani et al.,2017)来提取最相关的信息以生成新的特征图。
然后上采样堆栈解码器预测噪声项,以用于训练期间的回归或 DDPM 采样。
评价指标
,FID (Fréchet Inception Distance) 和 ZS-FID (Zero-Shot Fréchet Inception Distance) 是两种常用的评估生成模型性能的指标。它们都是通过比较生成图像与真实图像的分布差异来进行评估的。
FID 需要访问到真实图像,并且在这些图像上训练模型,因此它更适合于有大量真实图像可用的情况。而 ZS-FID 不需要在真实图像上训练模型,因此它更适合于没有足够真实图像,或者想要评估模型在未见过的类别上的性能的情况。
FID
https://github.com/mseitzer/pytorch-fid#generating-a-compatible-npz-archive-from-a-dataset
FID 是一种衡量生成模型性能的指标,它通过比较生成图像与真实图像的统计特性来进行评估。具体来说,FID 使用 Inception 网络提取图像的特征,然后计算这些特征的高斯分布。FID 是根据这两个高斯分布的 Fréchet 距离来评价生成图像与真实图像的相似度。FID 越小,表明生成图像与真实图像的分布越接近,生成模型的性能越好。
ZS FID
ZS-FID 是 FID 的一个变种,它也是通过比较生成图像与真实图像的统计特性来进行评估。不过,ZS-FID 的一个关键区别在于,它不需要在真实图像上训练任何模型。这使得 ZS-FID 能够进行“零样本”或“零次射击”评估,即在没有真实图像的情况下评估生成模型的性能。这在某些情况下是非常有用的,例如当我们没有访问到足够的真实图像,或者当我们想要评估生成模型在未见过的类别上的性能时。
实验
Re-Imagen(使用 COCO 数据库)无需微调即可在 FID-30K 上实现显着增益:相对于 Imagen 大约有 2.0 的绝对 FID 改进。性能甚至比微调的 Make-A-Scene (Gafni et al. , 2022 )还要好,但比微调的 20B Parti 稍差。相比之下,从域外数据库检索的 Re-Imagen (LAION) 获得的增益较小,但仍比 Imagen 获得 0.4 FID 的改进。Re-Imagen 的性能远远优于另一种检索增强扩散模型 KNN-Diffusion。
由于 COCO 不包含不常见的实体,因此“实体知识”并不重要。相反,从训练集中检索可以为模型提供有用的“风格知识”。Re-Imagen能够使生成的图像适应相同风格的COCO分布,它可以获得更好的FID分数。从图4的上半部分可以看出 ,带有检索的Re-Imagen生成了与COCO相同风格的图像,而没有检索,输出仍然是高质量的,但风格与COCO不太相似。
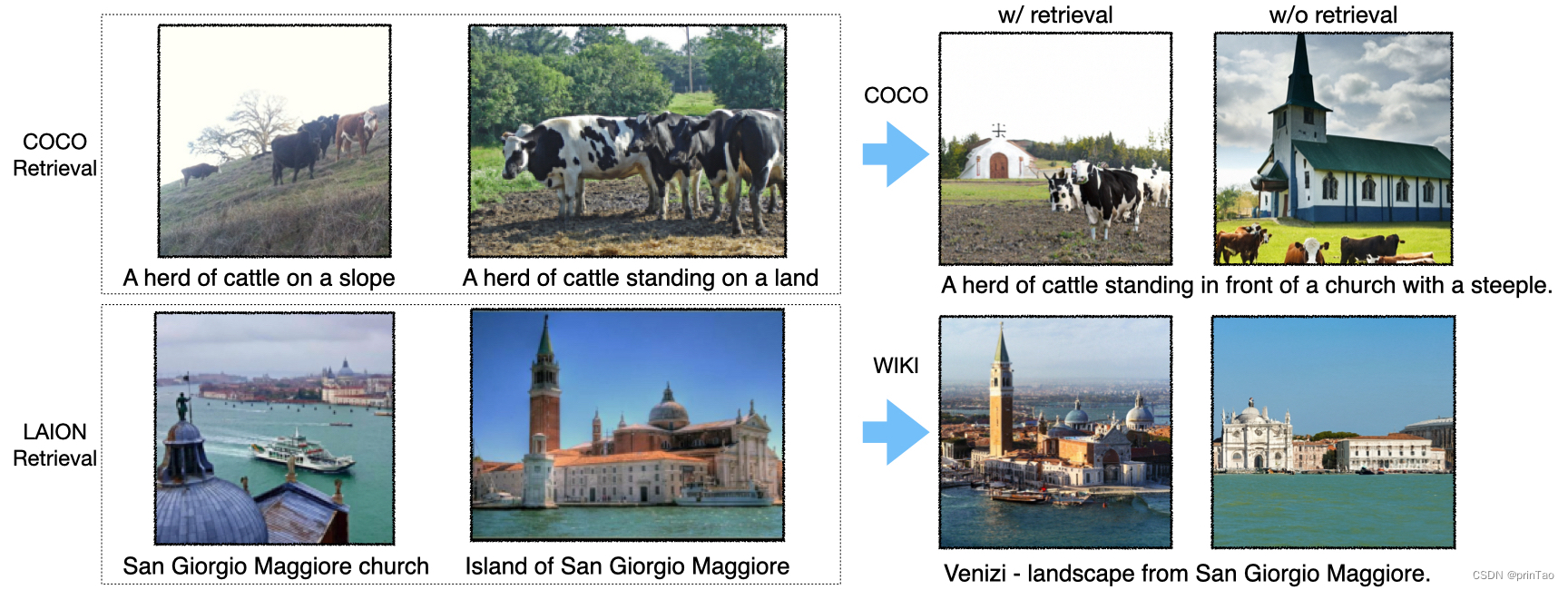
图 4下半部分描述了一个示例 ,其中 LAION 检索找到“Island of San Giorgio Maggiore”,这有助于模型生成古典文艺复兴风格的教堂。当不检索生成时,模型无法生成特定的教堂。这表明在 WikiImages 数据集检索中拥有相关实体的重要性,也解释了为什么 LAION 数据库取得了最佳结果。我们还在附录 C中提供了来自 WikiImages 的更多示例。
ENTITYDRAWBENCH 上的以实体为中心的评估
数据集构建 我们引入EntityDrawBench来评估模型在不同视觉场景中生成不同实体集的能力。具体来说,我们从 Wikipedia Commons 和 Google Landmarks 中选择三种类型的视觉实体(狗品种、地标和食物)来构建我们的提示。我们总共收集了 150 个以实体为中心的评估提示。这些提示大多是独特的,我们无法通过Google图像搜索找到相应的图像。
我们使用提示作为输入,并使用其对应的图像文本对作为 Re-Imagen 的“检索”,生成四个 1024
×
1024 张图像。对于其他模型,我们也直接输入提示来生成四个图像。我们将从这四个样本中选出最好的图像来评价其真实感和忠实度。对于照片真实感,如果图像适度真实且没有明显的伪影,我们分配 1,否则,我们分配 0 分。对于忠实度度量,如果图像忠实于实体源和文本描述,我们分配 1,否则,我们分配0。
实体在 Imagen 训练语料库中的频率(前 50% 为“频繁”)进一步将实体分为“频繁”和“不频繁”类别。我们在 图 5中分别绘制了“频繁”和“不频繁”的忠实度得分。我们可以看到,我们的模型对输入实体的频率的敏感度低于其他模型,对于不频繁的实体仅下降了 10-20%。相比之下,Imagen 和 DALL-E 2 在不常见实体上都下降了 40%-50%。这项研究反映了文本到图像生成模型在长尾实体上的有效性。
我们提出了 Re-Imagen,一种检索增强扩散模型,并证明了其在生成真实且忠实图像方面的有效性。我们不仅通过标准基准(即COCO 和 WikiImage)上的自动 FID 测量,而且还通过新引入的 EntityDrawBench 上的人工评估来展示这些优势。我们进一步证明,我们的模型在从提及稀有实体的文本生成图像方面特别有效。
Re-Imagen 在文本到图像生成方面仍然存在众所周知的问题,我们将在下面的道德声明中对此进行回顾。此外,由于检索增强建模,Re-Imagen 还具有一些独特的局限性。首先,由于Re-Imagen对其所依赖的检索到的图像文本对很敏感,因此当检索到的图像质量较低时,会对生成的图像产生负面影响。其次,当实体的视觉外观超出生成空间时,Re-Imagen 有时仍然无法基于检索到的实体。第三,我们注意到超分辨率模型效果较差,并且经常会错过视觉实体的低级纹理细节。在未来的工作中,我们计划进一步研究上述局限性并解决它们。
这篇关于【生成模型】解决生成模型面对长尾类型物体时的问题 RE-IMAGEN: RETRIEVAL-AUGMENTED TEXT-TO-IMAGE GENERATOR的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








