imagen专题

图像生成模型浅析(Stable Diffusion、DALL-E、Imagen)
目录 前言1. 速览图像生成模型1.1 VAE1.2 Flow-based Model1.3 Diffusion Model1.4 GAN1.5 对比速览 2. Diffusion Model3. Stable Diffusion3.1 Text Encoder3.2 Decoder3.3 Generation Model 总结参考 前言 简单学习下图像生成模型的相关知识🤗

Instruct-Imagen
谷歌图像生成AI掌握多模态指令,Google DeepMind 和 Google Research 提出可将多模态指令方法用于图像生成。该方法可将不同模态的信息交织在一起来表达图像生成的条件。 用图 2 的风格画图 1 的猫猫并给它戴上一顶帽子。谷歌新设计的一种图像生成模型已经能做到这一点了!通过引入指令微调技术,多模态大模型可以根据文本指令描述的目标和多张参考图像准确生成新图像,效果堪比 P
Google谷歌 Bard 聊天机器人安装 Imagen 2 图像模型支持文生图功能:可免费生成“高质量且逼真”的图像
谷歌宣布,旗下聊天机器人 Bard 的能力又取得了重大突破,由 Imagen 2(Google 最先进的文本到图像模型)提供支持的新图像生成工具,除了原有的语言处理技能外,现在它还可以免费生成“高质量且逼真”的图像。 Bard实验体验链接:https://bard.google.com/chat 更多消息:AI人工智能行业动态,aigc应用领域资讯 此次更新为 Bard 增添了图像生
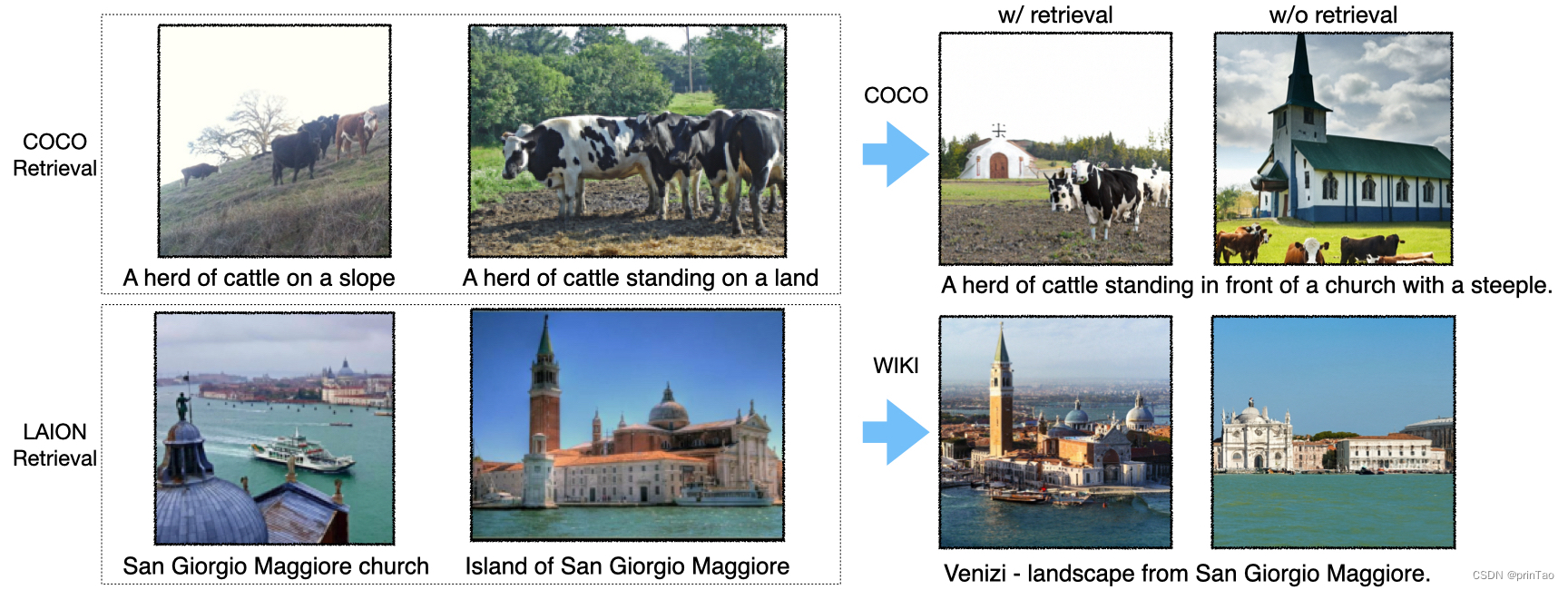
【生成模型】解决生成模型面对长尾类型物体时的问题 RE-IMAGEN: RETRIEVAL-AUGMENTED TEXT-TO-IMAGE GENERATOR
介绍 尽管最先进的模型可以生成常见实体的高质量图像,但它们通常难以生成不常见实体的图像,例如“Chortai(狗)”或“Picarones(食物)”。为了解决这个问题,我们提出了检索增强文本到图像生成器(Re-Imagen),这是一种生成模型,它使用检索到的信息来生成高保真和忠实的图像,即使对于罕见或看不见的实体也是如此。给定文本提示,Re-Imagen 访问外部多模态知识库来检索相关(图像、文