本文主要是介绍7.7亿参数,超越5400亿PaLM!UW谷歌提出「分步蒸馏」,只需80%训练数据|ACL 2023,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LLM不实用,小模型蒸馏才是「现实」的大模型应用路线,全面领先微调技术!土豪请无视。。。
大型语言模型虽然性能优异,可以用零样本或少样本提示解决新任务,但LLM在实际应用部署时却很不实用,内存利用效率低,并且需要大量计算资源。
比如运行一个1750亿参数的语言模型服务至少需要350GB的显存,而目前最先进的语言模型大多已超过5000亿参数量,很多研究团队都没有足够的资源来运行,在现实应用中也无法满足低延迟性能。
也有一些研究使用人工标注数据或使用LLM生成的标签进行蒸馏来训练较小的、任务专用的模型,不过微调和蒸馏需要大量的训练数据才能实现与LLM相当的性能。
为了解决大模型的资源需求问题,华盛顿大学联合谷歌提出了一种新的蒸馏机制「分步蒸馏」(Distilling Step-by-Step),蒸馏后的模型尺寸相比原模型来说非常小,但性能却更好,并且微调和蒸馏过程中所需的训练数据也更少。

论文链接:https://arxiv.org/abs/2305.02301
分布蒸馏机制把LLM中抽取出的预测理由(rationale)作为在多任务框架内训练小模型的额外监督信息。
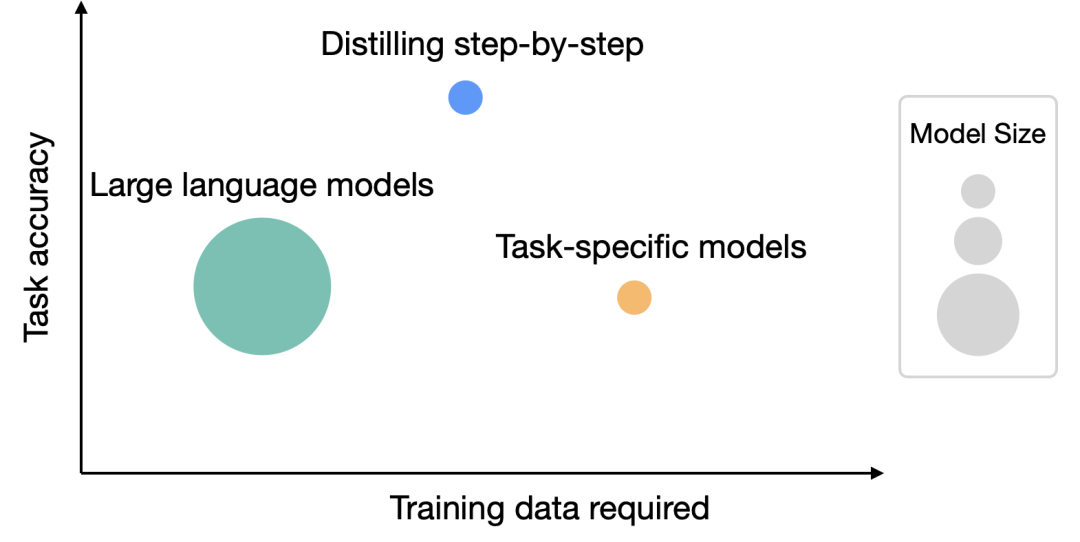
在4个NLP基准上进行实验后,可以发现:
1. 与微调和蒸馏相比,该机制用更少的训练样本实现了更好的性能;
2. 相比少样本提示LLM,该机制使用更小尺寸的模型实现了更好的性能;
3. 同时降低模型尺寸和数据量也可以实现优于LLM的性能。
实验中,微调后770M的T5模型在基准测试中仅使用80%的可用数据就优于少样本提示的540B的PaLM模型,而标准微调相同的T5模型即使使用100%的数据集也难以匹配。
蒸馏方法
分布蒸馏(distilling step by step)的关键思想是抽取出信息丰富且用自然语言描述的预测理由,即中间推理步骤,可以解释输入问题与模型输出之间的联系,然后再反过来用该数据以更高效的方式训练小模型。
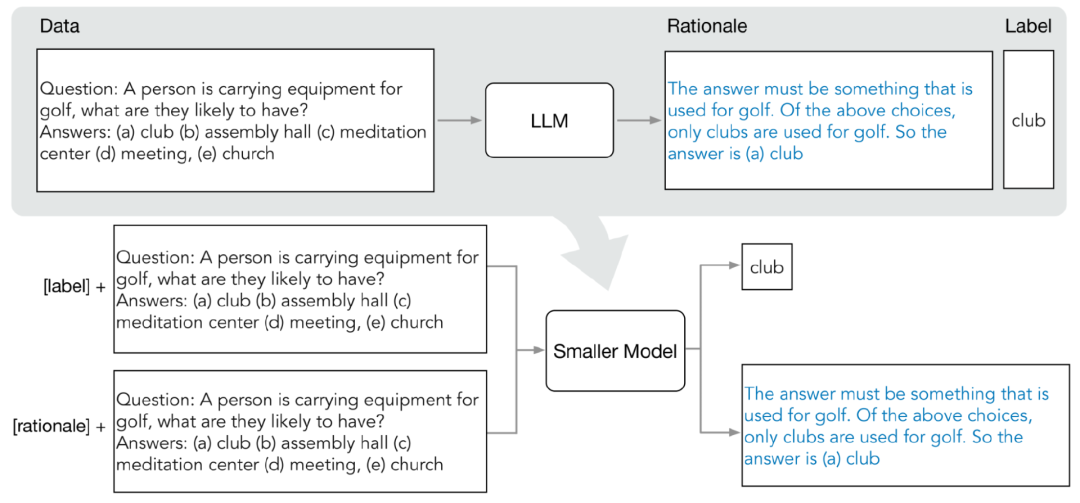
分布蒸馏主要由两个阶段组成:
1. 从LLM中抽取原理(rationale)
研究人员利用少样本思维链(CoT)提示从LLM中提取预测中间步骤。
给定目标任务后,先在LLM输入提示中准备几个样例,其中每个样例由一个三元组组成,包含(输入,原理,输出)。

输入提示后,LLM能够模仿三元组演示以生成其他新问题的预测原理,例如,在常识问答案任务中,给定输入问题:
「Sammy想要去人群所在的地方。他会去哪里?答案选项:(a)人口稠密地区,(B)赛道,(c)沙漠,(d)公寓,(e)路障」
(Sammy wanted to go to where the people are. Where might he go? Answer Choices: (a) populated areas, (b) race track, (c) desert, (d) apartment, (e) roadblock)
通过逐步提炼后,LLM可以给出问题的正确答案「(a)人口稠密地区」,并且提供回答问题的理由「答案必须是一个有很多人的地方,在上述选择中,只有人口稠密的地区有很多人。」
通过在提示中提供与基本原理配对的CoT示例,上下文学习能力可以让LLM为没见过的问题类型生成相应的回答理由。
2. 训练小模型
通过将训练过程构建为多任务问题,将预测理由抽取出来,并将其纳入训练小模型中。
除了标准标签预测任务之外,研究人员还使用新的理由生成任务来训练小模型,使得模型能够学习生成用于预测的中间推理步骤,并且引导模型更好地预测结果标签。
通过在输入提示中加入任务前缀「label」和「rationale」来区分标签预测和理由生成任务。
实验结果
在实验中,研究人员选择5400亿参数量的PaLM模型作为LLM基线,使用T5模型作为任务相关的下游小模型。
然后在三个不同的NLP任务中对四个基准数据集进行了实验:用于自然语言推理的e-SNLI和ANLI、常识问答的CQA,以及用于算术数学应用题的SVAMP.
更少的训练数据
与标准微调相比,分步蒸馏方法使用更少的训练数据即实现了更好的性能。
在e-SNLI数据集上,当使用完整数据集的12.5%时就实现了比标准微调更好的性能,在ANLI、CQA和SVAMP上分别只需要75%、25%和20%的训练数据。
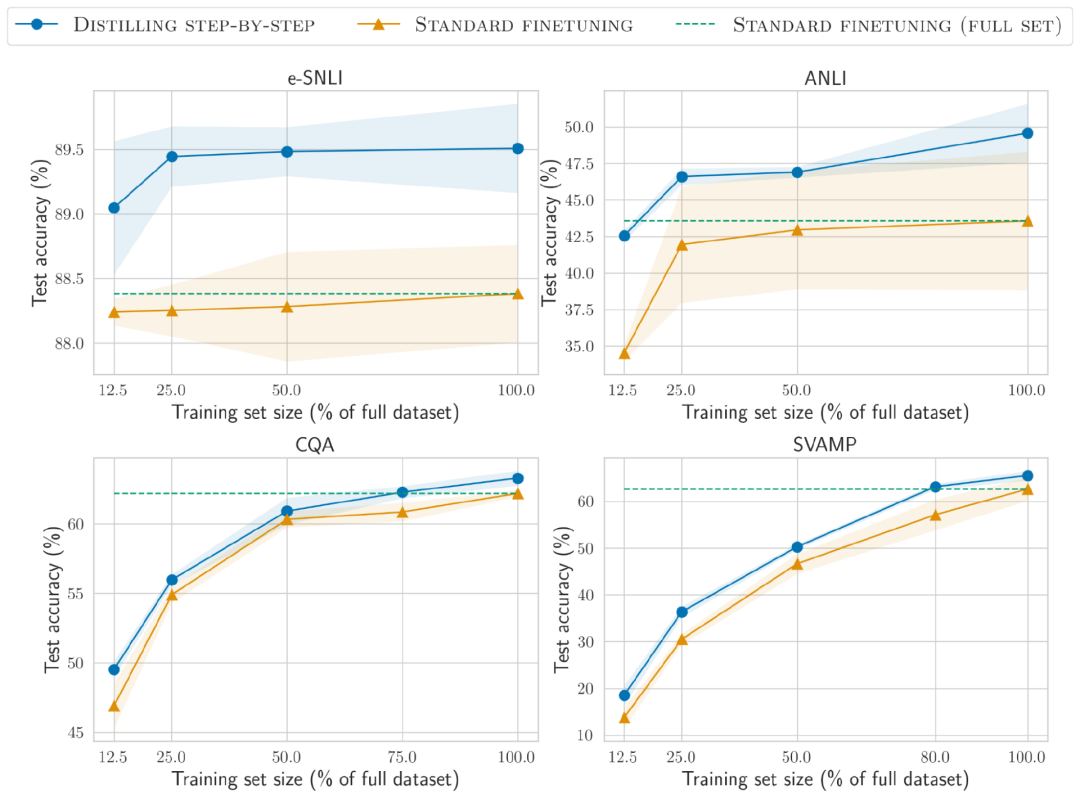
与使用220M T5模型对不同大小的人工标记数据集进行标准微调相比,在所有数据集上,分布蒸馏使用更少的训练示例优于在完整数据集上训练的标准微调。
更小的部署模型尺寸
与少样本CoT提示的LLM相比,分布蒸馏得到的模型尺寸要小得多,但性能却更好。
在e-SNLI数据集上,使用220M的T5模型实现了比540B的PaLM更好的性能;在ANLI上,使用770M的T5模型实现了比540B的PaLM更好的性能,模型尺寸仅为1/700
更小的模型、更少的数据
在模型尺寸和训练数据同时降低的情况下,也实现了超越少样本PaLM的性能。
在ANLI上,使用770M T5模型超越了540B PaLM的性能,只使用了完整数据集的80%
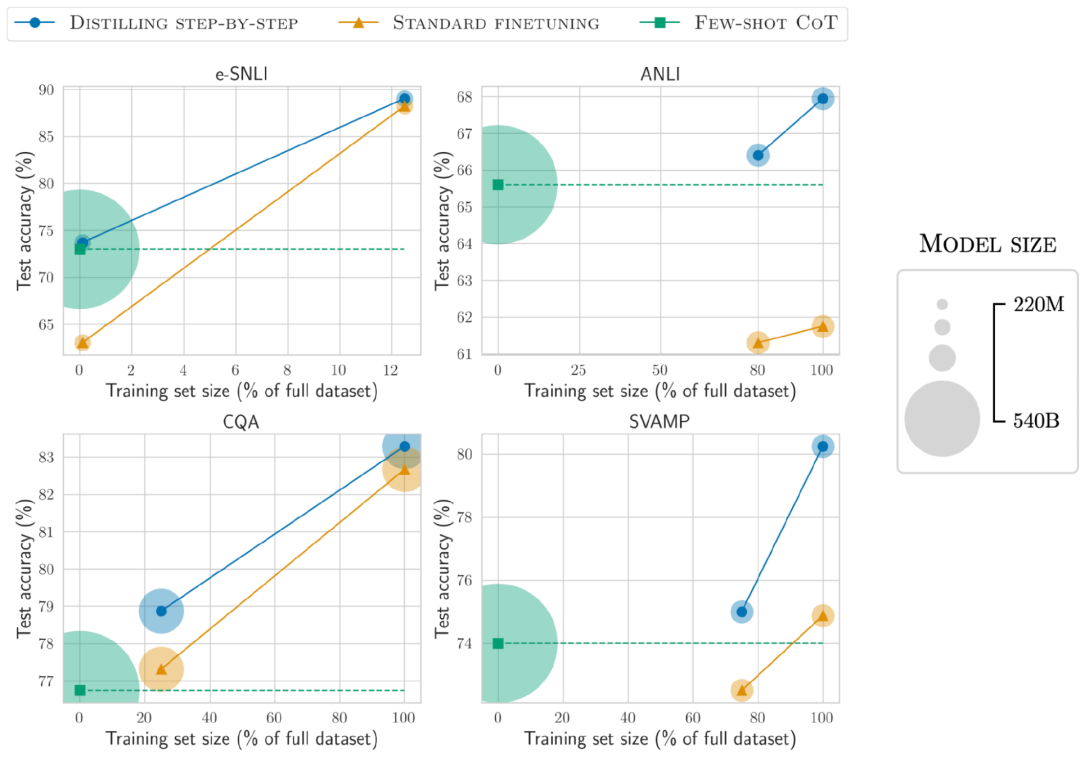
并且可以观察到,即使使用100%的完整数据集,标准微调也无法赶上PaLM的性能,表明分步蒸馏可以同时减少模型尺寸和训练数据量实现超越LLM的性能。
参考资料:
https://blog.research.google/2023/09/distilling-step-by-step-outperforming.html
这篇关于7.7亿参数,超越5400亿PaLM!UW谷歌提出「分步蒸馏」,只需80%训练数据|ACL 2023的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





