5400专题
![[数据集][目标检测]减速带检测数据集VOC+YOLO格式5400张1类别](https://img-blog.csdnimg.cn/direct/13f3fafa5a0740a392d2c0c3e4302e11.png)
[数据集][目标检测]减速带检测数据集VOC+YOLO格式5400张1类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):5400 标注数量(xml文件个数):5400 标注数量(txt文件个数):5400 标注类别数:1 标注类别名称:["speedbump"] 每个类别标注的框数: speedbump 框数 = 7343 总框数:7

【Python】【难度:简单】Leetcode 5400. 旅行终点站
给你一份旅游线路图,该线路图中的旅行线路用数组 paths 表示,其中 paths[i] = [cityAi, cityBi] 表示该线路将会从 cityAi 直接前往 cityBi 。请你找出这次旅行的终点站,即没有任何可以通往其他城市的线路的城市。 题目数据保证线路图会形成一条不存在循环的线路,因此只会有一个旅行终点站。 示例 1: 输入:paths = [["London","N
![[转]10+倍性能提升全过程--优酷账号绑定淘宝账号的TPS从500到5400的优化历程](http://i.imgur.com/m515K0s.png)
[转]10+倍性能提升全过程--优酷账号绑定淘宝账号的TPS从500到5400的优化历程
摘要: # 10+倍性能提升全过程--优酷账号绑定淘宝账号的TPS从500到5400的优化历程 ## 背景说明 > 2016年的双11在淘宝上买买买的时候,天猫和优酷土豆一起做了联合促销,在天猫双11当天购物满XXX元就赠送优酷会员,这个过程需要用户在优酷侧绑定淘宝账号(登录优酷、提供淘宝账号,优酷调用淘宝API实现两个账号绑定)和赠送会员并让会员权益生效(看收费影片、免广告等等) > 10+
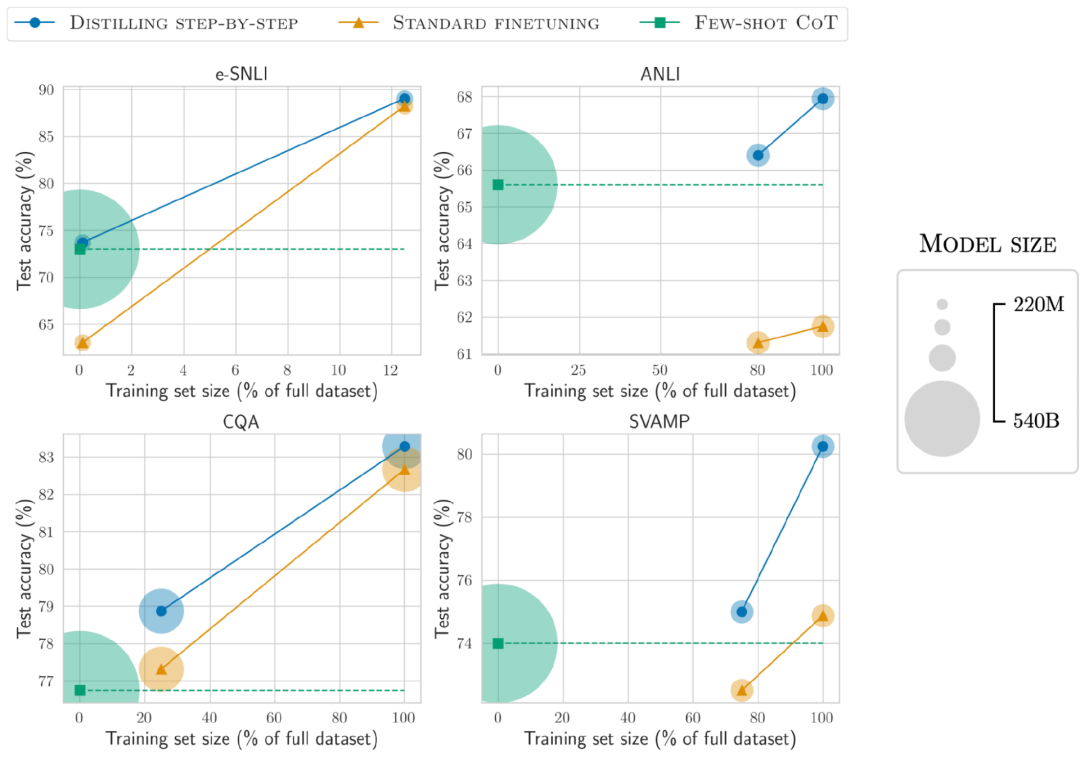
7.7亿参数,超越5400亿PaLM!UW谷歌提出「分步蒸馏」,只需80%训练数据|ACL 2023
LLM不实用,小模型蒸馏才是「现实」的大模型应用路线,全面领先微调技术!土豪请无视。。。 大型语言模型虽然性能优异,可以用零样本或少样本提示解决新任务,但LLM在实际应用部署时却很不实用,内存利用效率低,并且需要大量计算资源。 比如运行一个1750亿参数的语言模型服务至少需要350GB的显存,而目前最先进的语言模型大多已超过5000亿参数量,很多研究团队都没有足够的资源来运行,在现实应用中也无