本文主要是介绍AI大模型独角兽 MiniMax 基于 Apache Doris 升级日志系统,PB 数据秒级查询响应,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:MiniMax 基础架构研发工程师 Koyomi、香克斯、Tinker
导读:早期 MiniMax 基于 Grafana Loki 构建了日志系统,在资源消耗、写入性能及系统稳定性上都面临巨大的挑战。为此 MiniMax 开始寻找全新的日志系统方案,并基于 Apache Doris 升级了日志系统,新系统已接入 MiniMax 内部所有业务线日志数据,数据规模为 PB 级, 整体可用性达到 99.9% 以上,10 亿级日志数据的检索速度可实现秒级响应。
MiniMax 是领先的通用人工智能科技公司,自主研发了不同模态的通用大模型,其中包括拥有万亿参数的 MoE 文本大模型、语音大模型以及图像大模型。MiniMax 以“与用户共创智能”为愿景,通过对大模型持续迭代,MiniMax 在国内率先完成核心 MoE 算法技术路线的突破。2024 年 4 月,公司推出国内首个上线商用的 MoE 架构、包含万亿参数的大语言模型——“MiniMax-abab 6.5”,模型性能接近国际领先水平。
随着模型复杂度以及模型调用量的不断提升,模型训练及推理产生的运行日志也在激增,这些数据对于 AI 应用的运行监控、优化及问题定位至关重要。早期 MiniMax 基于 Grafana Loki 构建了日志系统,在资源消耗、写入性能及系统稳定性上都面临巨大的挑战。为此 MiniMax 开始寻找全新的日志系统方案,并对业界具有代表性的技术栈 Apache Doris 和 Elasticsearch 进行了对比,Apache Doris 在性能、成本以及易用性等方面均优于 Elasticsearch,因此最终选择了 Apache Doris 来构建日志系统。
目前基于 Apache Doris 的新系统已接入 MiniMax 内部所有业务线日志数据,数据规模为 PB 级, 整体可用性达到 99.9% 以上,10 亿级日志数据的检索速度可实现秒级响应。
问题及痛点
MiniMax 早期日志系统架构基于 Loki 搭建,Loki 是由 Grafana Labs 团队开发的开源日志聚合系统,设计思想受 Prometheus 启发,不使用传统索引结构、仅对日志标签和元数据构建索引,核心模块包括 Loki、Promtail、Grafana 三个部分,其中 Loki 是主服务器、负责日志存储和查询,Promtail 是代理层、负责采集日志并发送给 Loki,而 Grafana 则用于 UI 展示。
在实际 Grafana Loki 使用中,每个集群中单独部署一套完整的日志采集器 + Loki 日志存储/查询服务。Loki 采用 Index + Chunk 的日志存储设计,写入时按日志标签的哈希值将不同日志流分散到各个 Ingester 上实现负载均衡,由 Ingester 负责将日志数据写入对象存储。查询时,Querier 从对象存储取出 Index 对应的 Chunk 后进行日志匹配。

尽管 Grafana Loki 定位为轻量级、水平可拓展和高可用的日志系统,但其在实际业务使用过程中仍存在一些问题:
-
查询资源消耗过大: Loki 未对日志内容创建索引,只能按照标签粒度对日志进行初步过滤。如果想要实现日志内容搜索功能,需使用 Query 对全量日志数据进行全文正则匹配, 而该操作会带来巨大的突发资源消耗,包括 CPU、内存、网络带宽。当查询的数据量和 QPS 越来越大时,Loki 的资源消耗及其稳定性问题也变得越来越不可忍受。
-
Loki 架构复杂繁多: Loki 除了上图涉及模块之外,还有 Index Gateway、 Memcache、 Compactor 等模块,过多的架构组件给系统运维和管理带来很高的难度,配置起来也非常复杂。
-
维护成本及难度高: MiniMax 部署集群数量较多,且每个集群的系统、资源、存储、网络等环境都有差异, 如果在每个集群中部署一套独立的 Loki 架构,维护成本及运维难度都非常高。
为什么选择 Apache Doris
根据 AI 场景的数据特点及业务需求,MiniMax 对新日志系统提出了以下要求:
-
日志数据规模庞大:由于 AI 业务场景具备链路长、上下文数据多、单次请求数据量大等特点,其产生的日志体量远远高于相同用户量级的其他互联网产品,这要求系统能够以较低的成本、稳定可靠的存储这些数据。
-
查询性能要求高:业务对日志查询速度有较高的要求, 比如 1 亿条数据需要在秒级返回查询结果。
-
分析灵活:要求系统能够支持日志指标查询、如某些关键词的统计曲线,同时能够提供日志告警服务。
-
低成本:由于日志原始数据量达到 PB 级,而且还在不断增加,存储和计算的成本需要控制在合理范围内。
MiniMax 参考了当前业界成熟的日志系统架构解决方案,发现主流的日志系统一般包含以下几个关键组件:
- 采集端:负责从服务的标准输出采集日志,并将数据推送到中心消息队列。
- 消息队列:负责解耦上下游、削峰填谷。在下游组件不可用时,仍然能保留一段时间的数据,保证系统稳定性。
- 存储查询中间件:负责日志数据的存储和查询,在日志系统场景下,一般要求该中间件具备倒排索引能力,来支持高效的日志检索。
根据上述方案组成,MiniMax 决定在新日志系统中:采集端使用 iLogtail、消息队列使用 Kafka、存储中间件为 Apache Doris。在存储中间件的选择上,对比了业界具有代表性的 Apache Doris 和 Elasticsearch 这两个技术栈:

Apache Doris 在成本、写入性能、查询性能这几大维度均有较好的表现,尤其在存储效率、写入吞吐、聚合分析等方面有突出的优势,同时兼容 MySQL 的 SQL 语法也更加易用,因此最终选择 Apache Doris 作为存储中间件。
Aapche Doris 日志系统升级实践
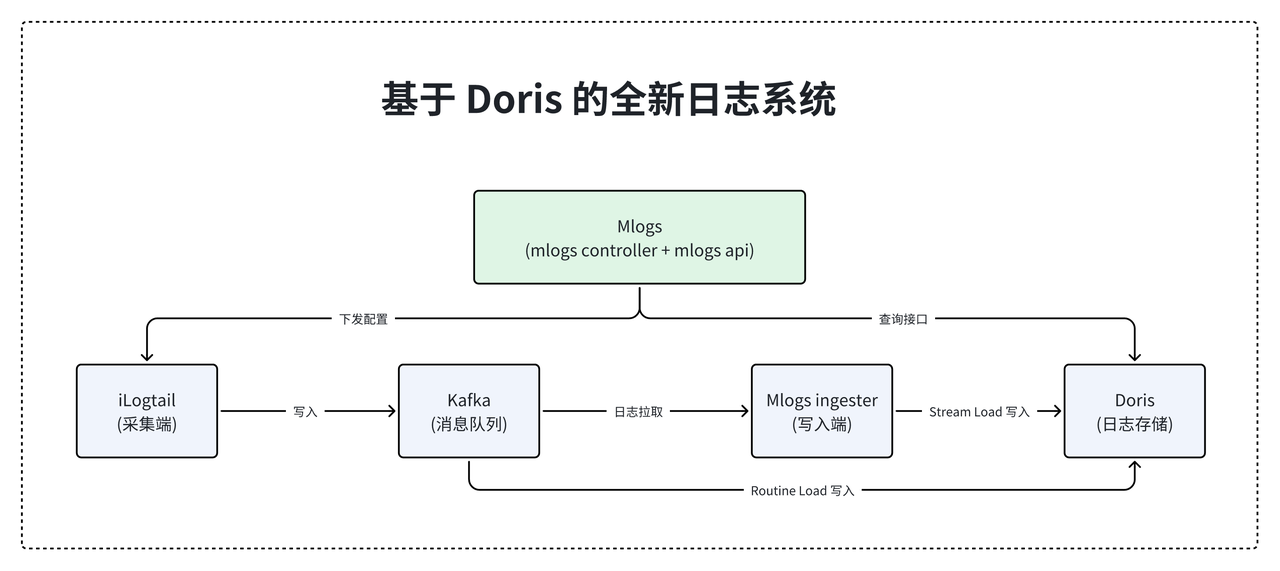
新日志系统(Mlogs)更加简洁,一套架构即可服务全部集群。上层为日志系统的控制面, 包括日志查询接口封装以及配置自动生产与下发模块。 下层是日志系统的数据面, 从左到右依次是日志采集端、消息队列、日志写入器、Doris 数据库。
集群服务产生的日志数据由 iLogtail 采集并推送到 Kafka,一部分会经由 Mlogs Ingester 从 Kafka 拉取并通过 Doris 的 Stream Load 写入到 Doris 集群中,另一部分则由 Doris 通过 Routine Load 直接实时订阅拉取Kafka 的消息流 。最后由 Doris 承担全量日志数据的存储与查询,无需每套集群单独部署。
在具体的应用落地方面:
-
在日志导入上: 新架构同时使用了 Doris Routine Load 和 Stream Load 方式。Routine Load 开箱即用,可直接处理不需要额外解析处理的 JSON 格式日志。而对于需要过滤与处理的复杂日志, MiniMax 在 Kafka 和 Doris 之间增加了日志写入器 Mlogs Ingester,由其解析和处理后,再通过 Stream Load 写入 Doris 中。
-
在日志检索上: 主要使用了 Doris 倒排索引分词查询能力以及全文正则查询能力。
-
倒排索引分词查询能力:分词查询性能较好, 场景覆盖度较广,主要采用倒排索引查询
MATCH和MATCH_PHRASE。 -
全文正则查询能力:正则查询精度更高,性能低于比分词查询, 适合小范围查询且对查询精度要求较高的场景,主要使用正则查询
REGEXP。
-
-
在性能提升上:为进一步提升性能,实现了查询截断功能。当前日志数据按照时间顺序呈线性排列, 如果用户选择的查询范围过大, 会消耗较大的计算存储网络资源, 从而导致查询超时甚至系统不可用。 因此,对用户的查询进行了时间范围截断, 避免查询范围过大;并提前统计所有表的每 15 分钟的数据量, 动态地预估用户在不同表中最大可查询的时间长度。
-
在成本控制上: 使用了 Doris 的冷热数据分层能力, 将 7 天内的数据定义为热数据,7 天之前的数据为冷数据。冷数据存储到对象存储, 以降低存储成本;同时对 30 天之前的对象存储数据进行归档, 仅在必要时恢复归档数据, 这也极大地降低了存量数据的存储成本。
使用收益
目前基于 Apache Doris 的新架构已接入 MiniMax 内部所有业务线日志数据,数据规模为 PB 级, 整体可用性达到 99.9% 以上, 同时也带来以下收益:
-
架构简化:新架构部署简单、一套架构即可服务全部集群,降低了整体系统维护及管理的复杂度,节省了大量的运维人力及成本投入。
-
秒级查询响应: 基于 Apache Doris 的倒排索引能力及查询拦截功能,性能显著提升的同时系统也更加稳定。从 10 亿数据中查询单个关键字以及进行聚合分析,基本可以在 2s 内完成,对于日志数据的分析,大部分场景也可以做到秒级响应。
-
写入性能高:当前系统规格可以实现 10 GB/s 级别的日志写入吞吐,能够在满足持续高吞吐写入的同时满足实时性要求,数据延迟控制在秒级。
-
存储成本低: 数据压缩率较高达到 1:5 倍以上,因此存储空间占用较原本架构极大幅度降低。对于冷数据使用 Doris 冷热分层能力进一步降低数据的存储成本,存储成本节省超过 70%。
未来规划
未来 MiniMax 将持续迭代日志系统, 并重点从以下几方面发力:
-
丰富日志导入预处理能力:增加日志采样、结构化等预处理能力,进一步提升数据的可用性及存储性价比。
-
增加 Tracing 能力:尝试将监控、告警、Tracing、日志等各方面的可观测性系统打通,以提供全方位的运维洞察。
-
扩大 Doris 使用范围:除日志场景之外,Doris 逐步被引入数据分析和大数据处理场景下,助力后续构建数据湖仓能力。
这篇关于AI大模型独角兽 MiniMax 基于 Apache Doris 升级日志系统,PB 数据秒级查询响应的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






