本文主要是介绍【AI基础】租用云GPU之autoDL部署大模型ollama+llama3,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在这个显卡昂贵的年代,很多想要尝试一下AI的人可能都止步于第一步。这个时候我们可以租用在线的GPU资源来使用AI。autoDL就是这样的一个云平台。
一、创建服务器
1.1 注册账号
官网:https://www.autodl.com/ | 租GPU就上AutoDL
帮助文档:https://www.autodl.com/docs/ | AutoDL帮助文档
登录官网,注册账号。
1.2 创建服务器
注册后会跳转到创建实例页面,也可以通过控制台进入:
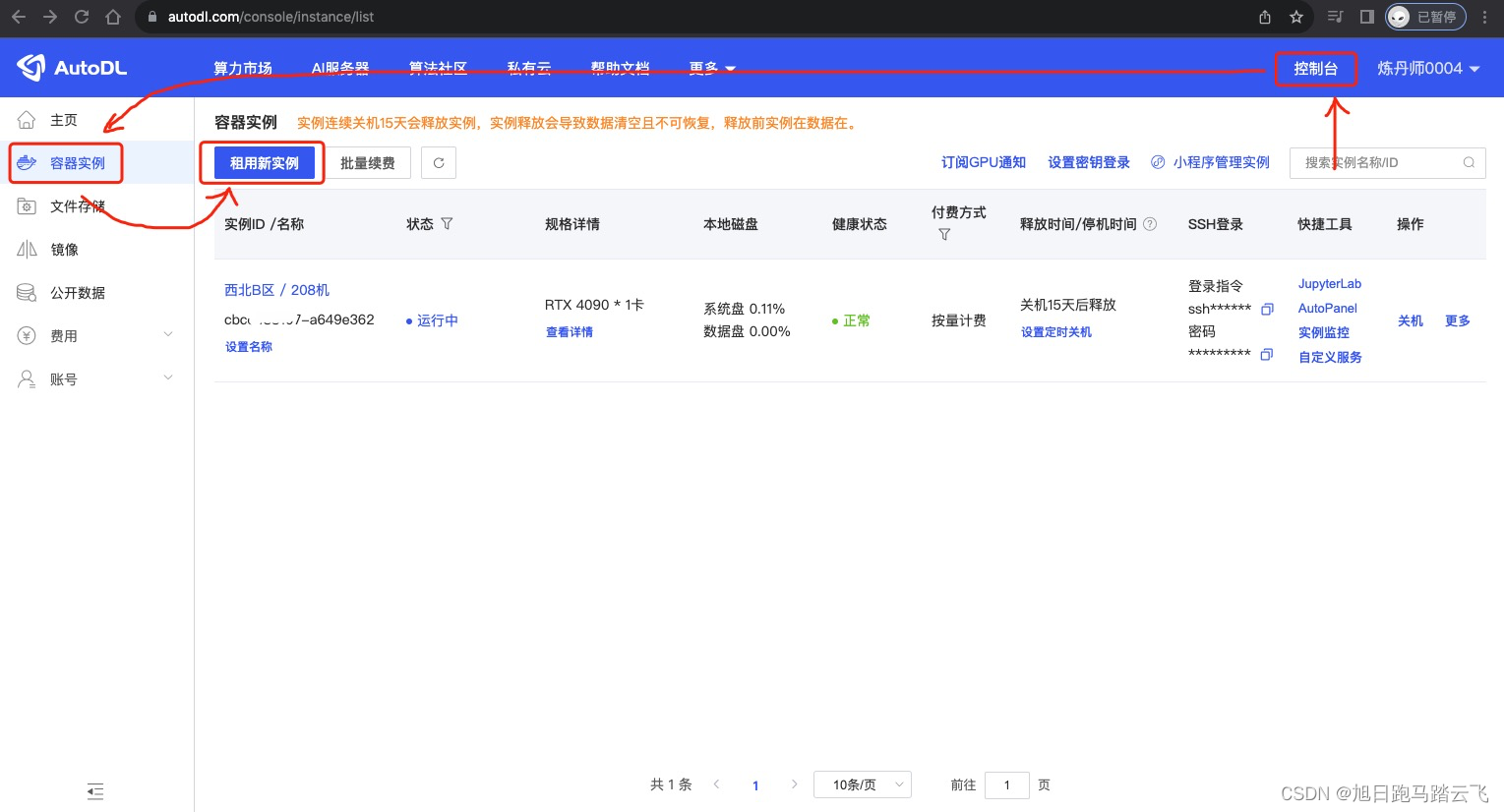 进入后可以选择新实例的配置:付费方式/GPU型号等:
进入后可以选择新实例的配置:付费方式/GPU型号等:
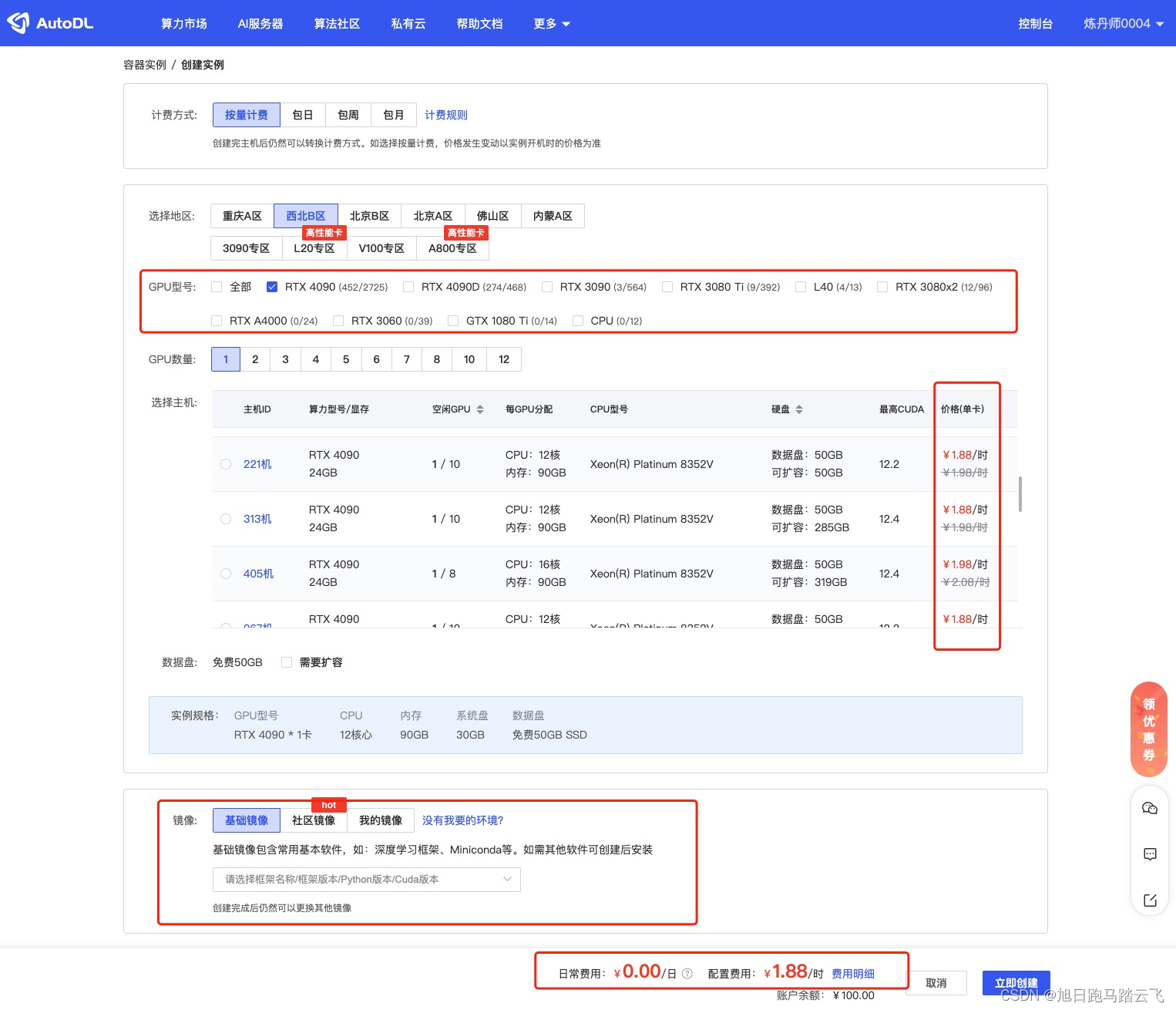
选择好硬件后,选择系统镜像:
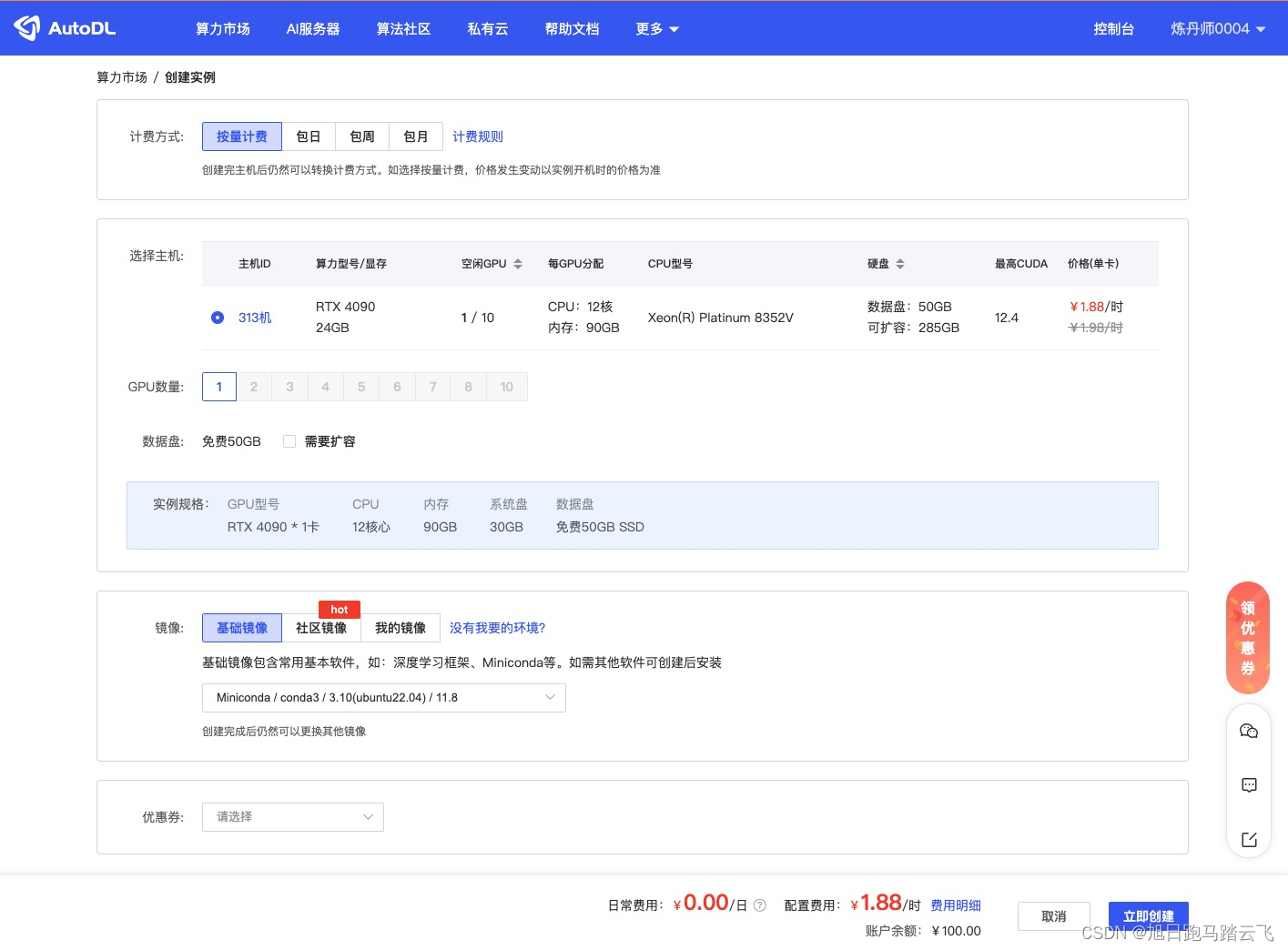
默认镜像还是比较全的,这里选择miniconda:
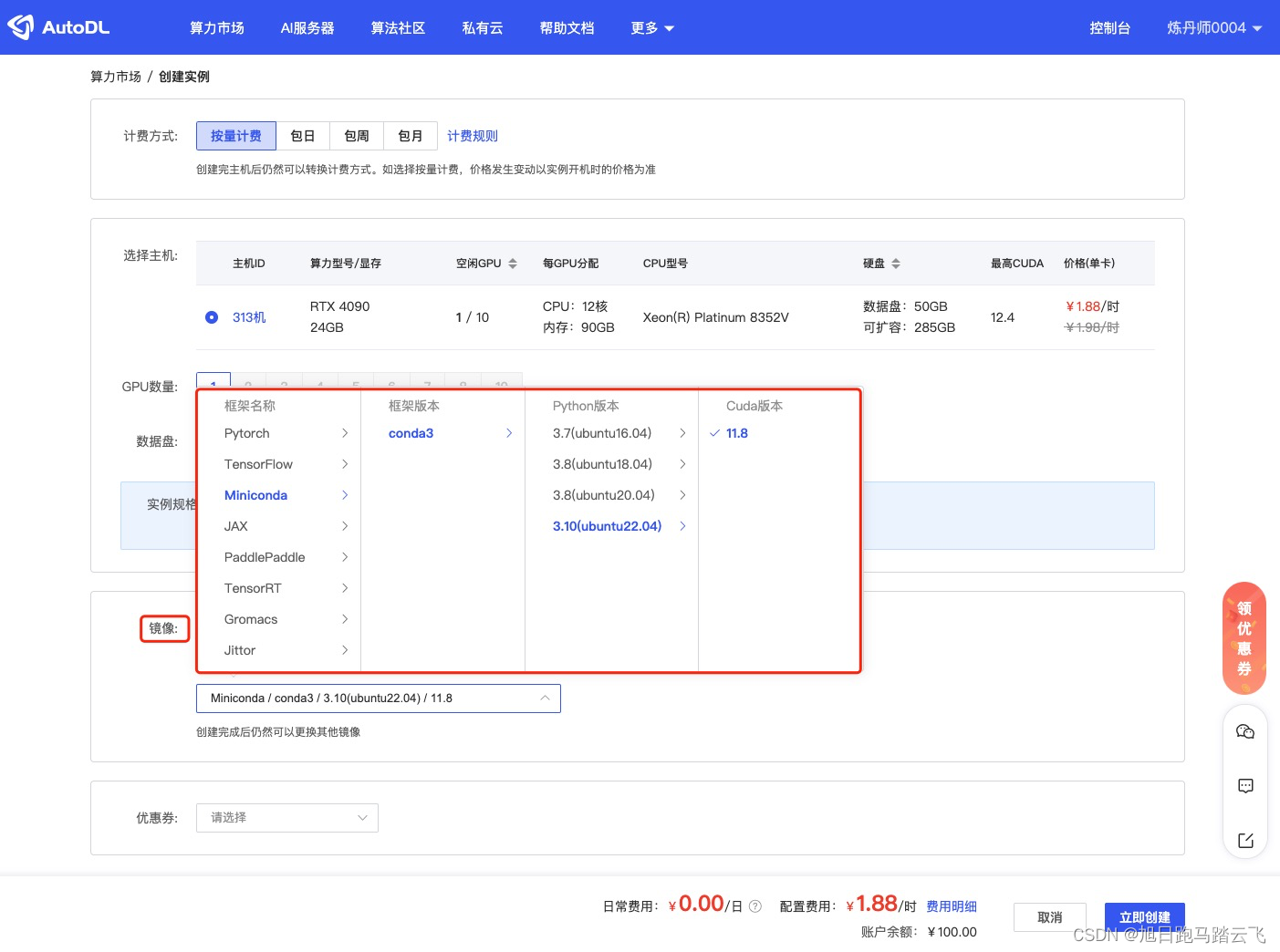
点击“立即创建”后,稍等一下,跳转到“容器实例”页面,等状态变为“运行中”时,代表已经可以远程登录:
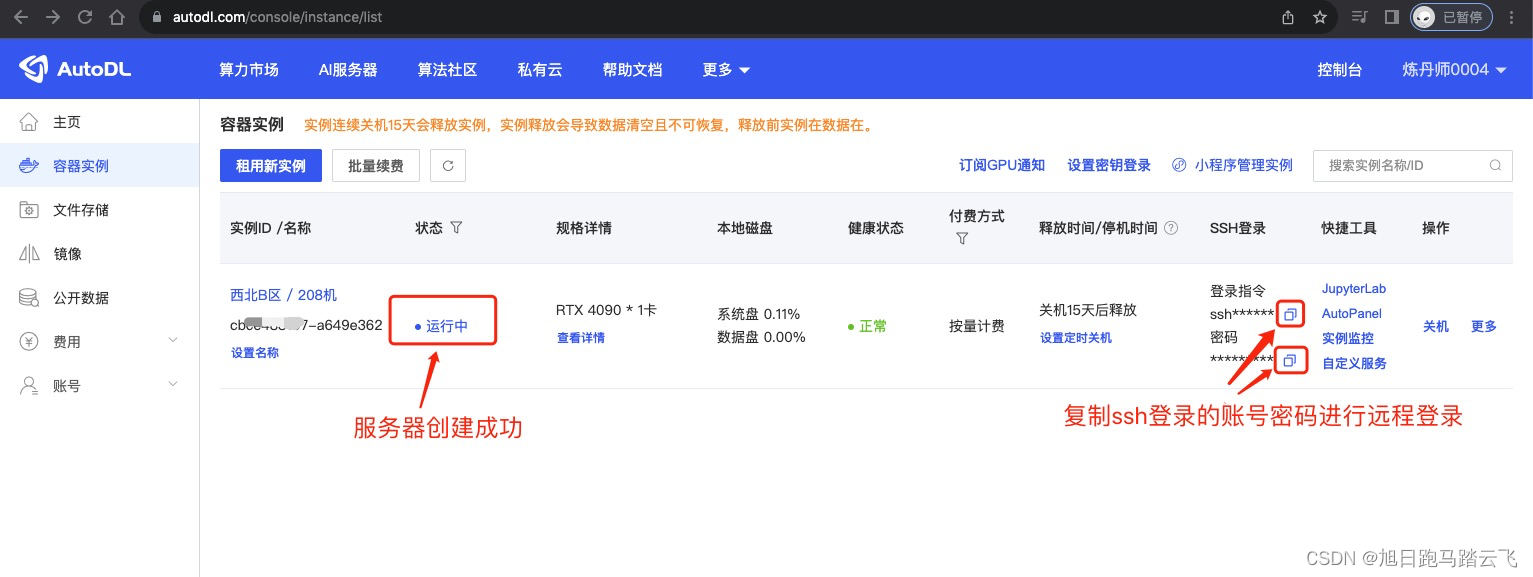
1.3 登录服务器
复制上图中的ssh账号密码,登录服务器:
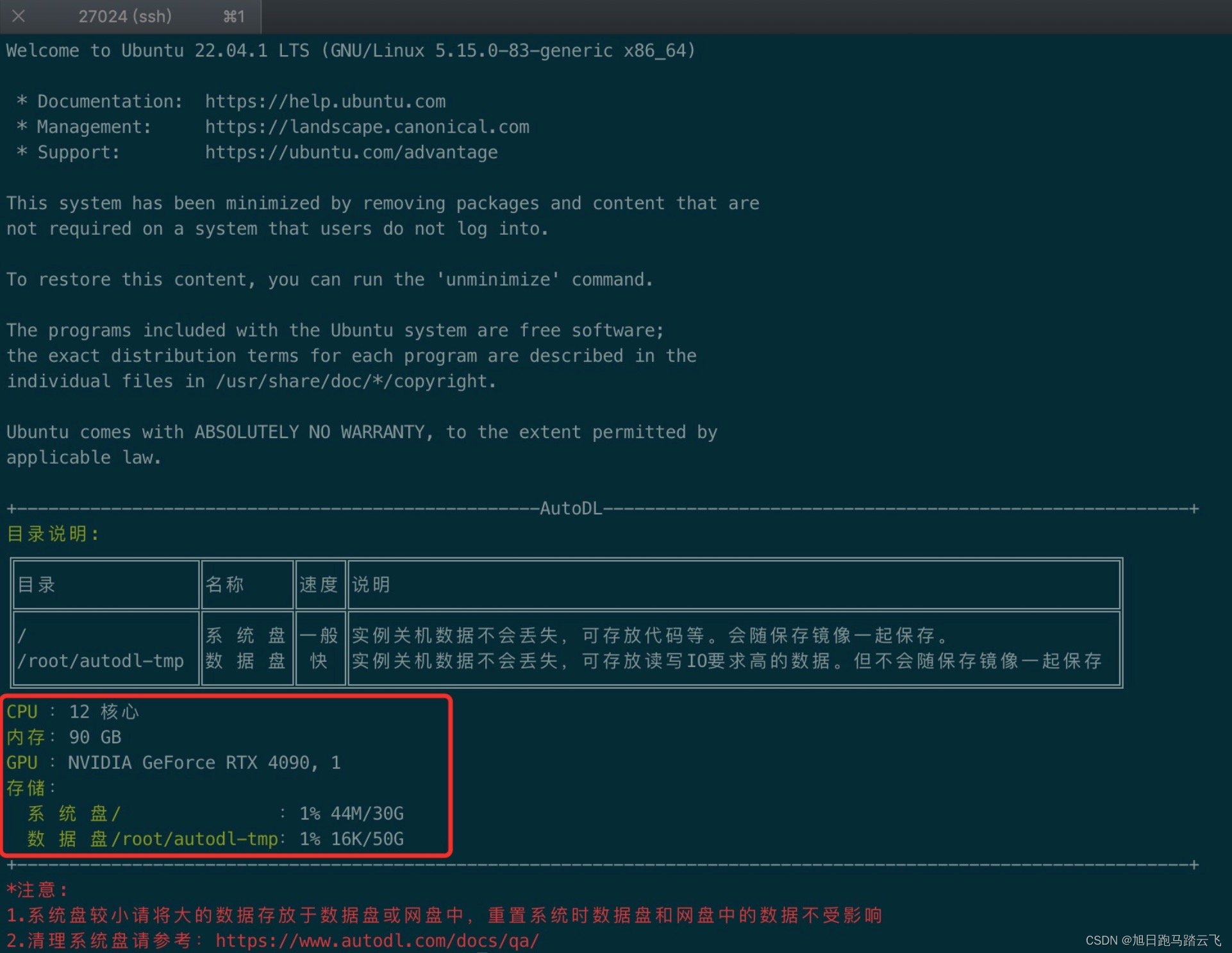
登陆后显示了服务器的相关配置。
二、配置服务器
2.1 配置加速器
为了加快下载速度,aotuDL提供了学术资源加速:https://www.autodl.com/docs/network_turbo/ | 学术资源加速
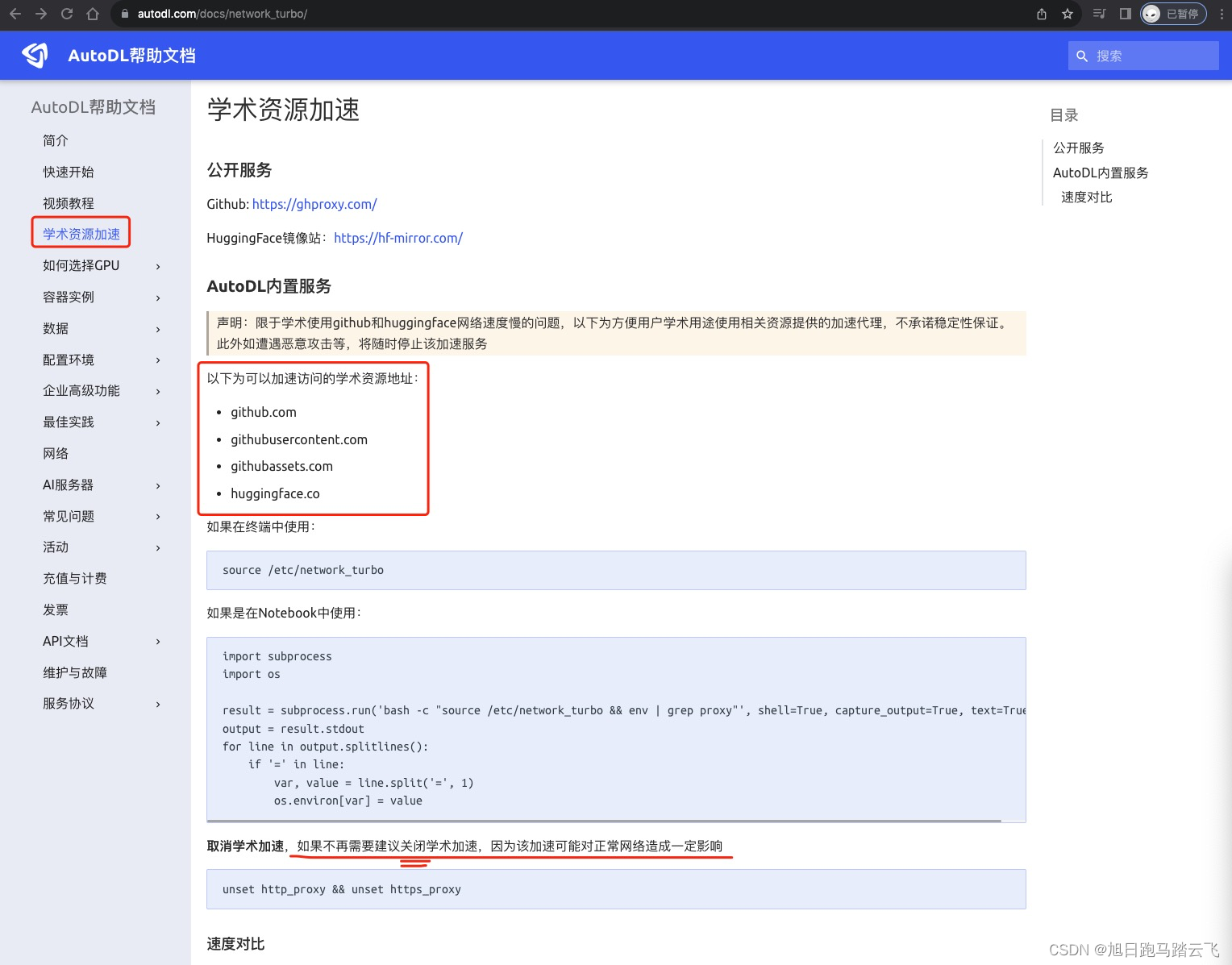
从文档了解,当我们需要下载大模型的时候可以打开,下载完成后最好关闭加速。
执行加速命令:
> source /etc/network_turbo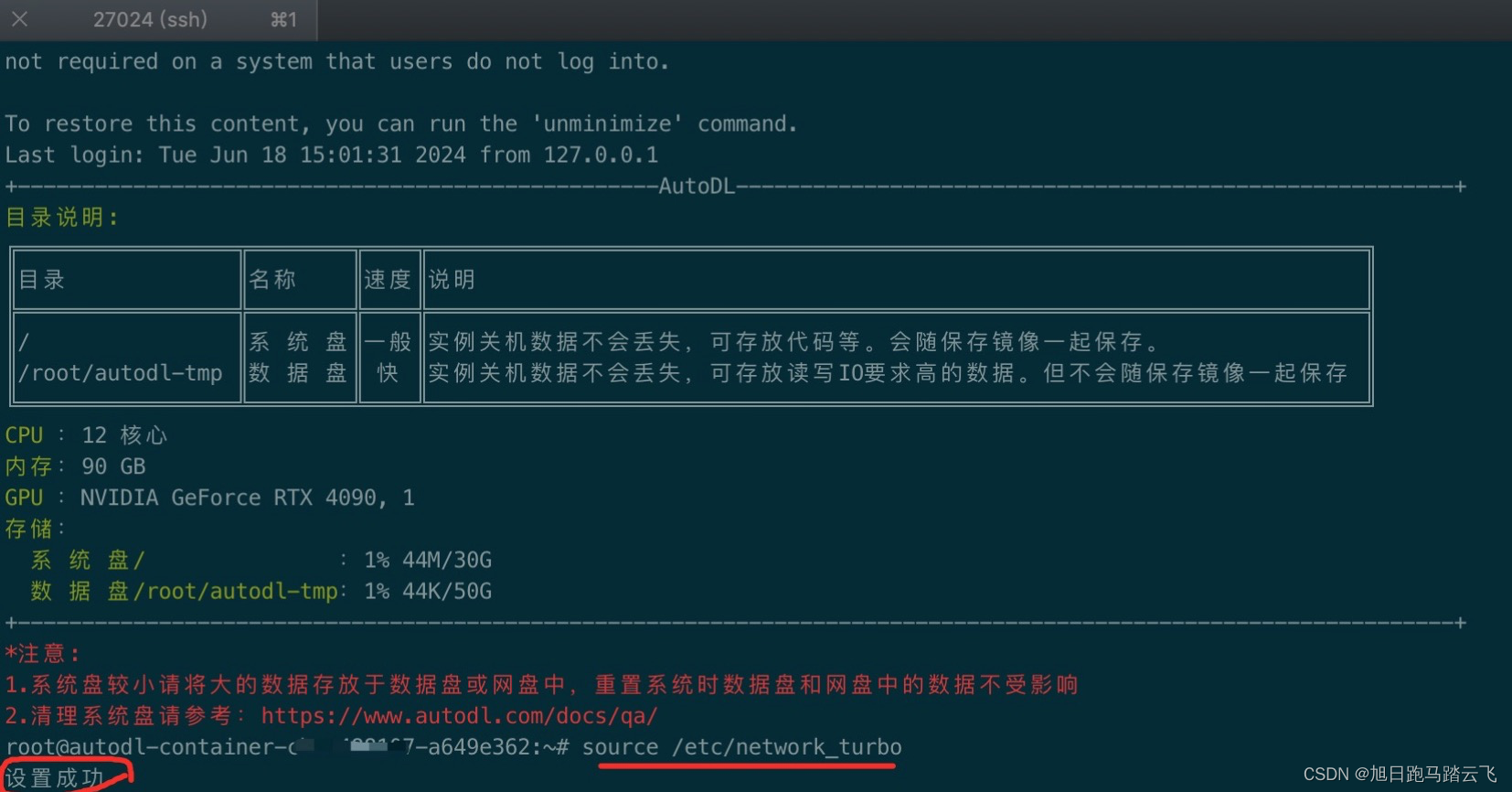
2.2 安装ollama
ollama的介绍请参考:【AI基础】大模型部署工具之ollama的安装部署。
官网:https://ollama.com/
快速入门:https://github.com/ollama/ollama/blob/main/README.md#quickstart
快速入门的部署界面,
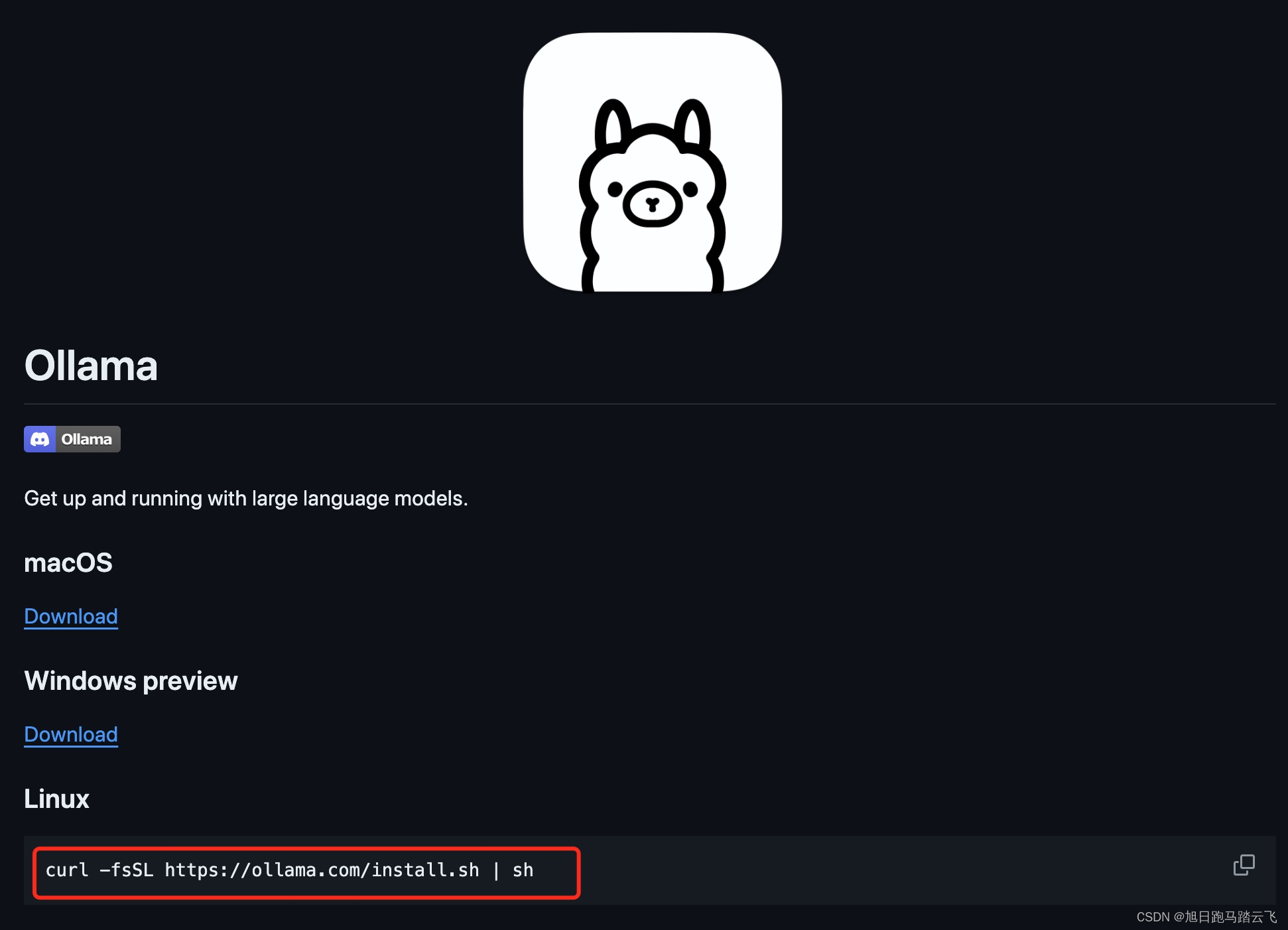 因为autoDL对应的服务器是ubuntu,我们找到linux的命令:
因为autoDL对应的服务器是ubuntu,我们找到linux的命令:
> curl -fsSL https://ollama.com/install.sh | sh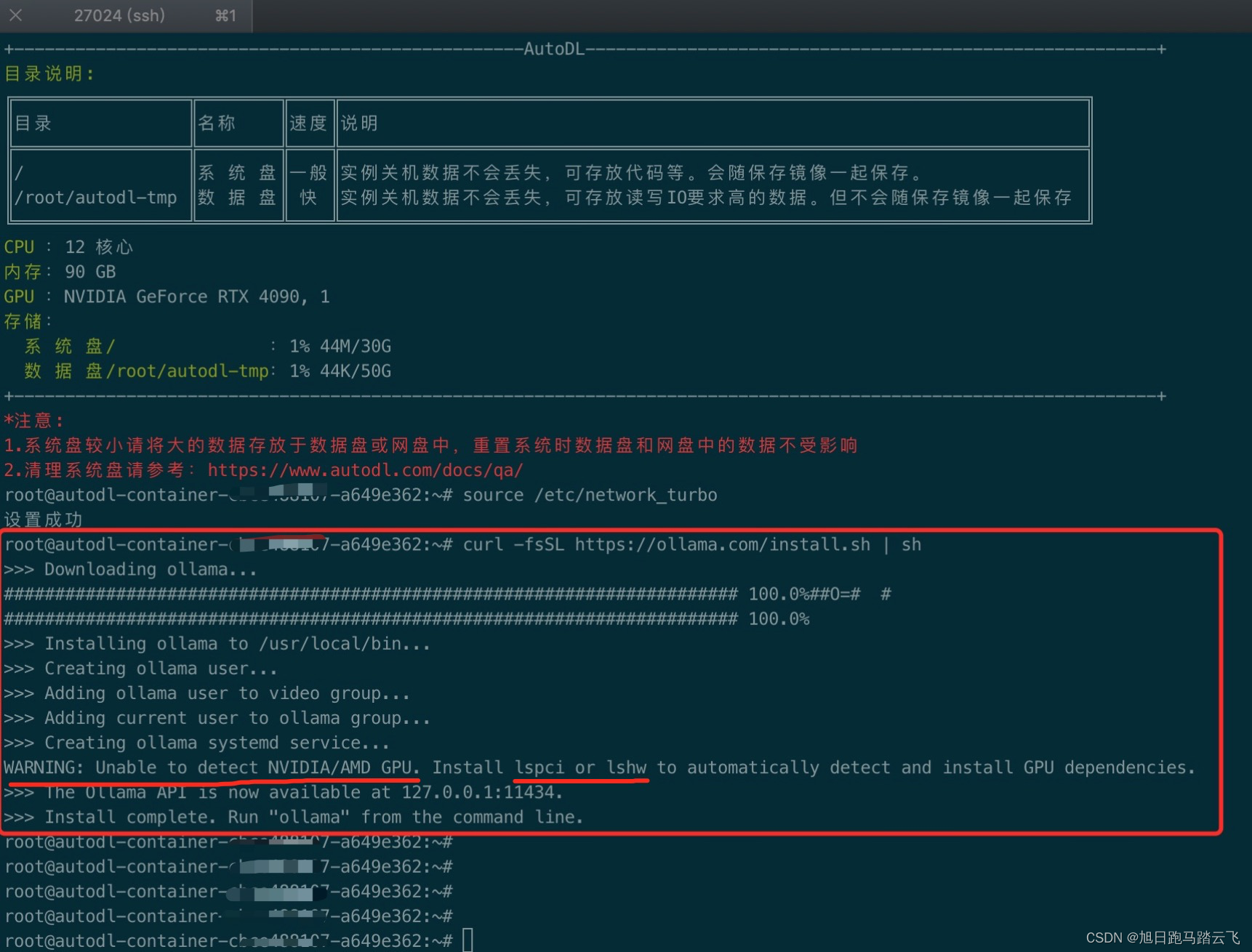
从上图可以看出,有个依赖需要安装,这个要看部署的服务器情况,有时候缺少有时候又是ok的,缺少什么就安装什么,安装对应的依赖后重新安装ollama就好了。
这里执行命令安装lshw:
> sudo apt-get update
> sudo apt-get install lshw然后重新执行ollama安装命令:
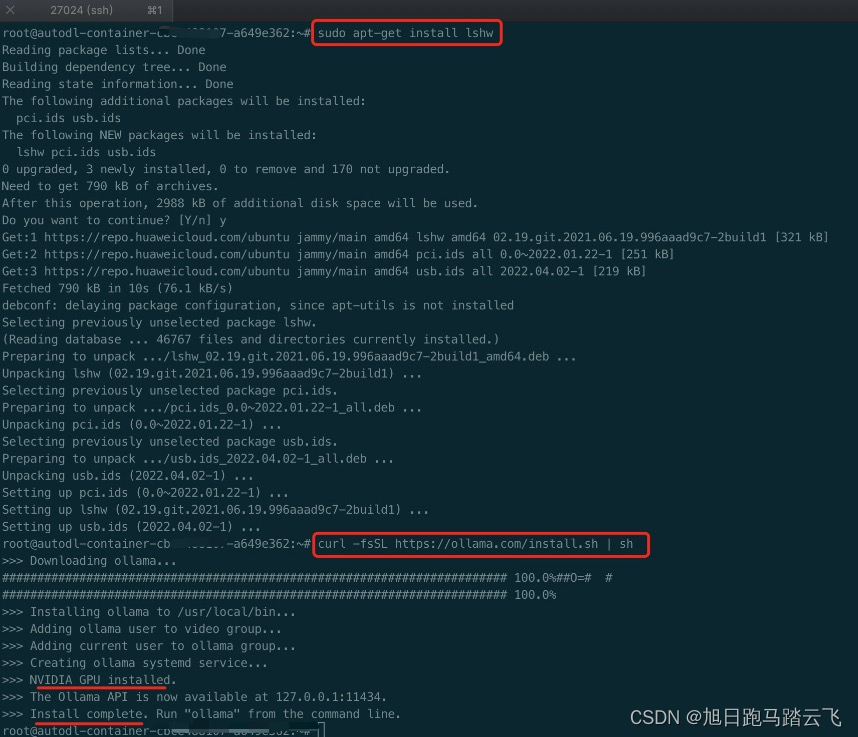
安装成功。
2.3 检验ollama
ollama安装成功后默认以服务形式运行,运行命令检查状态:
> systemctl status ollama.service结果发现出现错误:
System has not been booted with systemd as init system (PID 1). Can't operate.
Failed to connect to bus: Host is down

可以看出 systemctl 命令异常,需要安装 systemd和systemctl:
> apt-get install systemd -y
> apt-get install systemctl -y安装完成后,重新运行systemctl:
> systemctl start ollama.service
> systemctl status ollama.service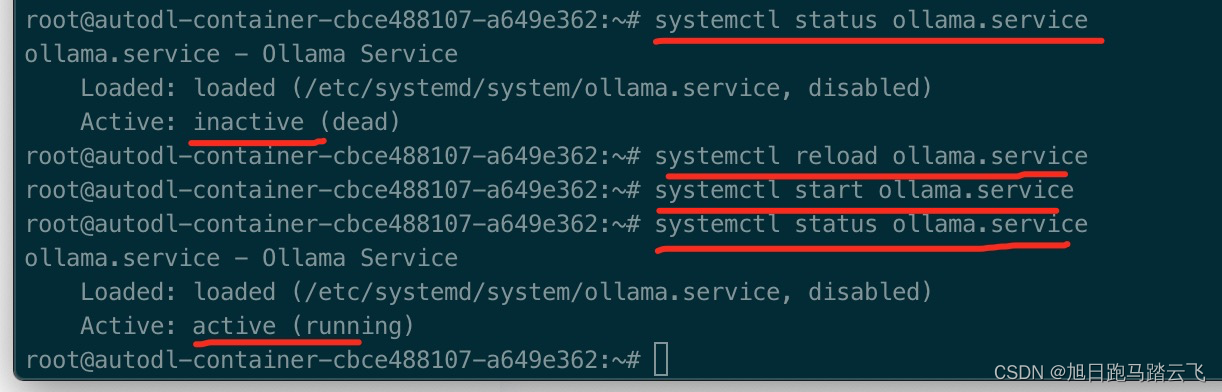 ollama服务已启动,运行ollama命令:
ollama服务已启动,运行ollama命令:
> ollama -v
> ollama list
> ollama ps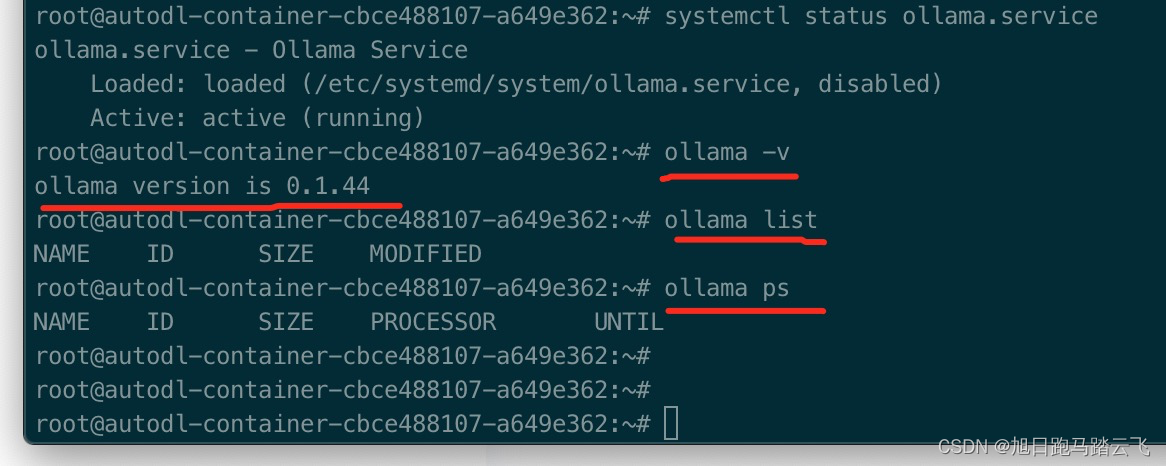 ollama运行正常。
ollama运行正常。
三、部署大模型
3.1 部署大模型
参考 【AI基础】大模型部署工具之ollama的安装部署 ,这里我们还是部署llama3:
> ollama pull llama3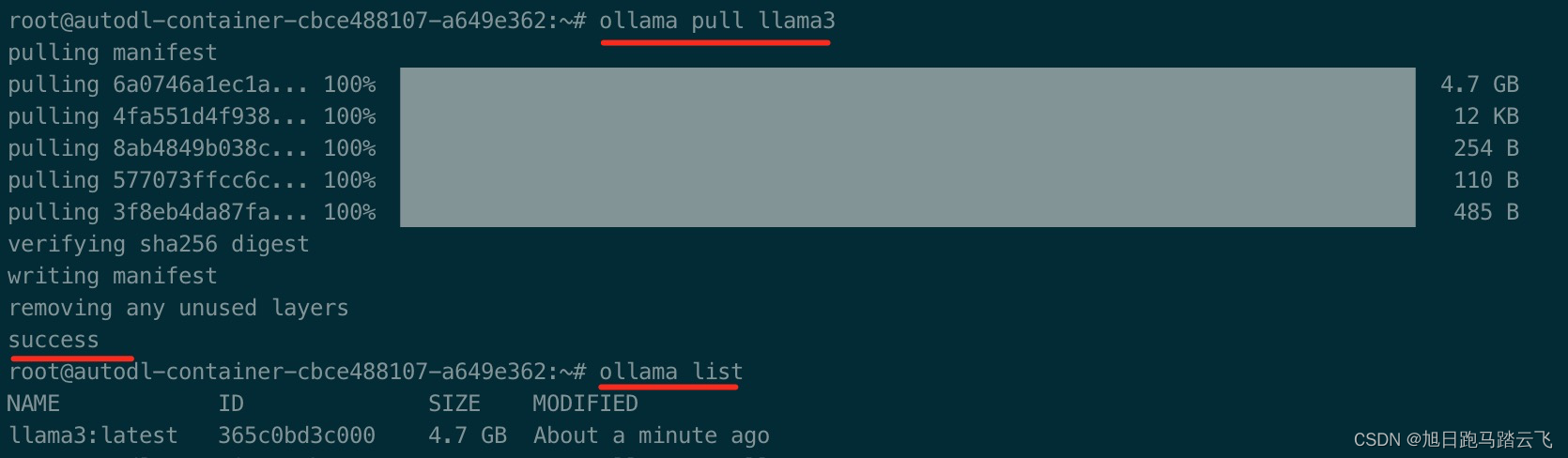
3.2 检验
通过 ollama run llama3 启动llama3,接下来可以直接跟llama3对话,在三个箭头➡️后输入问题,llama3会给出回应:
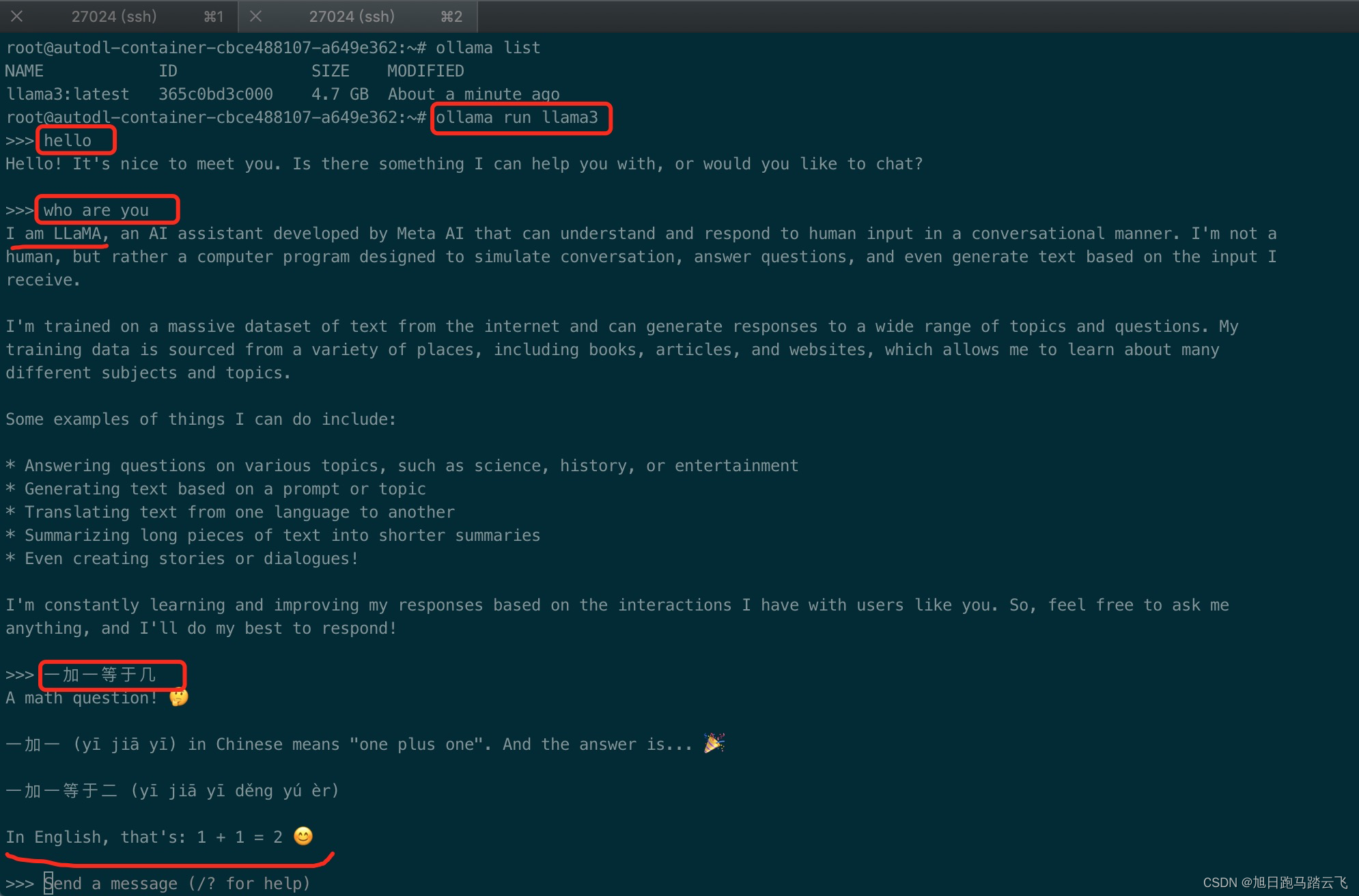
相比于本地环境,autoDL的服务器真的是秒回。有米就是了不起啊。
这篇关于【AI基础】租用云GPU之autoDL部署大模型ollama+llama3的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







