autodl专题

解决AutoDL远程服务器训练大模型的常见问题:CPU内存不足与 SSH 断开
在使用远程服务器(如 AutoDL)进行深度学习训练时,通常会遇到一些常见问题,比如由于数据加载导致的内存消耗过高,以及 SSH 连接中断后训练任务被迫停止。这篇文章将介绍我在这些问题上遇到的挑战,并分享相应的解决方案。 问题 1:内存消耗过高导致训练中断 问题描述 在深度学习大模型训练过程中,数据加载是一个消耗内存的重要环节。特别是在使用大规模数据集和多线程数据加载时,内存消耗可能会迅速增

解决方案:在autodl环境下为什么已安装torch打印出来版本号对应不上
文章目录 一、现象二、解决方案 一、现象 平台:autodl 镜像:PyTorch 2.0.0 Python 3.8(ubuntu20.04) Cuda 11.8 GPU:A40(48GB) * 1 CPU:15 vCPU AMD EPYC 7543 32-Core Processor 内存:80GB 安装torch:1.13.0环境,发现执行下面的命令行之后,也显示安装

| AutoDL租服务器 |AutoDL租服务器保姆级教程
🐑 | AutoDL租服务器 |AutoDL租服务器保姆级教程 🐑 文章目录 🐑 | AutoDL租服务器 |AutoDL租服务器保姆级教程 🐑🐑 前言🐑🐑 实例创建🐑🐑 环境配置🐑🐑 数据上传🐑🐑 上传系统盘🐑🐑 上传数据盘🐑🐑 Xshell上传数据🐑 🐑 代码运行🐑🐑 总结🐑 🐑 前言🐑 由于现在神经网络架构发

解决方案:在autodl环境下安装torch被killed掉
文章目录 一、现象二、解决方案 一、现象 平台:autodl 镜像:PyTorch 2.0.0 Python 3.8(ubuntu20.04) Cuda 11.8 GPU:A40(48GB) * 1 CPU:15 vCPU AMD EPYC 7543 32-Core Processor 内存:80GB 安装torch:1.13.0环境,发现执行下面的命令行都不行**(不行

工具技巧:如何使用AutoDL算力云
AutoDL算力云可以快速构建编程环境,价格也很实惠 模型运行已知需要显存少,可以考虑选择4090,有24G,具体选择哪种类型,可以看看重点看看这两方面**:数据盘能否扩容,CUDA版本是否够高** 根据自身需要选择基础镜像还是社区镜像(这里我选择的是基础镜像,里面也可以用github、huggingface、hf镜像等) 点击创建后,显示的环境如下: 点击JupyterLab,进
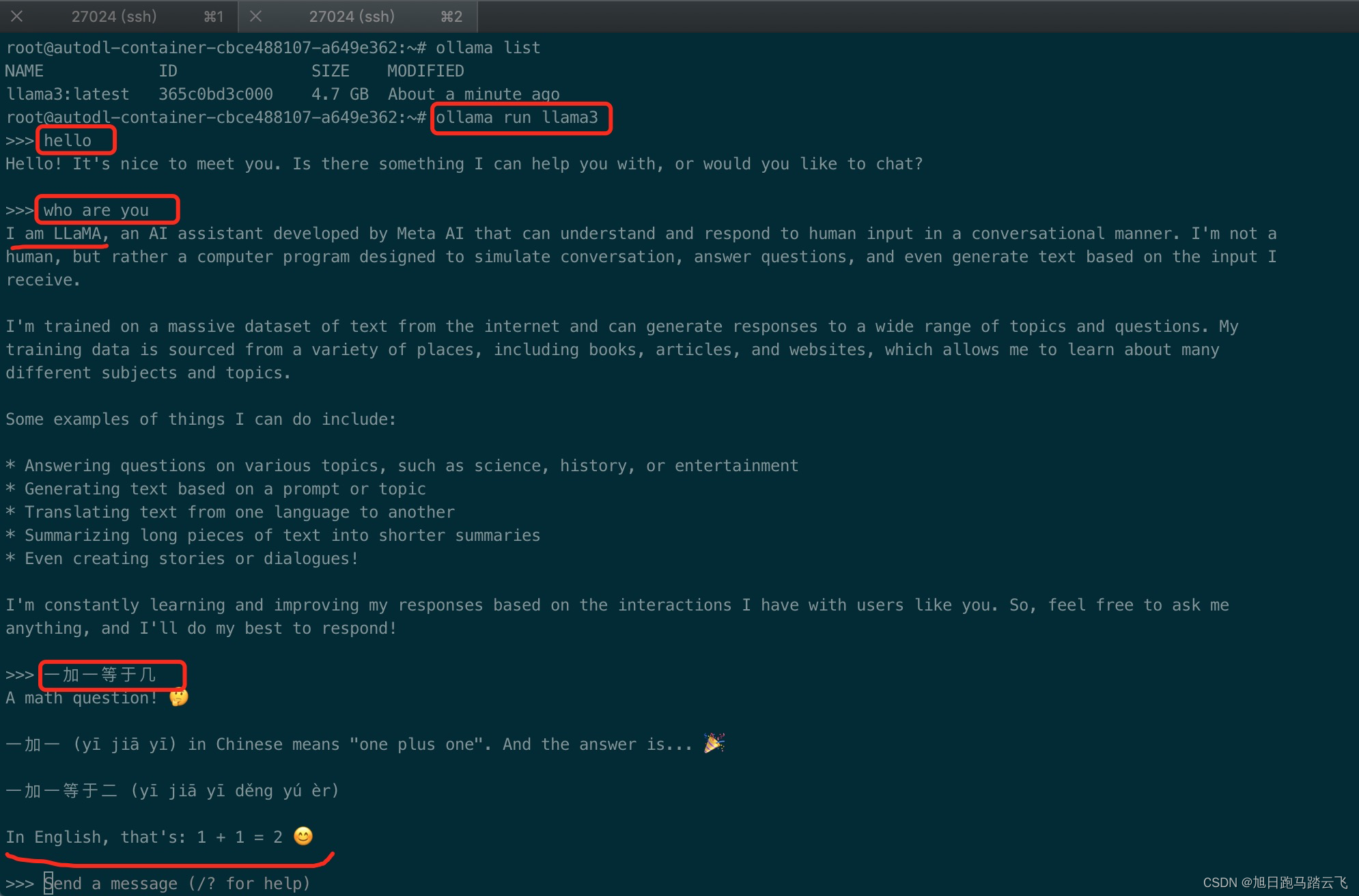
【AI基础】租用云GPU之autoDL部署大模型ollama+llama3
在这个显卡昂贵的年代,很多想要尝试一下AI的人可能都止步于第一步。这个时候我们可以租用在线的GPU资源来使用AI。autoDL就是这样的一个云平台。 一、创建服务器 1.1 注册账号 官网:https://www.autodl.com/ | 租GPU就上AutoDL 帮助文档:https://www.autodl.com/docs/ | AutoDL帮助文档 登录官网,注册账号。 1
[AI基础]租用云GPU之autoDL部署大模型ollama+llama3
在这个显卡昂贵的年代,很多想要尝试一下AI的人可能都止步于第一步。这个时候我们可以租用在线的GPU资源来使用AI。autoDL就是这样的一个云平台。 一、创建服务器 1.1 注册账号 官网:https://www.autodl.com/ | 租GPU就上AutoDL 帮助文档:https://www.autodl.com/docs/ | AutoDL帮助文档 登录官网,注册账号。 1

使用autodl服务器进行模型训练
1.注册并且选择一个服务器租用 2.点击jupyter lab进入服务器内部 3.把yolov5-master这个的压缩文件上传到jupyter的文件列表中 4.打开终端 (1)查看目录 ls (2)解压yolov5-master(1) unzip "yolov5-master (1).zip" 可以看到解压成功! (3)进入yolov5-master这
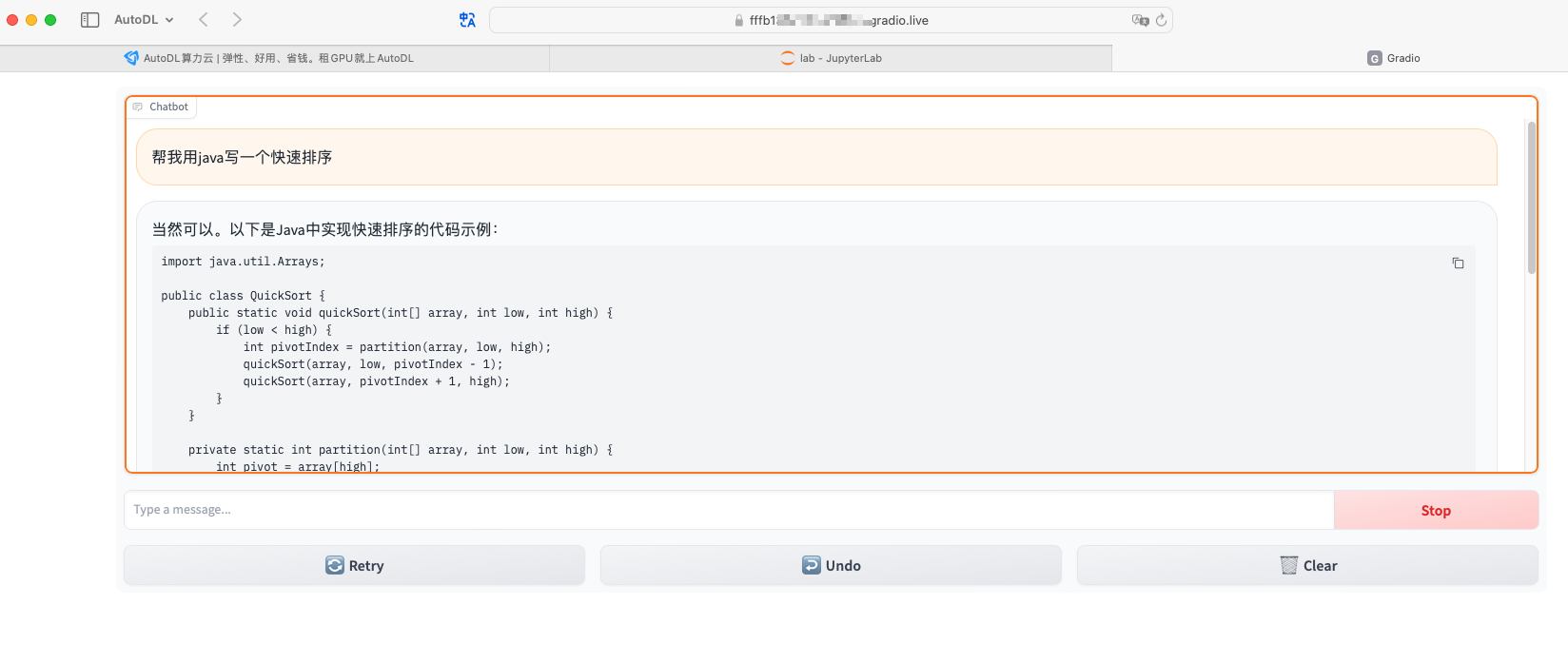
在AutoDL上部署Yi-34B大模型
在AutoDL上部署Yi-34B大模型 Yi介绍 Yi 系列模型是 01.AI 从零训练的下一代开源大语言模型。Yi 系列模型是一个双语语言模型,在 3T 多语言语料库上训练而成,是全球最强大的大语言模型之一。Yi 系列模型在语言认知、常识推理、阅读理解等方面表现优异。 Yi-34B-Chat 模型在 AlpacaEval Leaderboard 排名第二,仅次于 GPT-4 Turbo,
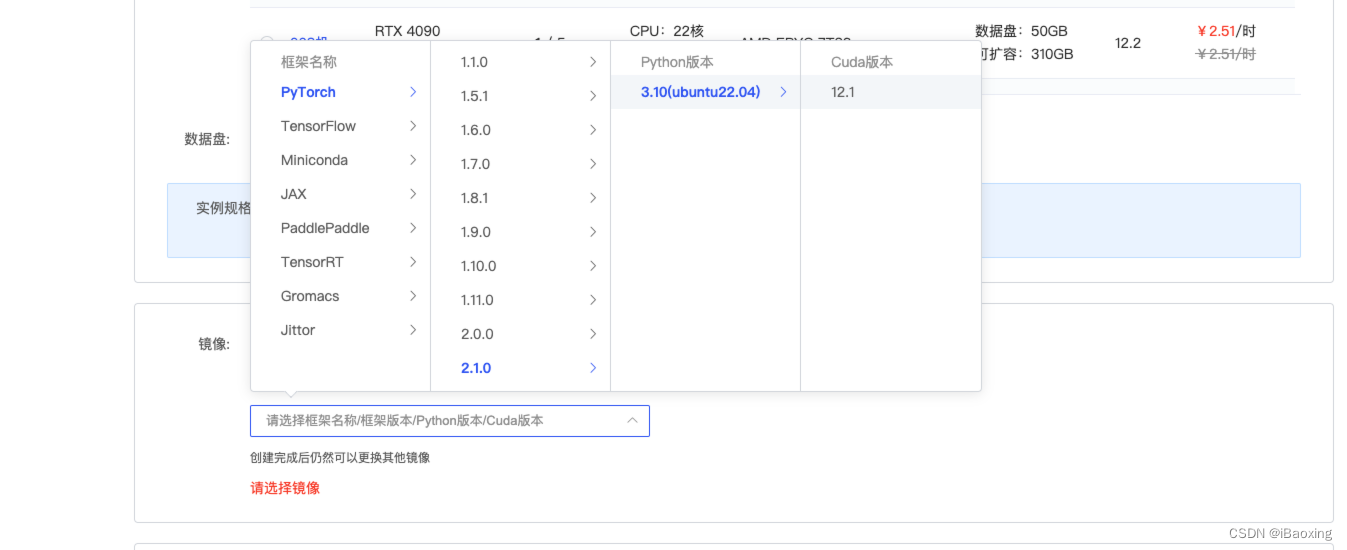
AutoDL搭建 ChatGLM3
租用新实例 这里选择的西北 B 区、RTX 409024GB 创建虚拟环境并激活 # 安装虚拟环境至数据盘conda create --prefix /root/autodl-tmp/envs/chatglm3-demo python=3.10# 激活虚拟环境conda activate /root/autodl-tmp/envs/chatglm3-demo 拉取ChatGLM3
云服务器平台AutoDL--基本介绍与使用感受
因为课程作业需要复现DreamBooth,找了几个教程之后,发现了AutoDL这个好东西,芜湖~ 相关概念 以下回答来自于ChatGPT。 云计算平台:云服务器平台是提供按需计算资源和服务的在线平台,通常包括存储、处理能力、数据库、网络等。 实例:在云计算平台中,“实例”通常是指一个虚拟服务器或虚拟机(Virtual Machine, VM),它运行在云提供商的基础设施上。实例是云计算

AutoDL中Notebook中无法打开“checkpoints”文件夹
checkpoints是Notebook的关键字,若用户创建文件夹命名为checkpoints,则在JupyterLab上无法打开、重命名和删除。此时可以在Terminal里使用命令行打开checkpoints,或者新建文件夹将checkpoints里的数据移动到新的文件夹下。 操作步骤: 打开Terminal,用命令行进行操作。 方法一:执行cd checkpoints命令打开checkp

Vision Mamba 代码调试---Pycharm+AutoDL
《AutoDL使用手册》 1. 服务器租用与配置 先上项目链接: GitHub - hustvl/Vim: Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model 1.1 服务器租用与配置 根据环境要求,去租一个服务器:AutoDL算力云 | 弹性

【LocalAI】(10):在autodl上编译embeddings.cpp项目,转换bge-base-zh-v1.5模型成ggml格式,本地运行main成功
1,关于 localai LocalAI 是一个用于本地推理的,与 OpenAI API 规范兼容的 REST API。 它允许您在本地使用消费级硬件运行 LLM(不仅如此),支持与 ggml 格式兼容的多个模型系列。支持CPU硬件/GPU硬件。 【LocalAI】(10):在autodl上编译embeddings.cpp项目,转换bge-base-zh-v1.5模型成ggml格式
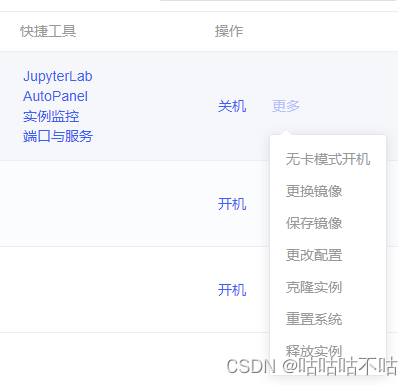
autodl私有云使用方法(成员端使用)
此时找管理员添加进团队,https://private.autodl.com/访问,登录账号。可以看到容器实例。 点击创建实例,根据所需创建。版本号不可以超过最高的CUDA支持,可以自己拉取镜像。 此处需要注意数据盘使用量,密切关注。存取传输数据时请选择无卡模式开机,否则GPU会分配,导致GPU空载。 然后创建所需镜像,第一次拉取镜像会比较慢,请耐心等待。 这样就是创建完成。 复制登陆
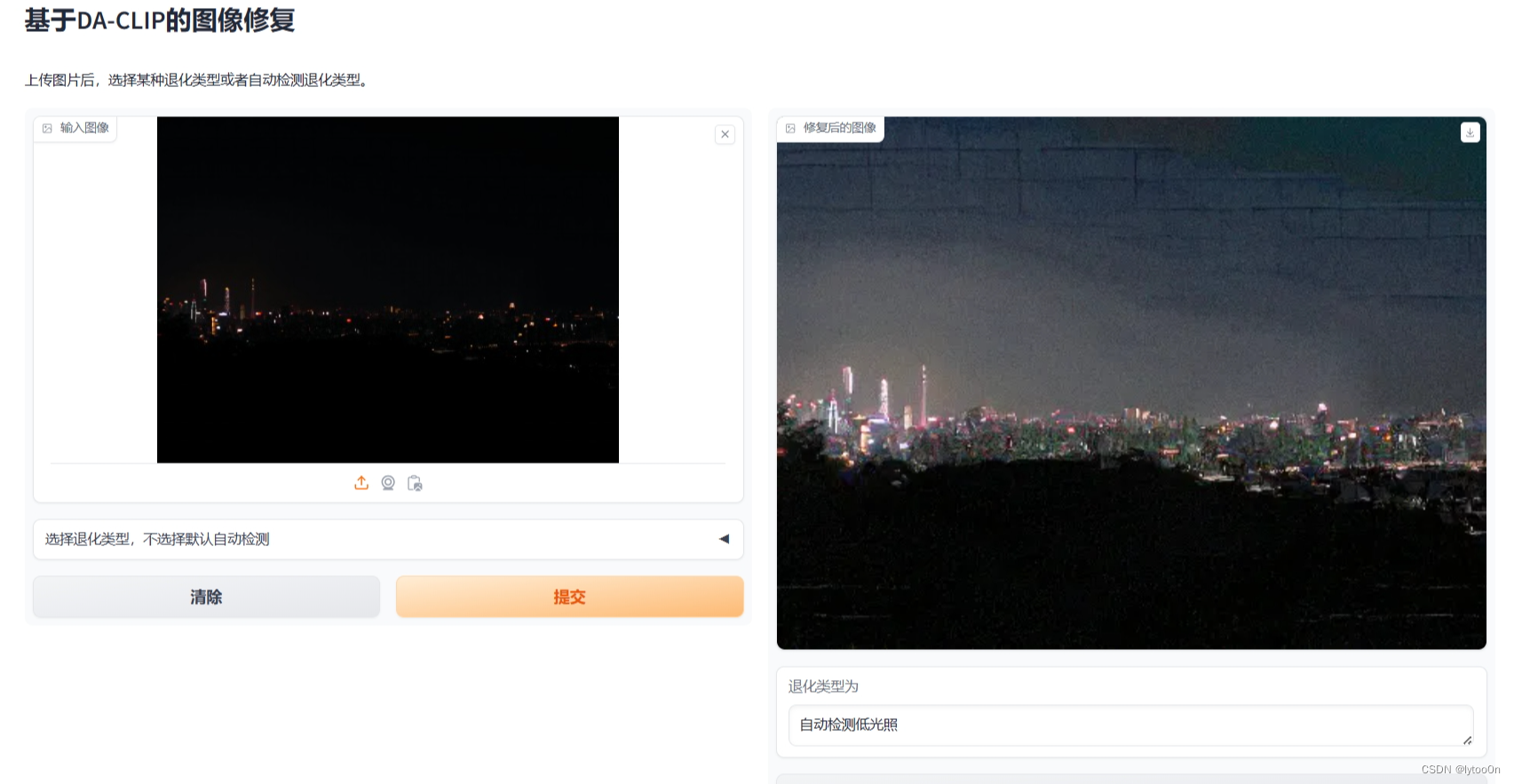
【DA-CLIP】图像复原在AutoDL上部署测试
起因: 虽然在本机Windows部署成功运行,但是由于计算资源少只有6G的GPU无法计算手机拍摄图像复原和其他一些数据集测试,尝试租用AutoDL的服务器部署测试 租AutoDL 租的人很多,刚确定运行的镜像环境就报告说这个机子已经没卡了,又换了一台4090 上传权重文件、项目文件 没用网盘和filezilla那些AutoDL帮助文档,一开始AutoDL文件存储 传了不同区,
使用Autodl与Xftp远程训练模型及管理远程文件
1 AutoDL网站登录创建实例 AutoDL网站:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL 1)进入算力市场,选取可用显卡(工作日一般白天抢不到,晚上才能抢到) 2)选择配置环境 3)创建成功实例 之后配置环境时建议先关机,再在“更多”中选择无卡模式启动(0.01yuan/h) 无卡模式可以传输文件等等 复制并查看登陆指令与密码 格式应该如下(指令
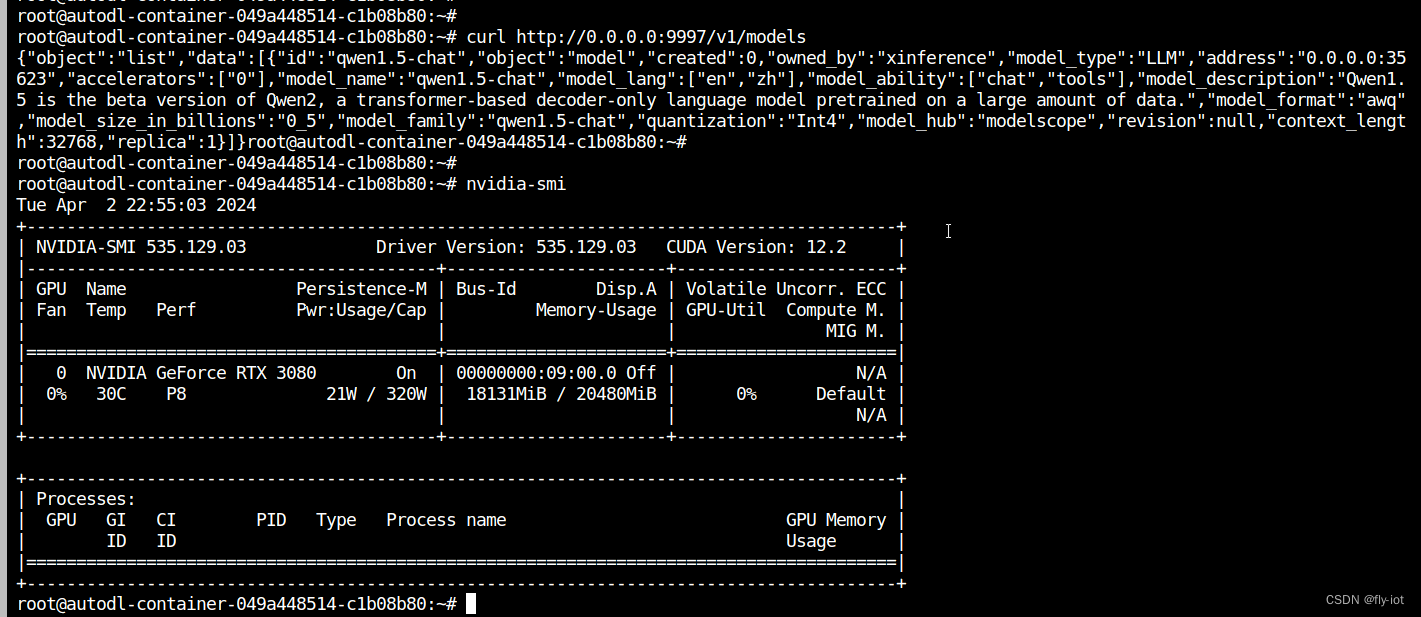
【xinference】(8):在autodl上,使用xinference部署qwen1.5大模型,速度特别快,同时还支持函数调用,测试成功!
1,关于xinference Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。 Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(
AutoDL算力云进行yolov5训练流程
目录 第一步 充值第二步 选择我们用到的显卡第三步 将我们的yolov5源代码导入服务器第四步 激活环境第五步 训练第六步 训练完成 提取 第一步 充值 打开我们的算力云官网 然后找到充值入口 最低充值50 第二步 选择我们用到的显卡 一般呢我都用便宜的2080ti 选择2080ti之后 基础镜像 之后就可以立即创建了 ,我们的服务器就启动了,点击第一行JupyterL
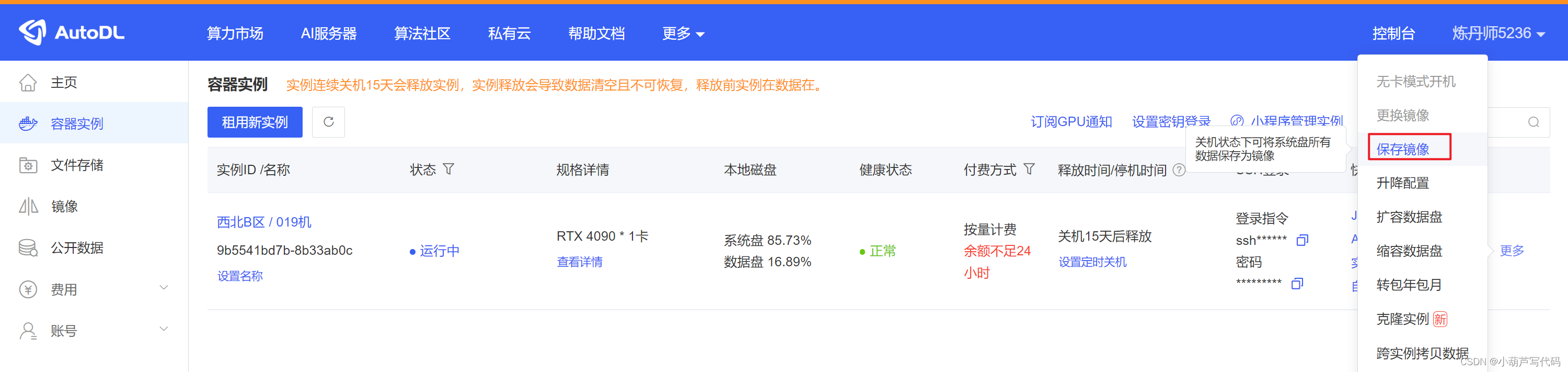
在autodl搭建stable-diffusion-webui+sadTalker
本文介绍在autodl.com搭建gpu服务器,实现stable-diffusion-webui+sadTalker功能,图片+音频 可生成视频。 autodl租GPU 自己本地部署SD环境会遇到各种问题,网络问题(比如huggingface是无法访问),所以最好的方式是租用GPU,可以通过以下视频了解如何使用autodl.com AutoDL算力云 | 弹性
使用Autodl云服务器或其他远程机实现在本地部署知识图谱数据库Neo4j
本篇博客的目的在于提高读者的使用效率 温馨提醒:以下操作均可在无卡开机状态下就可完成 一.安装JDK 和 Neo4j 1.1 ssh至云服务器 打开你的pycharm或者其他IDE工具或者本地终端,ssh连接到autodl的服务器。(这一步很简单如下图) 1.2 安装JDK 由于我想使用Neo4j的最新版,所以需要安装JDK=21的版本: 直接按照下述命令依次进行即可: 更新包管理器
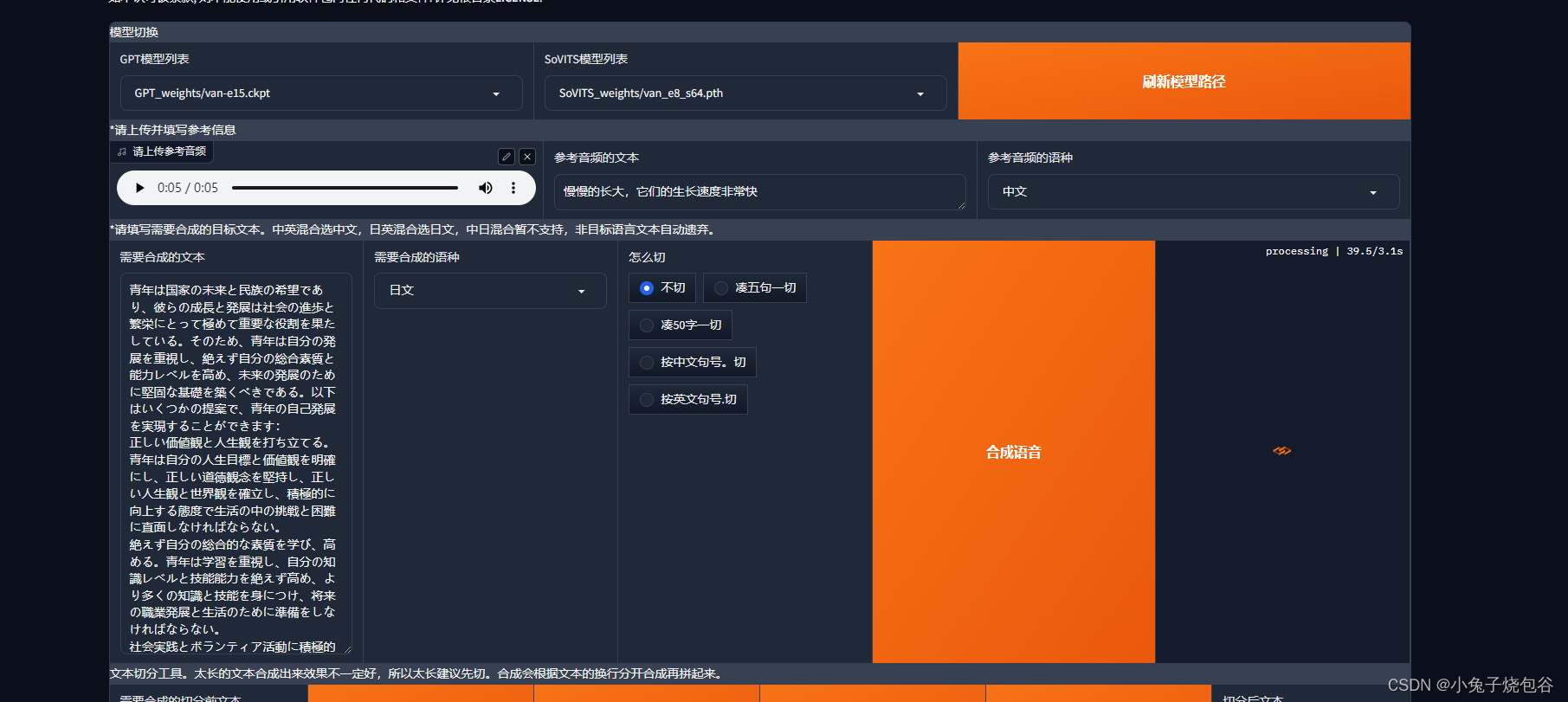
GPT-SoVITs从零开始训练声音克隆教程(以云端AutoDL部署为例)【教程超详细】
打开网站 https://www.autodl.com/ 注册账户和和实名认证、绑定微信才能使用。操作完成后选择镜像购买。 等待创建完成 创建完成单击JupyterLab 在文件GPT-Sovits(使用).ipynb拉到最下面 先运行下图框中命令 再运行下图框中命令,然后单击蓝色链接 打开页面如下所示 单击是否开启UVR5-WebUl 打开UVR5-WebUl页面 打开页面如下
AutoDL----VScode远程ssh连接
1、首先安装ssh插件 首先安装插件,在商店里抖索remote-ssh 2、建立连接 安装完成后在插件栏就会看到远程连接这一栏 点击添加后会让你输入ssh的地址,直接复制AutoDL的,按下Enter,选择第一个配置文件 选择Linux平台 继续后会让输入密码,直接输入即可 之后就登陆成功,可以进行操作了。

【超详细教程】GPT-SoVITs从零开始训练声音克隆教程(主要以云端AutoDL部署为例)
目录 一、前言 二、GPT-SoVITs使用教程 2.1、Windows一键启动 2.2、AutoDL云端部署 2.3、人声伴奏分离 2.4、语音切割 2.5、打标训练数据 2.6、数据集预处理 2.7、训练音频数据 2.8、推理模型 三、总结 一、前言 近日,RVC变声器的创始人(GitHub昵称为RVC-Boss)与AI音色转换技术专家Rcell合作,共同开
Pycharm连接云算力远程服务器(AutoDL)训练深度学习模型全过程
前言:在上一篇windows搭建深度学习环境中,我试图使用笔记本联想小新air14的mx350显卡训练一个图像检测的深度学习模型,但是训练时长大概需要几天时间远超我的预期,所以我便选择租用GPU进行训练,在对多家平台对比后找到了经济实惠的AutoDL,接下来是我租用GPU–配置环境–连接Pycharm–训练模型的全过程,基于本人也是刚入门的新手,如果有不恰当的地方还请大家指教。 一、租用GPU
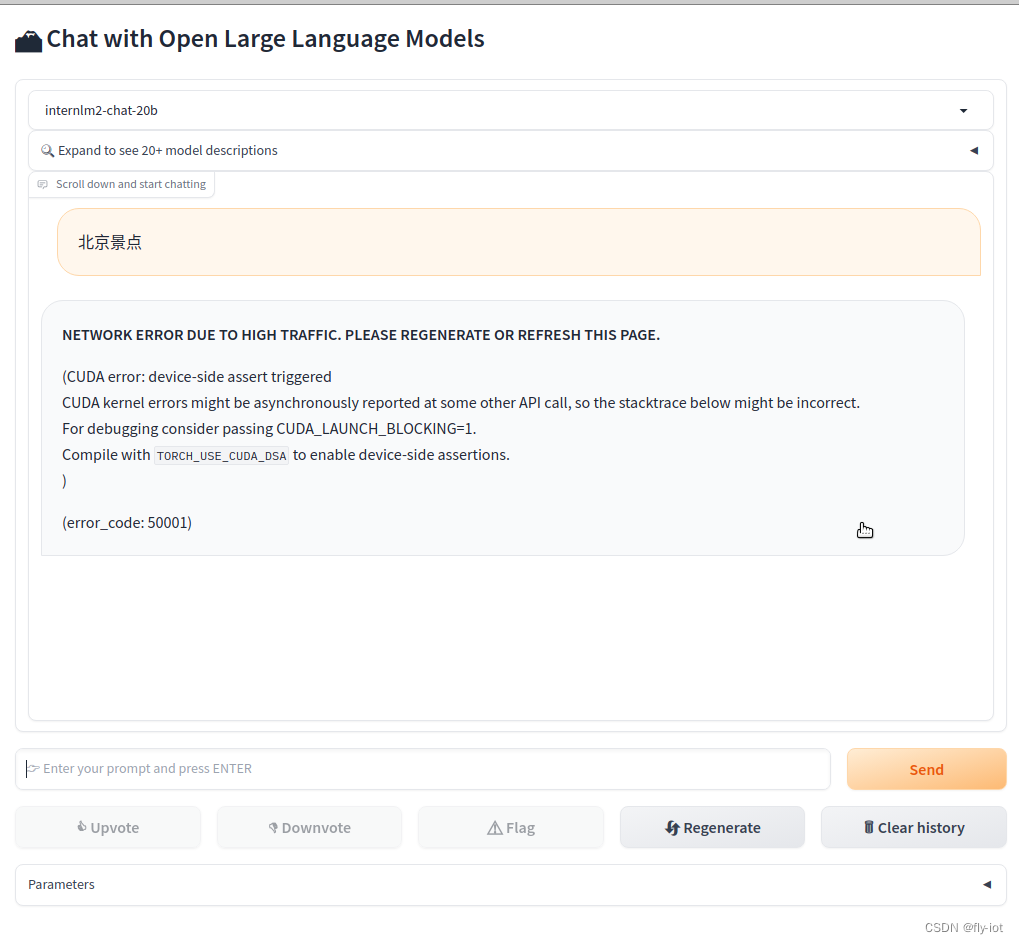
【大模型研究】(1):从零开始部署书生·浦语2-20B大模型,使用fastchat和webui部署测试,autodl申请2张显卡,占用显存40G可以运行
1,演示视频 https://www.bilibili.com/video/BV1pT4y1h7Af/ 【大模型研究】(1):从零开始部署书生·浦语2-20B大模型,使用fastchat和webui部署测试,autodl申请2张显卡,占用显存40G可以运行 2,书生·浦语2-对话-20B https://modelscope.cn/models/Shanghai_AI_La