本文主要是介绍GPT-SoVITs从零开始训练声音克隆教程(以云端AutoDL部署为例)【教程超详细】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
打开网站
https://www.autodl.com/
注册账户和和实名认证、绑定微信才能使用。操作完成后选择镜像购买。
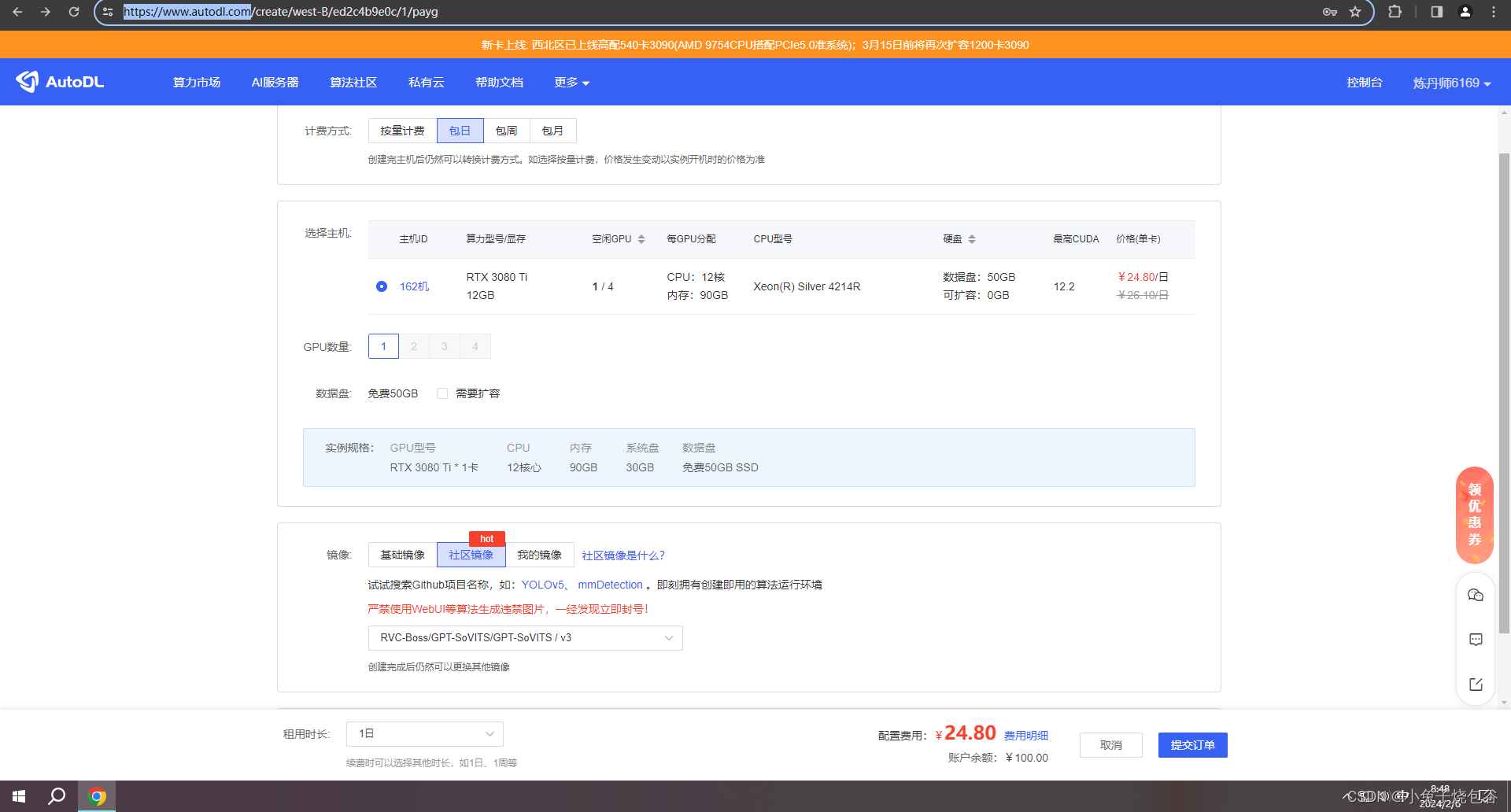
等待创建完成
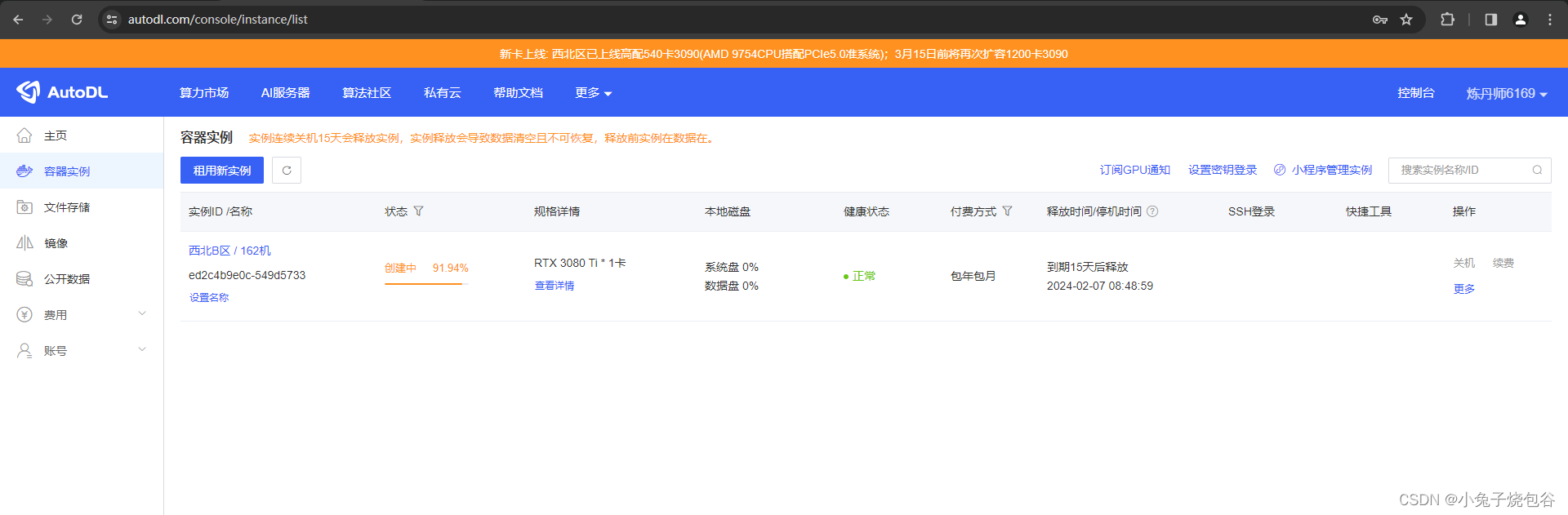
创建完成单击JupyterLab
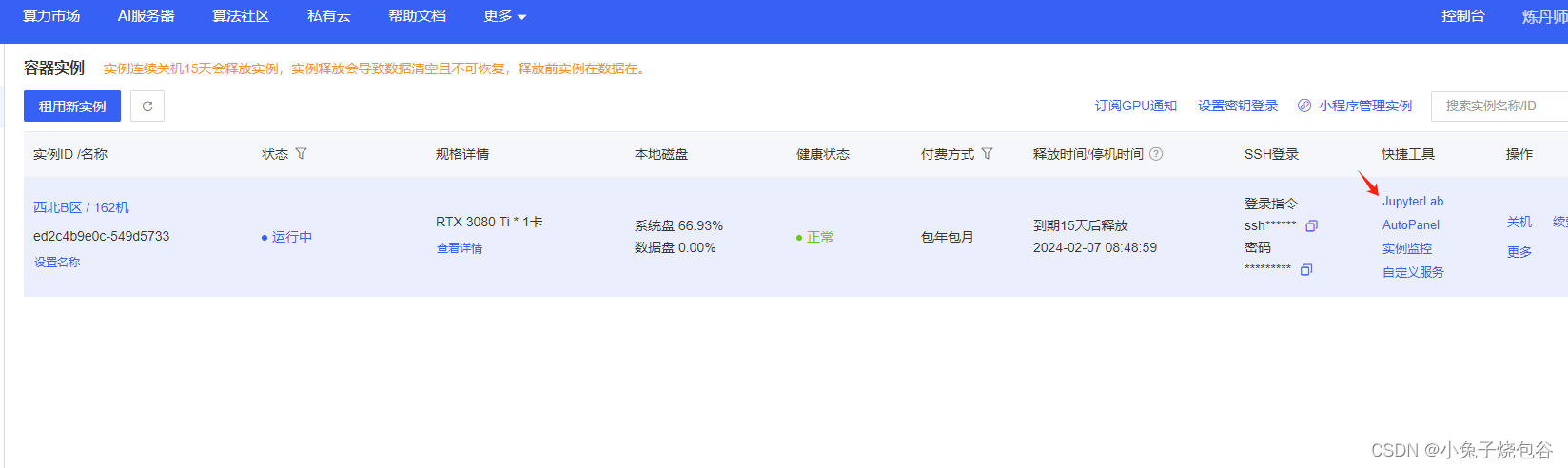
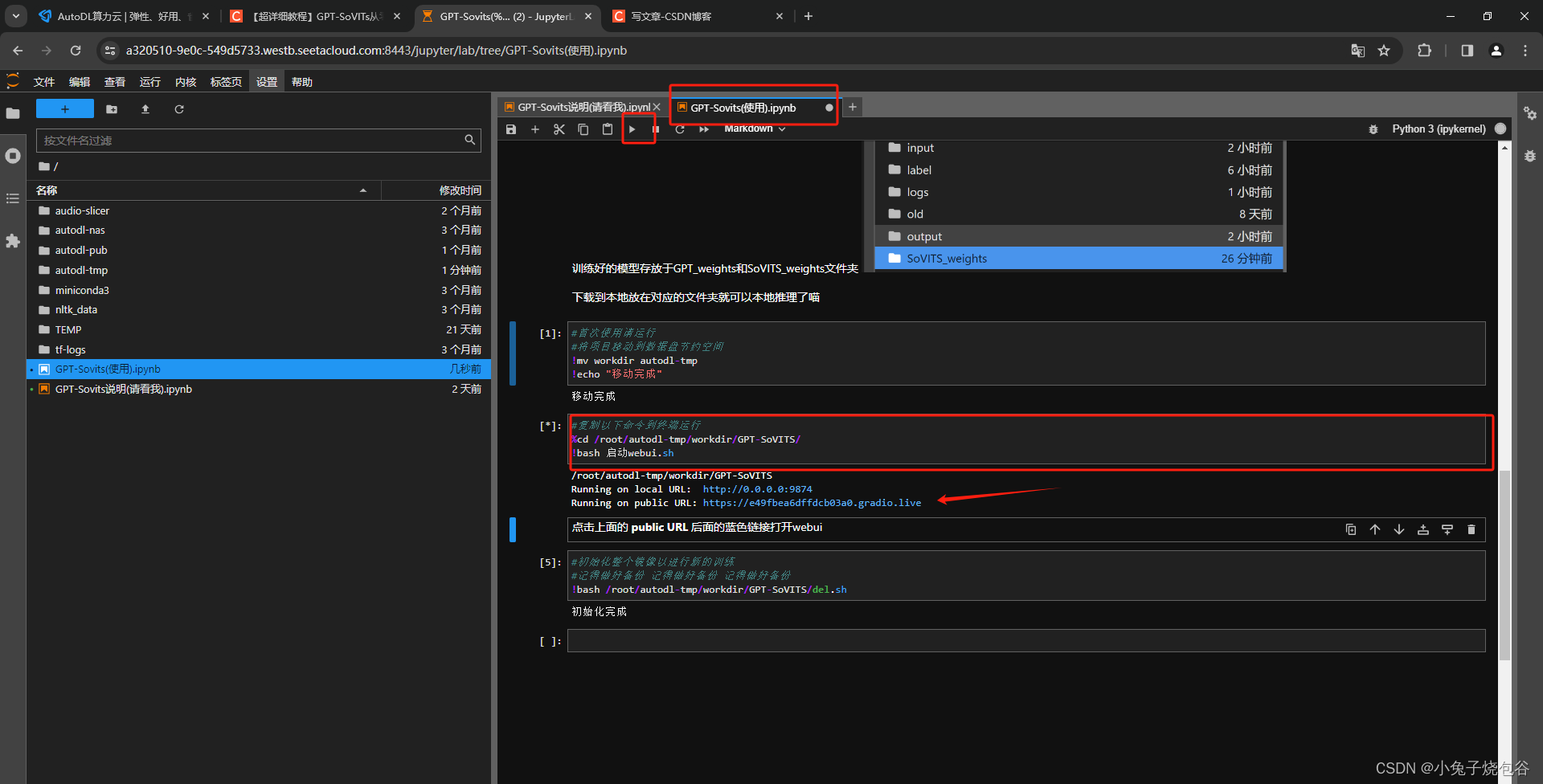
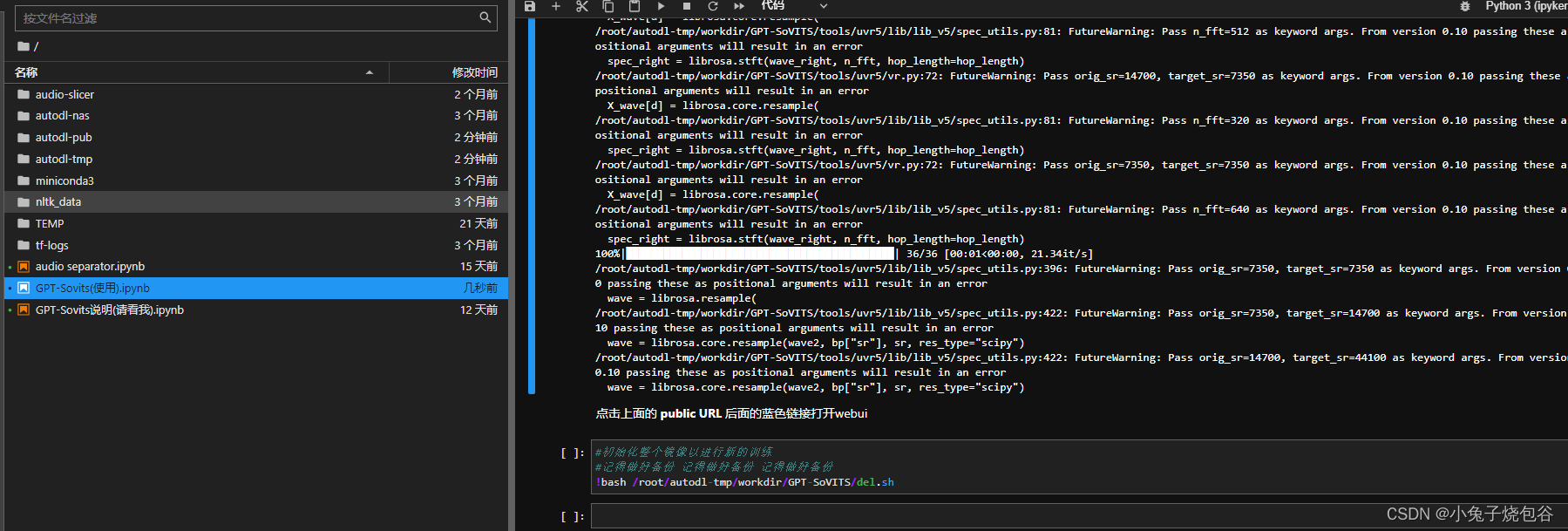
在文件GPT-Sovits(使用).ipynb拉到最下面
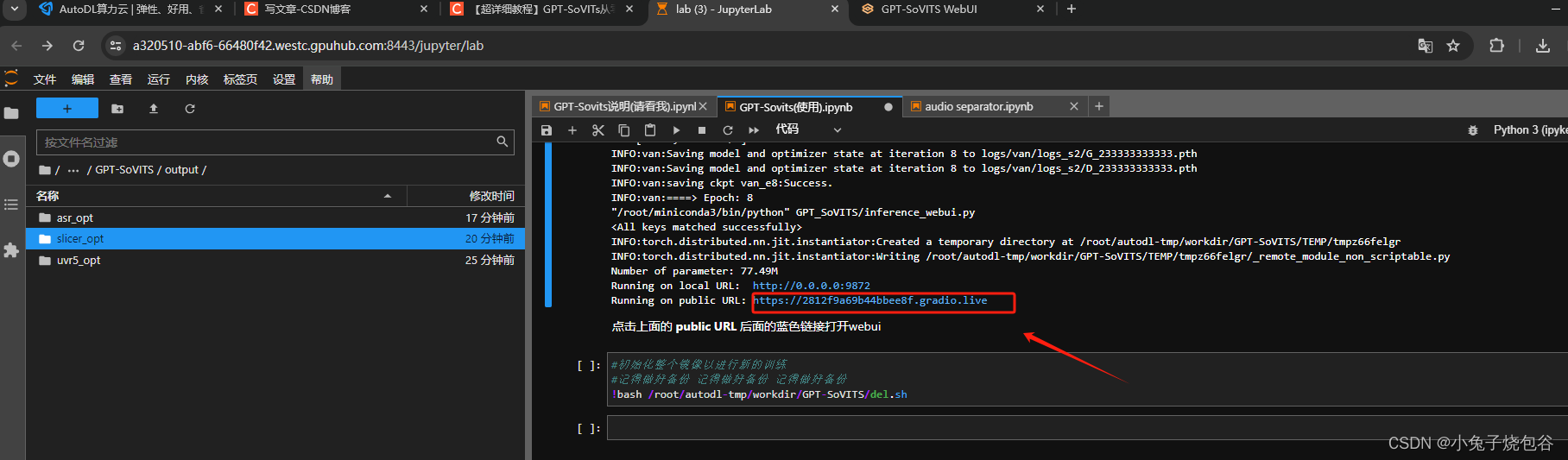
先运行下图框中命令
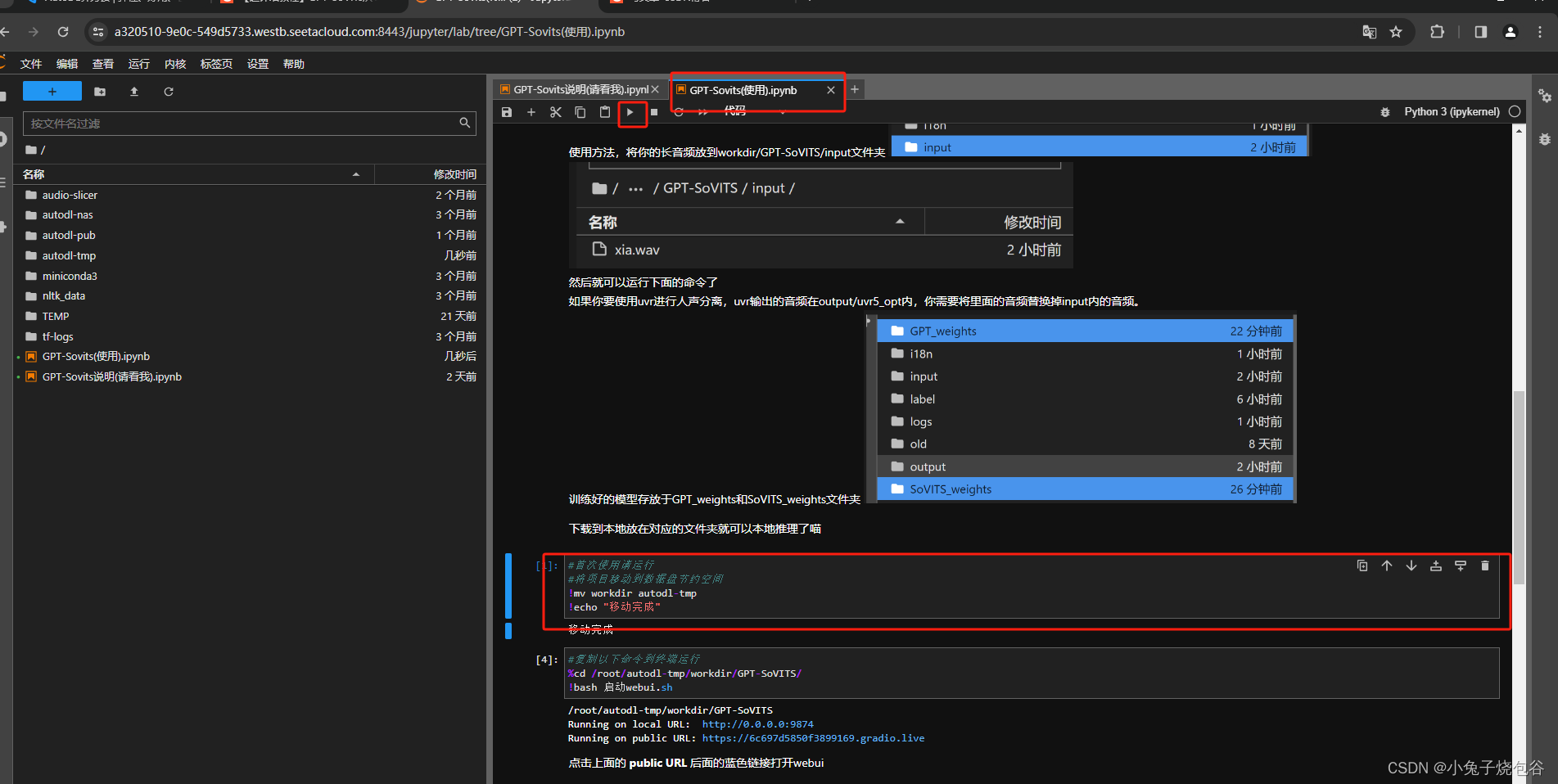
再运行下图框中命令,然后单击蓝色链接
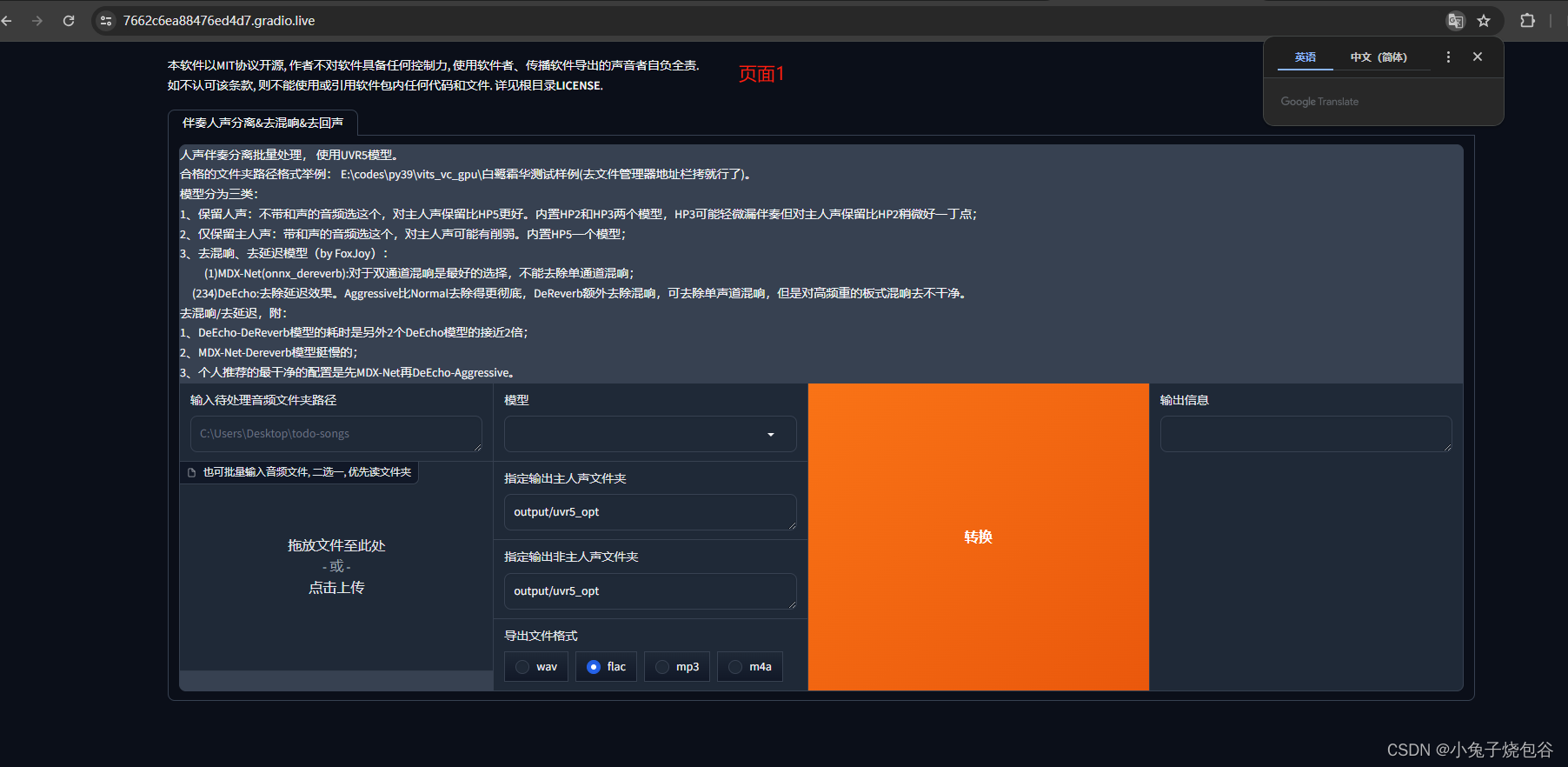
打开页面如下所示
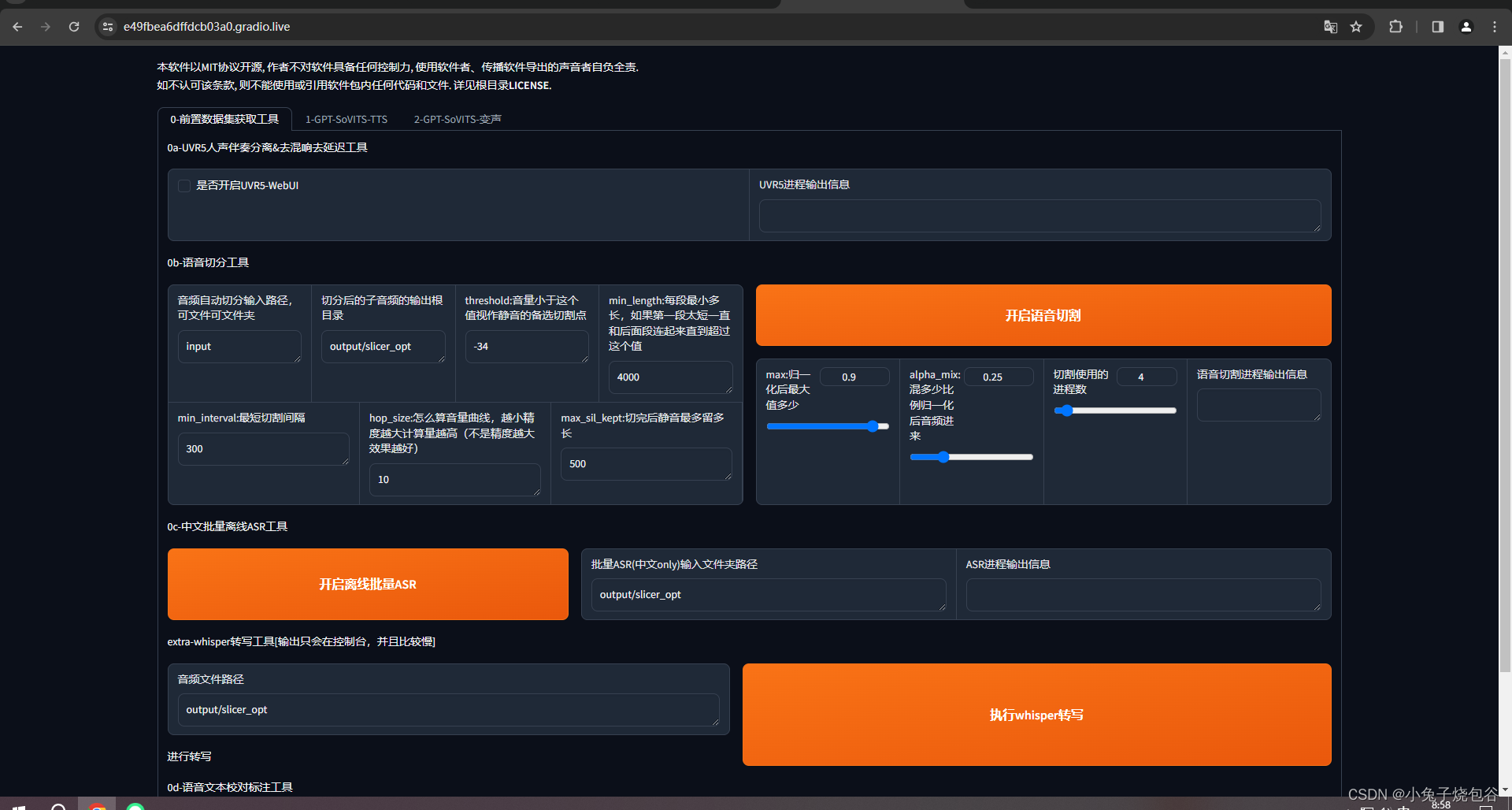
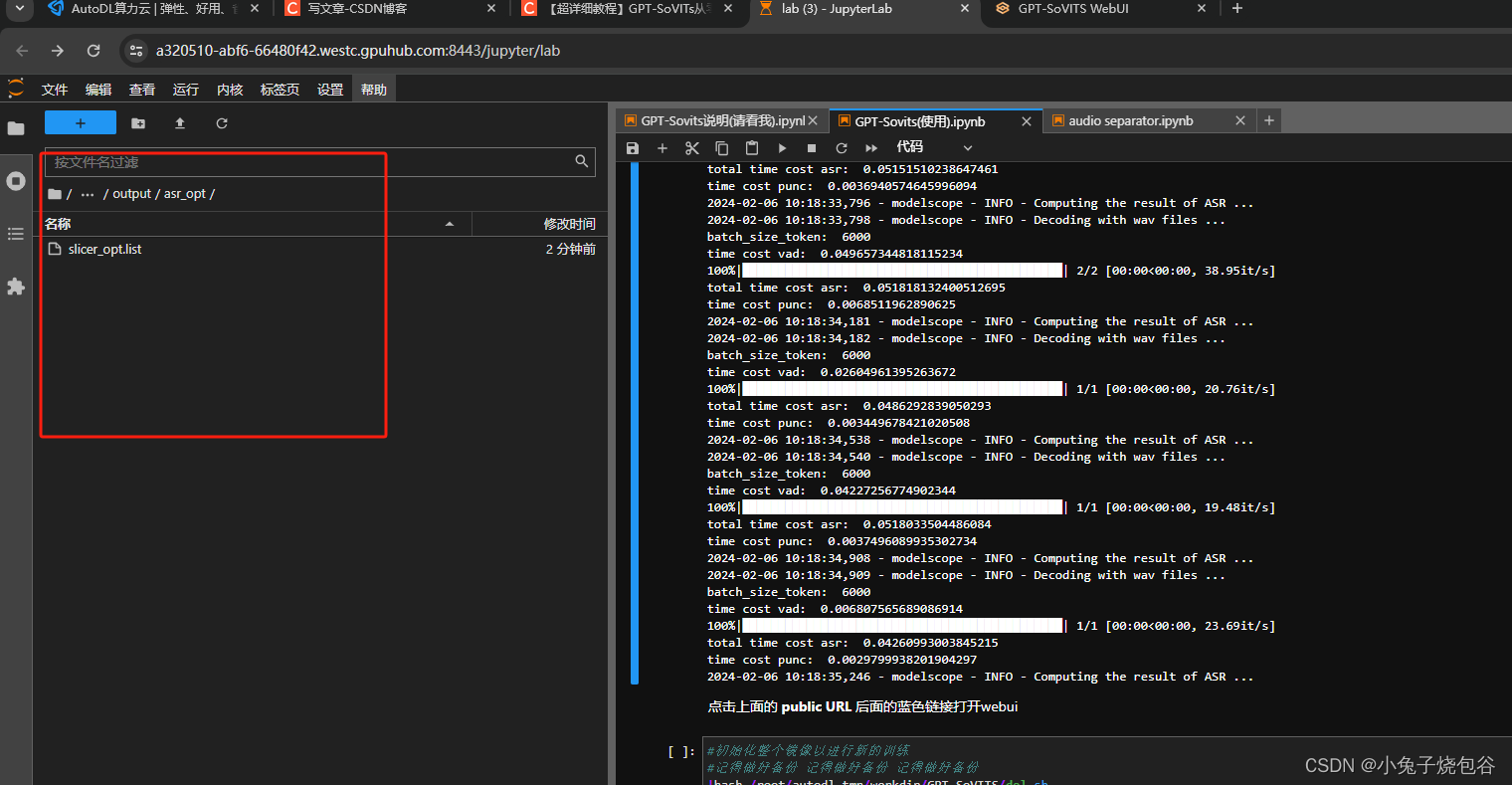
单击是否开启UVR5-WebUl
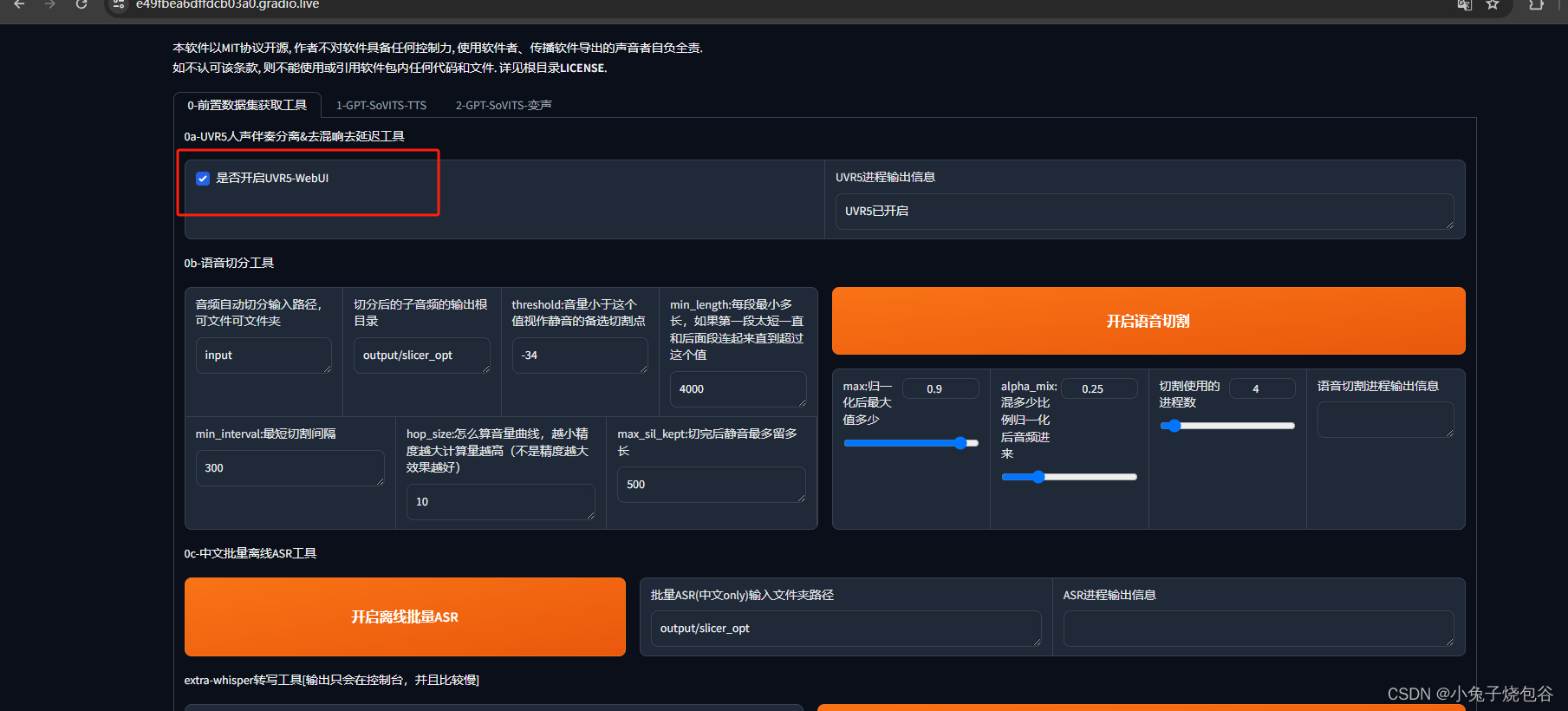
打开UVR5-WebUl页面
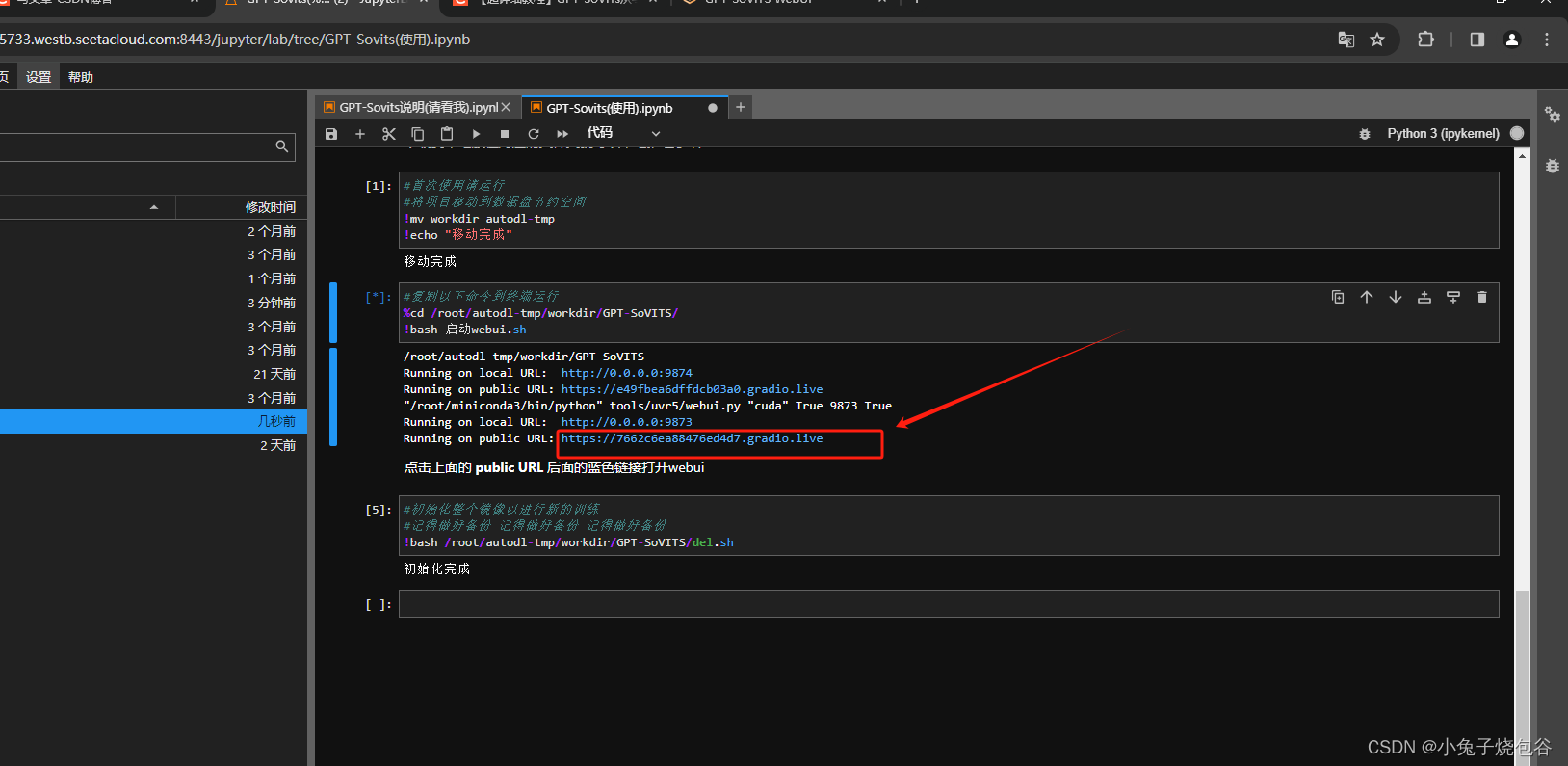
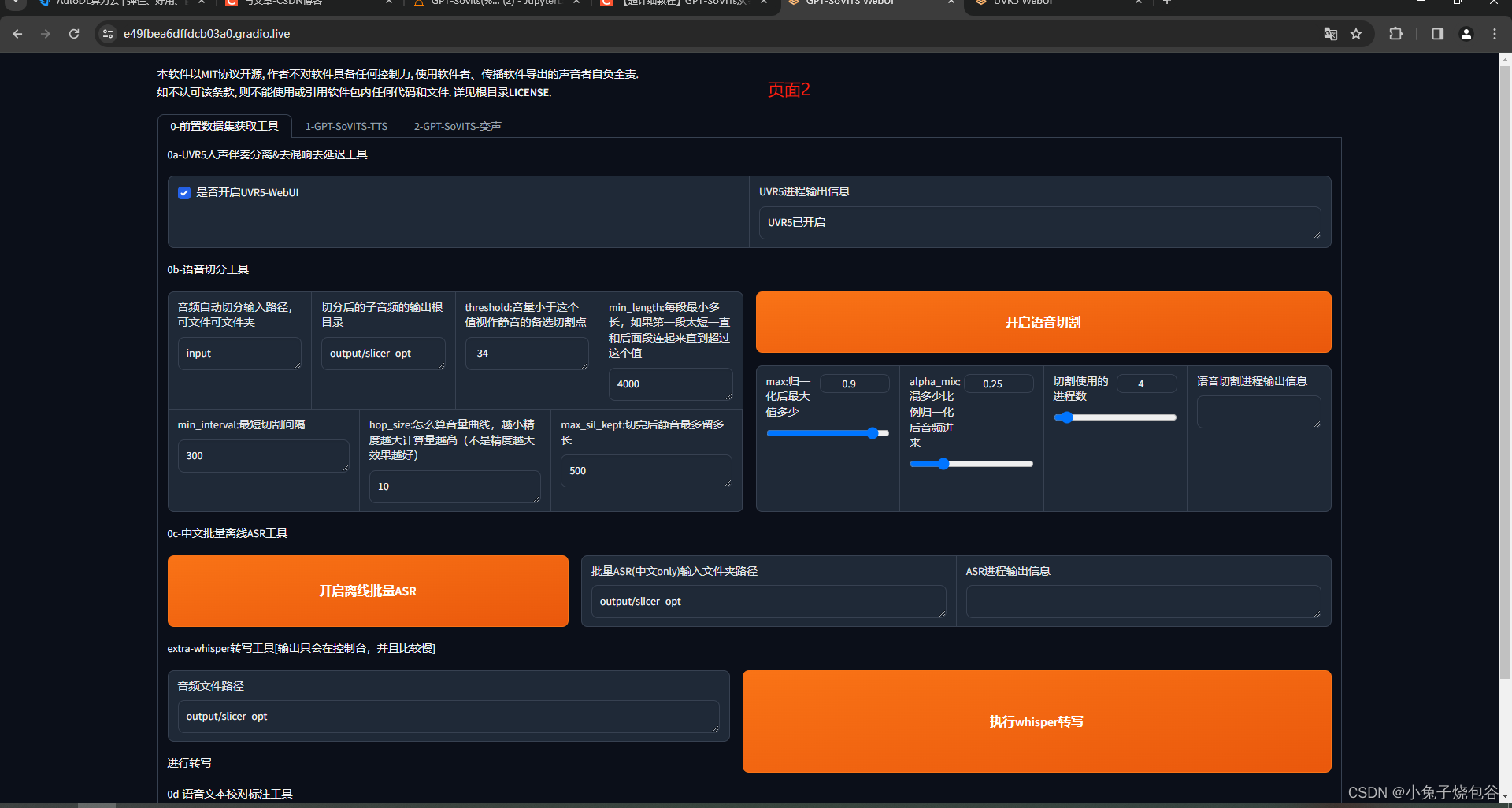
打开页面如下所示
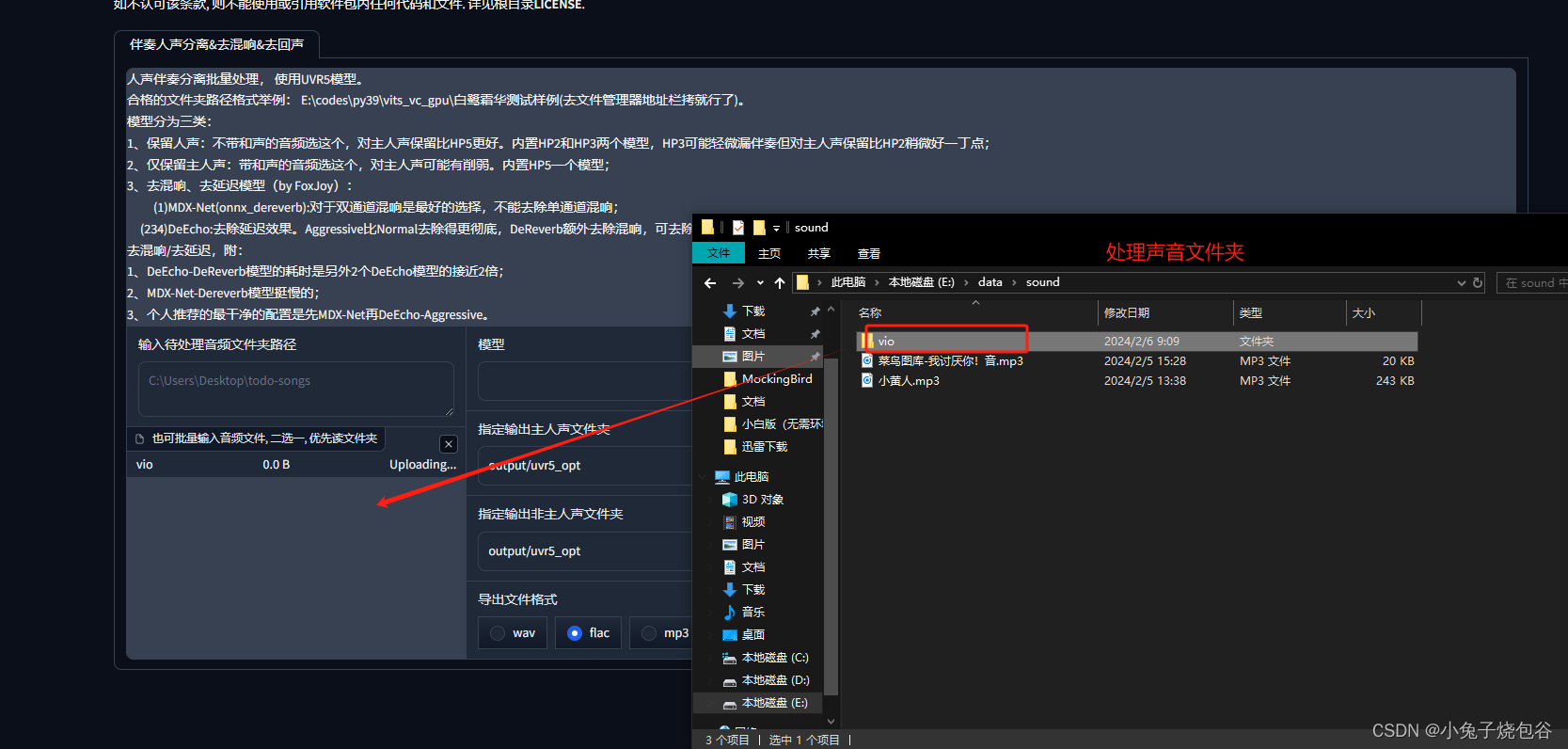
UVR5-WebUl页面上传处理的声音文件
上传完声音点击转换
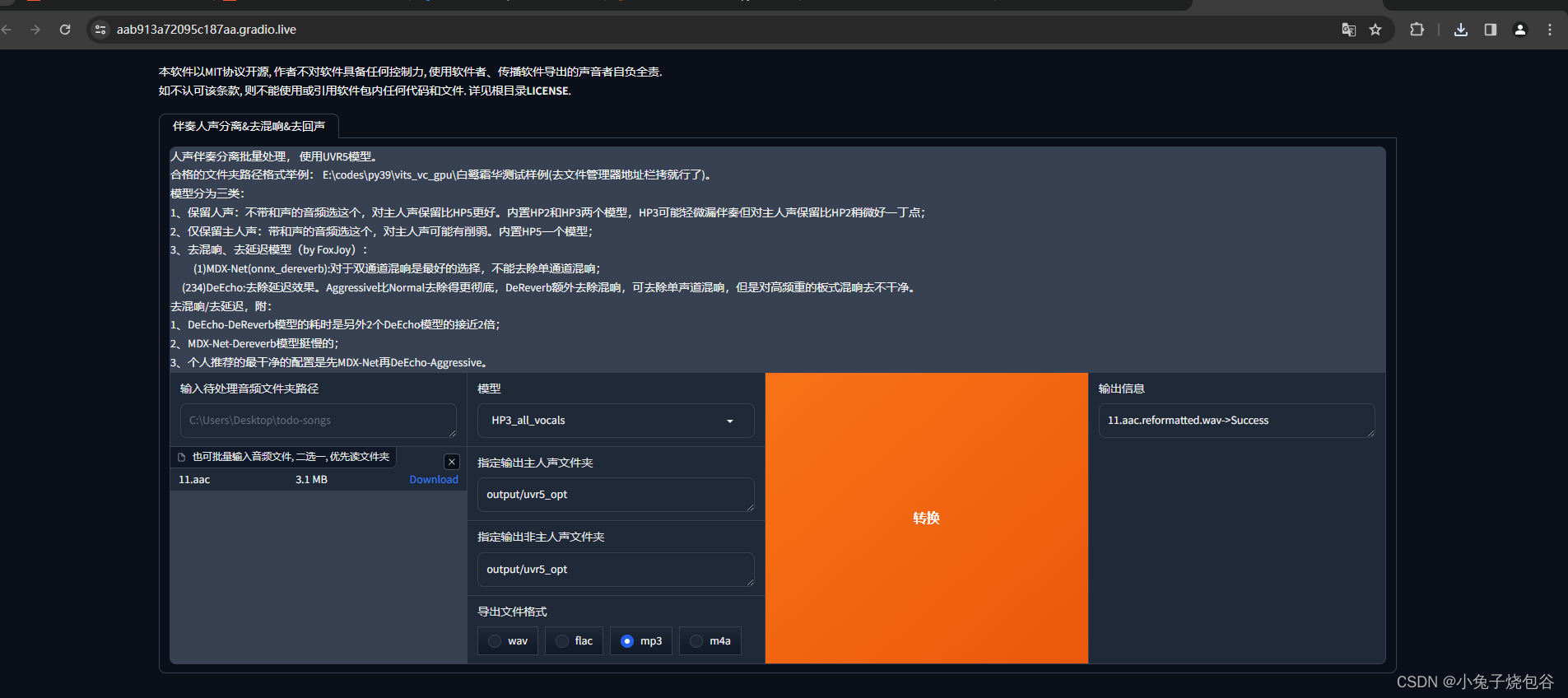
转换日志
转换完成提示
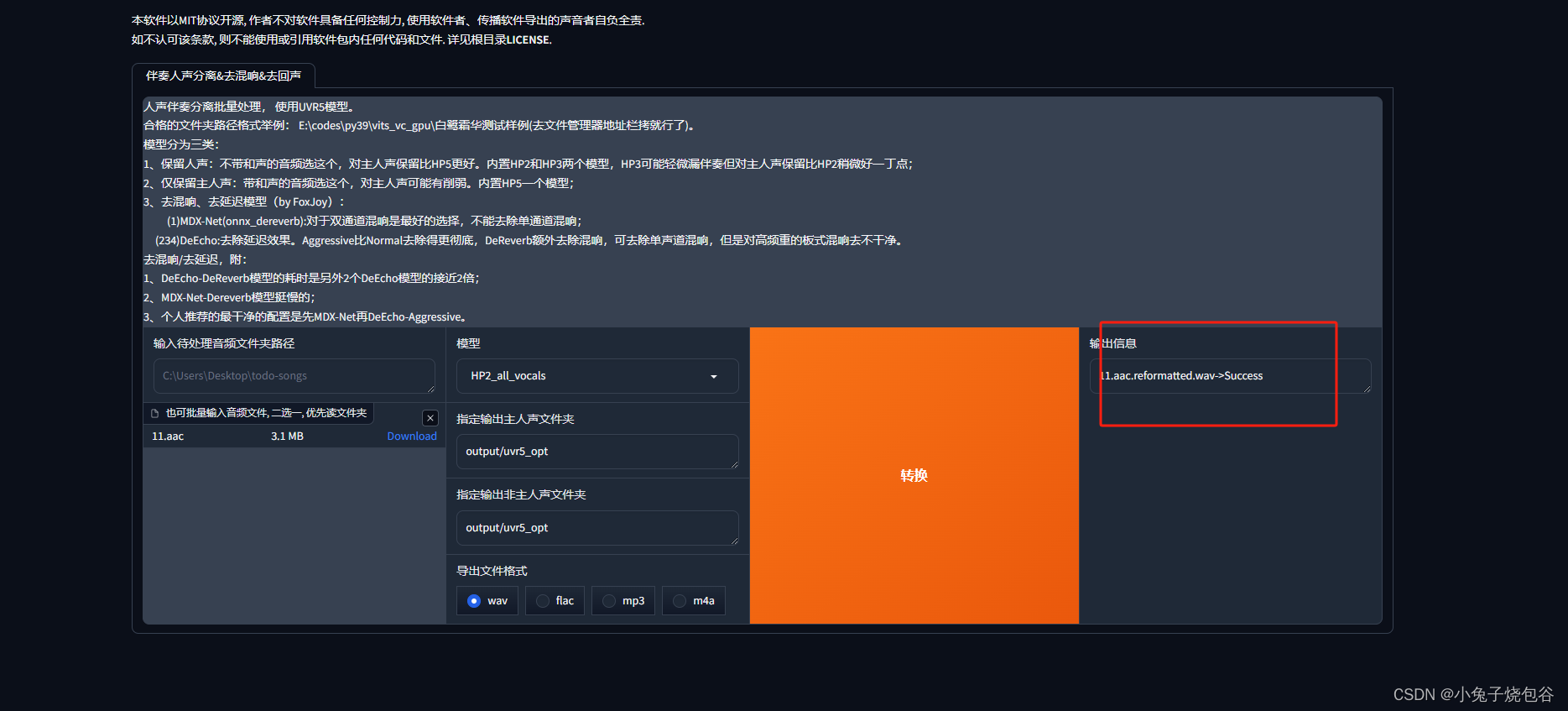
转换完成文件
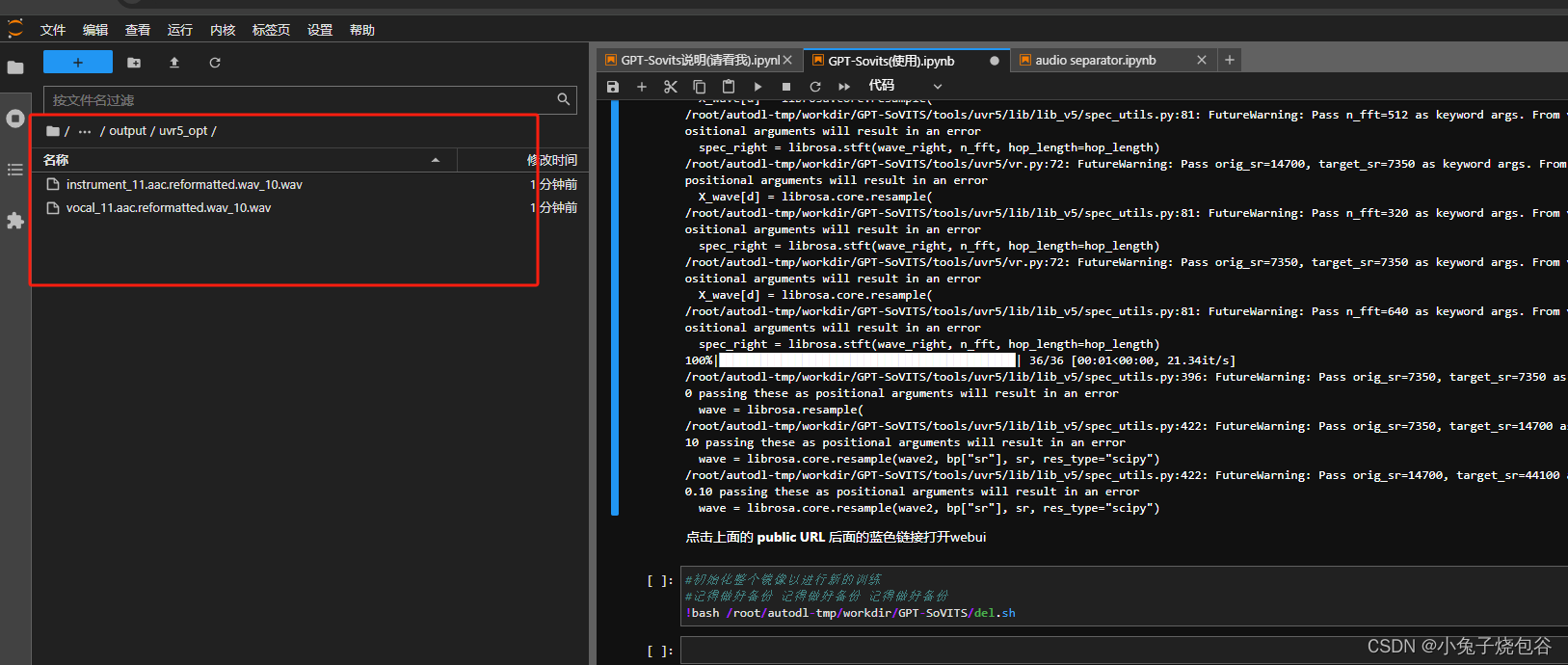
把刚才转换后成功的文件上传到这个文件路径下
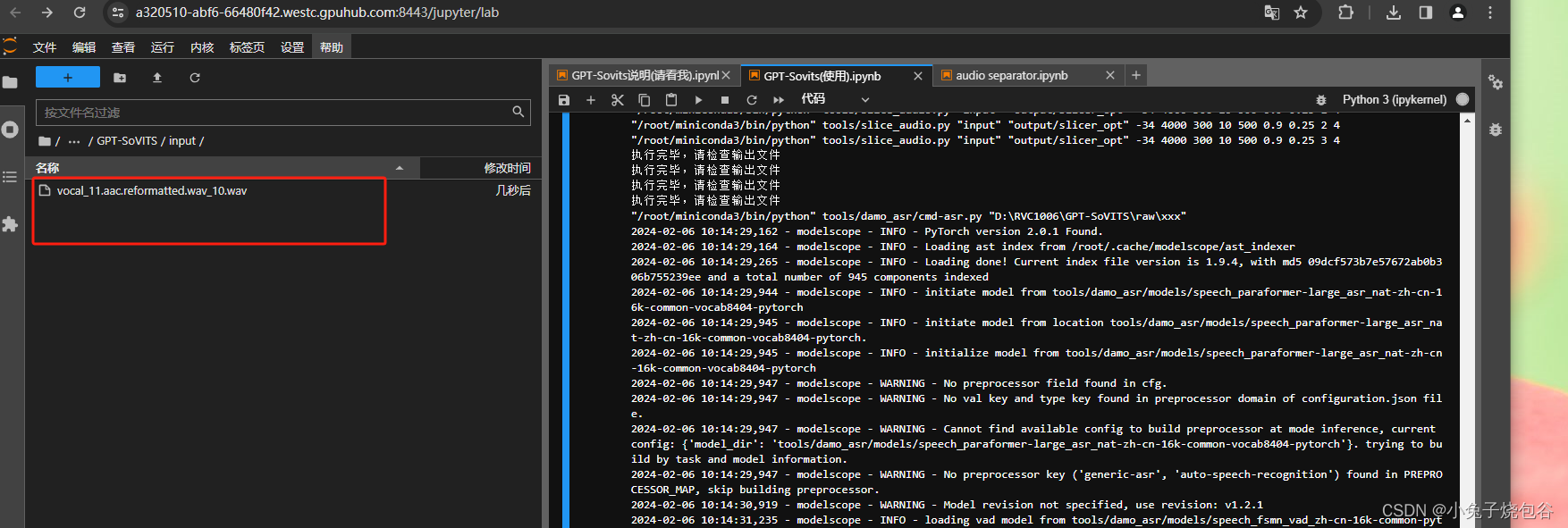
开启语音切割(填写对应的输入地址,输出等信息)
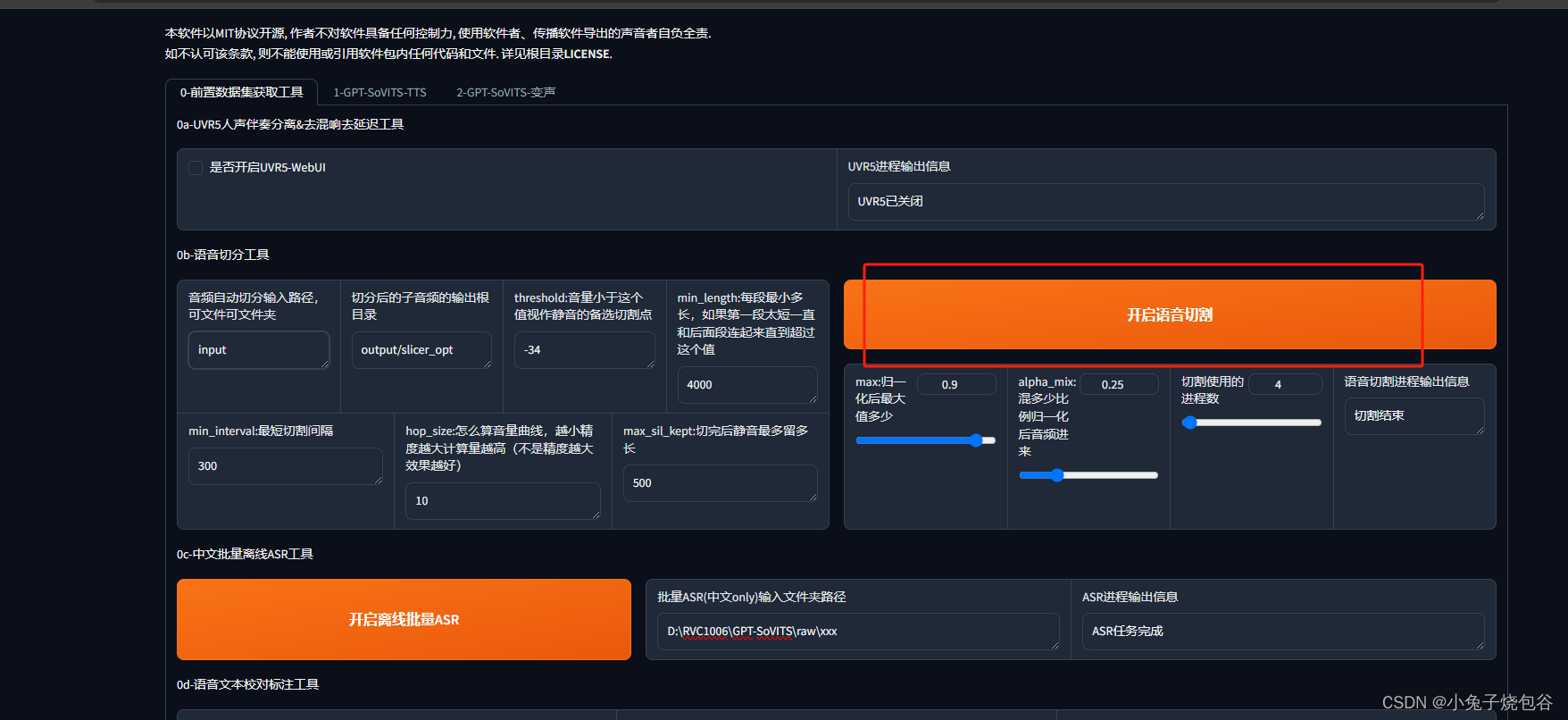
切割完的文件如下所示
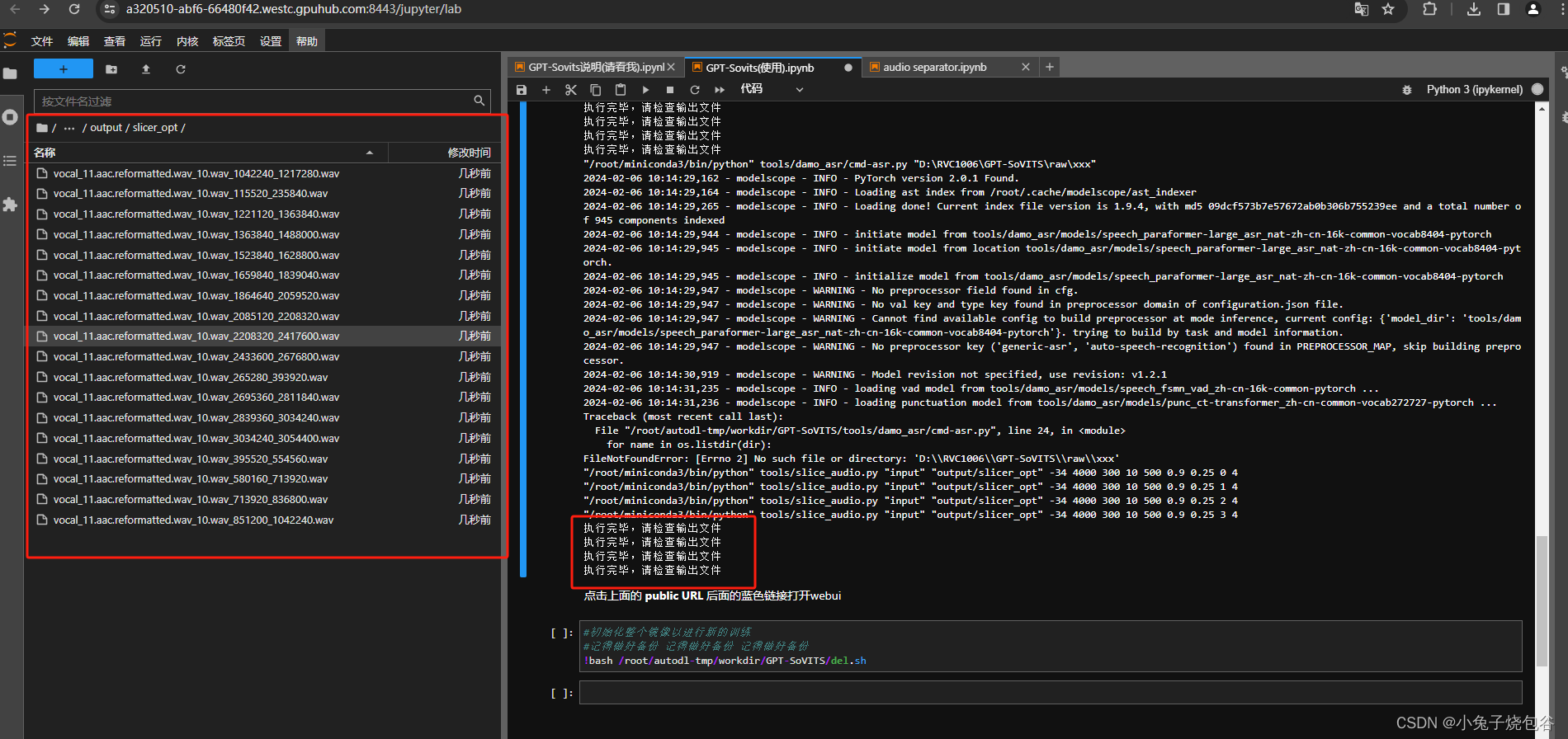
开启离线批量ASR(注意路径)
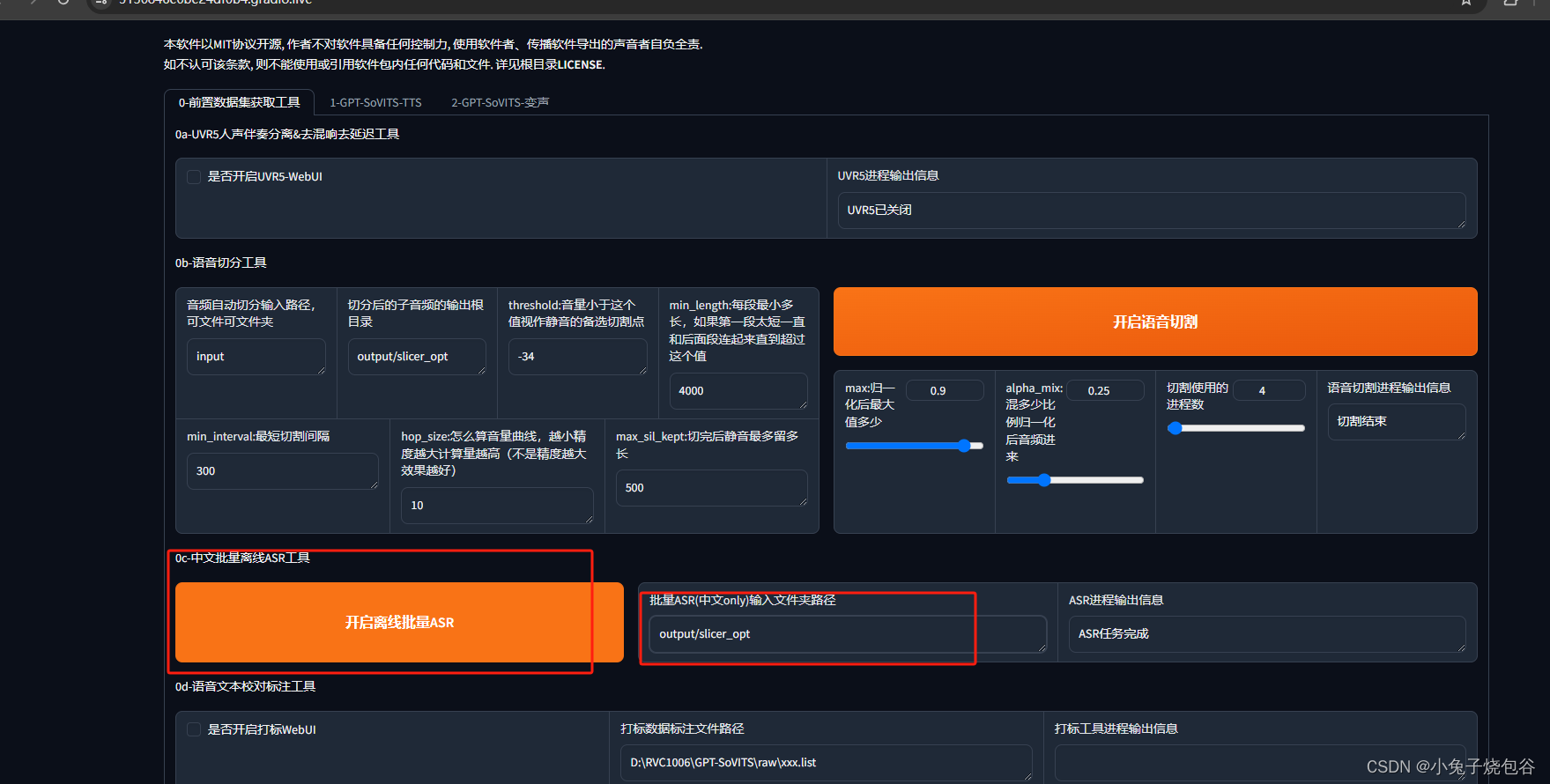
处理日志
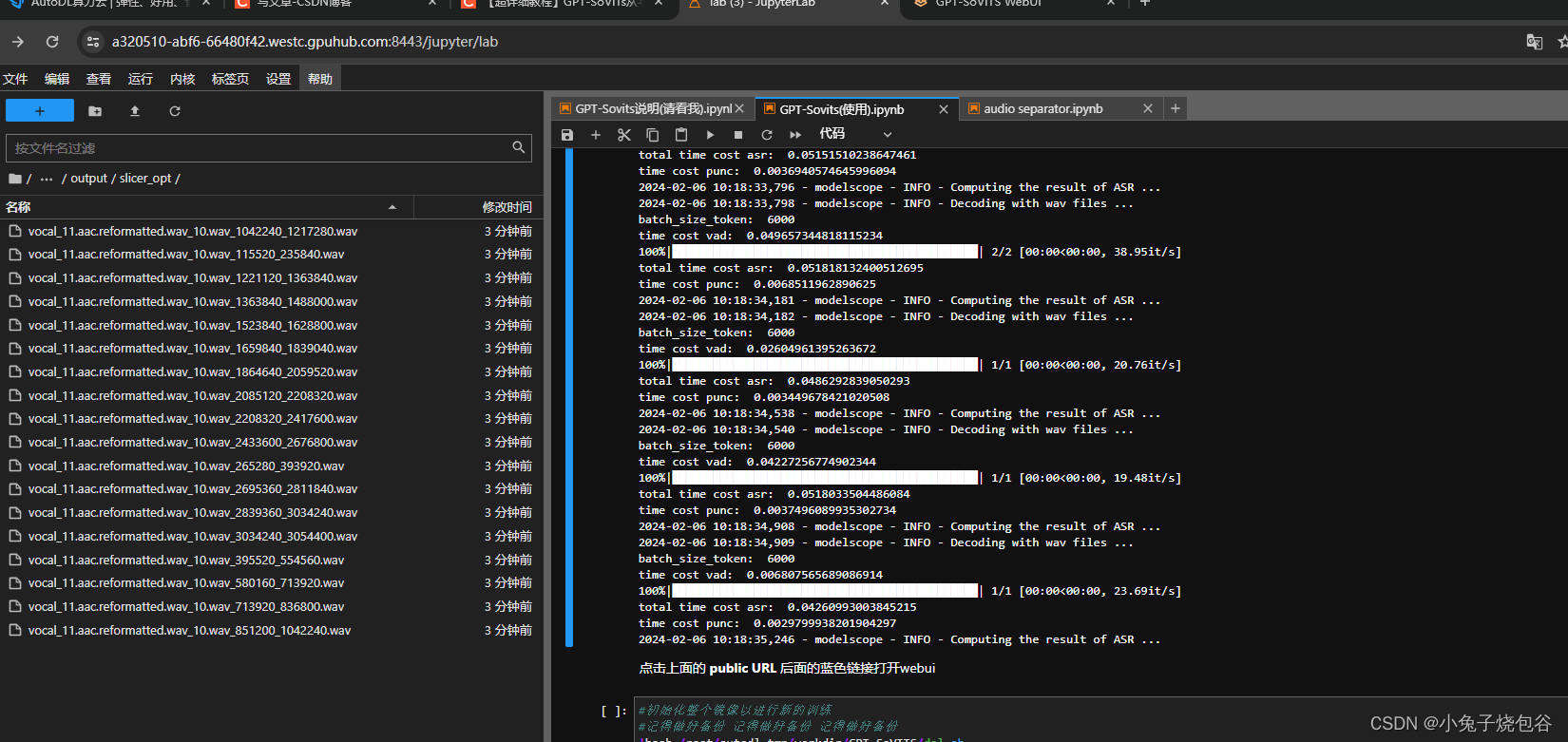
处理完成后的文件
开启打标WebUI
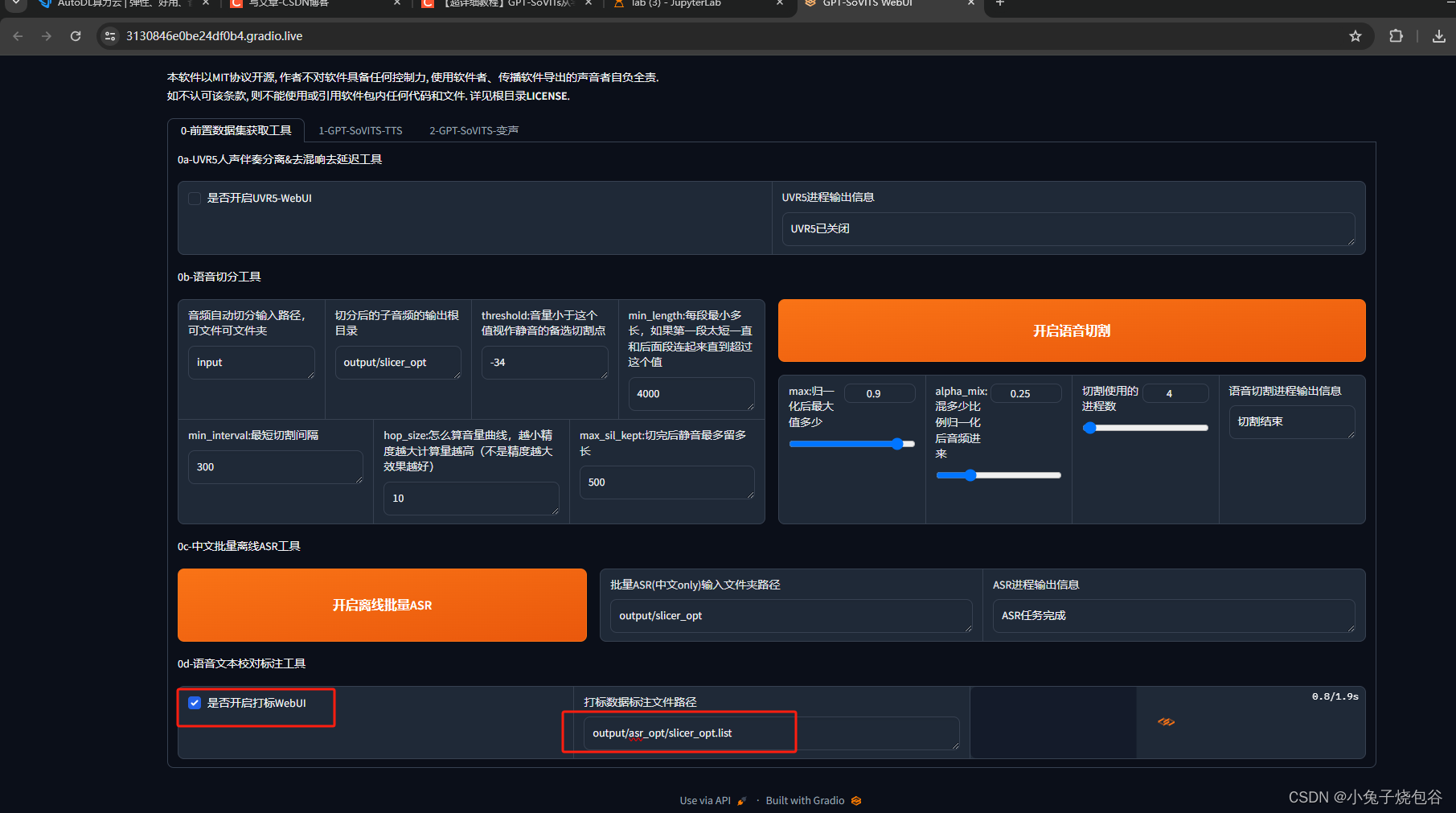
点击日志地址
核对每个声音都正确后保存,下一页核对再保存,处理完后就可以关闭了。
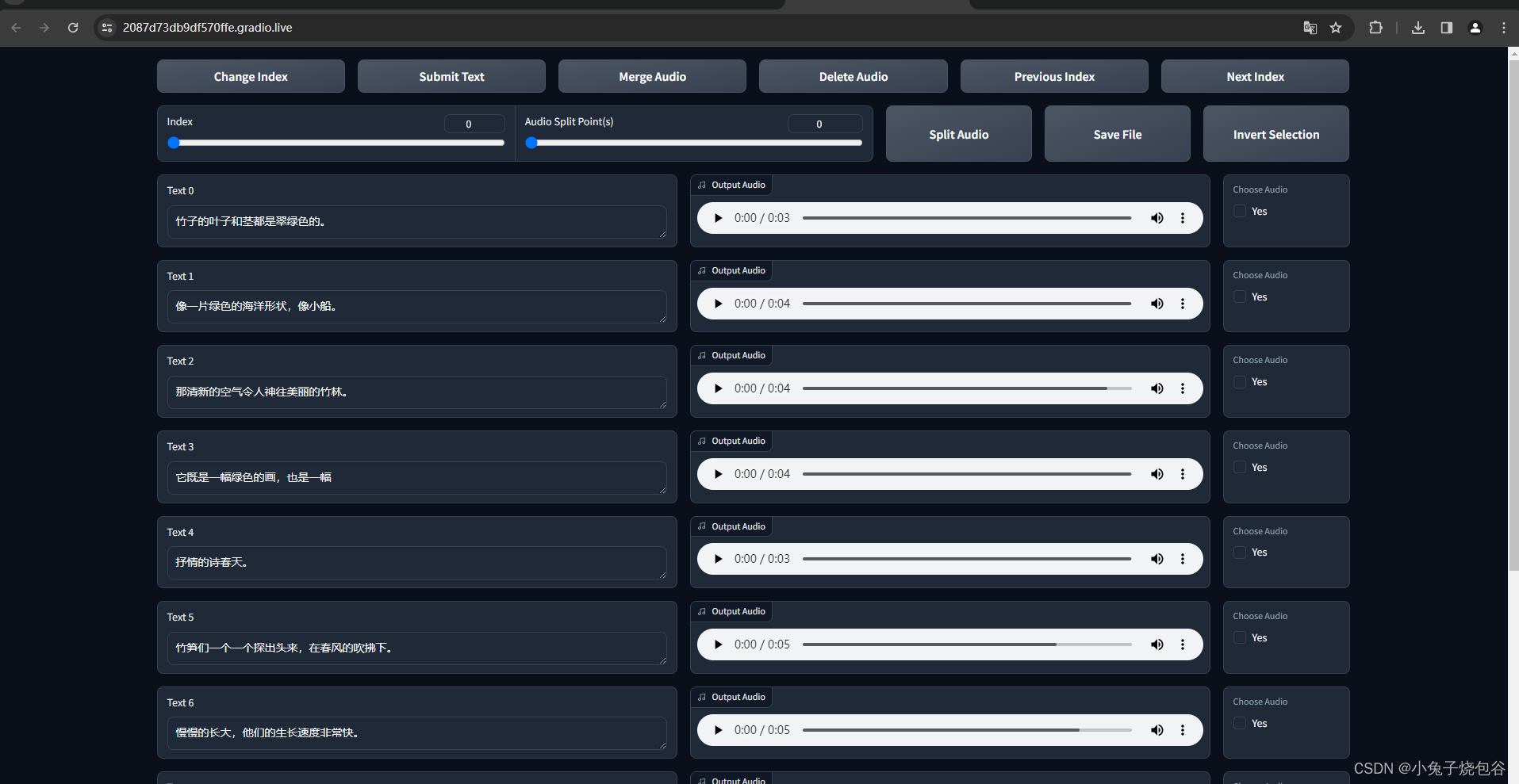
打开TTS页面
设置模型名称,选择刚才生产的list文件夹,及其音频
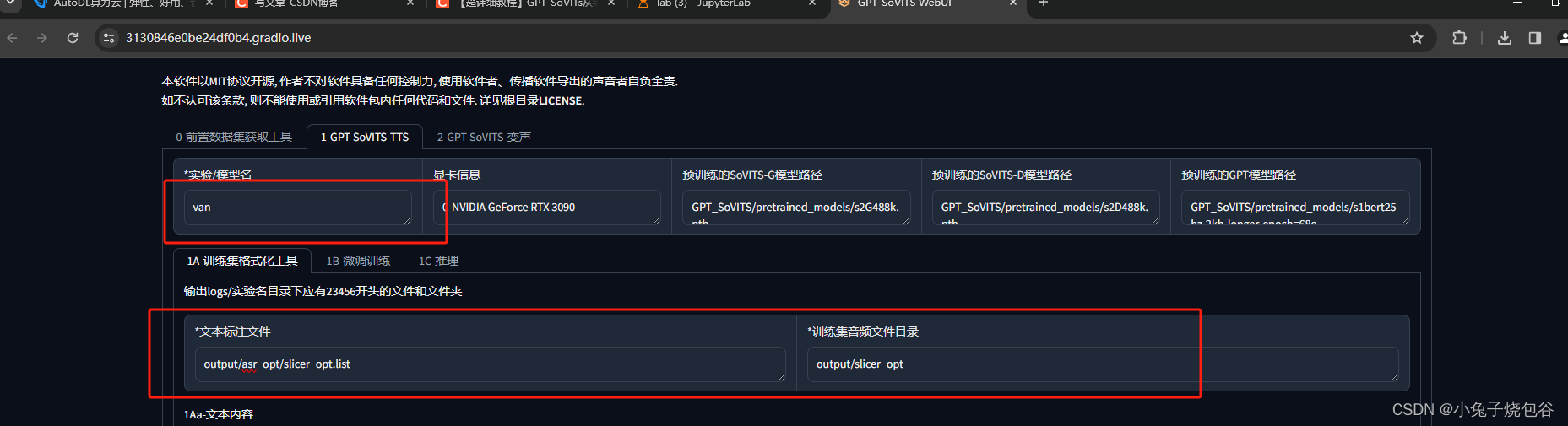
开启文本获取,等待完成
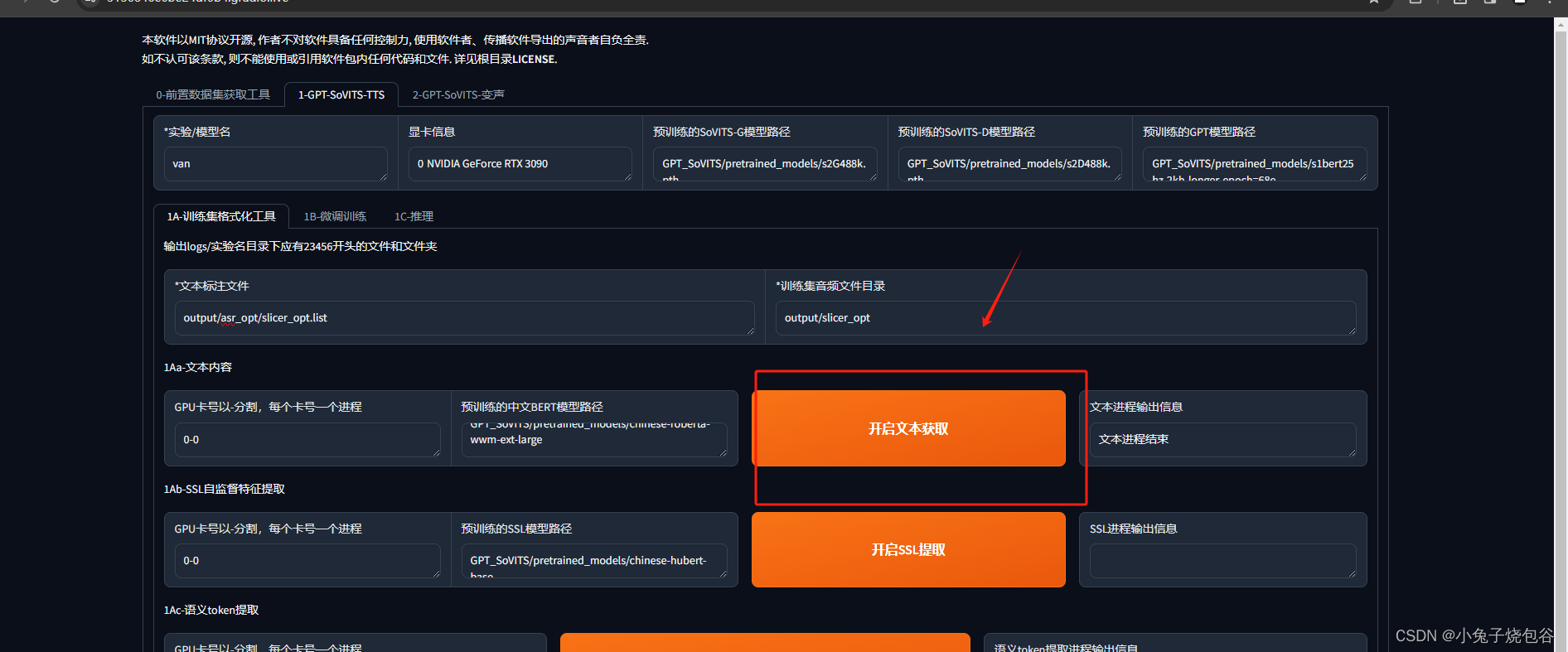
开启SSL提取,等待完成
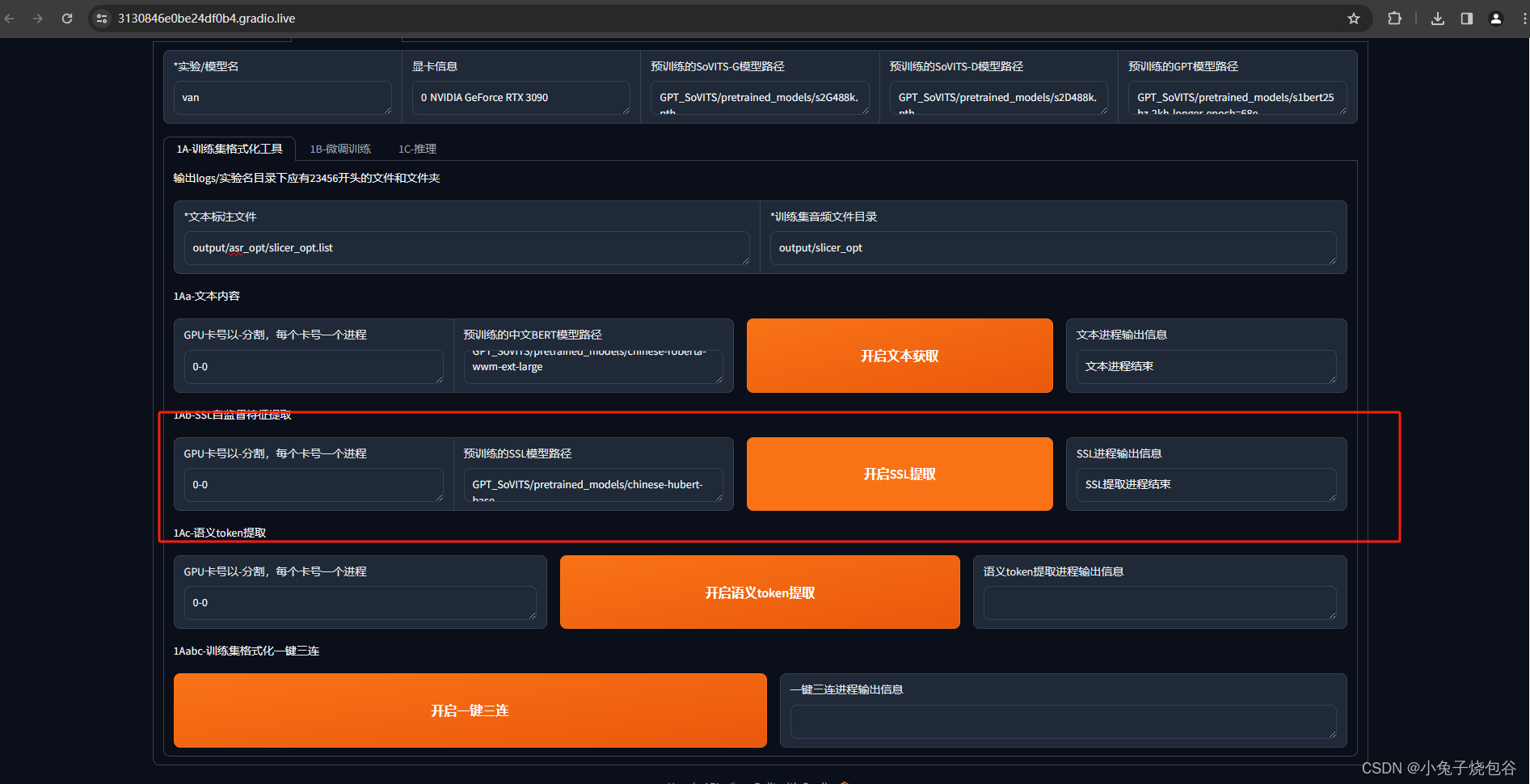
开启Token提取,等待完成
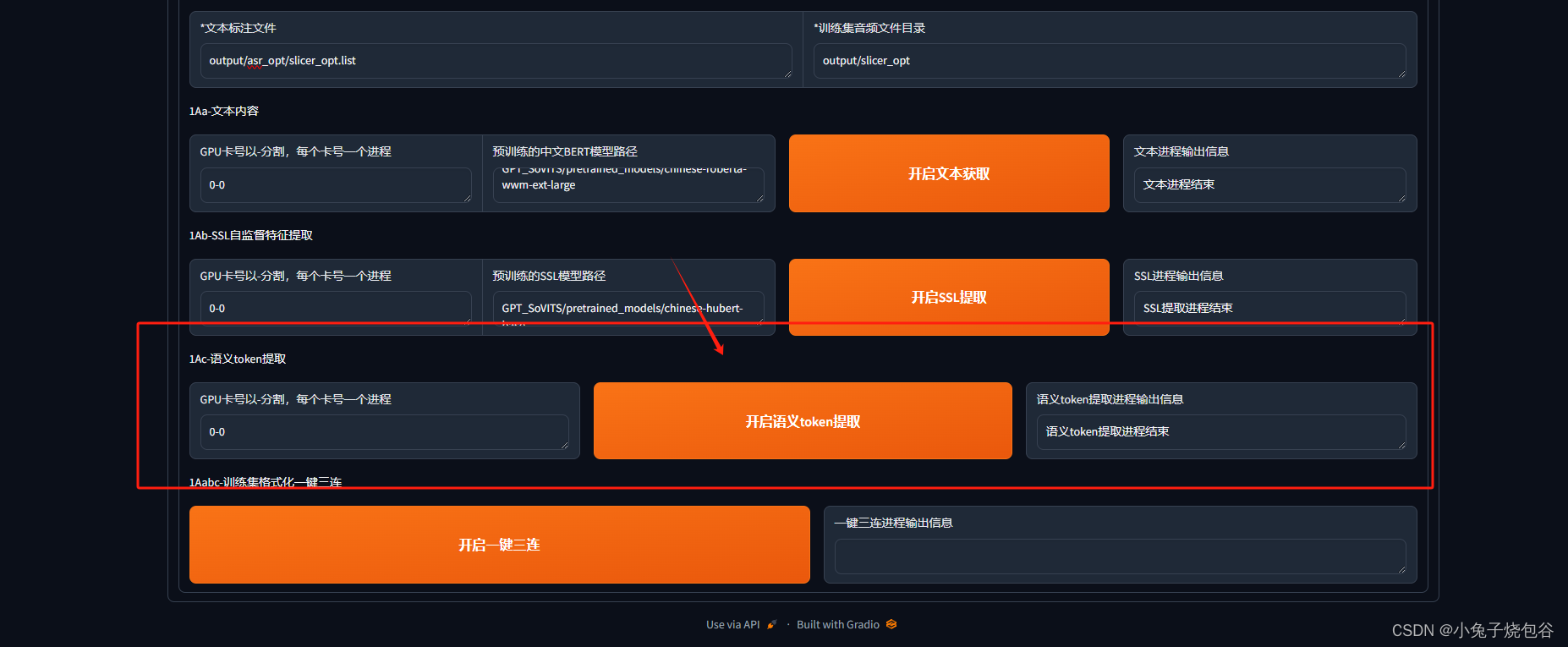
一键三连,等待完成
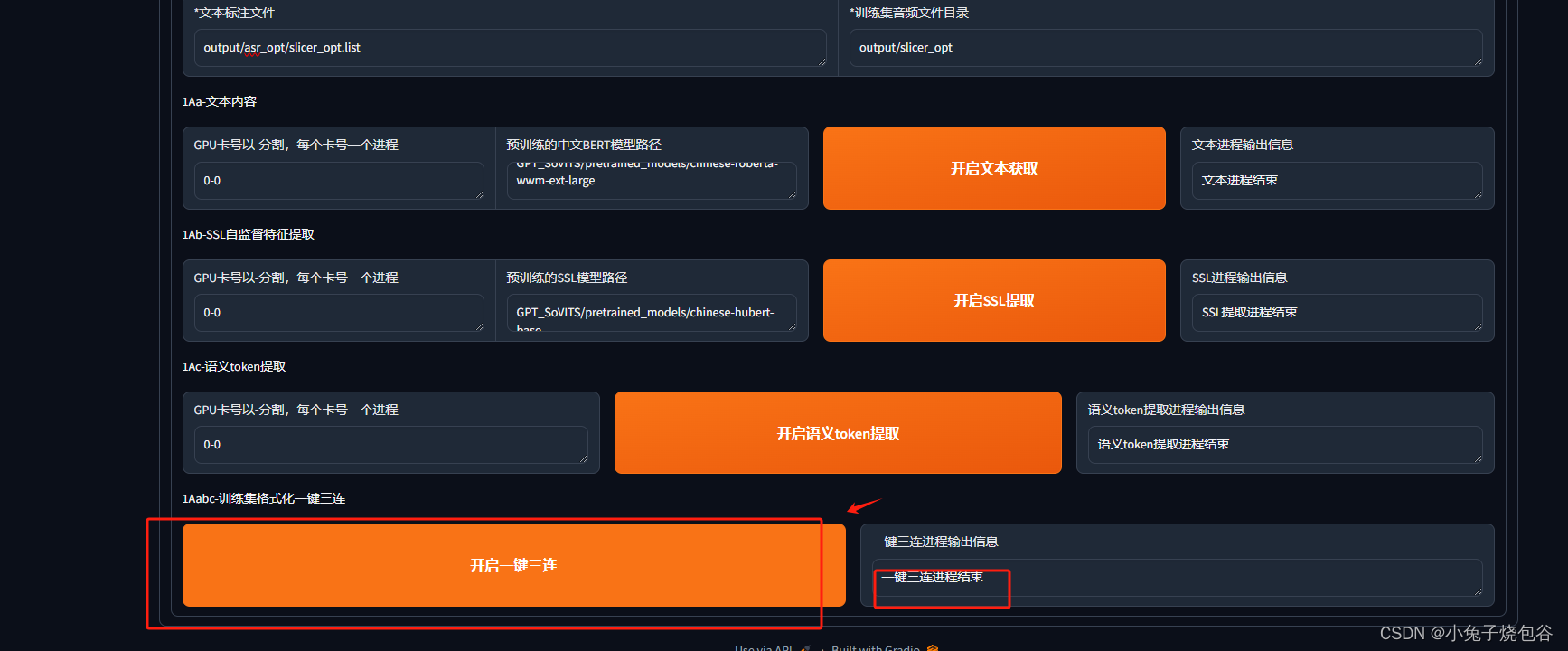
开始训练
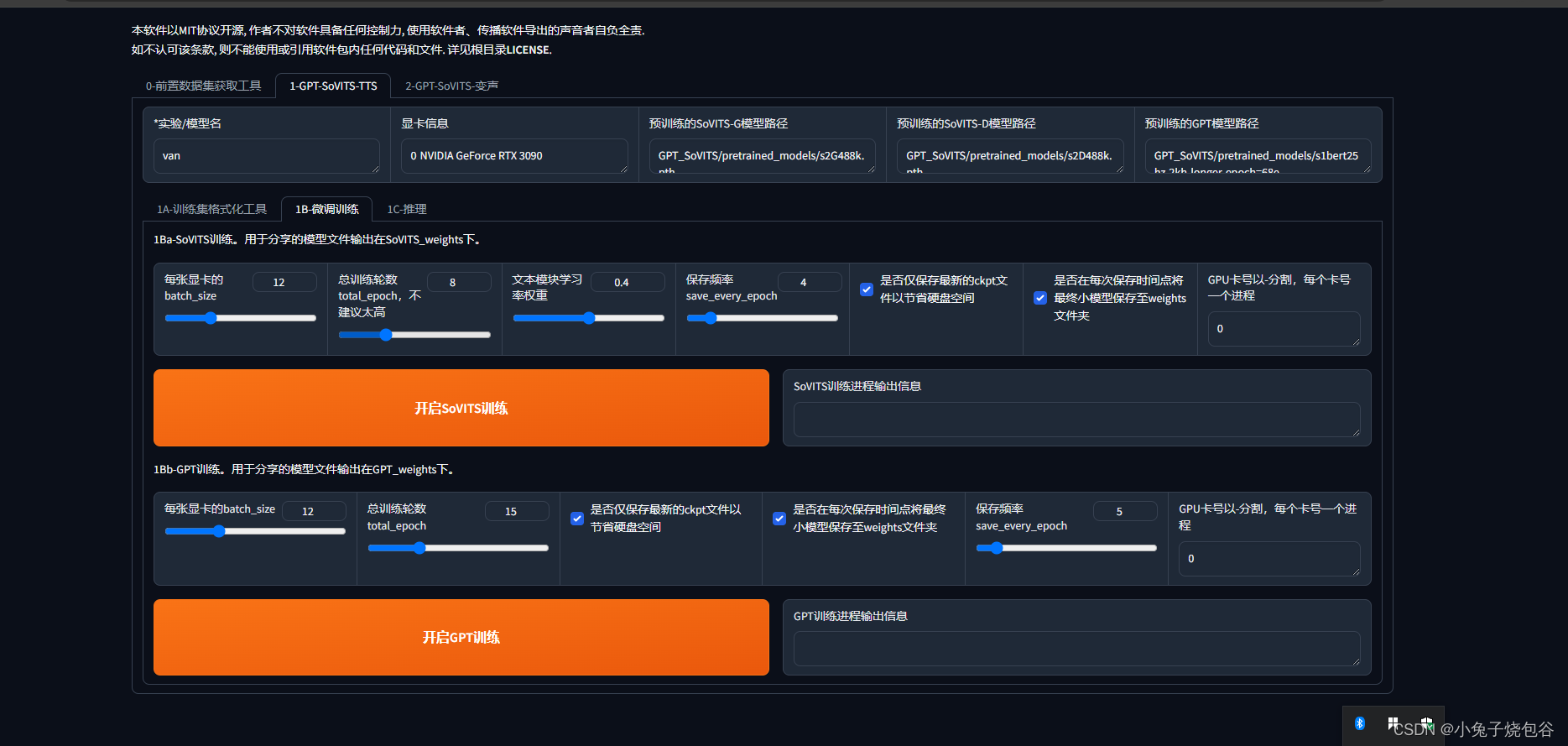
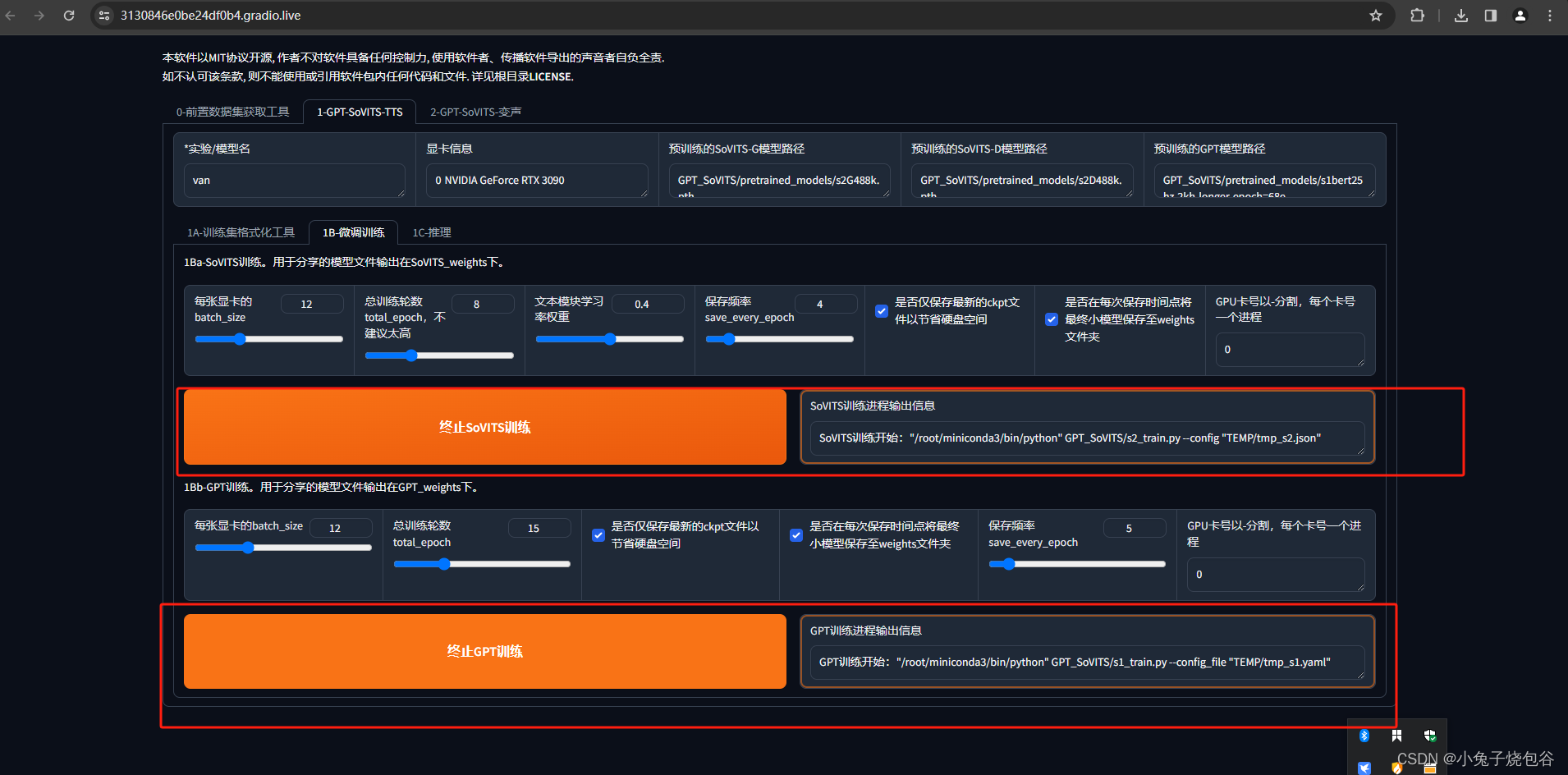
训练完成
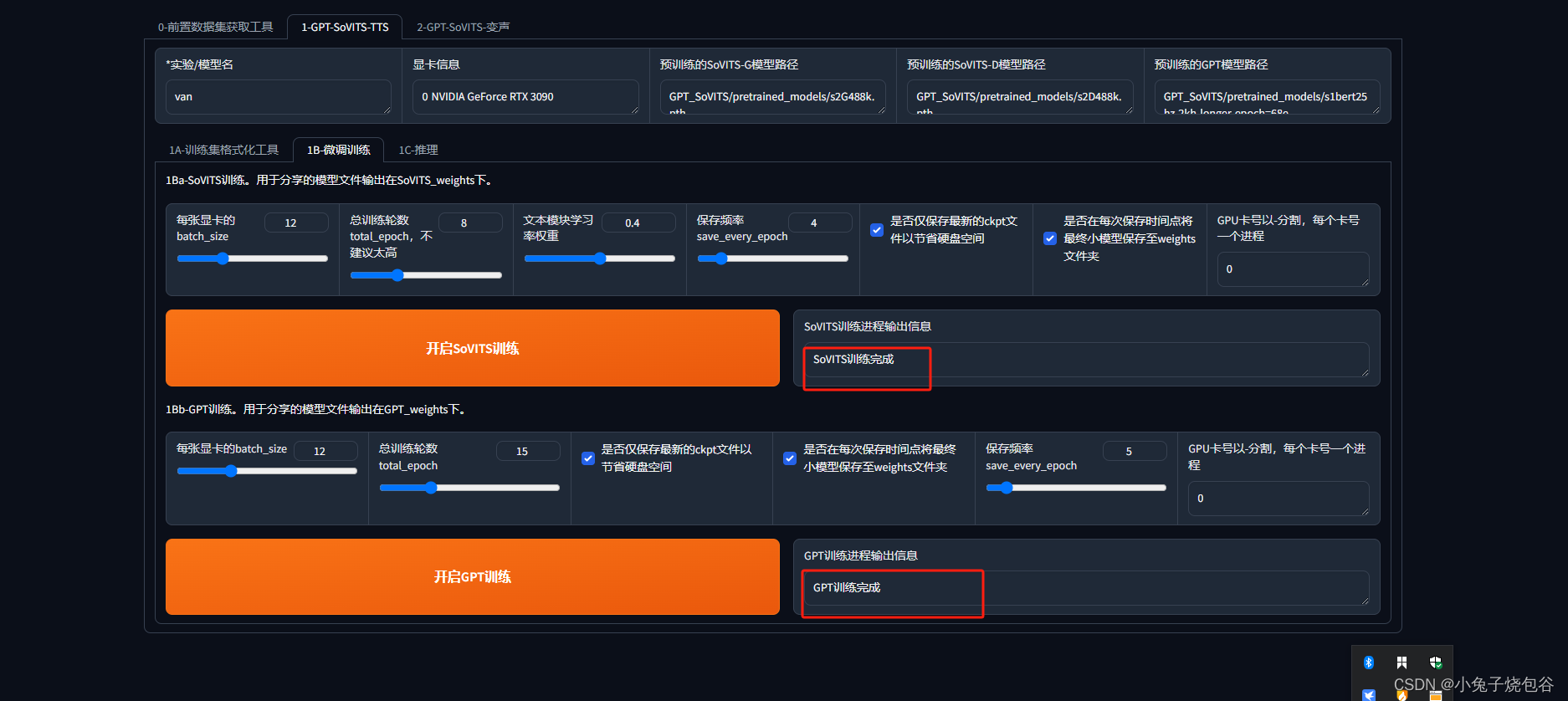
刷新训练结果
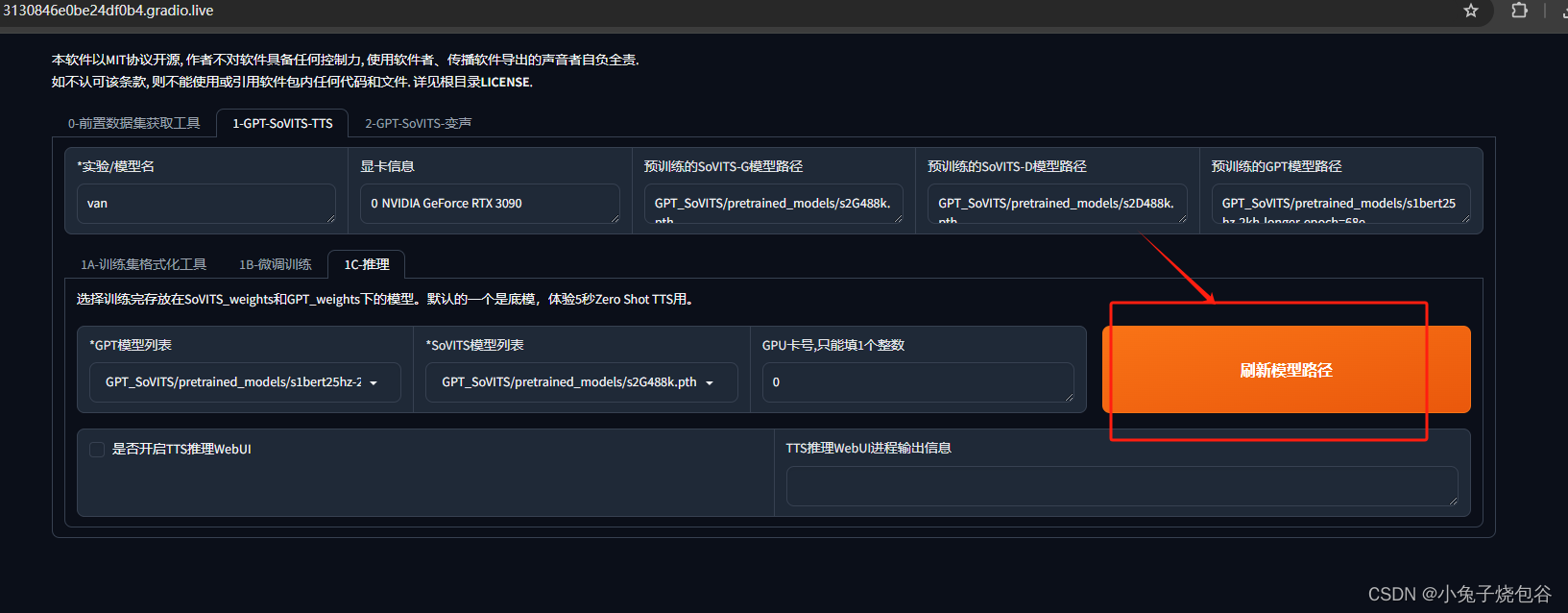
选择刚才训练的数据
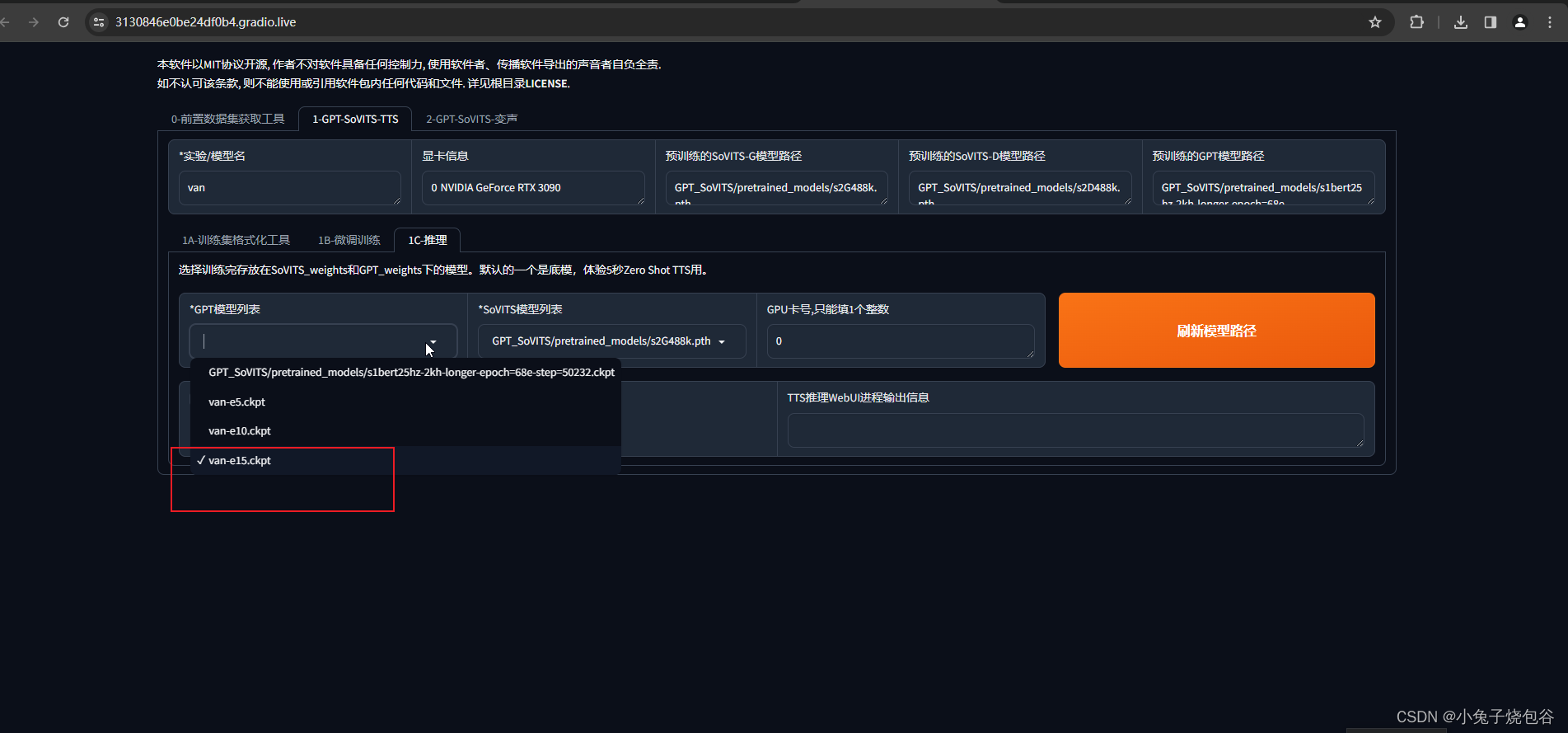
选择刚才训练的数据
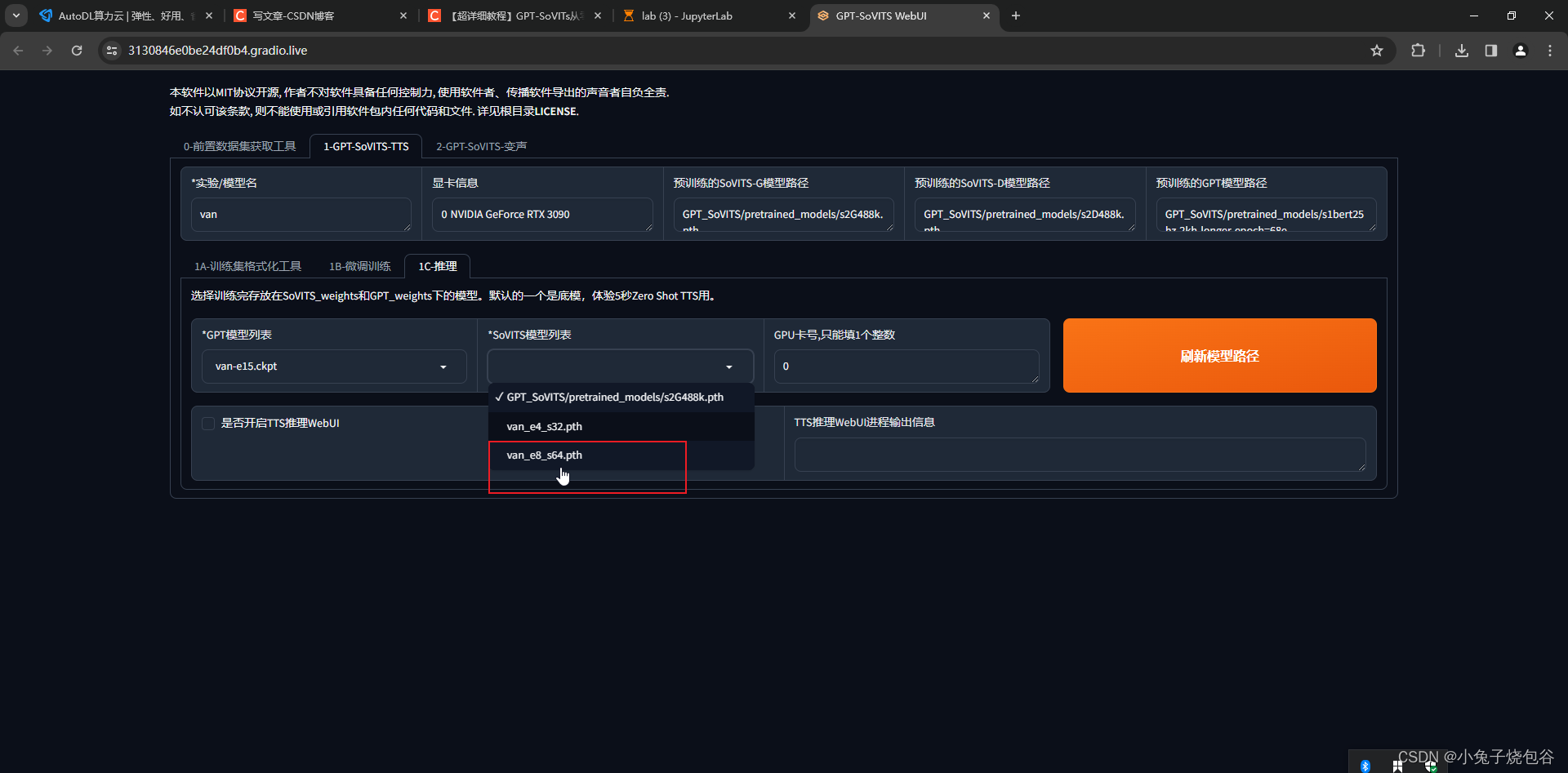
开启UI
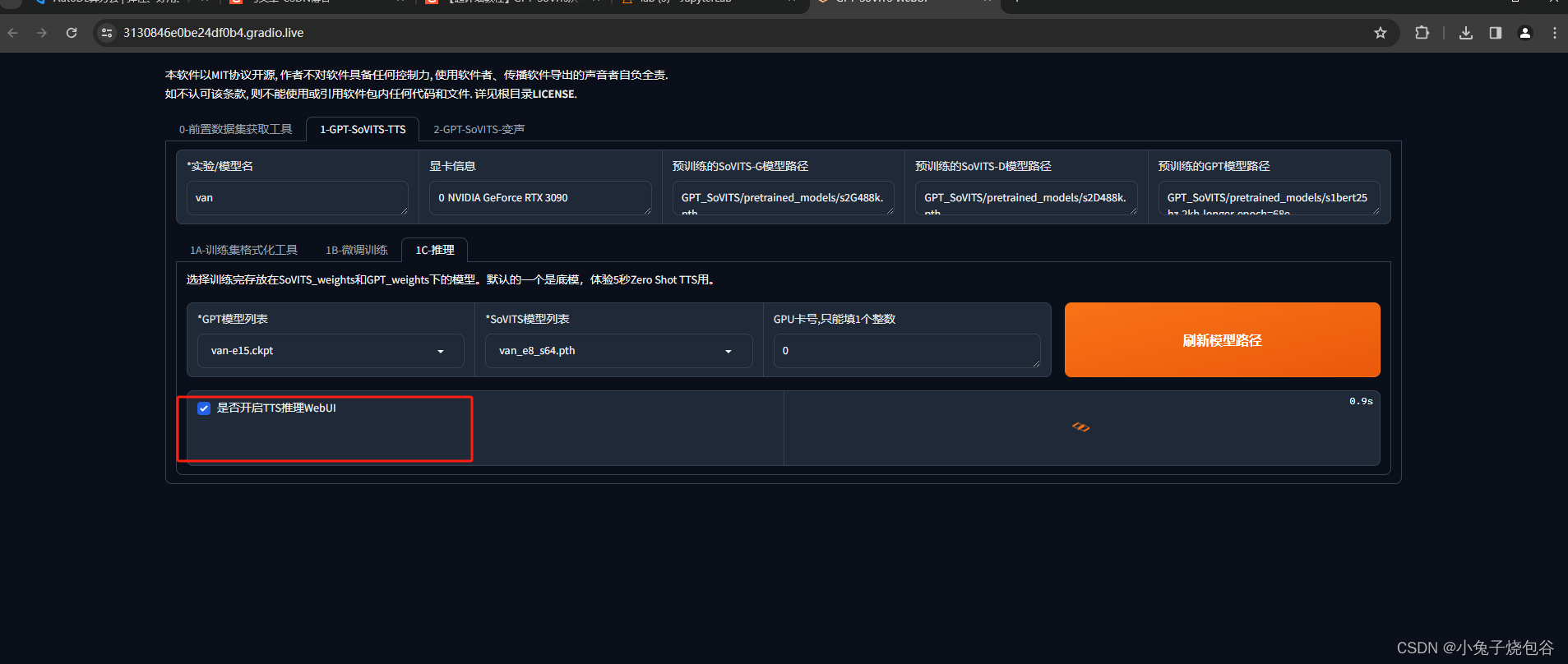
点击日志开启UI
上传对比音频
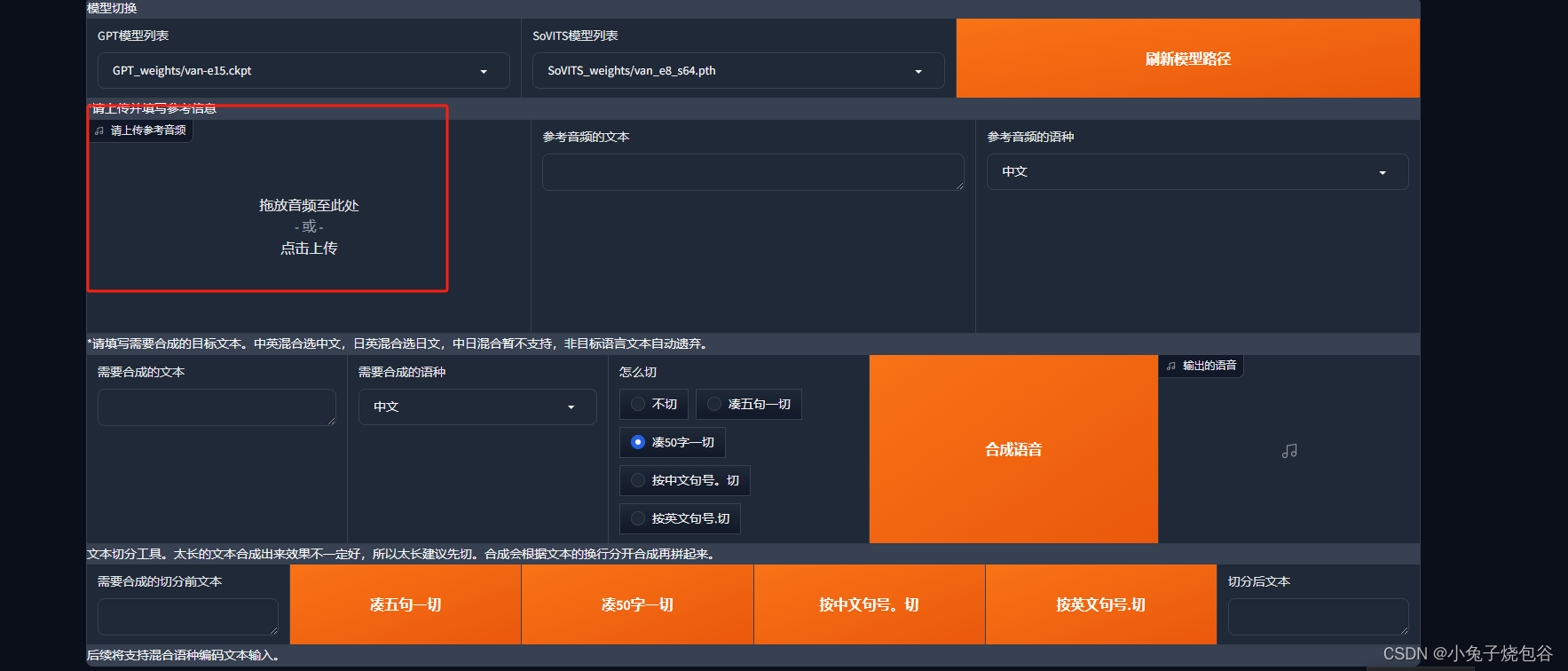
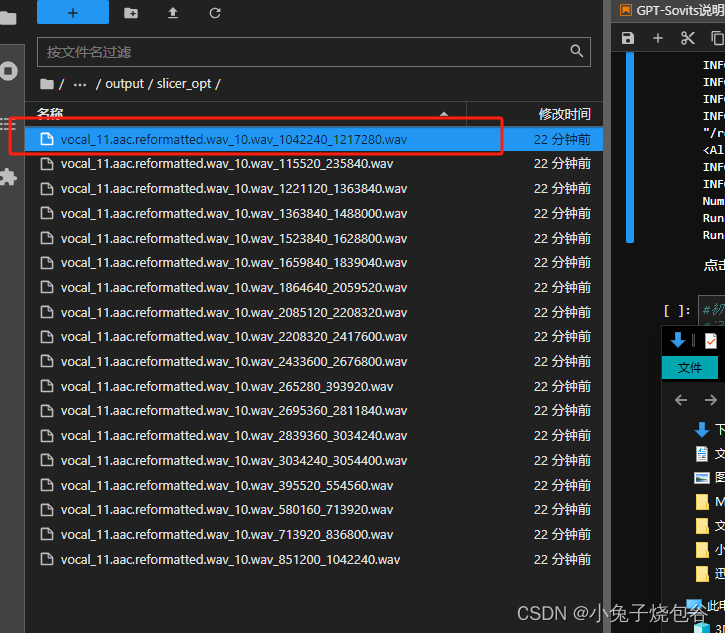
可以上传刚才切割出来的文件
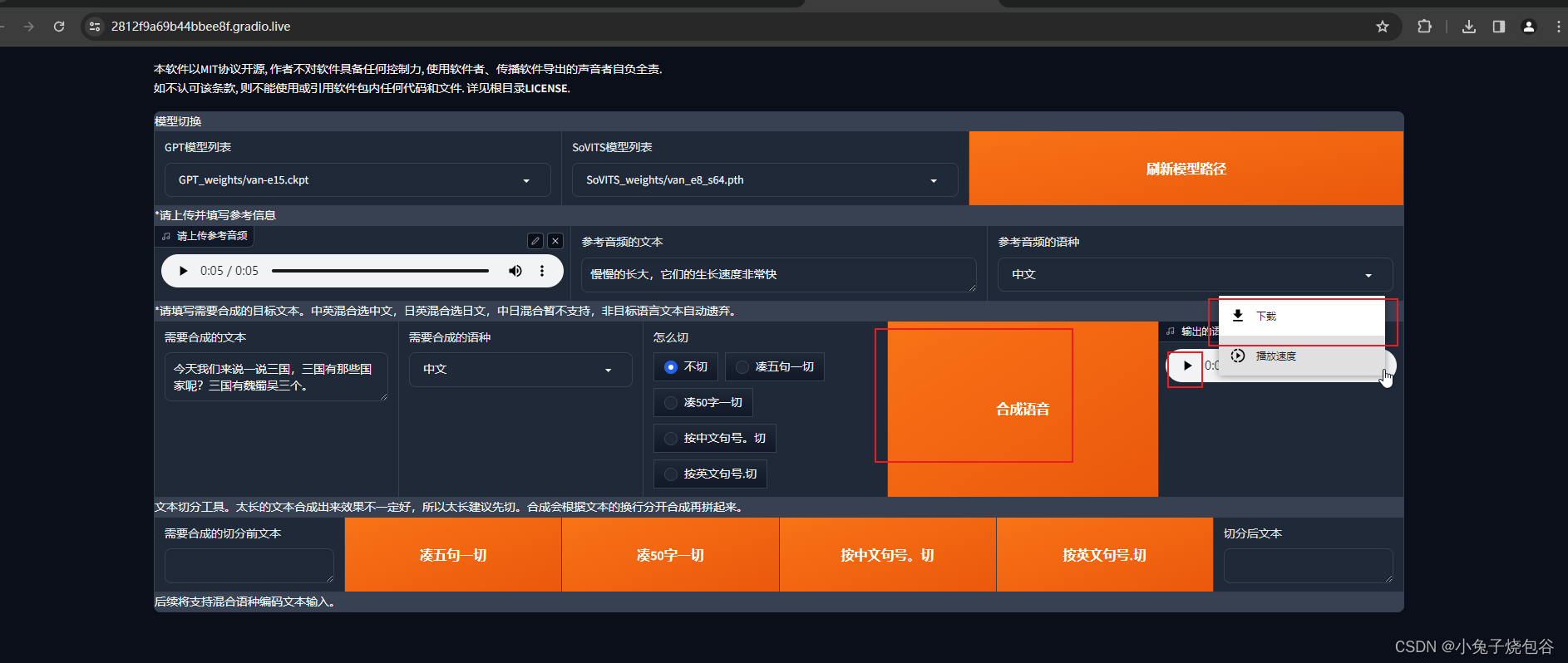
输入音频对应的文字
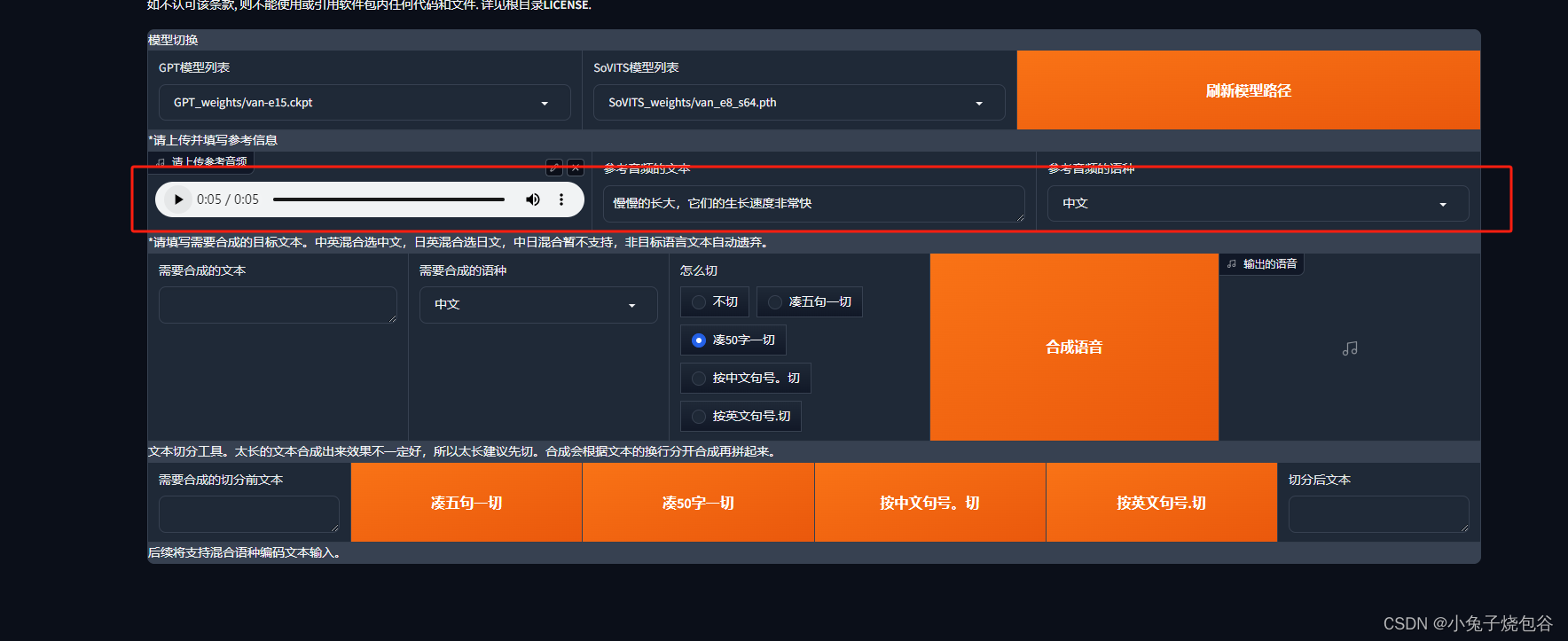
输入我们想要转换的语音,点击合成语音,就可以听到想模拟的声音了,可以下载哦。
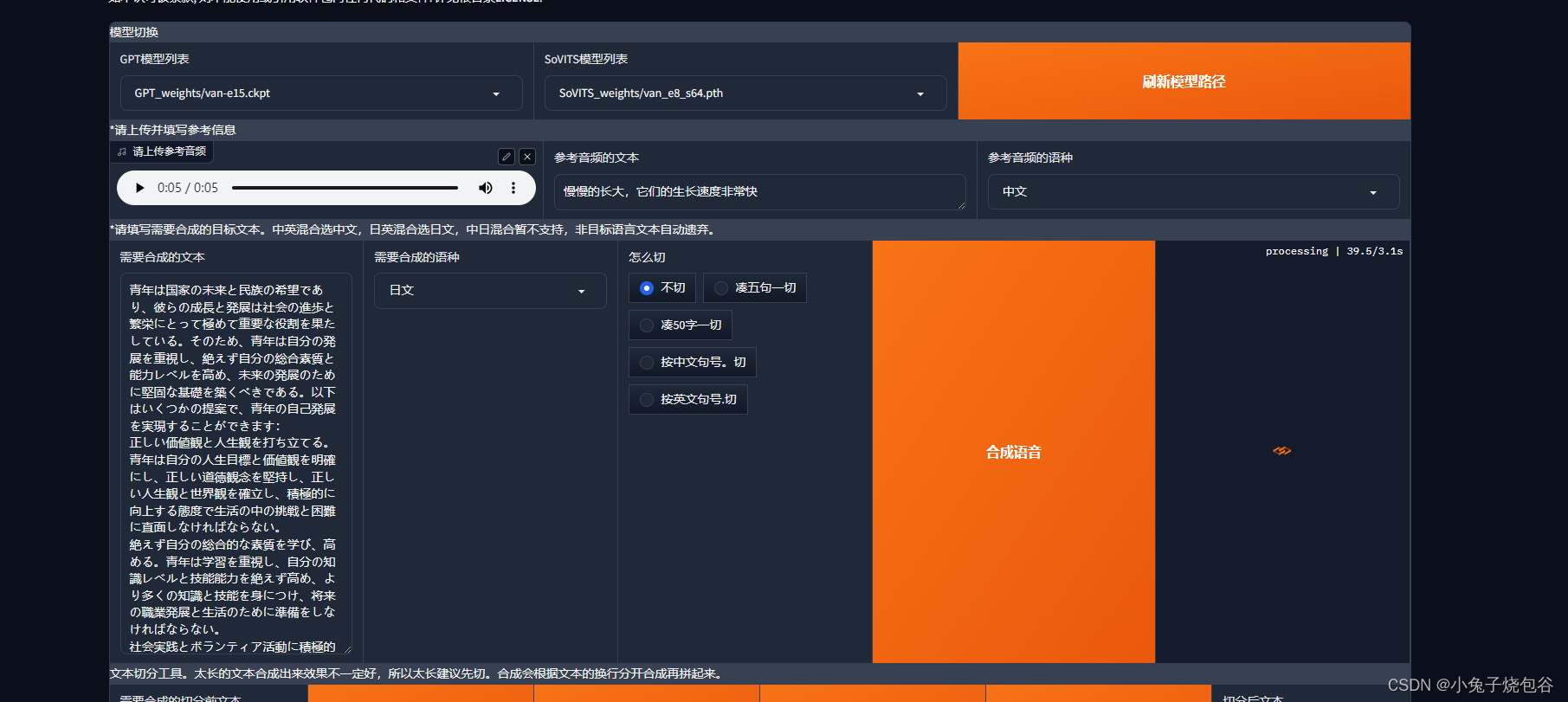
切换日语模式,日语模式也能合成,是不是第一次听自己说日语。
这篇关于GPT-SoVITs从零开始训练声音克隆教程(以云端AutoDL部署为例)【教程超详细】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






