sovits专题


手把手教你GPT-SoVITS V2版本模型教程,内附整合包
首先需要声明的一点就是V1的模型能用在V2上面,但是V2的模型不能用在V1上,并且V1模型在V2上效果不佳! 整合包下载地址: GPT-SoVITS V2整合包下载 https://klrvc.com/ GPT-SoVITS V2模型下载网 这次V2更新了以下功能 UVR5: 1.将hp2模型替换为model_bs_roformer_ep_317_sdr_12.9755模型,大幅提升分离人

使用GPT-soVITS再4060下2小时训练声音模型以及处理断句带来的声音模糊问题
B站UP主视频 感谢UP主“白菜工厂1145号员工”的“熟肉”,我这篇笔记就不展示整一个训练和推理流程,重点写的4060该注意的一些事项。如何解决断句模糊的问题,在本篇笔记的最末尾。 相关连接: 原项目github UP主的说明文档 1、训练模型: 这里是在windows11的4060下进行训练测试,其他显卡不一定又参考作用,简单再复述一下流程: 1.1、准备数据集 在前期准备数据的时
GPT-SoVits:语音克隆,语音融合
首发网站 https://tianfeng.space 前言 零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,

GPT-SoVITS声音克隆训练和推理(新手教程,附整合包)
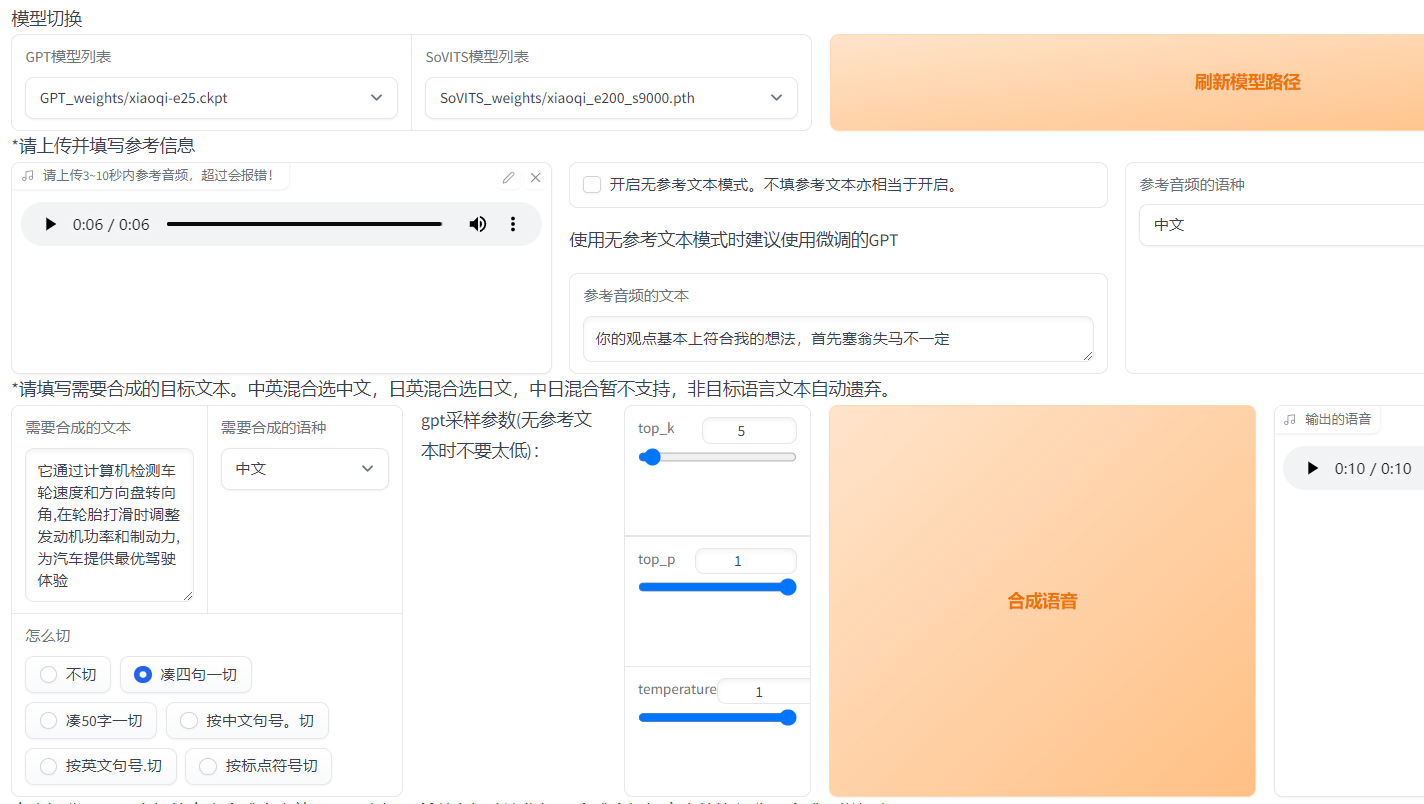
环境: Win10 专业版 GPT-SoVITS-0421 整合包 问题描述: GPT-SoVITS声音克隆如何训练和推理教程 解决方案: Zero-shot TTS: Input a 5-second vocal sample and experience instant text-to-speech conversion.零样本 TTS:输入 5 秒的人声样本并体验即时文本到
【AI开发:音频】二、GPT-SoVITS使用方法和过程中出现的问题(GPU版)
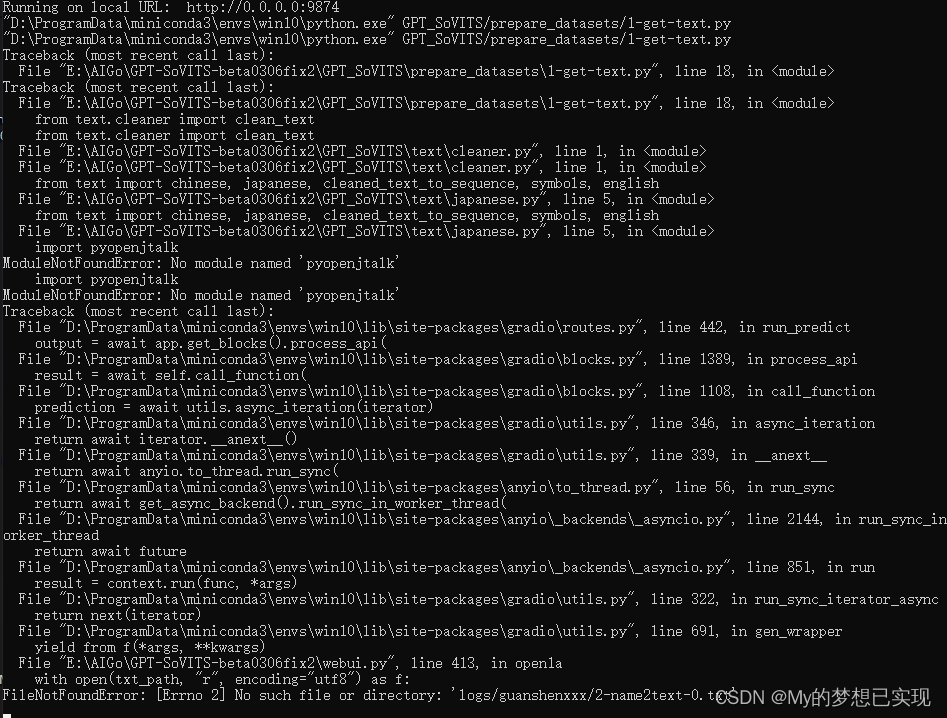
1.FileNotFoundError: [Errno 2] No such file or directory: 'logs/guanshenxxx/2-name2text-0.txt' 这个问题中包含了两个: 第一个:No module named 'pyopenjtalk' 我的电脑出现的就是这个 解决:pip install pyopenjtalk 第二个:nltk_da
【AI开发:音频】一、GPT-SoVITS整合工具包的部署问题解决(GPU版)
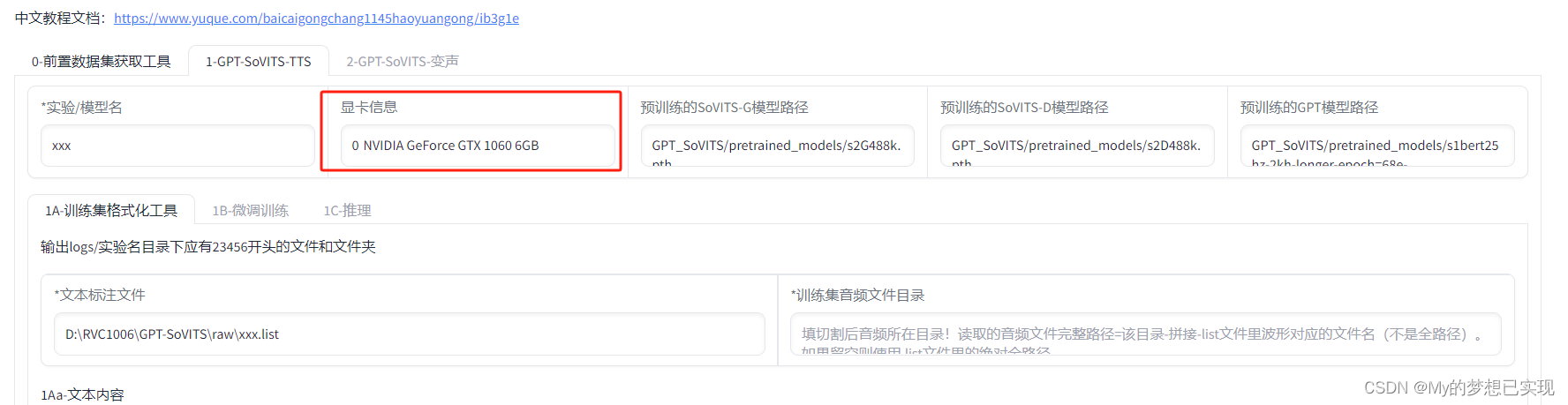
前言 目前GPT-SoVITS的合成效果比较不错,相比较其他厂商的产品要规整的多。众多厂家中也是国内使用最多的一款了,并且这个整合包里携带了,除背景音、切割、训练、微调、合成、低成本合成等一些列完整的工具,也可以作为API进行使用。 GPT-SoVITS是花儿不哭大佬研发的低成本AI音色克隆软件。 本文中,使用GPT-SoVITS-beta03

AI克隆语音(基于GPT-SoVITS)
概述 使用GPT-SoVITS训练声音模型,实现文本转语音功能。可以模拟出语气,语速。如果数据质量足够高,可以达到非常相似的结果。相比于So-VITS-SVC需要的显卡配置更低,数据集更小(我的笔记本NVIDIA GeForce RTX 4050 Laptop GPU跑起来毫无压力。) 使用 GPT-SoVITS项目地址(https://github.com/RVC-Project/Retr
关于GPT-SoVITS语音合成的效果展示(西游之西天送葬团)
目录 使用效果总结合成效果展示 使用效果总结 使用的是2024年03月21日22点28分更新的版本。 使用起来很方便,从它“自带界面”这点就能看出,易于使用也是目的之一,而且从训练到推理的每个步骤都能在界面中完成。 集成了多个实用工具,包括语音伴奏分离、训练集自动分割、中文ASR和文本标注,帮助初学者创建训练数据集和GPT/SoVITS模型。 合成效果虽然需要抽卡,但参数不
【GPT-SOVITS-01】源码梳理
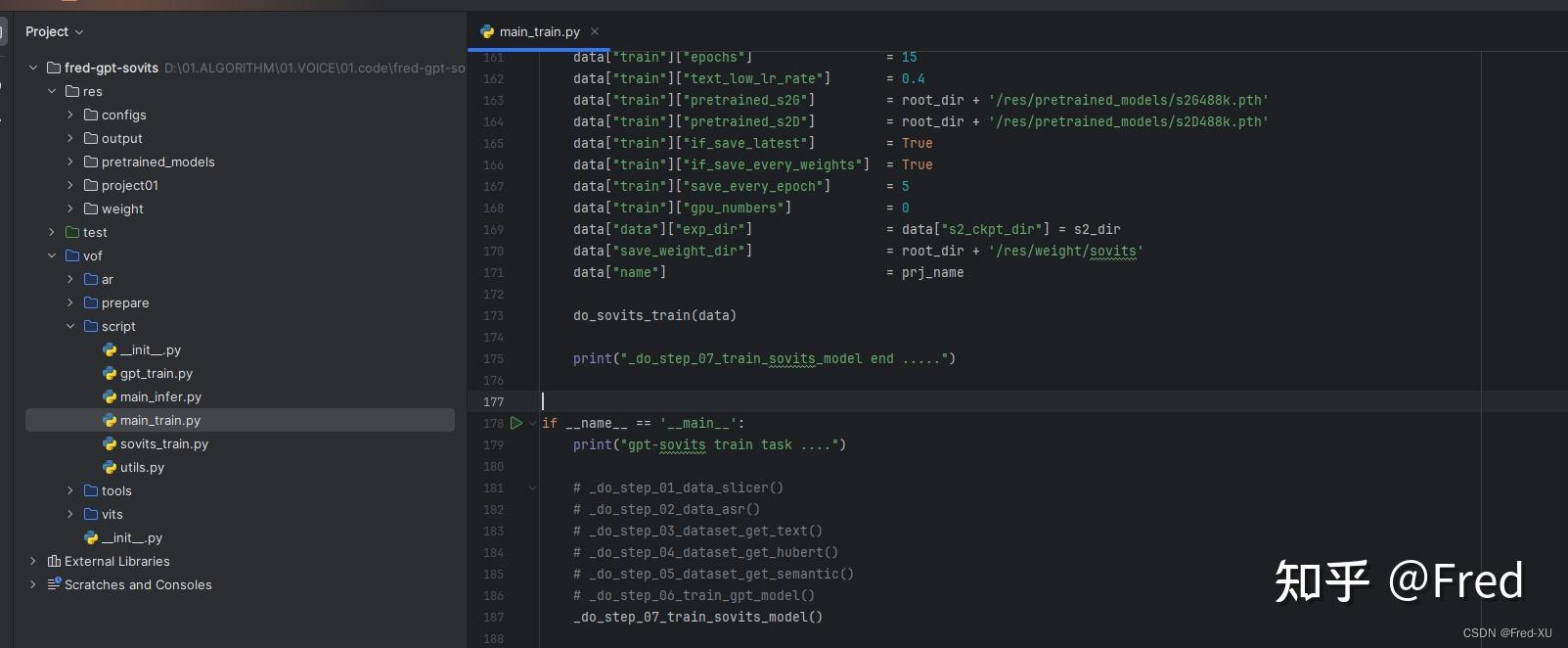
说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。 知乎专栏地址: 语音生成专栏 系列文章地址: 【GPT-SOVITS-01】源码梳理 【GPT-SOVITS-02】GPT模块解析 【GPT-SOVITS-03】SOVITS 模块-生成模型解析 【GPT-SOVITS-04】SOVITS 模块-鉴别模型解析 【GPT-SOVITS-05】SOVITS 模块-残差量化解析
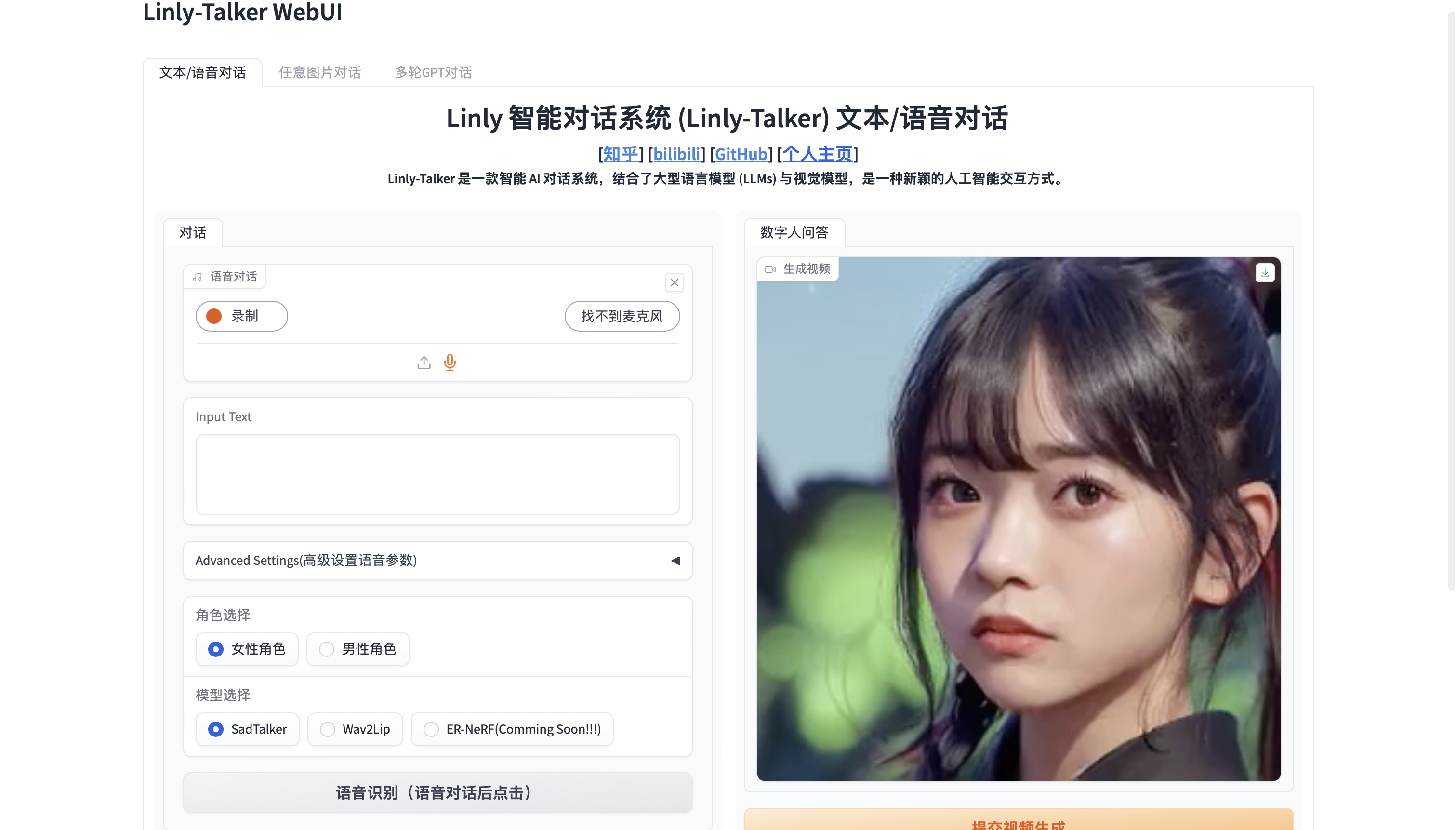
数字人的未来:数字人对话系统 Linly-Talker + 克隆语音 GPT-SoVITS
🚀数字人的未来:数字人对话系统 Linly-Talker + 克隆语音 GPT-SoVITS https://github.com/Kedreamix/Linly-Talker 2023.12 更新 📆 用户可以上传任意图片进行对话 2024.01 更新 📆 令人兴奋的消息!我现在已经将强大的GeminiPro和Qwen大模型融入到我们的对话场景中。用户现在可以在对话中上传任何图片

GPT-SoVITS音色克隆-模型训练步骤
GPT-SoVITS音色克隆-模型训练步骤 GPT-SoVITS模型源码一个简单的TTS后端项目 基于模型部署和训练教程,语雀 模型部署和训练教程 启动模型训练的主页面 1. 切到模型路径 /psycheEpic/GPT-SoVITS 进入Python虚拟环境,并挂起执行python脚本 conda activate GPTSoVitsnohup python ./webui.py
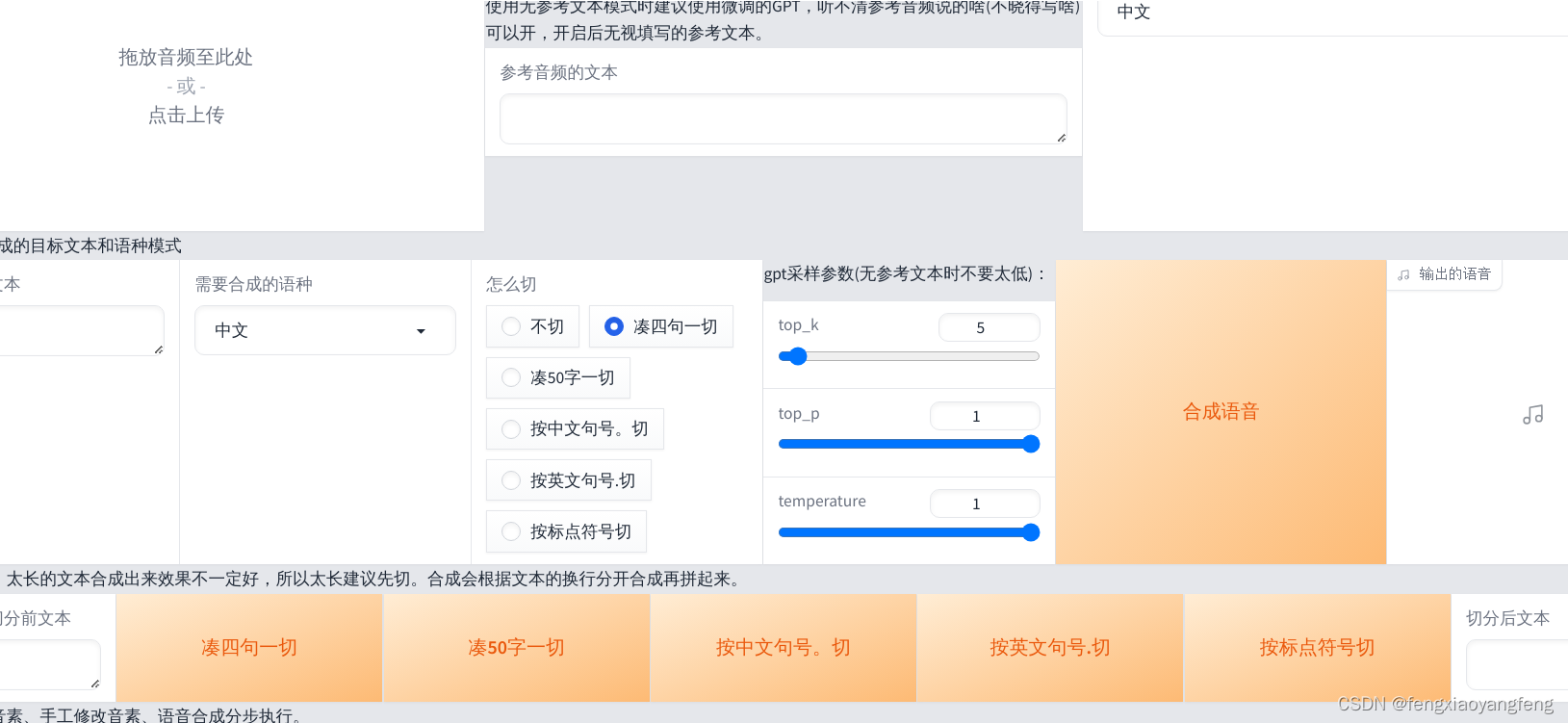
爆火的1分钟声音克隆GPT-SoVITS项目 linux系统 ubuntu22.04安装2天踩坑教程
原项目地址:https://github.com/RVC-Boss/GPT-SoVITS 1分钟素材,最后出来的效果确实不错。 1. cuda环境安装 cuda环境准备 根据项目要求在cuda11.8和12.3都测试了通过。我这里是用cuda11.8 cuda11.8安装教程: ubuntu 22.04 cuda多版本和cudnn安装细节 2.项目python包安装 这里根据官方的说
数字人的未来:数字人对话系统 Linly-Talker + 克隆语音 GPT-SoVITS
🚀数字人的未来:数字人对话系统 Linly-Talker + 克隆语音 GPT-SoVITS https://github.com/Kedreamix/Linly-Talker 2023.12 更新 📆 用户可以上传任意图片进行对话 2024.01 更新 📆 令人兴奋的消息!我现在已经将强大的GeminiPro和Qwen大模型融入到我们的对话场景中。用户现在可以在对话中上传任何图片
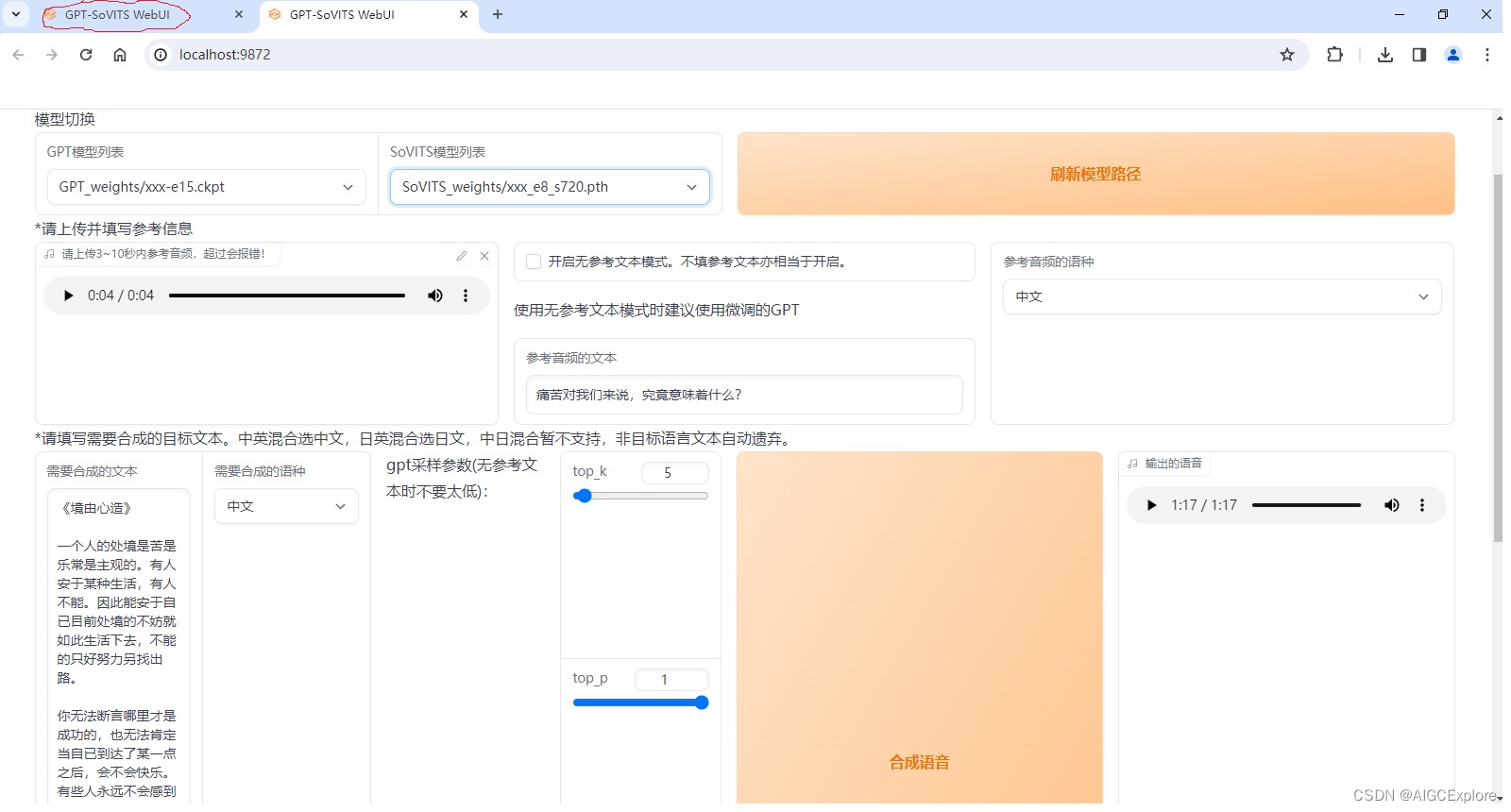
【AIGC】开源声音克隆GPT-SoVITS
GPT-SoVITS 是由 RVC 创始人 RVC-Boss 与 AI 声音转换技术专家 Rcell 共同开发的一款跨语言 TTS 克隆项目,被誉为“最强大中文声音克隆项目” 相比以往的声音克隆项目,GPT-SoVITS 对硬件配置的要求相对较低,一般只需 6GB 显存以上的 GPU 即可满足。而类似 BERT-ViTES2 的模型则需要更高规格的 GPU,否则容易出现显存不足的问题。对于想要体
GPT-SoVITS-WebUI 克隆声音 macos搭建
强大的少样本语音转换与语音合成Web用户界面 macos运行参考 macos conda create -n GPTSoVits python=3.9conda activate GPTSoVits 激活环境 conda activate GPTSoVits停用 conda deactivate mkdir GPTSoVitscd GPTSoVitsgit clone
仅需5元,手把手教你训练纳西妲GPT-SoVITS模型
资源下载及音频试听: 仅需5元,手把手教你训练纳西妲GPT-SoVITS模型 - 风屿岛 (biliwind.com) 购买服务器 首先,我们需要买一台显卡云服务器 极度推荐使用雨云,优惠码:wp-admin 账户注册成功后,前往:购买地址 选择宿迁显卡云 若只是短期使用,建议选择最高配置,如果是长期使用,建议按需选择(主要关注显存) 系统选择Windows Ser
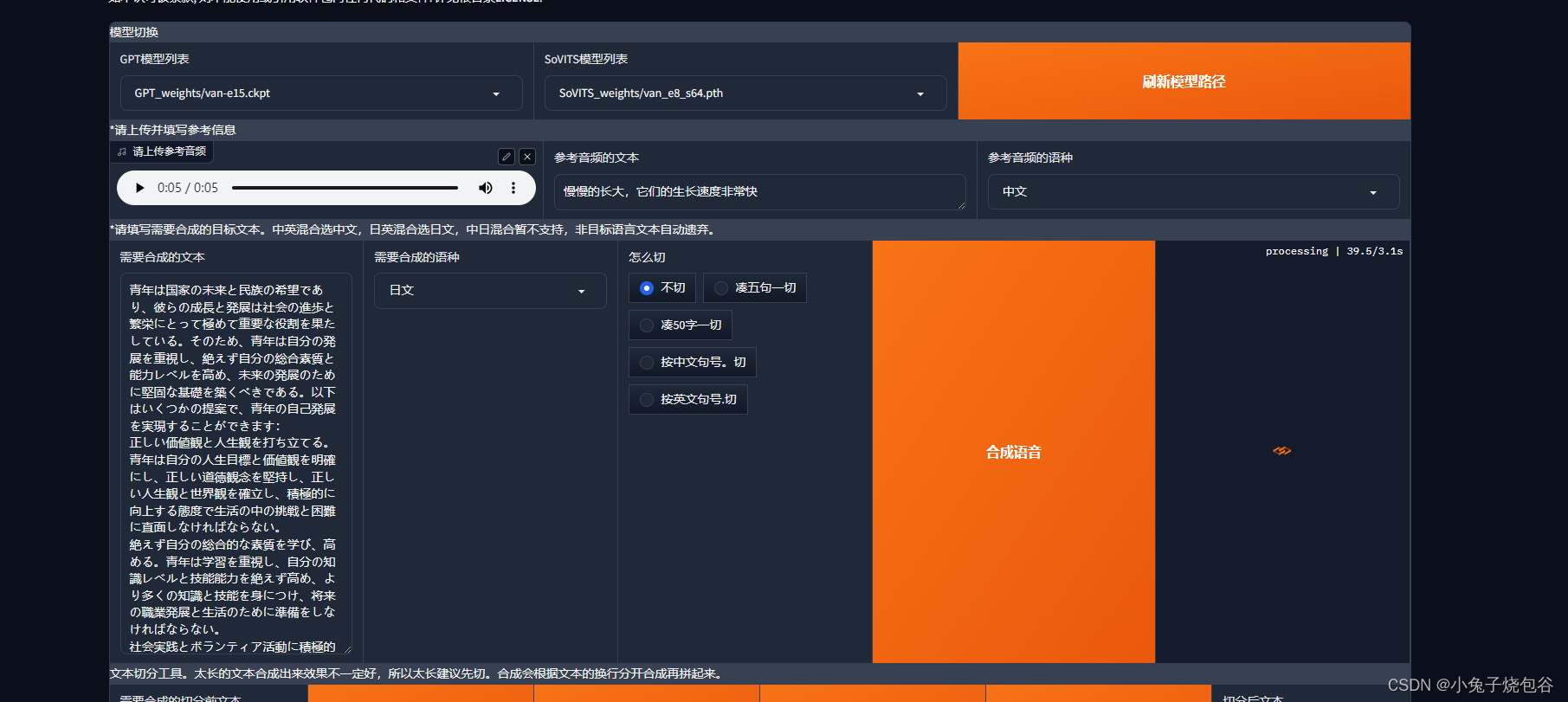
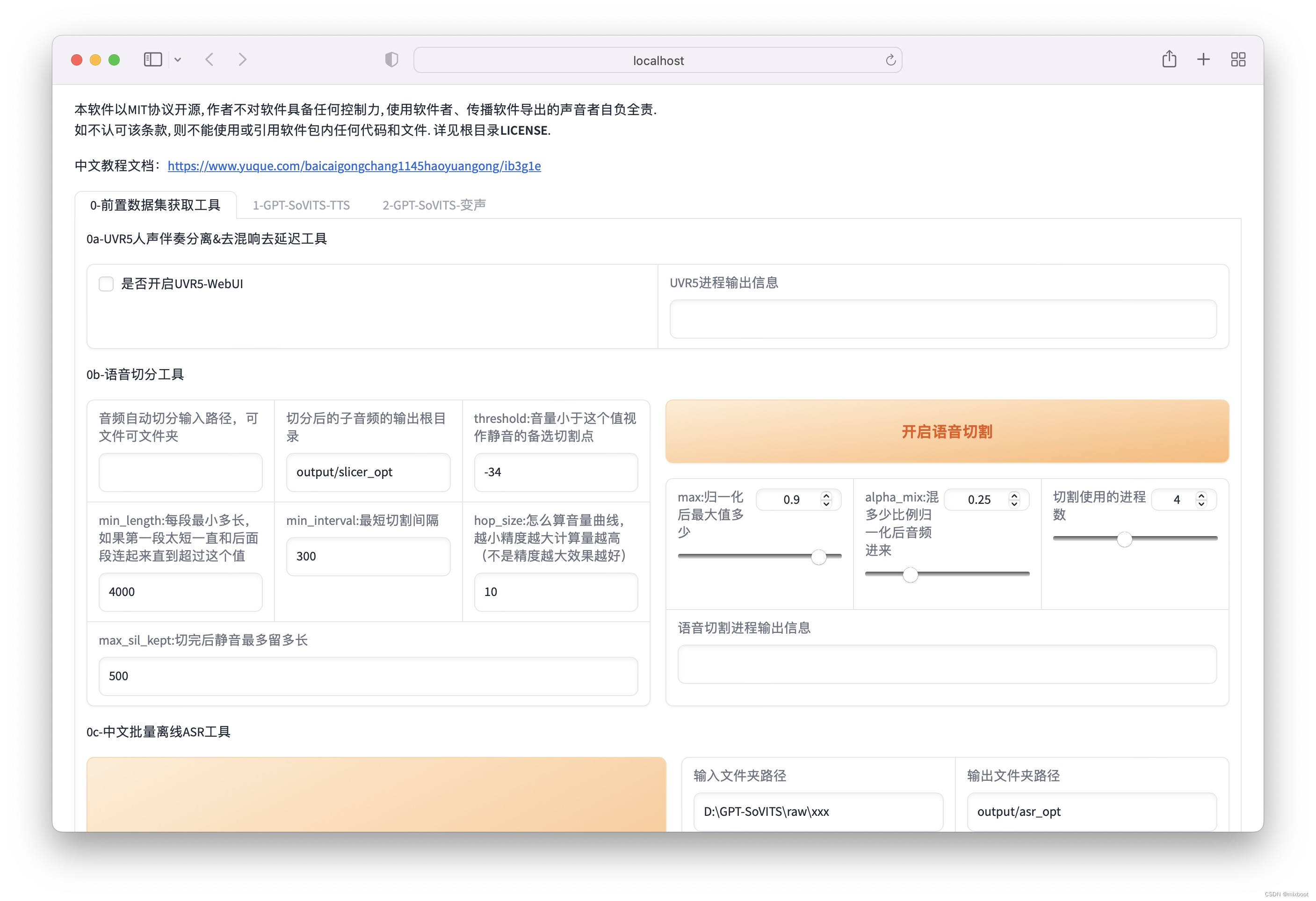
GPT-SoVITs从零开始训练声音克隆教程(以云端AutoDL部署为例)【教程超详细】
打开网站 https://www.autodl.com/ 注册账户和和实名认证、绑定微信才能使用。操作完成后选择镜像购买。 等待创建完成 创建完成单击JupyterLab 在文件GPT-Sovits(使用).ipynb拉到最下面 先运行下图框中命令 再运行下图框中命令,然后单击蓝色链接 打开页面如下所示 单击是否开启UVR5-WebUl 打开UVR5-WebUl页面 打开页面如下

【超详细教程】GPT-SoVITs从零开始训练声音克隆教程(主要以云端AutoDL部署为例)
目录 一、前言 二、GPT-SoVITs使用教程 2.1、Windows一键启动 2.2、AutoDL云端部署 2.3、人声伴奏分离 2.4、语音切割 2.5、打标训练数据 2.6、数据集预处理 2.7、训练音频数据 2.8、推理模型 三、总结 一、前言 近日,RVC变声器的创始人(GitHub昵称为RVC-Boss)与AI音色转换技术专家Rcell合作,共同开

让AI帮你说话--GPT-SoVITS教程
有时候我们在录制视频的时候,由于周边环境嘈杂或者录音设备问题需要后期配音,这样就比较麻烦。一个比较直观的想法就是能不能将写好的视频脚本直接转换成我们的声音,让AI帮我们完成配音呢?在语音合成领域已经有很多这类工作了,最近网上了解到一个效果比较好的项目GPT-SoVITS,尝试了一下,趟了一些坑,记录一下操作过程。 首先附上大佬的仓库和教程: GitHub链接视频教程 下载代码和创建环境 电脑
GPT-SoVITS 测试
开箱直用版(使用 AutoDL) step1 打开地址 https://www.codewithgpu.com/i/RVC-Boss/GPT-SoVITS/GPT-SoVITS-Official 选择 AutoDL创建实例,选择 3080ti 机器 step2 创建好实例之后,进入命令行,输入命令 echo {}> ~/GPT-SoVITS/i18n/locale/en_US.json
GPT-SoVits:刚上线就获得了5.1k star的开源声音克隆项目!效果炸裂的跨语言音色克隆模型!
上周,RVC变声器创始人 (GitHub昵称:RVC-Boss) 开源了一款跨语言音色克隆项目 GPT-SoVITS。项目一上线就引来了互联网大佬和博主的好评推荐,不到两天时间就已经在GitHub上获得了1.4k Star量,不过现在已经飙升到了5.1k。 据说,该项目是RVC-Boss 同Rcell (AI音色转换技术Sovits开发者)共同研究,历时半年,期间遇到了很多难题而开发出来的一款全

关于Sovits的本地部署
近几天有好多小伙伴咨询Sovits本地部署的问题,所以呢决定写个简易教程。 首先给出官方Github链接:GitHub - svc-develop-team/so-vits-svc: SoftVC VITS Singing Voice Conversion 首先放出声明(官方写的): 本项目为开源、离线的项目,SvcDevelopTeam的所有成员与本项目的所有开发者以及维护者(以下简称