本文主要是介绍在AutoDL上部署Yi-34B大模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在AutoDL上部署Yi-34B大模型
Yi介绍
- Yi 系列模型是 01.AI 从零训练的下一代开源大语言模型。
- Yi 系列模型是一个双语语言模型,在 3T 多语言语料库上训练而成,是全球最强大的大语言模型之一。Yi 系列模型在语言认知、常识推理、阅读理解等方面表现优异。
- Yi-34B-Chat 模型在 AlpacaEval Leaderboard 排名第二,仅次于 GPT-4 Turbo,超过了 GPT-4、Mixtral 和 Claude 等大语言模型(数据截止至 2024 年 1 月)
- Yi-34B 模型在 Hugging Face Open LLM Leaderboard(预训练)与 C-Eval 基准测试中荣登榜首,在中文和英文语言能力方面均超过了其它开源模型,例如,Falcon-180B、Llama-70B 和 Claude(数据截止至 2023 年 11 月)。
部署步骤
硬件要求
部署 Yi 系列模型之前,确保硬件满足以下要求。
| 模型 | 最低显存 | 推荐GPU示例 |
|---|---|---|
| Yi-6B-Chat | 15 GB | RTX 3090 RTX 4090 A10 A30 |
| Yi-6B-Chat-4bits | 4 GB | RTX 3060 RTX 4060 |
| Yi-6B-Chat-8bits | 8 GB | RTX 3070 RTX 4060 |
| Yi-34B-Chat | 72 GB | 4 x RTX 4090 A800 (80GB) |
| Yi-34B-Chat-4bits | 20 GB | RTX 3090 RTX 4090 A10 A30 A100 (40GB) |
| Yi-34B-Chat-8bits | 38 GB | 2 x RTX 3090 2 x RTX 4090 A800 (40GB) |
运行实例
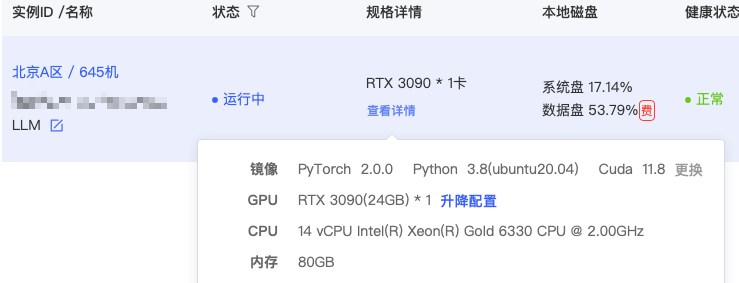

pip install -i https://pypi.tuna.tsinghua.edu.cn/simple modelscope
下载模型
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('01ai/Yi-34B-Chat-4bits', cache_dir='autodl-tmp', revision='master', ignore_file_pattern='.bin')
从modelscope上下载Yi-34B-Chat-4bits模型,存放目录为autodl-tmp
版本是master,去除后缀为.bin的文件,这里只需要下载safetensors后缀的模型
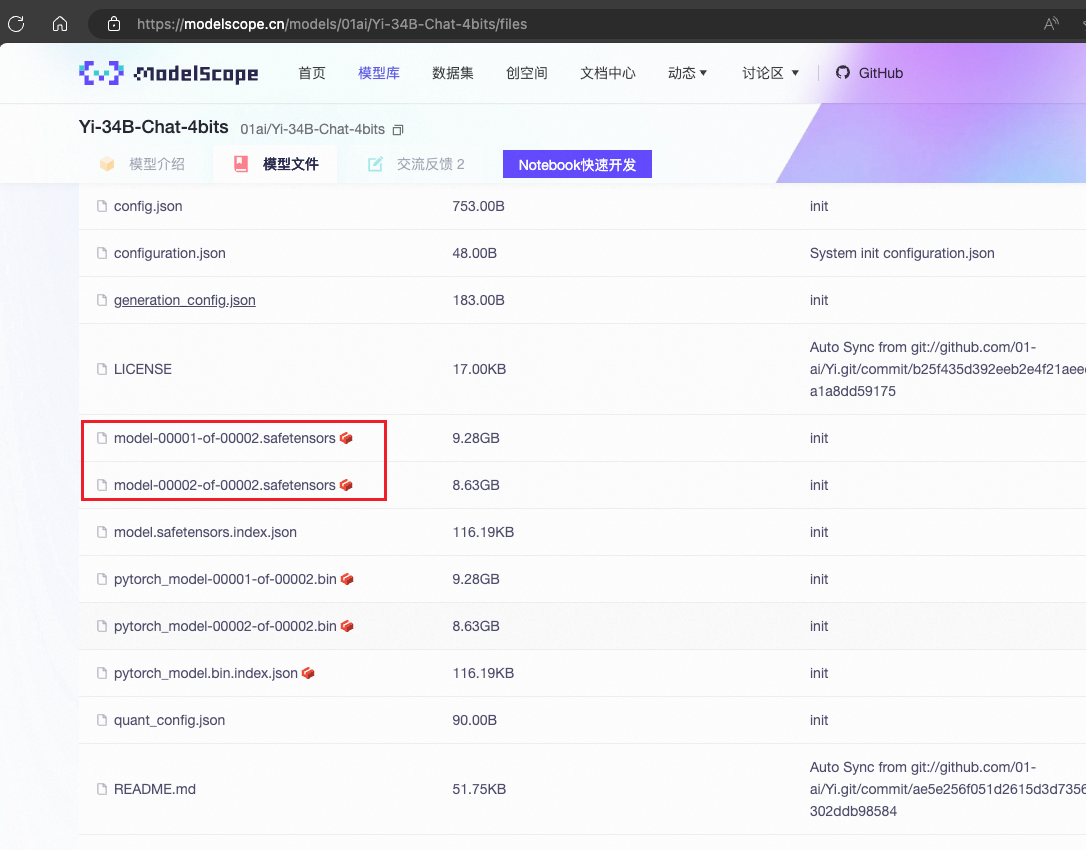
安装 vllm
vLLM是伯克利大学LMSYS组织开源的大语言模型高速推理框架,旨在极大地提升实时场景下的语言模型服务的吞吐与内存使用效率。vLLM是一个快速且易于使用的库,用于 LLM 推理和服务,可以和HuggingFace 无缝集成。vLLM利用了全新的注意力算法「PagedAttention」,有效地管理注意力键和值。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple vllm
python -m vllm.entrypoints.openai.api_server \--model /root/autodl-tmp/01ai/Yi-34B-Chat-4bits \--served-model-name 01ai/Yi-34B-Chat-4bits \--trust-remote-code \--max-model-len 2048 -q awq
– model : 指定模型的位置
– served-model-name : 指定模型的名称
– trust-remote-code : 接收它执行的代码
– max-model-len : 接收的上下文大小
-q awq : 量化方式为awq
nvidia-smi
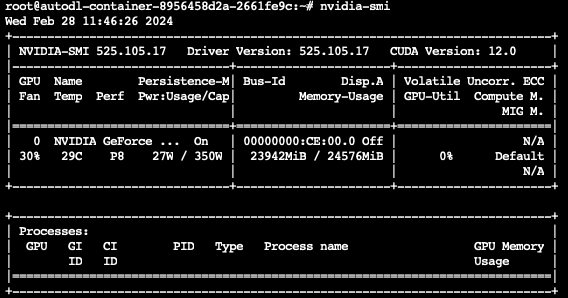
显示占用的23G显存
- 测试服务
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{"model": "01ai/Yi-34B-Chat-4bits","prompt": "San Francisco is a","max_tokens": 7,"temperature": 0
}'
执行 benchmark 测试
-
关闭之前的API Server服务
-
开启AutoDL的学术加速
source /etc/network_turbo
-
下载vllm 源码
git clone https://github.com/vllm-project/vllmcd vllm/benchmarks
-
测试
-
python benchmark_throughput.py \--backend vllm \--input-len 128 --output-len 512 \--model /root/autodl-tmp/01ai/Yi-34B-Chat-4bits \-q awq --num-prompts 100 --seed 1100 \--trust-remote-code \--max-model-len 2048
-
gradio 的 chat 组件
- 安装openai
pip install openai -U
- 安装gradio
pip install gradio==3.41
- 创建一个python脚本
chat.py
from openai import OpenAI
import gradio as gr# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"# 创建一个 OpenAI 客户端,用于与 API 服务器进行交互
client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)def predict(message, history):# 将聊天历史转换为 OpenAI 格式history_openai_format = [{"role": "system", "content": "你是个靠谱的 AI 助手,尽量详细的解答用户的提问。"}]for human, assistant in history:history_openai_format.append({"role": "user", "content": human })history_openai_format.append({"role": "assistant", "content":assistant})history_openai_format.append({"role": "user", "content": message})# 创建一个聊天完成请求,并将其发送到 API 服务器stream = client.chat.completions.create(model='01ai/Yi-34B-Chat-4bits', # 使用的模型名称messages= history_openai_format, # 聊天历史temperature=0.8, # 控制生成文本的随机性stream=True, # 是否以流的形式接收响应extra_body={'repetition_penalty': 1, 'stop_token_ids': [7]})# 从响应流中读取并返回生成的文本partial_message = ""for chunk in stream:partial_message += (chunk.choices[0].delta.content or "")yield partial_message# 创建一个聊天界面,并启动它,share=True 让 gradio 为我们提供一个 debug 用的域名
gr.ChatInterface(predict).queue().launch(share=True)
- 开启一个新的终端执行命令:
python chat.py
稍等它在终端给我们生成一个
xxxx.gradio.live的域名,访问这个域名就可以进行测试了。
- 如果gradio无法生成可分享的外部连接

-
解决办法 :
-
1.下载此文件:https://cdn-media.huggingface.co/frpc-gradio-0.2/frpc_linux_amd64 如果auto服务器下载不到,可以手动上传 2.将下载的文件重命名为:frpc_linux_amd64_v0.2 mv frpc_linux_amd64 frpc_linux_amd64_v0.2 3.将文件移动到以下位置/root/miniconda3/lib/python3.8/site-packages/gradio cp frpc_linux_amd64_v0.2 /root/miniconda3/lib/python3.8/site-packages/gradio 4.给予执行权限 chmod +x /root/miniconda3/lib/python3.8/site-packages/gradio/frpc_linux_amd64_v0.2
-

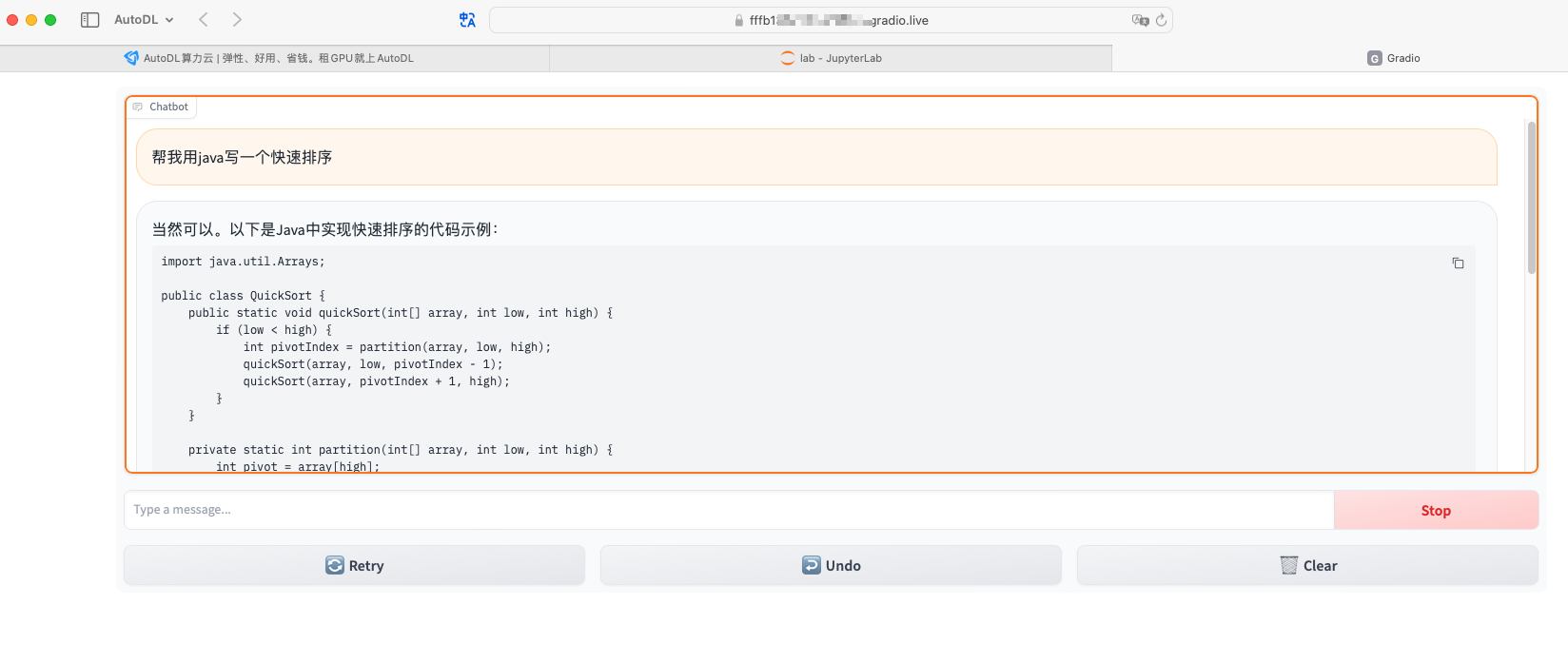
效果
- 3090 运行起来之后,问题问到第二个之后就会OOM,显存几乎全部占满
这篇关于在AutoDL上部署Yi-34B大模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







