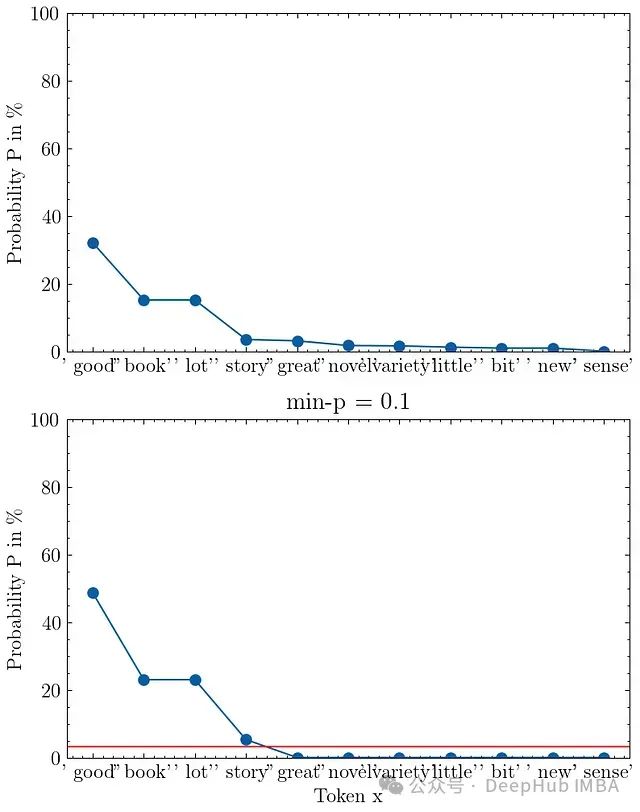
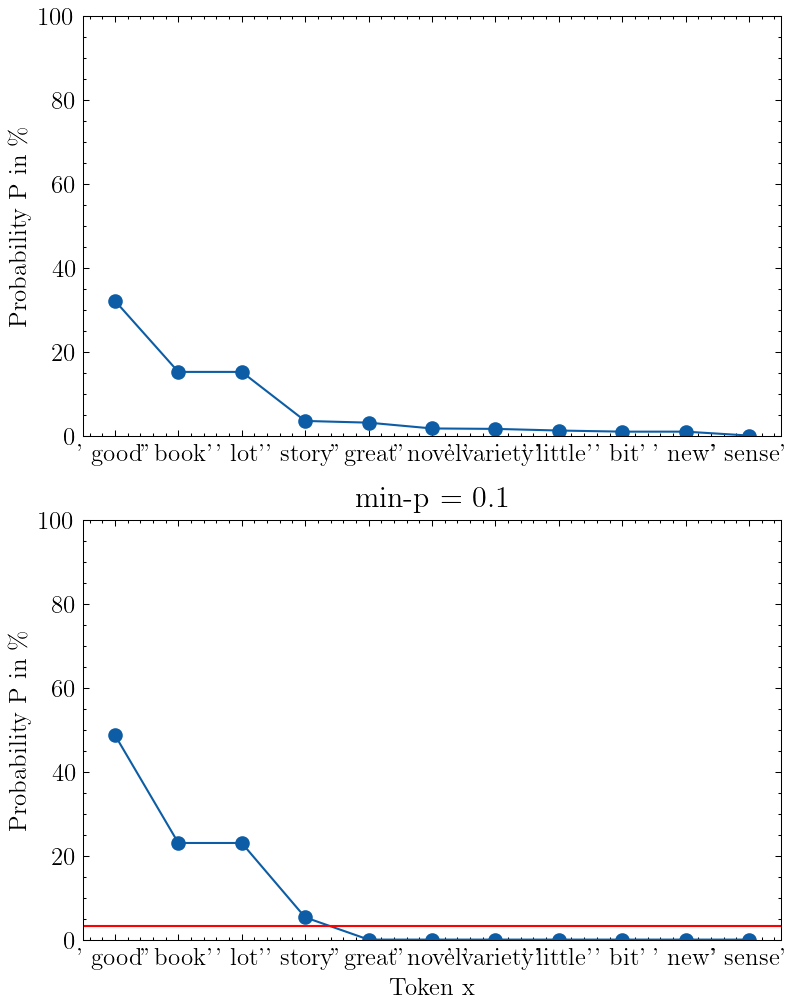
本文主要是介绍退火朗之万动力学采样,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
退火朗之万动力学采样(Simulated Annealing Langevin Dynamics Sampling)结合了退火技术和朗之万动力学,是一种用于分子模拟和统计物理中的计算方法。这种方法可以帮助系统从局部最小值中逃逸,以找到全局最小值或进行有效的配置空间探索。
这里简要介绍下朗之万动力学和退火技术:
朗之万动力学(Langevin Dynamics)
朗之万动力学是分子模拟中常用的一种方法,用于模拟粒子在含有随机力(热噪声)的介质中的运动。其基本方程考虑了粒子的惯性、粘滞阻力以及一个随机的力。数学形式是一种随机微分方程,可以写作:
m d 2 x d t 2 = − ∇ U ( x ) − γ d x d t + 2 γ k B T R ( t ) m\frac{d^2\mathbf{x}}{dt^2} = -\nabla U(\mathbf{x}) - \gamma\frac{d\mathbf{x}}{dt} + \sqrt{2\gamma k_B T}\mathbf{R}(t) mdt2d2x=−∇U(x)−γdtdx+2γkBTR(t)
其中 m m m 是质量, x \mathbf{x} x 是位置, U ( x ) U(\mathbf{x}) U(x) 是势能函数, γ \gamma γ 是阻尼系数, k B k_B kB 是玻尔兹曼常数, T T T 是温度, R ( t ) \mathbf{R}(t) R(t) 是标准正态分布的随机力。
退火技术(Simulated Annealing)
退火技术是一种全局优化算法,其灵感来源于金属加热后再慢慢冷却的过程。在模拟退火中,系统的温度逐渐降低,系统可能的能量状态按照玻尔兹曼分布进行采样。开始时,系统温度较高,系统可以跨越较高的能量壁垒,随着温度的降低,系统逐渐冷却并趋向于处于较低能量的状态。
退火朗之万动力学采样
结合这两种技术的退火朗之万动力学采样,在模拟过程中逐渐降低系统的温度。这种方法特别适用于复杂能量景观的系统,它可以帮助系统跳出局部最小值,寻找全局最小值。在这个过程中,朗之万动力学提供了随机扰动,退火技术降低系统的温度。
具体的实现方式是,随着时间的推移,逐渐降低用于定义朗之万动力学中随机力标准偏差的温度参数。在优化问题中,这有助于在初期允许系统探索较大的配置空间,而在后期则集中在潜在的最优解周围。
这种方法在计算化学、材料科学、生物物理学以及机器学习的某些应用中是非常有用的,特别是在对系统的底层势能景观知之甚少时。然而,正确地选择降温计划和朗之万动力学的参数对于采样的成功至关重要。
虚构应用例子:高分辨率图像生成
退火朗之万动力学采样在基于分数的生成模型(如分数驱动的分布或Score-Based Generative Models)中的应用是一个先进而且活跃的研究方向。分数驱动的生成模型利用了一个观察到的数据分布的梯度信息(即分数),来生成新的、与观测数据相似的样本。这种方法可以被应用于各种领域,从图像生成到物理模拟等。
以下是一个退火朗之万动力学采样在基于分数的生成模型应用的虚构例子,用于说明其工作原理和潜在的应用场景。
背景
假设我们正在研究一种新的高分辨率图像生成模型,该模型旨在创建逼真的自然景观图像。我们的目标是生成高质量、多样化、并且视觉上吸引人的图像,这在艺术创作、游戏开发、虚拟现实等领域都有广泛的应用。
模型设计
我们设计了一个基于分数的生成模型,该模型通过学习一个数据集中真实景观图像的分数(即数据分布的梯度)来生成新图像。这种方法的关键在于精确地估计每个图像的梯度信息,然后使用这些信息来引导图像的生成过程。
退火朗之万动力学采样的应用
为了有效地采样并生成新的图像,我们采用了退火朗之万动力学采样方法。具体来说,我们的采样过程从一个随机初始化的图像开始,逐渐调整像素值以最小化与目标分布的差异。
- 初始化阶段:选择一个随机或简单噪声图像作为起点。
- 动态更新:利用朗之万动力学的方法,根据当前图像的分数梯度引入随机扰动,同时考虑到梯度方向来调整图像。这个动态更新的过程模拟了物理中粒子在势场中的随机运动。
- 退火调度:在采样过程中,我们逐步降低系统的“温度”,这实际上降低了随机扰动的强度,允许系统逐渐聚焦于高概率(即高质量)的图像生成。这个退火过程帮助避免生成过程陷入局部最小值,从而促进多样性和创新性的图像生成。
结果
使用退火朗之万动力学采样,我们的模型能够生成一系列既逼真又多样化的自然景观图像。退火过程确保了生成的图像不仅质量高,而且避免了重复或过于简化的图案。
结论
这个虚构的例子展示了退火朗之万动力学采样在基于分数的生成模型中的一个潜在应用场景。通过精心设计的退火过程和动力学更新机制,可以生成高质量和多样化的图像,这对于提高生成模型的实用性和创造力具有重要意义。
需要指出的是,尽管这个例子是虚构的,但它基于实际的技术原理,类似的方法已经被应用于各种机器学习和人工智能领域中,用于解决复杂的生成任务。
这篇关于退火朗之万动力学采样的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!