本文主要是介绍助力樱桃智能自动化采摘,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建果园种植采摘场景下樱桃成熟度智能检测识别系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着科技的飞速发展,人工智能(AI)技术已经渗透到我们生活的方方面面,从智能家居到自动驾驶,再到医疗健康,其影响力无处不在。然而,当我们把目光转向中国的农业领域时,一个令人惊讶的事实映入眼帘——在这片广袤的土地上,农业生产仍然大量依赖人力,而非智能机械化。与此同时,国外的农业生产模式早已进入全面机械化的新时代。面对这一现状,我们不禁要思考:如何将AI技术融入农业,引领农业生产走向数字化、智能化?
樱桃,作为一种高价值水果,其种植和采摘过程一直是农业生产中的关键环节。传统的樱桃采摘方式主要依靠人力,这不仅效率低下,而且成本高昂。更重要的是,随着人口老龄化问题的加剧,劳动力短缺已经成为制约农业发展的瓶颈。因此,探索樱桃采摘的智能化解决方案显得尤为重要,深度学习技术的快速发展为我们提供了新的思路。通过结合机械设计和AI智能模型,我们可以实现樱桃采摘的完全智能机械化。具体来说,这种智能采摘系统可以通过前端连接的摄像头对果树上的果实进行实时检测识别。利用深度学习算法,系统能够准确地分辨出已经成熟的果树、半成熟的果实和未成熟的果实。一旦识别出成熟的果实,系统便会将信号传递给机械臂,机械臂则会自动完成采摘动作。这种智能采摘系统的优势显而易见。首先,它大大提高了采摘效率,减少了人力成本。其次,由于机械臂的精准操作,可以减少对果树的伤害,保护果树资源。此外,智能采摘系统还可以根据果实的成熟度进行分拣,提高产品的品质和市场竞争力。本文正是基于这样的背景思考下,想要从软件实验实践分析的角度出发,来实际探索分析此举落地应用的可行性,在前文中我们已经做了相关的开发实践,感兴趣的话可以自行移步阅读即可:
《助力樱桃智能自动化采摘,基于YOLOv3全系列【yolov3tiny/yolov3/yolov3spp】参数模型开发构建果园种植采摘场景下樱桃成熟度智能检测识别系统》
本文主要是想要基于经典的YOLOv5全系列的参数模型来开发构建对应的检测系统,首先看下实例效果:
接下来简单看下实例数据集:

本文是选择的是YOLOv5算法模型来完成本文项目的开发构建。相较于前两代的算法模型,YOLOv5可谓是集大成者,达到了SOTA的水平,下面简单对v3-v5系列模型的演变进行简单介绍总结方便对比分析学习:
【YOLOv3】
YOLOv3(You Only Look Once version 3)是一种基于深度学习的快速目标检测算法,由Joseph Redmon等人于2018年提出。它的核心技术原理和亮点如下:
技术原理:
YOLOv3采用单个神经网络模型来完成目标检测任务。与传统的目标检测方法不同,YOLOv3将目标检测问题转化为一个回归问题,通过卷积神经网络输出图像中存在的目标的边界框坐标和类别概率。
YOLOv3使用Darknet-53作为骨干网络,用来提取图像特征。检测头(detection head)负责将提取的特征映射到目标边界框和类别预测。
亮点:
YOLOv3在保持较高的检测精度的同时,能够实现非常快的检测速度。相较于一些基于候选区域的目标检测算法(如Faster R-CNN、SSD等),YOLOv3具有更高的实时性能。
YOLOv3对小目标和密集目标的检测效果较好,同时在大目标的检测精度上也有不错的表现。
YOLOv3具有较好的通用性和适应性,适用于各种目标检测任务,包括车辆检测、行人检测等。
【YOLOv4】
YOLOv4是一种实时目标检测模型,它在速度和准确度上都有显著的提高。相比于其前一代模型YOLOv3,YOLOv4在保持较高的检测精度的同时,还提高了检测速度。这主要得益于其采用的CSPDarknet53网络结构,主要有三个方面的优点:增强CNN的学习能力,使得在轻量化的同时保持准确性;降低计算瓶颈;降低内存成本。YOLOv4的目标检测策略采用的是“分而治之”的策略,将一张图片平均分成7×7个网格,每个网格分别负责预测中心点落在该网格内的目标。这种方法不需要额外再设计一个区域提议网络(RPN),从而减少了训练的负担。然而,尽管YOLOv4在许多方面都表现出色,但它仍然存在一些不足。例如,小目标检测效果较差。此外,当需要在资源受限的设备上部署像YOLOv4这样的大模型时,模型压缩是研究人员重新调整较大模型所需资源消耗的有用工具。
优点:
速度:YOLOv4 保持了 YOLO 算法一贯的实时性,能够在检测速度和精度之间实现良好的平衡。
精度:YOLOv4 采用了 CSPDarknet 和 PANet 两种先进的技术,提高了检测精度,特别是在检测小型物体方面有显著提升。
通用性:YOLOv4 适用于多种任务,如行人检测、车辆检测、人脸检测等,具有较高的通用性。
模块化设计:YOLOv4 中的组件可以方便地更换和扩展,便于进一步优化和适应不同场景。
缺点:
内存占用:YOLOv4 模型参数较多,因此需要较大的内存来存储和运行模型,这对于部分硬件设备来说可能是一个限制因素。
训练成本:YOLOv4 模型需要大量的训练数据和计算资源才能达到理想的性能,这可能导致训练成本较高。
精确度与速度的权衡:虽然 YOLOv4 在速度和精度之间取得了较好的平衡,但在极端情况下,例如检测高速移动的物体或复杂背景下的物体时,性能可能会受到影响。
误检和漏检:由于 YOLOv4 采用单一网络对整个图像进行预测,可能会导致一些误检和漏检现象。
【YOLOv5】
YOLOv5是一种快速、准确的目标检测模型,由Glen Darby于2020年提出。相较于前两代模型,YOLOv5集成了众多的tricks达到了性能的SOTA:
技术原理:
YOLOv5同样采用单个神经网络模型来完成目标检测任务,但采用了新的神经网络架构,融合了领先的轻量级模型设计理念。YOLOv5使用较小的骨干网络和新的检测头设计,以实现更快的推断速度,并在不降低精度的前提下提高目标检测的准确性。
亮点:
YOLOv5在模型结构上进行了改进,引入了更先进的轻量级网络架构,因此在速度和精度上都有所提升。
YOLOv5支持更灵活的模型大小和预训练选项,可以根据任务需求选择不同大小的模型,同时提供丰富的数据增强扩展、模型集成等方法来提高检测精度。YOLOv5通过使用更简洁的代码实现,提高了模型的易用性和可扩展性。
训练数据配置文件如下:
# Dataset
path: ./dataset
train:- images/train
val:- images/test
test:- images/test# Classes
names:0: immature1: mature2: medium_mature实验截止目前,本文将YOLOv5系列五款不同参数量级的模型均进行了开发评测,接下来看下模型详情:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv5 object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/yolov5# Parameters
nc: 3 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov5n.yaml' will call yolov5.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]s: [0.33, 0.50, 1024]m: [0.67, 0.75, 1024]l: [1.00, 1.00, 1024]x: [1.33, 1.25, 1024]# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc]], # Detect(P3, P4, P5)]在实验训练开发阶段,所有的模型均保持完全相同的参数设置,等待漫长的训练完成后,来整体进行评测对比分析。
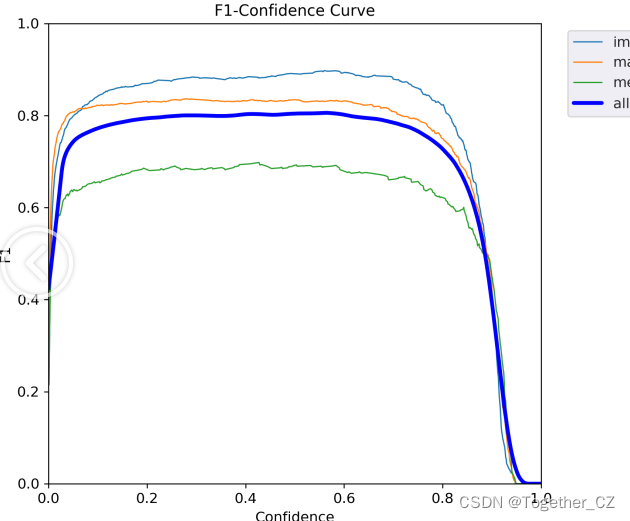
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能.F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。

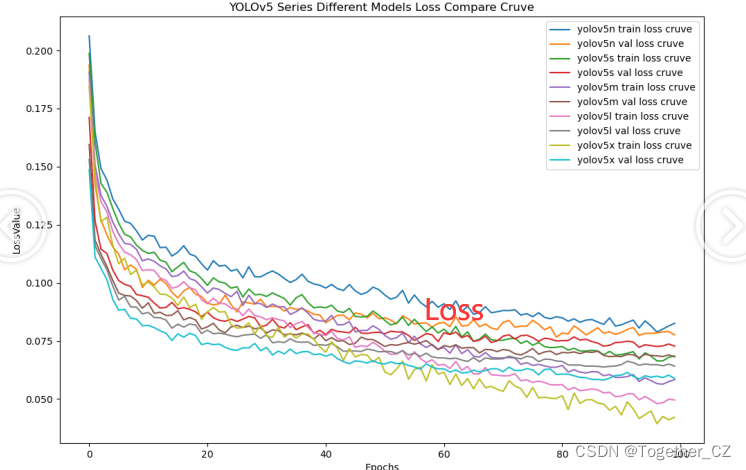
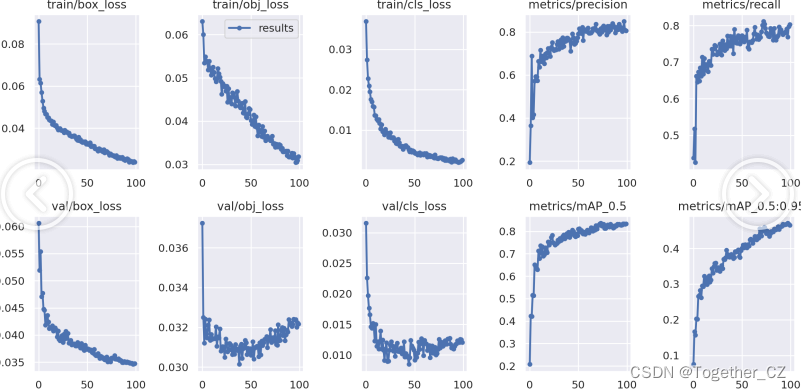
【loss曲线】
在深度学习的训练过程中,loss函数用于衡量模型预测结果与实际标签之间的差异。loss曲线则是通过记录每个epoch(或者迭代步数)的loss值,并将其以图形化的方式展现出来,以便我们更好地理解和分析模型的训练过程。
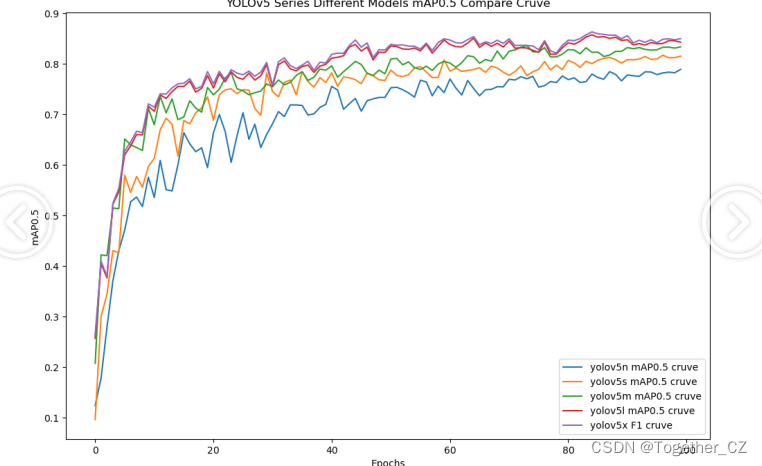
【mAP0.5】
mAP0.5,也被称为mAP@0.5或AP50,指的是当Intersection over Union(IoU)阈值为0.5时的平均精度(mean Average Precision)。IoU是一个用于衡量预测边界框与真实边界框之间重叠程度的指标,其值范围在0到1之间。当IoU值为0.5时,意味着预测框与真实框至少有50%的重叠部分。
在计算mAP0.5时,首先会为每个类别计算所有图片的AP(Average Precision),然后将所有类别的AP值求平均,得到mAP0.5。AP是Precision-Recall Curve曲线下面的面积,这个面积越大,说明AP的值越大,类别的检测精度就越高。
mAP0.5主要关注模型在IoU阈值为0.5时的性能,当mAP0.5的值很高时,说明算法能够准确检测到物体的位置,并且将其与真实标注框的IoU值超过了阈值0.5。
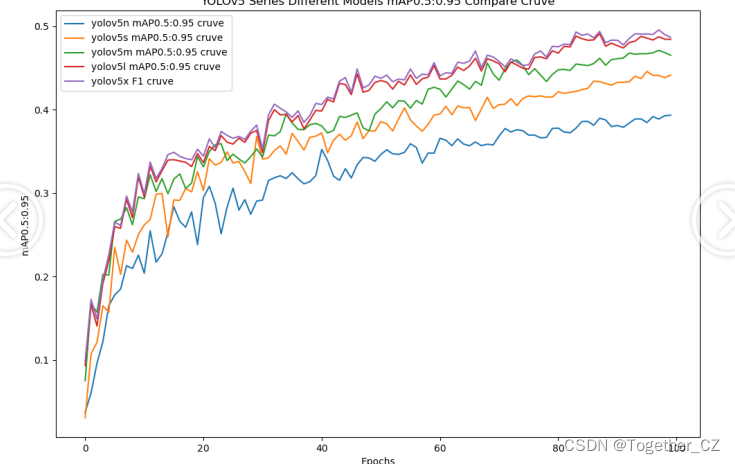
【mAP0.5:0.95】
mAP0.5:0.95,也被称为mAP@[0.5:0.95]或AP@[0.5:0.95],表示在IoU阈值从0.5到0.95变化时,取各个阈值对应的mAP的平均值。具体来说,它会在IoU阈值从0.5开始,以0.05为步长,逐步增加到0.95,并在每个阈值下计算mAP,然后将这些mAP值求平均。
这个指标考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。当mAP0.5:0.95的值很高时,说明算法在不同阈值下的检测结果均非常准确,覆盖面广,可以适应不同的场景和应用需求。
对于一些需求比较高的场合,比如安全监控等领域,需要保证高的准确率和召回率,这时mAP0.5:0.95可能更适合作为模型的评价标准。
综上所述,mAP0.5和mAP0.5:0.95都是用于评估目标检测模型性能的重要指标,但它们的关注点有所不同。mAP0.5主要关注模型在IoU阈值为0.5时的性能,而mAP0.5:0.95则考虑了多个IoU阈值下的平均精度,从而更全面、更准确地评估模型性能。
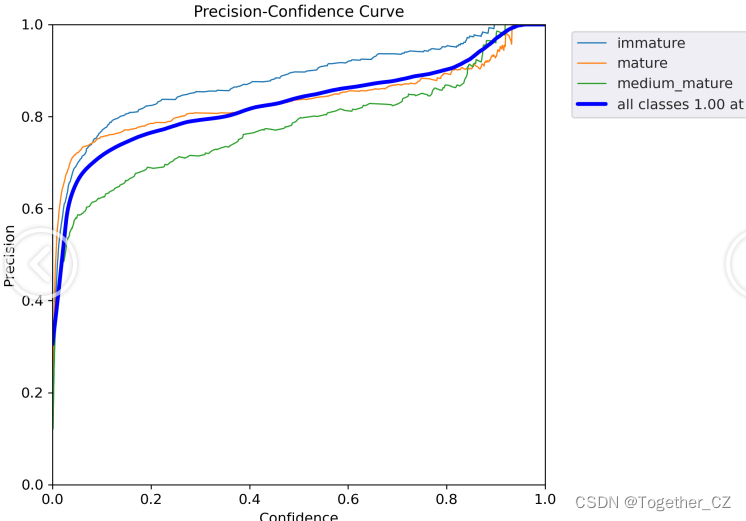
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。

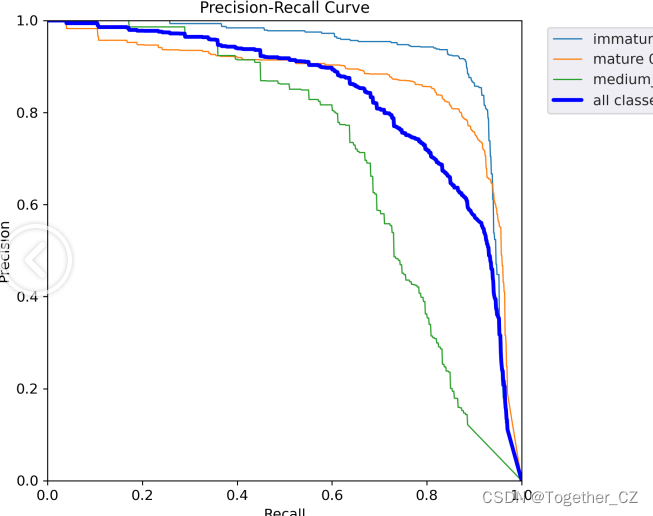
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
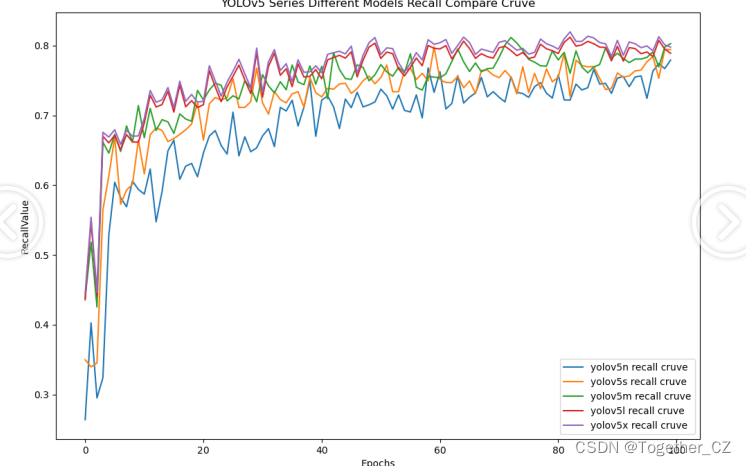
整体5款模型对比结果来看,几款不同参数量级的模型最终实现的效果相对来说更加层次分明一些,n系列的模型效果最差,s系列的模型效果次之,但是和m系列的模型较为相近,l和x系列的模型达到了十分相近的效果,这里我们综合考虑使用m系列的模型作为最终的推理模型。
接下来看下m系列模型的详情。
【离线推理实例】

【Batch实例】


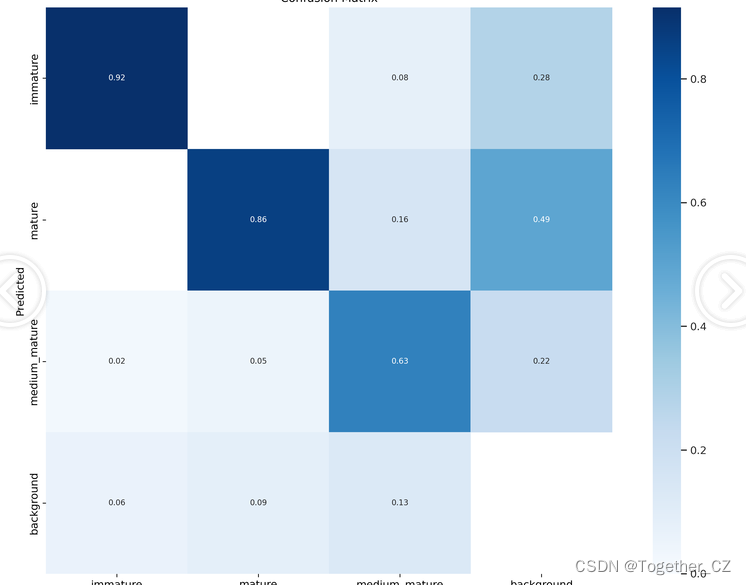
【混淆矩阵】
【F1值曲线】
【Precision曲线】
【Recall曲线】

【PR曲线】
【训练可视化】
整体实践做下来,yolov5整体的表现则更为出色,我们构建的数据集本身比较偏实验性质真正落地的场景会更加复杂化多样化。
要实现樱桃采摘的完全智能机械化还面临着一些挑战。例如,如何确保摄像头在各种天气条件下都能准确识别果实?如何保证机械臂在复杂环境中的稳定性和灵活性?这些问题都需要我们进一步研究和探索。随着技术的不断进步和创新,我们有理由相信这些挑战都将被克服。在不远的将来,我们或许能够看到这样的场景:在广袤的樱桃园中,智能采摘机器人在忙碌地工作着,它们通过AI技术精准地识别出成熟的果实并将其采摘下来。这样的场景不仅将极大地提高农业生产的效率和质量,也将为农民带来更多的收益和幸福。
本文也仅作为抛砖引玉,智能机械化是农业生产未来的发展方向。通过结合机械设计和AI技术,我们可以实现樱桃等水果的智能化采摘和分拣工作,推动农业生产向数字化、智能化迈进。让我们共同期待这一天的到来!
这篇关于助力樱桃智能自动化采摘,基于YOLOv5全系列【n/s/m/l/x】参数模型开发构建果园种植采摘场景下樱桃成熟度智能检测识别系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





