本文主要是介绍DriveWorld:一个预训练模型大幅提升检测+地图+跟踪+运动预测+Occ多个任务性能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 写在前面
以视觉为中心的自动驾驶技术近期因其较低的成本而引起了广泛关注,而预训练对于提取通用表示至关重要。然而,当前的以视觉为中心的预训练通常依赖于2D或3D预训练任务,忽视了自动驾驶作为4D场景理解任务的时序特征。这里通过引入一个基于世界模型的自动驾驶4D表示学习框架“DriveWorld”来解决这一挑战,该框架能够从多摄像头驾驶视频中以时空方式进行预训练。具体来说,提出了一个用于时空建模的记忆状态空间模型,它由一个动态记忆库模块组成,用于学习时间感知的潜在动态以预测未来变化,以及一个静态场景传播模块,用于学习空间感知的潜在静态以提供全面的场景上下文。此外,还引入了一个任务提示,以解耦用于各种下游任务的任务感知特征。实验表明,DriveWorld在各种自动驾驶任务上取得了令人鼓舞的结果。当使用OpenScene数据集进行预训练时,DriveWorld在3D检测中实现了7.5%的mAP提升,在线地图中的IoU提升了3.0%,多目标跟踪中的AMOTA提升了5.0%,运动预测中的minADE降低了0.1m,占用预测中的IoU提升了3.0%,规划中的平均L2误差减少了0.34m。
2. 领域背景
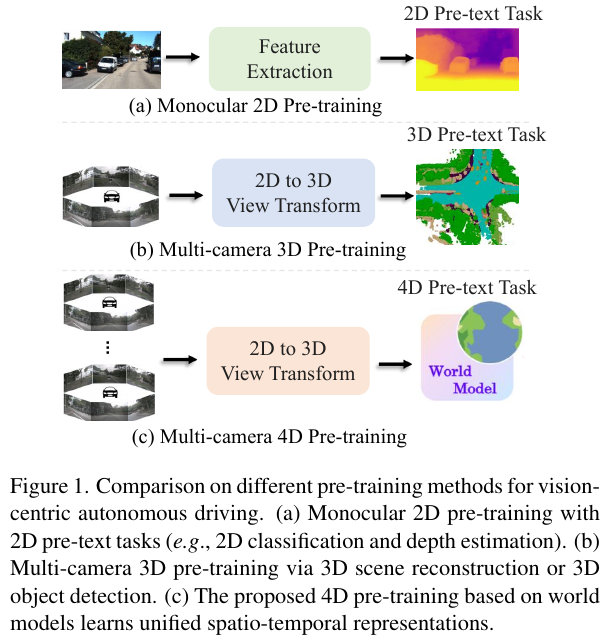
自动驾驶是一项复杂的任务,它依赖于全面的4D场景理解。这要求获得一个稳健的时空表示,能够处理涉及感知、预测和规划的任务。由于自然场景的随机性、环境的部分可观察性以及下游任务的多样性,学习时空表示极具挑战性。预训练在从大量数据中获取通用表示方面起着关键作用,使得能够构建出包含共同知识的基础模型。然而,自动驾驶中时空表示学习的预训练研究仍然相对有限。
我们的目标是利用世界模型来处理以视觉为中心的自动驾驶预训练中的4D表示。世界模型在表示代理对其环境的时空知识方面表现出色。在强化学习中,DreamerV1、DreamerV2和DreamerV3利用世界模型将代理的经验封装在预测模型中,从而促进了广泛行为的习得。MILE利用3D几何作为归纳偏差,直接从专家演示的视频中学习紧凑的潜在空间,以在CARLA模拟器中构建世界模型。ContextWM和SWIM利用丰富的野外视频对世界模型进行预训练,以增强下游视觉任务的高效学习。最近,GAIA-1和DriveDreamer构建了生成性的世界模型,利用视频、文本和动作输入,使用扩散模型创建逼真的驾驶场景。与上述关于世界模型的先前工作不同,本文的方法主要侧重于利用世界模型学习自动驾驶预训练中的4D表示。
驾驶本质上涉及与不确定性的斗争。在模糊的自动驾驶场景中,存在两种类型的不确定性:偶然不确定性,源于世界的随机性;以及认知不确定性,源于不完美的知识或信息。如何利用过去的经验来预测可能的未来状态,并估计自动驾驶中缺失的世界状态信息仍然是一个未解决的问题。本文探索了通过世界模型进行4D预训练以处理偶然不确定性和认知不确定性。具体来说,设计了记忆状态空间模型,从两个方面减少自动驾驶中的不确定性。首先,为了处理偶然不确定性,我们提出了动态记忆库模块,用于学习时间感知的潜在动态以预测未来状态。其次,为了缓解认知不确定性,我们提出了静态场景传播模块,用于学习空间感知的潜在静态特征,以提供全面的场景上下文。此外,引入了任务提示(Task Prompt),它利用语义线索作为提示,以自适应地调整特征提取网络,以适应不同的下游驾驶任务。
为了验证提出的4D预训练方法的性能,在nuScenes训练集和最近发布的大规模3D占用率数据集OpenScene上进行了预训练,随后在nuScenes训练集上进行了微调。实验结果表明,与2D ImageNet预训练、3D占用率预训练和知识蒸馏算法相比,4D预训练方法具有显著优势。4D预训练算法在以视觉为中心的自动驾驶任务中表现出极大的改进,包括3D检测、多目标跟踪、在线建图、运动预测、占用率预测和规划。
3. 网络结构
DriveWorld的总体框架如下所示,由于自动驾驶严重依赖于对4D场景的理解,方法首先涉及将多摄像头图像转换为4D空间。在所提出的时空建模的记忆状态空间模型中,有两个基本组件:动态记忆库,它学习时间感知的潜在动态以预测未来状态;以及静态场景传播,它学习空间感知的潜在静态特征以提供全面的场景上下文。这种配置有助于解码器为当前和未来时间步重建3D占用和动作的任务。此外,基于预训练的文本编码器设计了任务prompt,以自适应地为各种任务解耦任务感知特征。

提出的记忆状态空间模型(MSSM)的总体架构。MSSM将传输的信息分为两类:时间感知信息和空间感知信息。动态记忆库模块利用运动感知层归一化(MLN)来编码时间感知属性,并与动态更新的记忆库进行信息交互。同时,静态场景传播模块使用BEV特征来表示空间感知的潜在静态信息,这些信息直接被传送到解码器。

虽然通过世界模型设计的预训练任务使得时空表示的学习成为可能,但不同的下游任务侧重于不同的信息。例如,3D检测任务强调当前的空间感知信息,而未来预测任务则优先考虑时间感知信息。过分关注未来的信息,如车辆未来的位置,可能会对3D检测任务产生不利影响。为了缓解这个问题,受到少样本图像识别中语义提示和多任务学习中视觉示例驱动的提示的启发,引入了“任务提示”的概念,为不同的头提供特定的线索,以指导它们提取任务感知特征。认识到不同任务之间存在的语义联系,利用大型语言模型来构建这些任务提示。
4. 损失函数
DriveWorld的预训练目标涉及最小化后验和先验状态分布之间的差异(即Kullback-Leibler(KL)散度),以及最小化与过去和未来3D占用,即CrossEntropy损失(CE)和L1损失。这里描述了模型在T个时间步上观察输入,然后预测未来L步的3D占用和动作。DriveWorld的总损失函数是:

5. 实验对比分析
数据集。在自动驾驶数据集nuScenes 和最大规模的3D占用数据集OpenScene 上进行预训练,并在nuScenes上进行微调。评估设置与UniAD 相同。
预训练。与BEVFormer 和UniAD 一致,使用ResNet101-DCN 作为基础骨干网络。对于3D占用预测,设置了16 × 200 × 200的体素大小。学习率设置为2×10−4。默认情况下,预训练阶段包含24个epoch。
微调。在微调阶段,保留用于生成BEV特征的预训练编码器,并对下游任务进行微调。对于3D检测任务,我们使用了BEVFormer 框架,微调其参数而不冻结编码器,并进行了24个epoch的训练。对于其他自动驾驶任务,我们使用了UniAD 框架,并将我们微调后的BEVFormer权重加载到UniAD中,对所有任务遵循标准的20个epoch的训练协议。对于UniAD,我们遵循其实验设置,这包括在第一阶段训练6个epoch,在第二阶段训练20个epoch。实验使用8个NVIDIA Tesla A100 GPU进行。

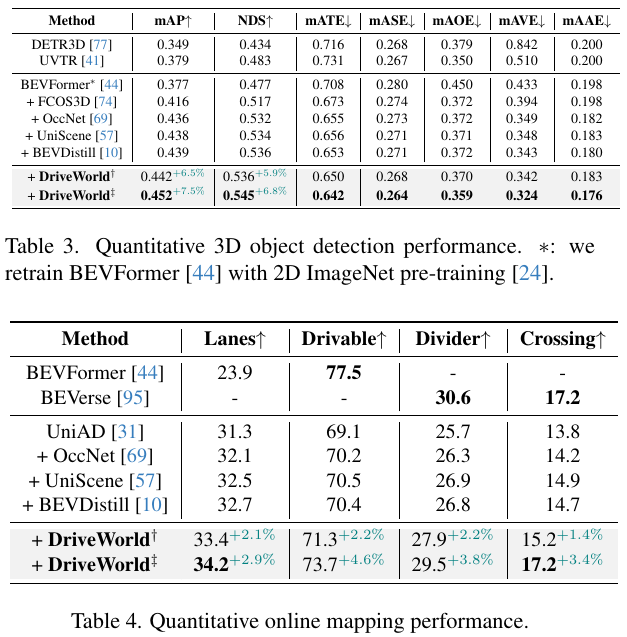
Occ任务和BEV-OD任务上的提升一览:
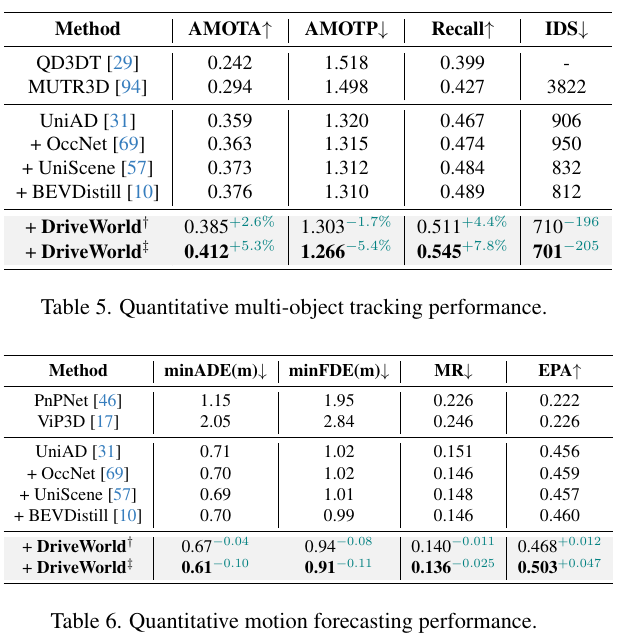
更多目标跟踪和规划任务性能提升一览:

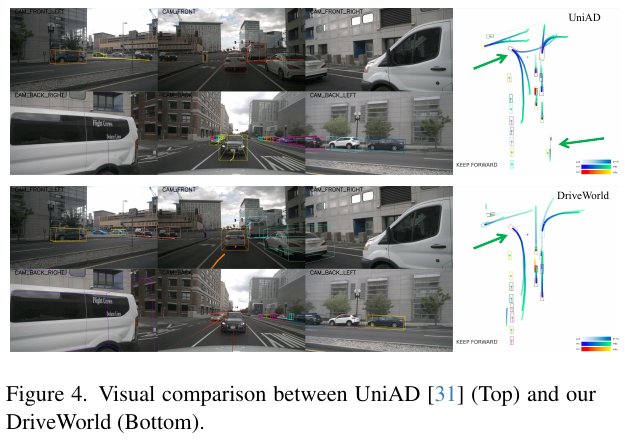
参考文献
DriveWorld:一个预训练模型大幅提升检测+地图+跟踪+运动预测+Occ多个任务性能
DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving
这篇关于DriveWorld:一个预训练模型大幅提升检测+地图+跟踪+运动预测+Occ多个任务性能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





