本文主要是介绍基于安卓的虫害识别软件设计--(2)模型性能可视化|混淆矩阵、热力图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.混淆矩阵(Confusion Matrix)
1.1基础理论
(1)在机器学习、深度学习领域中,混淆矩阵常用于监督学习,匹配矩阵常用于无监督学习。主要用来比较分类结果和实际预测值。
(2)图中表达的含义:混淆矩阵的每一列代表了预测类别,每一行代表了数据的真实类别。
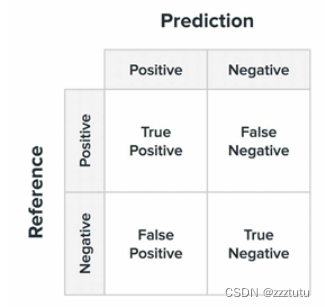
1.2 实现代码
import torch
import os
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import seaborn as sns
from torchvision import transformsclasses = ['bai_xing_hua_jin_gui', 'beetle', 'chui_mian_jie', 'ci_e_ke', 'da_qing_ye_chan','dou_yuan_jing','fan_qie_qian_ye_ying_larva','fan_qie_qian_ye_ying_mature','hong_zhi_zhu','huang_zong_ke']# classes = ['白星化金龟', '甲虫', '吹绵蚧', '刺蛾科', '大青叶蝉','豆芫菁','番茄潜叶蛾幼虫','番茄潜叶蛾成虫','红蜘蛛','蝗总科']def predict_image(model, image_path, true_label):device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")img = Image.open(image_path)val_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])tensor_img = val_transform(img)tensor_img = tensor_img.to(device)tensor_img = tensor_img.unsqueeze(0)output = model(tensor_img)_, pred = output.max(1)pred_label = classes[pred.item()]return pred_label, true_labelif __name__ == '__main__':# 1. 加载模型model_path = r"/kaggle/input/mymodel3/resnet101_final.pth"model = torch.load(model_path)model.eval()# 2. 预测多张图片并记录真实标签和预测结果true_labels = []pred_labels = []images_dir = r"/kaggle/input/insects-new/validation"for label in os.listdir(images_dir):label_dir = os.path.join(images_dir, label)if not os.path.isdir(label_dir):continuefor img_name in os.listdir(label_dir):img_path = os.path.join(label_dir, img_name)true_labels.append(label)pred_label, _ = predict_image(model, img_path, label)pred_labels.append(pred_label)# 3. 计算混淆矩阵cm = confusion_matrix(true_labels, pred_labels, labels=classes)# 4. 计算归一化的混淆矩阵cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]# 5. 绘制混淆矩阵save_path = "/kaggle/working/confusion_matrix.png"plt.figure(figsize=(8, 6))sns.heatmap(cm_normalized, annot=True, cmap='Blues', xticklabels=classes, yticklabels=classes, fmt='.2f')plt.xlabel('预测标签')plt.ylabel('真实标签')plt.tight_layout() # 自动调整子图参数plt.savefig(save_path)plt.show()
注意:以下数值需要和训练时的数值一样!


2.热力图
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import torch
from torchcam.methods import GradCAMpp
# CAM GradCAM GradCAMpp ISCAM LayerCAM SSCAM ScoreCAM SmoothGradCAMpp XGradCAM
from torchvision import transforms
from torchcam.utils import overlay_mask# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)model = torch.load('/kaggle/input/mymodel3/resnet101_final.pth')
model = model.eval().to(device)cam_extractor = GradCAMpp(model)# 要与训练集保持一致
test_transform = transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomGrayscale(),transforms.ToTensor(),transforms.RandomErasing(),transforms.Normalize([0.460, 0.483, 0.396], [0.171, 0.150, 0.190])])# 载入目标图像
img_path = '/kaggle/input/insects-new/train/hong_zhi_zhu/13845.jpg'
img_pil = Image.open(img_path)
input_tensor = test_transform(img_pil).unsqueeze(0).to(device) # 预处理
# 预测标签
pred_logits = model(input_tensor)
pred_id = torch.topk(pred_logits, 1)[1].detach().cpu().numpy().squeeze().item()activation_map = cam_extractor(pred_id, pred_logits)
activation_map = activation_map[0][0].detach().cpu().numpy()
# 矩阵热力图
plt.imshow(activation_map)
plt.show()
plt.savefig('/kaggle/working/activation_map.png')# 将原图重合
result = overlay_mask(img_pil, Image.fromarray(activation_map), alpha=0.7)
result.save('/kaggle/working/result.png')result
这篇关于基于安卓的虫害识别软件设计--(2)模型性能可视化|混淆矩阵、热力图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





