本文主要是介绍M2m中的采样,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
采样的完整代码
import torch
import numpy as np
from torchvision import datasets, transforms
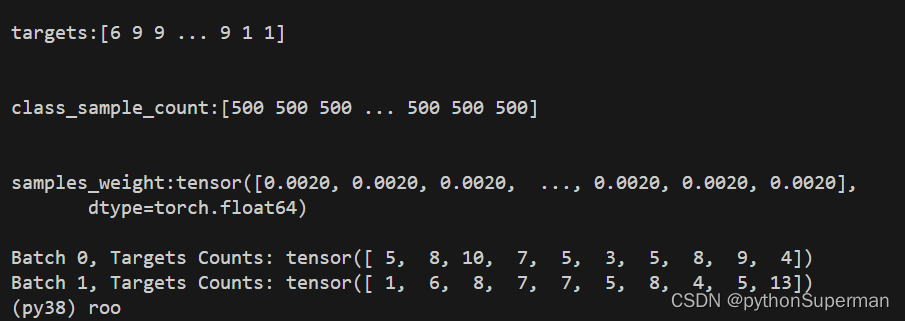
from torch.utils.data import DataLoader, WeightedRandomSampler, SubsetRandomSamplerdef get_oversampled_data(dataset, num_sample_per_class):""" Generate a list of indices that represents oversampling of the dataset. """targets = np.array(dataset.targets)class_sample_count = np.array([num_sample_per_class[target] for target in targets])weight = 1. / class_sample_countsamples_weight = torch.from_numpy(weight)sampler = WeightedRandomSampler(samples_weight, len(samples_weight))return samplerdef get_val_test_data(dataset, num_test_samples):""" Split dataset into validation and test indices. """num_classes = 10targets = dataset.targetstest_indices = []val_indices = []for i in range(num_classes):indices = [j for j, x in enumerate(targets) if x == i]np.random.shuffle(indices)val_indices.extend(indices[:num_test_samples])test_indices.extend(indices[num_test_samples:num_test_samples*2])return val_indices, test_indicesdef get_oversampled(dataset_name, num_sample_per_class, batch_size, transform_train, transform_test):""" Create training and testing loaders with oversampling for imbalance. """dataset_class = datasets.__dict__[dataset_presets[dataset_name]['class']]dataset_train = dataset_class(root='./data', train=True, download=True, transform=transform_train)dataset_test = dataset_class(root='./data', train=False, download=True, transform=transform_test)# Oversamplingsampler = get_oversampled_data(dataset_train, num_sample_per_class)train_loader = DataLoader(dataset_train, batch_size=batch_size, sampler=sampler)# Validation and Test splitval_idx, test_idx = get_val_test_data(dataset_test, 1000)val_loader = DataLoader(dataset_test, batch_size=batch_size, sampler=SubsetRandomSampler(val_idx))test_loader = DataLoader(dataset_test, batch_size=batch_size, sampler=SubsetRandomSampler(test_idx))return train_loader, val_loader, test_loader# Configuration and run
dataset_presets = {'cifar10': {'class': 'CIFAR10', 'num_classes': 10}
}
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])
num_sample_per_class = [500] * 10 # Pretend we want equal class distributiontrain_loader, val_loader, test_loader = get_oversampled('cifar10', num_sample_per_class, 64, transform, transform)# Print out some info from loaders
for i, (inputs, targets) in enumerate(train_loader):print(f'Batch {i}, Targets Counts: {torch.bincount(targets)}')if i == 1: # Just show first two batches for demonstrationbreak
WeightedRandomSampler类的__iter__
def __iter__(self) -> Iterator[int]:rand_tensor = torch.multinomial(self.weights, self.num_samples, self.replacement, generator=self.generator)return iter(rand_tensor.tolist())
- 方法功能:此方法实现了迭代器协议,允许
WeightedRandomSampler对象在迭代中返回一系列随机选择的索引。
过采样的效果
在get_oversampled函数中,使用了WeightedRandomSampler来实现过采样的逻辑。这个过程虽然看起来是通过权重调整样本的选取概率,但实际上,通过这种方式也可以达到过采样的效果,尤其是当设置replacement=True时。让我们更详细地分析一下这一点:
权重的分配
权重是根据num_sample_per_class数组分配的,这个数组定义了每个类别希望被采样到的频率。在数据加载过程中,每个类别的样本将根据其在num_sample_per_class中对应的值获得一个权重。权重越大的类别在每次迭代中
被选中的概率也越大。这样,通过调整这些权重,我们可以控制模型在训练过程中看到的每个类别样本的频率,实现对类别不平衡的处理。
过采样的实现
在使用WeightedRandomSampler时,关键的参数是replacement:
-
如果
replacement=True:这允许同一个样本在一次抽样中被多次选择,即进行了过采样。对于少数类的样本来说,即使它们在数据集中的绝对数量不多,也可以通过这种方式增加它们在每个训练批次中出现的次数,从而让模型更频繁地从这些少数类样本学习。 -
如果
replacement=False:则每个样本只能被抽样一次,这通常用于不放回的抽样。在这种模式下,WeightedRandomSampler不会直接导致过采样,但可以用来确保每个类别在数据批次中都有均等的代表性,从而帮助模型学习到更平衡的特征。
这篇关于M2m中的采样的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!