本文主要是介绍语音深度鉴伪识别项目实战:基于深度学习的语音深度鉴伪识别算法模型(一)音频数据编码与预处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
深度学习技术在当今技术市场上面尚有余力和开发空间的,主流落地领域主要有:视觉,听觉,AIGC这三大板块。目前视觉板块的框架和主流技术在我上一篇基于Yolov7-LPRNet的动态车牌目标识别算法模型已有较为详细的解说。与AIGC相关联的,其实语音模块在近来市场上面活跃空间很大。从智能手机的语音助手到智能家居中的语音控制系统,再到银行和电信行业的语音身份验证,语音技术的应用日益广泛。那么对应现在ACG技术是可以利用原音频去进行训练学习,从而得到相对应的声音特征,从而进行模仿,甚至可以利用人工智能生成的语音可以以假乱真,给社会带来了严重的安全隐患。
当前,语音深度鉴伪识别技术已经取得了一定的进展。研究人员利用机器学习和深度学习方法,通过分析语音信号的特征,开发出了一系列鉴伪算法。然而,随着生成大模型和其他语音合成技术的不断进步,伪造语音的逼真度也在不断提高,使得语音鉴伪任务变得愈加复杂和具有挑战性。本项目系列文章将从最基础的语音数据存储和详细分析开始,由于本系列专栏是有详细解说过深度学习和机器学习内容的,音频数据处理和现主流技术语音分类模型和编码模型将会是本项目系列文章的主体内容,具体本项目系列要讲述的内容可参考下图:
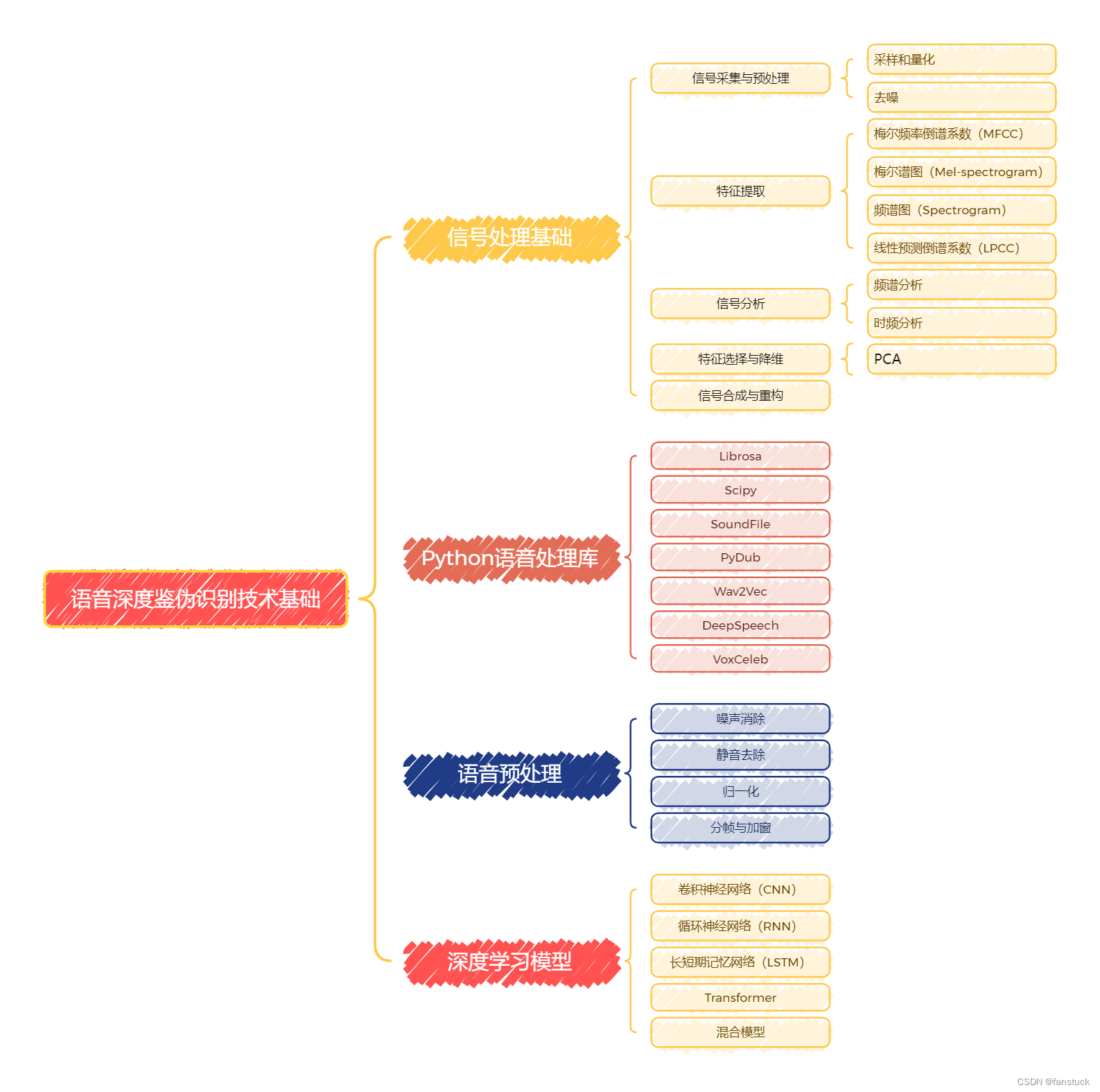
语音模型的内容不是那么好掌握的,包含大量的数学理论知识以及大量的计算公式原理需要推理。且如果不进行实际操作很难够理解我们写的代码究极在神经网络计算框架中代表什么作用。不过我会尽可能将知识简化,转换为我们比较熟悉的内容,我将尽力让大家了解并熟悉神经网络框架,保证能够理解通畅以及推演顺利的条件之下,尽量不使用过多的数学公式和专业理论知识。以一篇文章快速了解并实现该算法,以效率最高的方式熟练这些知识。希望有需求的小伙伴不要错过笔者精心打造的专栏。
那么本系列文章第一节我们将解答音频常见存储载体和其特征,以及音频的数据保存形态有哪些?具体数据可视化展示为何种形式?也就是我们第一部要了解声音是如何转换为数据的,是如何编码保存的。
一、音频数据编码
音频数据的编码和解码是将声音信号转换为数字信号以及将数字信号还原为声音信号的过程。不同的音频文件格式采用不同的编码方式来保存音频数据。音频数据的编码方式主要有两类:未压缩编码和压缩编码。未压缩编码保留了原始音频数据,而压缩编码则通过各种算法减少音频数据的大小,可以是有损压缩或无损压缩。
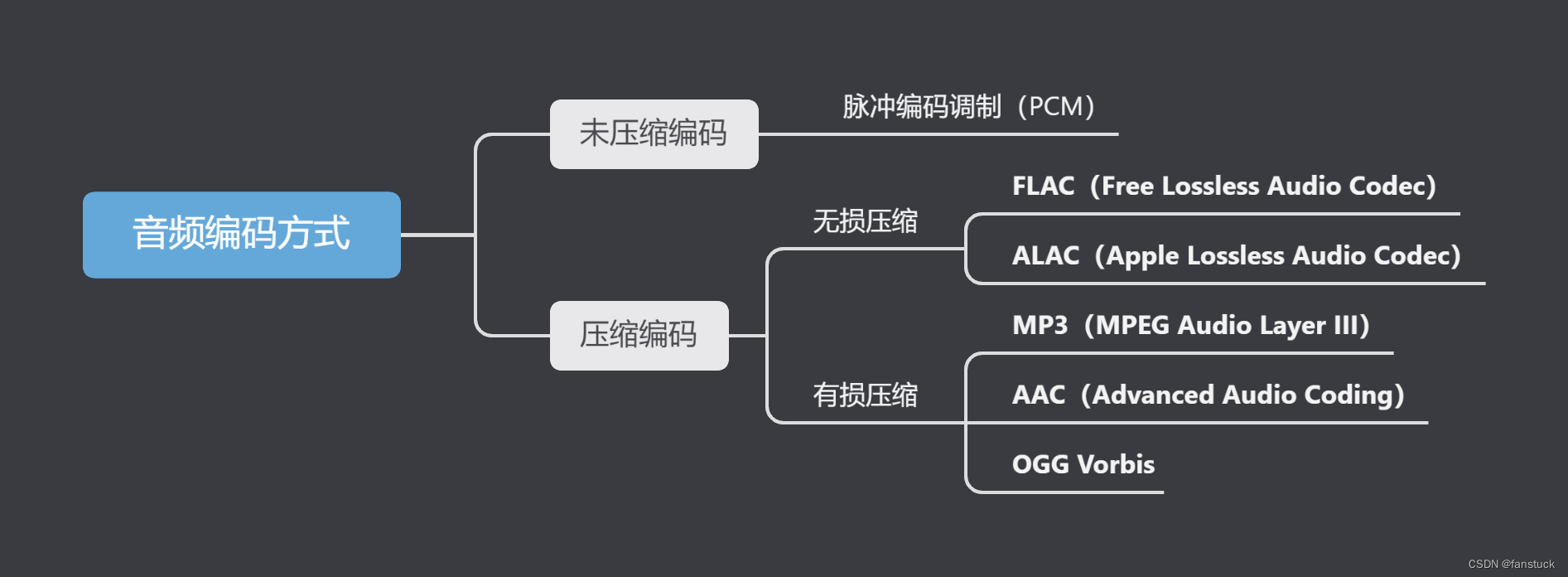
1.1未压缩编码
未压缩编码保存音频数据的原始信息,主要采用脉冲编码调制(PCM)方式。
1.1.1 脉冲编码调制(PCM)
PCM是最常见的未压缩音频编码方式。它直接对模拟信号进行采样、量化和编码,将声音波形转换为数字信号。总共有三步:
- 采样:以固定的时间间隔对模拟信号进行采样,得到离散的时间点。
- 将连续的模拟音频信号在时间上以固定的间隔进行采样,得到离散的时间点。采样频率(如44.1kHz)决定了每秒钟采样的次数。高采样率能够更准确地表示原始信号,但也会产生更多的数据。
- 量化:将每个采样点的幅值转换为最接近的离散值,通常使用16位或24位表示。
- 量化位数(如16位、24位)决定了每个采样点的精度,量化的过程会引入量化误差,位数越高,误差越小,音质越好。
- 编码:将量化后的值编码为二进制数,形成数字信号。
- 通常使用整型数表示量化后的幅值。
我们可以使用Python编码实现PCM编码:
import wave
import numpy as np# 生成一个1秒的1kHz正弦波
sample_rate = 44100 # 采样率:44.1kHz,CD质量
frequency = 1000 # 频率:1kHz
duration = 1.0 # 持续时间:1秒
t = np.linspace(0, duration, int(sample_rate * duration), endpoint=False) # 时间点
signal = 0.5 * np.sin(2 * np.pi * frequency * t) # 正弦波,幅值为0.5# 量化为16位PCM
signal_int16 = np.int16(signal * 32767) # 将幅值转换为16位整型数# 保存为WAV文件
with wave.open('sine_wave.wav', 'w') as wav_file:wav_file.setnchannels(1) # 单声道wav_file.setsampwidth(2) # 采样位宽:16位(2字节)wav_file.setframerate(sample_rate) # 采样率:44.1kHzwav_file.writeframes(signal_int16.tobytes()) # 写入音频数据
上述在音频处理和编码过程中这些采样率、频率、采样位宽等特征,我们在此作一个详细的介绍方便大家了解:
采样率(Sample Rate)
采样率是指每秒钟对连续的模拟音频信号进行采样的次数,单位是赫兹(Hz)。
- 常见值
- 8000 Hz:电话音频质量
- 16000 Hz:宽带电话
- 22050 Hz:广播质量
- 44100 Hz:CD音质
- 48000 Hz:专业音频和视频
- 96000 Hz:高分辨率音频
采样率决定了音频信号的频率范围和保真度。较高的采样率可以更精确地表示高频成分,提供更好的音质。根据奈奎斯特定理,采样率必须至少是音频信号最高频率的两倍,以避免混叠(aliasing)现象。
频率(Frequency)
频率是指音频信号中波形的振动次数,通常以赫兹(Hz)为单位。频率决定了声音的音调。较高的频率对应较高的音调,较低的频率对应较低的音调。人耳能够听到的频率范围通常在20 Hz到20 kHz之间。
持续时间(Duration)
持续时间是指音频信号的总时长,通常以秒(s)为单位。持续时间决定了音频文件的长度。较长的持续时间会产生更大的数据量。
单声道和立体声(Channels)
单声道(Mono):单声道音频只有一个声道,所有的声音都来自一个方向,音频文件较小,常用于电话通信和某些广播应用。
立体声(Stereo):立体声音频有两个声道,通常分别对应左声道和右声道。能够产生空间感和方向感,提供更逼真的音频体验,音频文件较大,常用于音乐和电影。
采样位宽(Bits Per Sample)
采样位宽是指每个采样点使用的位数,通常为8位、16位或24位。
- 8位:256个可能的振幅级别
- 16位:65536个可能的振幅级别(CD质量)
- 24位:16777216个可能的振幅级别(高分辨率音频)
采样位宽决定了每个采样点的精度和动态范围。较高的采样位宽能够更精确地表示音频信号,减少量化误差,提供更好的音质。
时间点(Time Points)
时间点是指在特定时间间隔内对连续的模拟音频信号进行采样的位置。通过采样,我们将连续的时间信号转换为离散的时间信号。在固定的时间间隔对模拟信号进行采样,得到一系列离散的时间点。这些时间点决定了音频信号的采样率。时间点形成了音频信号的时间轴,每个时间点对应一个采样值。
import numpy as npsample_rate = 44100 # 采样率:44.1kHz
duration = 1.0 # 持续时间:1秒# 生成时间点
t = np.linspace(0, duration, int(sample_rate * duration), endpoint=False)上面的代码中:
np.linspace(0, duration, int(sample_rate * duration), endpoint=False)生成从0到持续时间(1秒)的时间点,总数为sample_rate * duration(44100个点),不包括终点。
正弦波(Sine Wave)
正弦波是一种最基本的周期信号,其数学表达式为:
x(t)=Asin(2πft+ϕ) 其中:
- A 是振幅,决定了波的最大值和最小值。
- f 是频率,表示波每秒钟振荡的次数,单位是赫兹(Hz)。
- t 是时间点。
- ϕ 是初始相位。
正弦波是最简单的声音信号,用于模拟纯音(如音乐中的音符)。在音频处理中,正弦波可以用来生成纯音,用于测试和校准音频设备。通过组合不同频率和振幅的正弦波,可以合成出复杂的音频信号。
frequency = 1000 # 频率:1kHz
amplitude = 0.5 # 振幅:0.5# 生成正弦波
signal = amplitude * np.sin(2 * np.pi * frequency * t)在上面的代码中:
amplitude设置为0.5,表示正弦波的最大振幅为0.5。frequency设置为1000 Hz,表示正弦波的频率为1kHz。np.sin(2 * np.pi * frequency * t)生成对应时间点的正弦波值。
这些步骤和概念是音频信号生成、处理和存储的基础。通过理解这些特征,可以更好地掌握音频处理技术。
查看一个WAV文件的数据特征,可以通过读取文件的元数据和音频数据,了解其采样率、声道数、采样位宽、持续时间等信息。可以使用Python的wave库和librosa库来读取WAV文件,并查看其数据特征。
import wavedef print_wav_file_properties(file_path):with wave.open(file_path, 'rb') as wav_file:# 获取WAV文件的基本特征num_channels = wav_file.getnchannels()sample_width = wav_file.getsampwidth()sample_rate = wav_file.getframerate()num_frames = wav_file.getnframes()duration = num_frames / sample_rateprint(f"Number of Channels: {num_channels}")print(f"Sample Width (bytes): {sample_width}")print(f"Sample Rate (Hz): {sample_rate}")print(f"Number of Frames: {num_frames}")print(f"Duration (seconds): {duration:.2f}")# 示例:打印WAV文件的基本特征
file_path = 'sine_wave.wav'
print_wav_file_properties(file_path)输出示例
Number of Channels: 1
Sample Width (bytes): 2
Sample Rate (Hz): 44100
Number of Frames: 44100
Duration (seconds): 1.00
1.2压缩编码
压缩编码通过压缩算法减少音频数据的大小,可以是无损压缩或有损压缩。
1.2.1无损压缩
无损压缩保留了原始音频数据,解压缩后可以完全还原。常见格式有FLAC和ALAC。
1.2.1.1 FLAC(Free Lossless Audio Codec)
FLAC(Free Lossless Audio Codec)是一种无损压缩音频格式,它通过高效的压缩算法减少音频文件的大小,但在解码时可以完全还原原始音频数据。FLAC的编码和解码可以通过Python中的相关库来实现,常用的库有soundfile和pydub。下面我将用soundfile读取WAV文件并保存为FLAC文件:
import soundfile as sf# 读取WAV文件
data, samplerate = sf.read('sine_wave.wav')# 保存为FLAC文件
sf.write('sine_wave.flac', data, samplerate, format='FLAC')
# 读取FLAC文件
data, samplerate = sf.read('sine_wave.flac')print(f"Sample Rate: {samplerate}")
print(f"Number of Samples: {len(data)}")
print(f"Duration: {len(data) / samplerate:.2f} seconds")输出实例:
Sample Rate: 44100
Number of Samples: 44100
Duration: 1.00 seconds
1.2.1.2ALAC(Apple Lossless Audio Codec)
苹果公司开发的无损压缩格式,类似于FLAC。主要用于苹果设备和软件。这里不作展开,和上述FLAC一样。
1.2.2有损压缩
有损压缩通过去除人耳不敏感的音频信息来减少数据大小,不能完全还原原始音频。常见格式有MP3、AAC和OGG Vorbis。
1.2.1.1 MP3(MPEG Audio Layer III)
MP3通过心理声学模型、子带编码、离散余弦变换和哈夫曼编码等一系列复杂的算法,实现了高效的音频压缩。心理声学模型可以通过模拟人耳的听觉特性去除一些人耳不容易察觉的声音,从而减少数据量。比如有:
- 掩蔽效应:当两个频率接近的声音同时存在时,较强的声音会掩蔽较弱的声音,人耳对较弱声音的感知能力下降。
- 临界频带:人耳对不同频率的敏感度不同,MP3编码器将音频信号分为多个临界频带进行处理。
- 绝对听觉阈值:人耳对不同频率声音的最低听觉阈值,低于该阈值的声音可以被忽略。
MP3将音频信号分解为多个子带,每个子带使用不同的量化和编码策略。通过子带分离,每个子带使用不同的量化和编码策略,MP3编码器可以更有效地利用心理声学模型进行压缩,而且MP3使用离散余弦变换(DCT)将时域信号转换为频域信号,方便应用心理声学模型和量化。实现MP3编码可以使用Python中的pydub库和ffmpeg工具。pydub是一个简单易用的音频处理库,ffmpeg是一个强大的多媒体处理工具,可以处理多种音频格式,包括MP3。
from pydub import AudioSegment
from pydub.utils import which# 自动查找系统路径中的 ffmpeg
ffmpeg_path = which("ffmpeg")
if not ffmpeg_path:# 如果自动查找失败,手动指定路径(替换为实际路径)ffmpeg_path = r"D:\ffmpeg\bin\ffmpeg.exe"
AudioSegment.converter = ffmpeg_path# 检查 FFmpeg 路径是否设置正确
if AudioSegment.converter:print(f"Using FFmpeg from: {AudioSegment.converter}")
else:raise RuntimeError("FFmpeg not found. Please ensure FFmpeg is installed and added to system PATH.")# 读取 WAV 文件
audio = AudioSegment.from_wav('sine_wave.wav')# 保存为 MP3 文件
audio.export('sine_wave.mp3', format='mp3', bitrate='192k')print("WAV file has been successfully converted to MP3 format.")
MP3对转换后的频域信号进行非均匀量化,量化精度取决于心理声学模型的分析结果。量化后的数据通过哈夫曼编码进行压缩,以进一步减少数据量。
1.2.2.2AAC(Advanced Audio Coding)
AAC(Advanced Audio Coding)是一种高效的有损音频压缩格式,属于MPEG-4标准的一部分。AAC设计旨在比MP3提供更好的音质和更高的压缩效率,是许多现代音频应用的首选格式,包括流媒体、音乐存储和数字广播。AAC支持多达48个声道,这使其在多声道音频(如环绕声系统)中具有优势。而且支持多种采样率和比特率,能够适应不同的应用场景,从低比特率的语音编码到高比特率的高保真音频。
代码方式如上,需要修改的只有:
# 保存为 AAC 文件
audio.export('sine_wave.aac', format='aac', bitrate='192k')
就好。
本系列将从最基础的音频数据认知开始一直讲解到最终完成整个语音深度鉴别模型的落地使用,对此项目感兴趣的,对此领域感兴趣的不要错过,多谢大家的支持!
这篇关于语音深度鉴伪识别项目实战:基于深度学习的语音深度鉴伪识别算法模型(一)音频数据编码与预处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



