词频专题

【Python 走进NLP】NLP词频统计和处理停用词,可视化
# coding=utf-8import requestsimport sysreload(sys)sys.setdefaultencoding('utf-8')from lxml import etreeimport timetime1=time.time()import bs4import nltkfrom bs4 import BeautifulSoupfrom

【Python123题库】#用字典来统计词频 #英汉词典 #统计字母数量
禁止转载,原文:https://blog.csdn.net/qq_45801887/article/details/140081737 参考教程:B站视频讲解——https://space.bilibili.com/3546616042621301 有帮助麻烦点个赞 ~ ~ Python123题库 用字典来统计词频英汉词典统计字母数量 用字典来统计词频 类型:字典

【Python机器学习】NLP词频背后的含义——距离和相似度
我们可以使用相似度评分(和距离),根据两篇文档的表示向量间的相似度(或距离)来判断文档间有多相似。 我们可以使用相似度评分(和举例)来查看LSA主题模型与高维TF-IDF模型之间的一致性。在去掉了包含在高维词袋中的大量信息之后,LSI模型在保持这些距离方面十分出色。我们可以检查主题向量之间的距离,以及这个距离是否较好地表示文档主题之间的距离。我们想要检查意义相近的文档在新主题向量空间中彼此相近。

【Python机器学习】NLP词频背后的含义——隐性狄利克雷分布(LDiA)
目录 LDiA思想 基于LDiA主题模型的短消息语义分析 LDiA+LDA=垃圾消息过滤器 更公平的对比:32个LDiA主题 对于大多数主题建模、语义搜索或基于内容的推荐引擎来说,LSA应该是首选方法。它的数学机理直观、有效,它会产生一个线性变换,可以应用于新来的自然语言文本而不需要训练过程,并几乎不会损失精确率。但是,在某些情况下,LDiA可以给出稍好的结果。 LDiA和LS

【Python机器学习】NLP词频背后的含义——隐性语义分析
隐性语义分析基于最古老和最常用的降维技术——奇异值分解(SVD)。SVD将一个矩阵分解成3个方阵,其中一个是对角矩阵。 SVD的一个应用是求逆矩阵。一个矩阵可以分解成3个最简单的方阵,然后对这些方阵求转置后再把它们相乘,就得到了原始矩阵的逆矩阵。它为我们提供了一个对大型复杂矩阵求逆的捷径。SVD适用于桁架结构的应力和应变分析等机械工程问题,它对电气工程中的电路分析也很有用,它甚至在数据科学中被用
【python高级编程】python中的Counter对象统计词频
使用Counter对象进行词频统计 统计词频是非常常见的一个实际场景应用,假设我们要对文章进行词频统计,我们可以利用python中的字典+遍历的方法来统计,但是这样比较麻烦,我们可以使用collections模块中的Counter对象方便的进行词频统计。 from collections import Counterfrom random import randint# 统计字典词频dat

词频统计(Word Frequency Analysis)详解
词频统计(Word Frequency Analysis)是语言学和文本分析中的一个重要工具,用于统计文本中各个词汇的出现频率。以下是关于词频统计(PTA)的详细解释,结合参考文章中的相关信息进行归纳和总结: 一、定义与目的 词频统计是对语篇或语料库中某一语词或短语出现的频数进行统计的过程或结果。其目的是通过量化词汇在文本中的出现次数,分析文本的主题、关键词、趋势等信息,为文本分析、数据挖掘、
Hadoop词频统计(二)之本地模式运行
想要在windows上以本地模式运行hadoop就必须要在windows上配置好hadoop的本地运行环境。我们需要下载编译好的hadoop二进制包。 下载地址如下: 链接:http://pan.baidu.com/s/1skE4fQt 密码:or48 下载完成后配置windows环境变量: HADOOP_HOME=C:\Program Files (x86)\hadoop-2.6.0
python 学习 三国演义词频显示 DAY6
import jieba txt = open(r"C:\Users\lenovo\Desktop\threekingdoms.txt","r",encoding="utf-8").read() excludes = {"将军","却说","二人","不可","荆州","不能","如此"} words = jieba.lcut(txt) counts = {} for word in w
词频统计(一):C++使用Vector做词频统计
统计圣经中每个单词出现的次数。 #include <iostream>#include <vector>#include <fstream>#include <string>#include <string.h>#include <sstream>struct Record{std::string word;int freq;};class WordStatic{public:

上海Java工程师招聘要求词频分析
之前的文章 Python利用Scrapy爬取智联招聘和前程无忧的招聘数据中已经提到说要对爬取的数据进行分析,但是由于一直也没找到比较好的分析方式,今天就单纯的利用sql查询关键字和Xmind做了一个统计图,大家将就看下 以上每个词代表的就是在总数据中出现的次数,当然,由于这个数据是10月份且数据是由智联和前程无忧合并的,并没有删去重复数据,所以数据中会存在一些重复信息,不
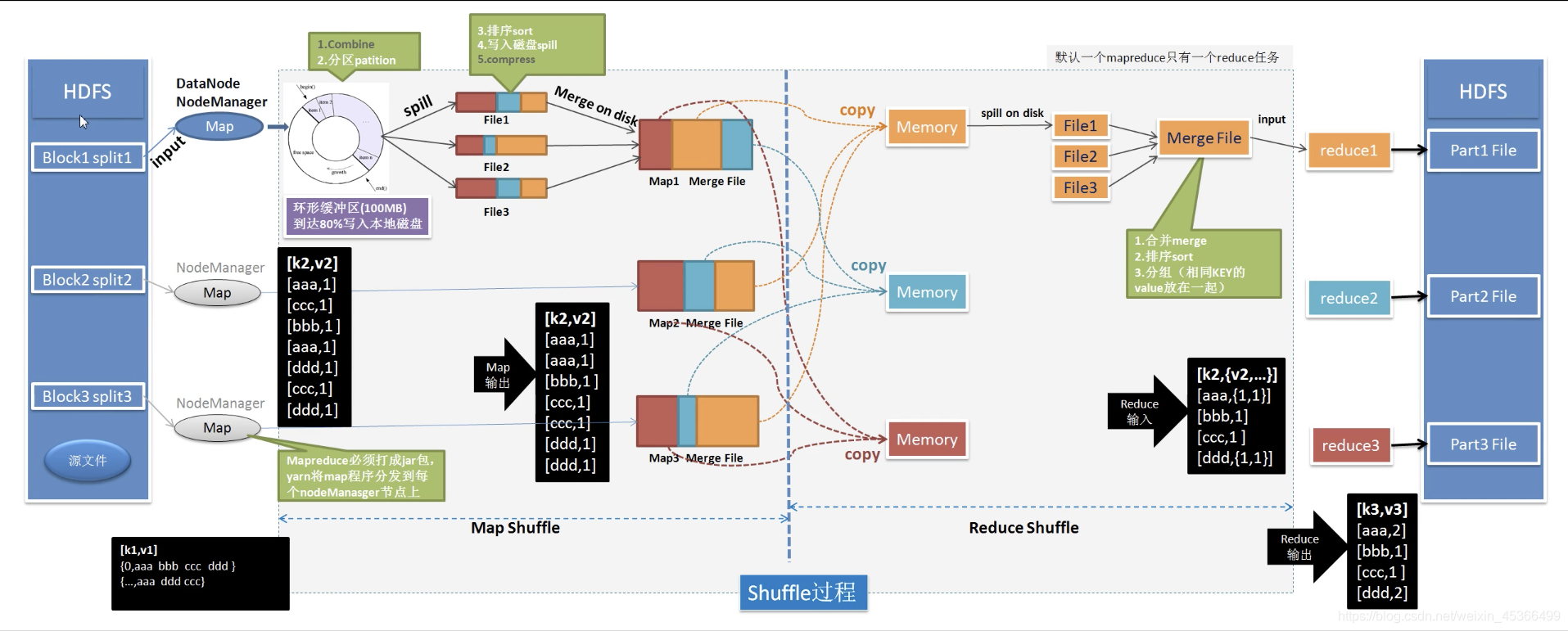
【大数据·Hadoop】从词频统计由浅入深介绍MapReduce分布式计算的设计思想和原理
一、引入:词频统计问题 假如我们有一亿份文档,需要统计这一亿份文档的词频。我们会怎么做,有以下思路 使用单台PC执行:能不能存的下不说,串行计算,一份一份文档读,然后进行词频统计,需要运行很长时间多台PC:把文档分布到多台PC上处理,每个PC处理一部分文件,最后合并。——听起来很简单,但是实际实现的话还是有很多问题的。 对于第二种方法,有以下几种方法,我们来分别分析一下: 可以看到,我
数据统计:词频统计、词表生成、排序及计数、词云图生成
文章目录 📚输入及输出📚代码实现 📚输入及输出 输入:读取一个input.txt,其中包含单词及其对应的TED打卡号。 输出 output.txt:包含按频率降序排列的每个单词及其计数(这里直接用于后续的词云图生成)。 output_word.json:包含每个单词及其计数,以及与之关联的TED打卡号列表,生成一个json文件(按字母序排列,用于后续网页数据导入
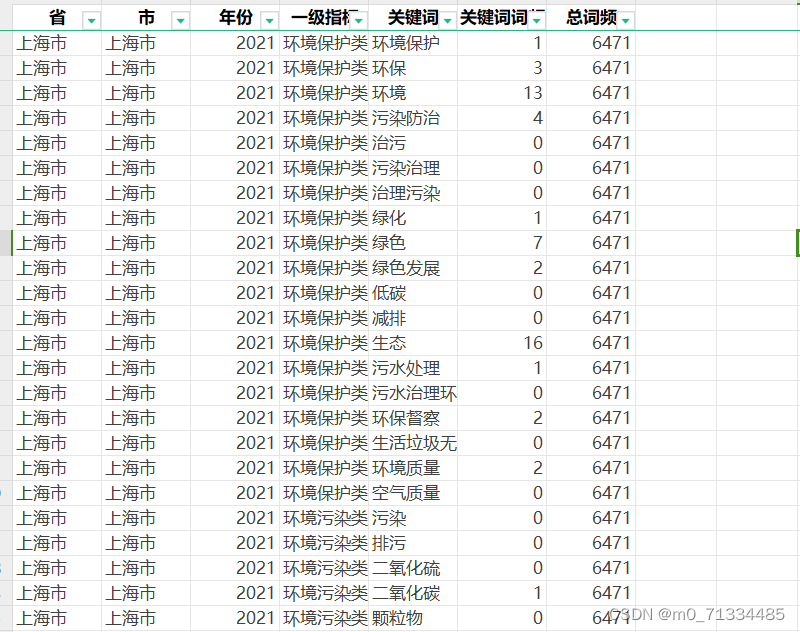
2005-2021年全国各地级市生态环境注意力/环保注意力数据(根据政府报告文本词频统计)
2005-2021年全国各地级市生态环境注意力/环保注意力数据(根据政府报告文本词频统计) 2005-2021年全国各地级市生态环境注意力/环保注意力数据(根据政府报告文本词频统计) 1、时间:2005-2021年 2、范围:270个地级市 3、指标: 省、市、年份、一级指标、关键词、关键词词频、总词频 4、来源:政府工作报告 5、关键词词频: 环境保护类: 关键词-环境保护、环保
MapReduce词频统计
1.1 文件准备 创建本地目录和创建两个文本文件,在两个文件中输入单词,用于统计词频。 cd /usr/local/hadoopmkdir WordFilecd WordFiletouch wordfile1.txttouch wordfile2.txt 1.2 创建一个HDFS目录,在本地上不可见,并将本地文本文件上传到HDFS目录。通过如下命令创建。 cd /usr/loc

使用python读取word统计词频并生成词云
1、准备 需要用到python-docx,jieba和wordcloud模块,先install pip3 install jiebapip install wordcloud 2、开始代码 (1)导入需要用到的模块 import reimport jiebaimport docxfrom wordcloud import WordCloudimport matplotlib.
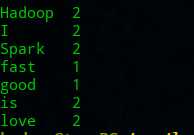
RDD编程 - 词频统计
RDD编程 - 词频统计 题目 编程要求 请仔细阅读右侧代码,根据方法内的提示,在Begin - End区域内进行代码补充,具体任务如下: 对文本文件内的每个单词都统计出其出现的次数。 按照每个单词出现次数的数量,降序排序。 文本文件内容如下: hello java hello python java hello python python hello flink scala scala s

「Python大数据」词频数据渲染词云图导出HTML
前言 本文主要介绍通过python实现数据聚类、脚本开发、办公自动化。词频数据渲染词云图导出HTML。 一、业务逻辑 读取voc数据采集的数据批处理,使用jieba进行分词,去除停用词词频数据渲染词云图将可视化结果保存到HTML文件中 二、具体产出 三、执行脚本 python wordCloud.py 四、关键代码 from pyecharts.charts import

在IntelliJ IDEA软件中用Python语言进行词频统计
1、首先在IntelliJ IDEA软件中插入Python插件,步骤如下: ①、右击“File”,然后点击设置 ②、先点击左侧的插件“Plugins”,然后输入“python”,点击右侧的“Install”,下载完后会出现一个重新启动的窗口,直接点击重启,之后点击“OK”。 2、插件完成后,创建Project ①、先点击左侧的“Python”,默认Project SDK,之后点

2001-2021年上市公司制造业智能制造词频统计数据
2001-2021年上市公司制造业智能制造词频统计数据 1、时间:2001-2021年 2、来源:上市公司年报 3、指标:年份、股票代码、行业名称、行业代码、所属省份、所属城市、智能制造词频、智能制造占比(%) 4、范围:上市公司 5、样本量:2.8W+ 6、参考文献:郭磊,贺芳兵,李静雯.中国智能制造发展态势分析——基于制造业上市公司年报的文本数据 7、下载链接: 2001-20

hadoop编程之词频统计
数据集实例 java代码,编程 实例 我们要先创建三个类分别为WordCoutMain、WordCoutMapper、WordCoutReducer这三个类 对应的代码如下 WordCoutMain import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache
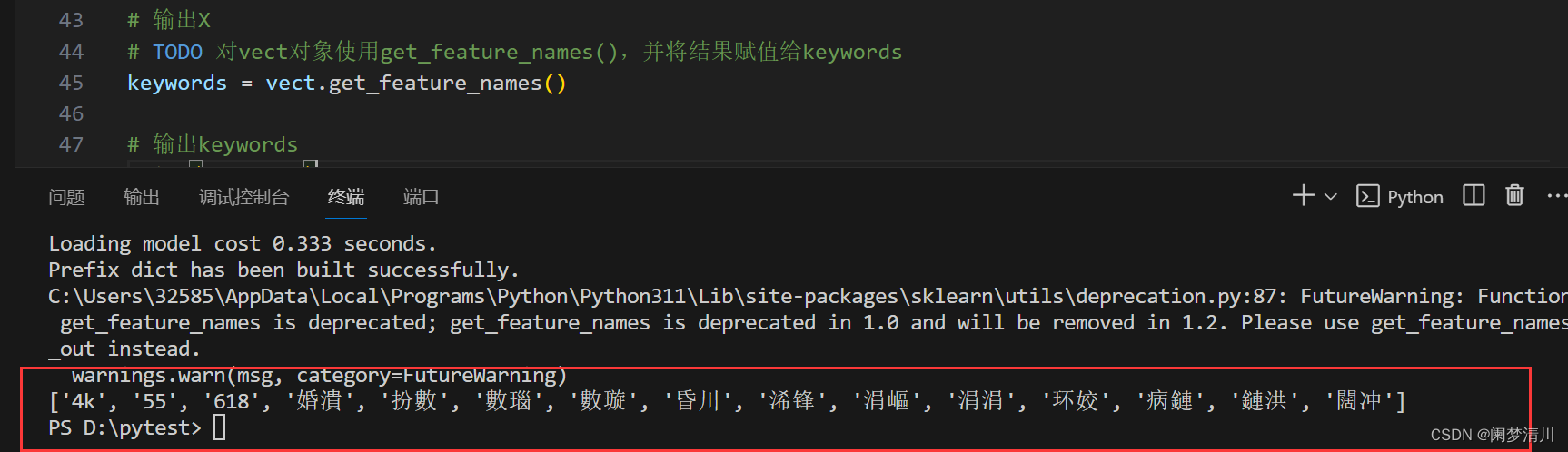
Python人工智能应用---中文分词词频统计
目录 1.中文分词 2.循环分别处理列表 (1)分析 (2)代码解决 3.词袋模型的构建 (1)分析需求 (2)处理分析 1.先实现字符串的连接 2.字符串放到新的列表里面 4.提取高频词语 (1)STEP1. 导入模块 (2)STEP2. 创建CountVectorizer对象 (3)STEP3. 使用fit_transform()函数构造词袋模型 (4)STEP
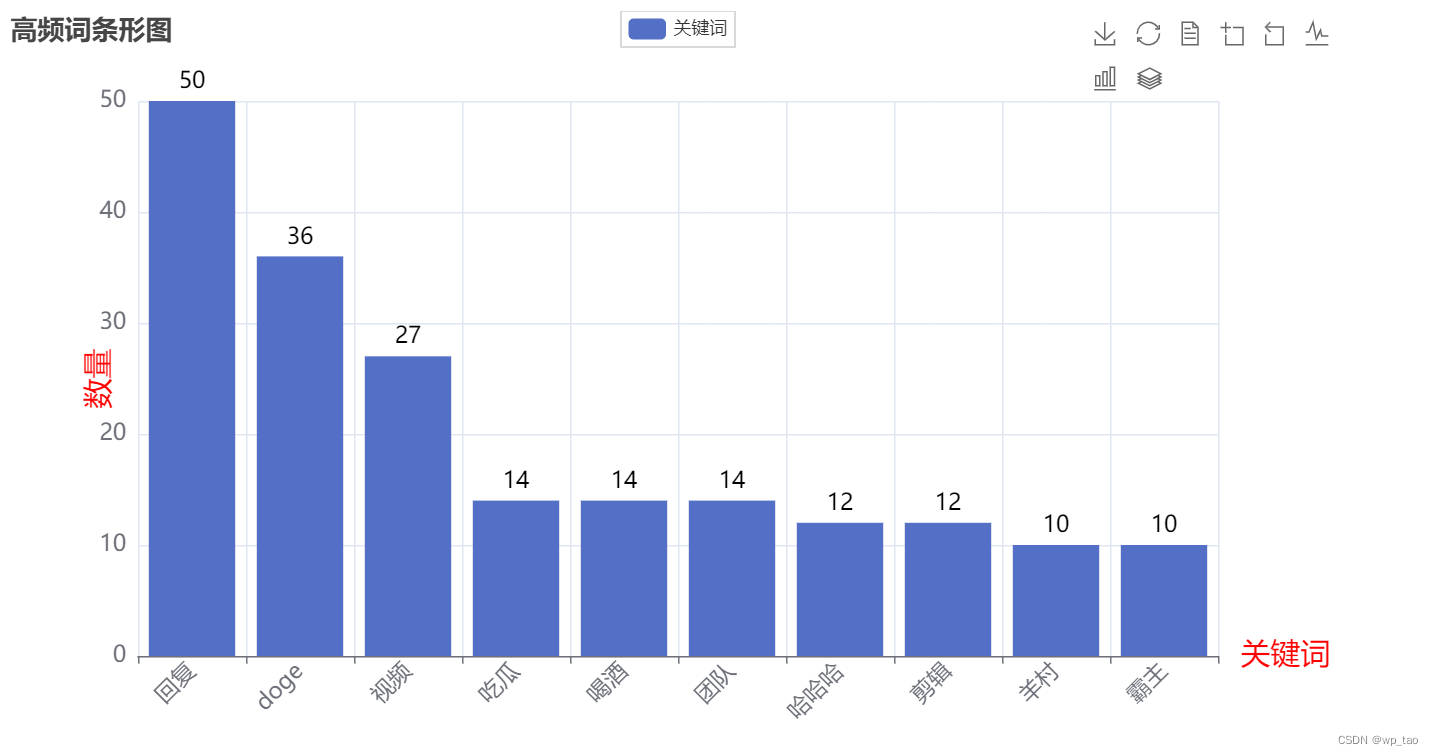
b站评论词频统计绘制词云图
一、评论爬取 在笔者之前的文章中,已经专门介绍了b站评论的爬取(传送门),这里只对b站评论的文本数据做展示。如下图所示: 二、分词、去停用词、词频统计 Python中的Jieba分词作为应用广泛的分词工具之一,其融合了基于词典的分词方法和基于统计的分词方法的优点,在快速地分词的同时,解决了歧义、未登录词等问题。因而Jieba分词是一个很好的分词工具。Jie
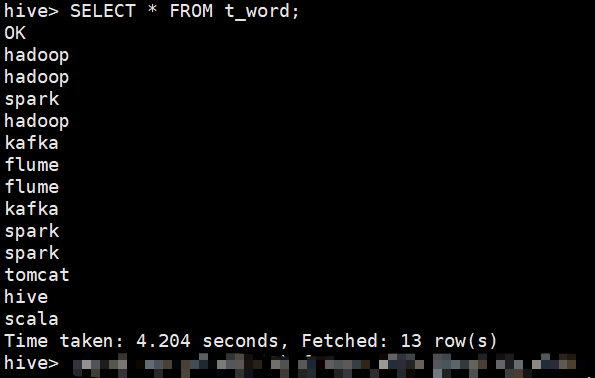
hive词频统计---文件始终上传不来
目录 准备工作: 文件内容: 创建数据库及表 将文件上传到:上传到/user/hive/warehouse/db1.db/t_word目录下 hive里面查询,始终报错:(直接查询也是不行) 解决方案: 准备工作: xshell连接主机,启动hadoop集群,启动MySQL服务已就绪 文件内容: 创建数据库及表 将文件上传到:上传到/user/hive/war
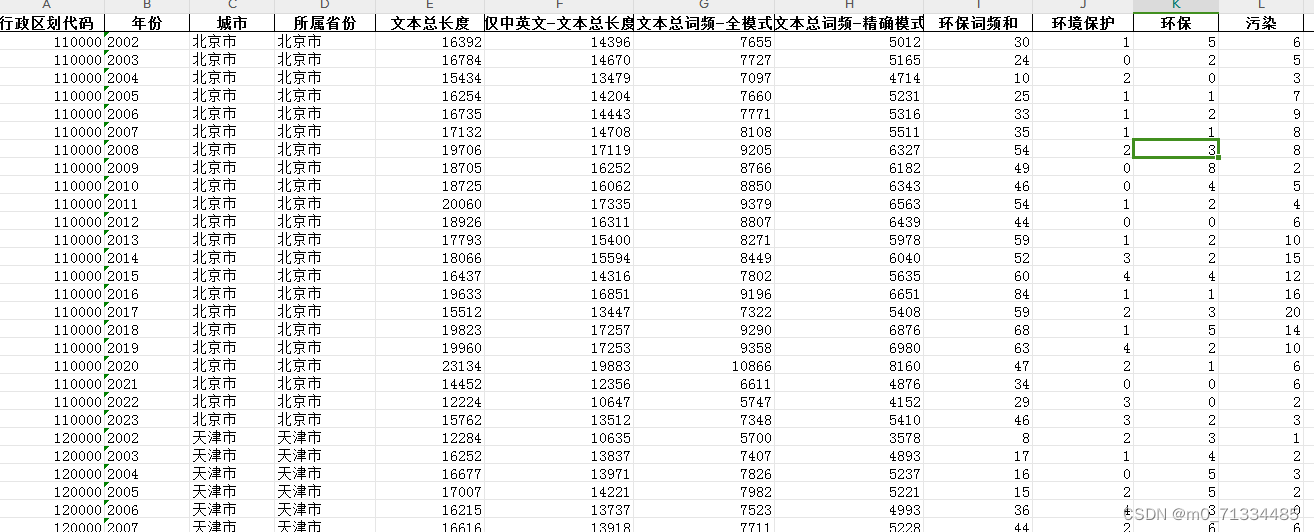
2002-2023年各地级市环境规制强度数据(环保词频统计)
2002-2023年各地级市环境规制强度数据(环保词频统计) 1、时间:2002-2023年 2、来源:政府工作报告 3、指标: 行政区划代码、年份、城市、所属省份、文本总长度、仅中英文-文本总长度、文本总词频-全模式、文本总词频-精确模式、环保词频和、环境保护、环保、污染、能耗、减排、排污、生态、绿色、低碳、空气、化学需氧量、二氧化硫|SO2、二氧化碳|CO2、PM10、PM2.5 4
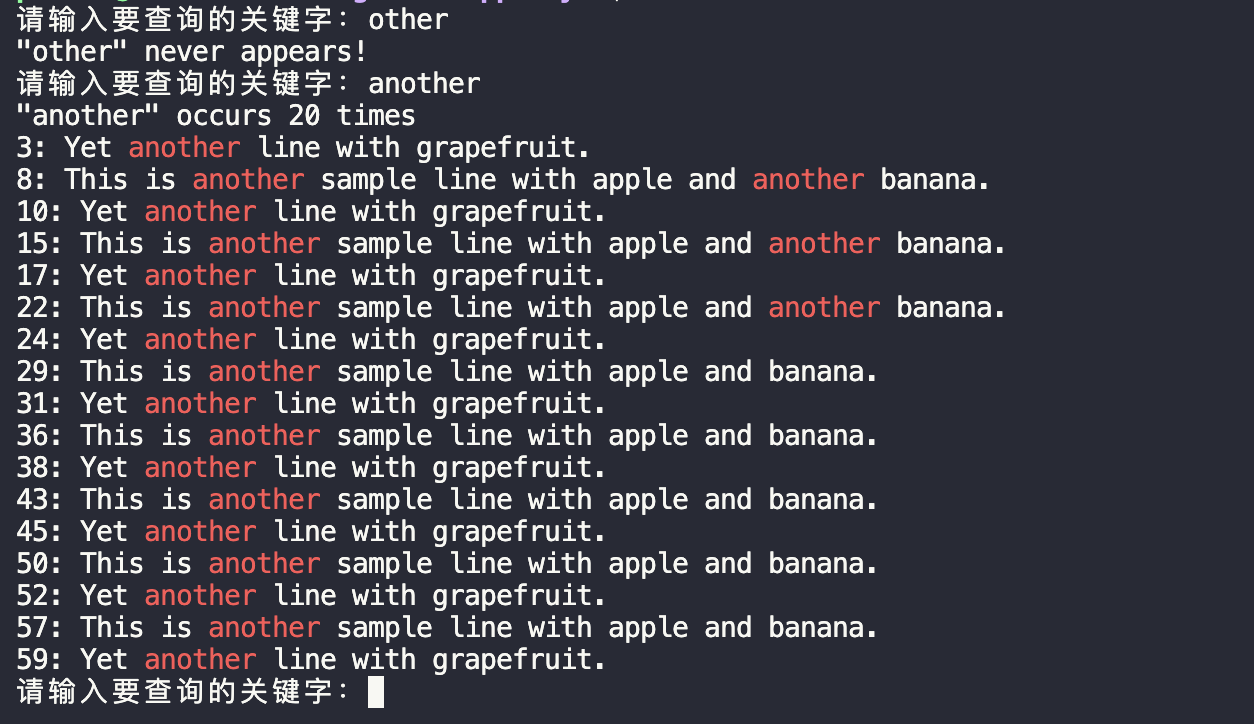
使用map和set实现简单的词频统计
一、运行效果图 二、代码示例 #include <iostream>#include <fstream>#include <sstream>#include <string>#include <map>#include <set>#include <vector>#include <algorithm>using namespace std;class TextQuery