本文主要是介绍【大数据·Hadoop】从词频统计由浅入深介绍MapReduce分布式计算的设计思想和原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、引入:词频统计问题
假如我们有一亿份文档,需要统计这一亿份文档的词频。我们会怎么做,有以下思路
- 使用单台PC执行:能不能存的下不说,串行计算,一份一份文档读,然后进行词频统计,需要运行很长时间
- 多台PC:把文档分布到多台PC上处理,每个PC处理一部分文件,最后合并。——听起来很简单,但是实际实现的话还是有很多问题的。
对于第二种方法,有以下几种方法,我们来分别分析一下:

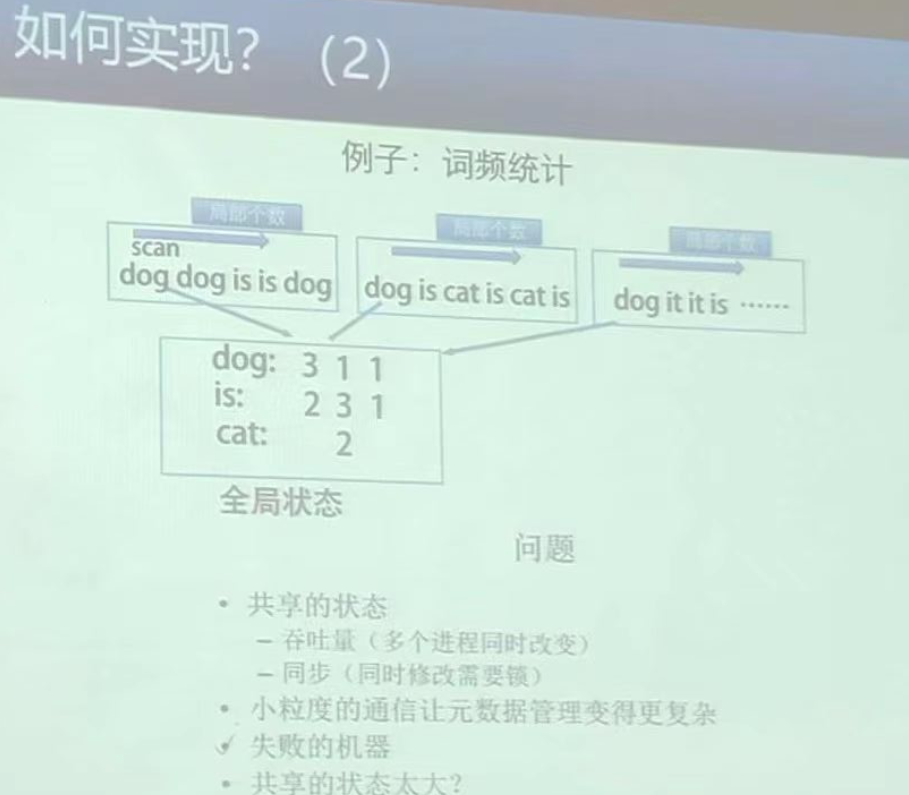
可以看到,我们把数据分布到多台主机上,然后让每台主机并行扫描文档,将读取到的单词发送给一台中央主机,由中央主机统一进行词频统计。
这样有哪些问题:
- 小粒度通信->网络通信瓶颈:所有子PC分别将一个个单词(超级无敌多)通过网络同时发送 给一台中央主机, 必定造成网络IO通信堵塞
- 中央主机的负载过重: 虽然数据分布到了多台子PC上进行扫描读取处理,的确和之前的单台PC相比(一个一个文档依次往后读)能节约时间,但是处理时间其实还是差不多的。
- 缺乏容错机制: 在这种单中央主机的设计思想下,一旦子PC中有一台出错,必定导致整个结果错误。
- 数据一致性和同步问题: 你想一想,像上图,多个子PC同时对比如
dog这个单词进行写入,这是一个并发操作,必须要加锁保证数据一致性。 - 扩展性问题: 随着数据量的增加,中央主机处理的数据量和计算负载也会线性增长,最终可能超过中央主机的处理能力。扩展系统可能需要更换更强大的中央主机,这不仅成本高昂,而且存在物理限制。
OK,我们先别一下子跳到MapReduce,看看基于上面这个方法我们还能怎么改进:
其实说实话这个基本上没啥改善,就是改了一下单台PC自己在发送词频之前先做了个预处理统计,这样能够稍微渐缓一下网络IO,但是其实还是没啥用。
那么还有什么其他可以改善的地方的吗?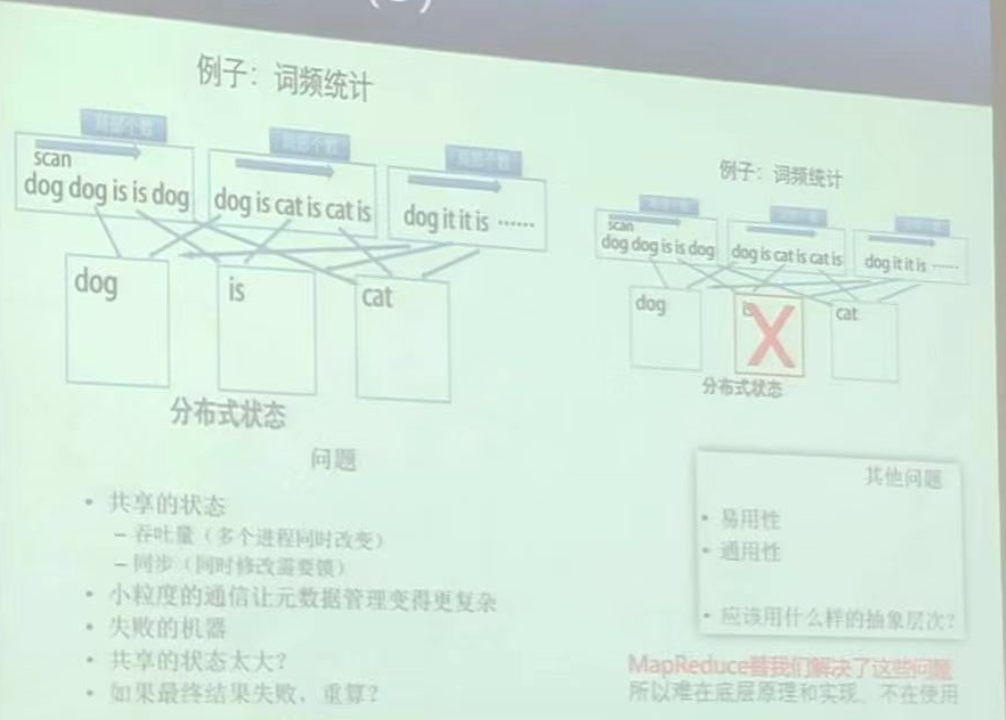
没错,上面不是说主机压力太大了吗?那么我们现在一个主机就处理一个单词,这样OK了把?其实还是有问题的,或者说带来了新的问题:
- 网络通信问题:这样一个个单词发,或者统计好了(也就是先做计算嘛)(其实很多时候不能先做计算,比如算整体学生的最大成绩差)再发,还是通信粒度太小了
- 负载不均衡:一些常见的单词(如“the”、“is”等)可能会导致某些主机负载过重,而其他主机负载轻松。
- 扩展性问题: 你看,我现在统计单词,那我统计汉字呢?计算主机的数量是不是需要改变??可扩展性还是很差的
其实在实现上还有很多细节问题:
- 数据怎么分呢?人工?手动分割数据并分配给多台机器处理,这个过程不仅繁琐而且难以管理和扩展。
- 开发者需要手动管理数据的分发、任务的执行、结果的汇总以及故障的处理等,这不仅增加了编程的复杂性,也增加了出错的几率。
- 处理分布式数据需要开发者对分布式系统的底层细节有深入的了解,如数据分布、通信机制、容错机制等
下面我们来看看MapReduce的思想,看看它是如何解决了这些问题,在这之中也可以看到:数据结构、算法、数学等知识的融合。
二、MapReduce介绍
2.1:设计思想
MapReduce的算法核心思想是: 分治
学过算法的同学应该会学到分治算法,所谓分治,就是把原问题分解为规模更小的问题,进行处理,最后将这些子问题的结果合并,就可以得到原问题的解。MapReduce这种分布式计算框架的核心就是:分治。
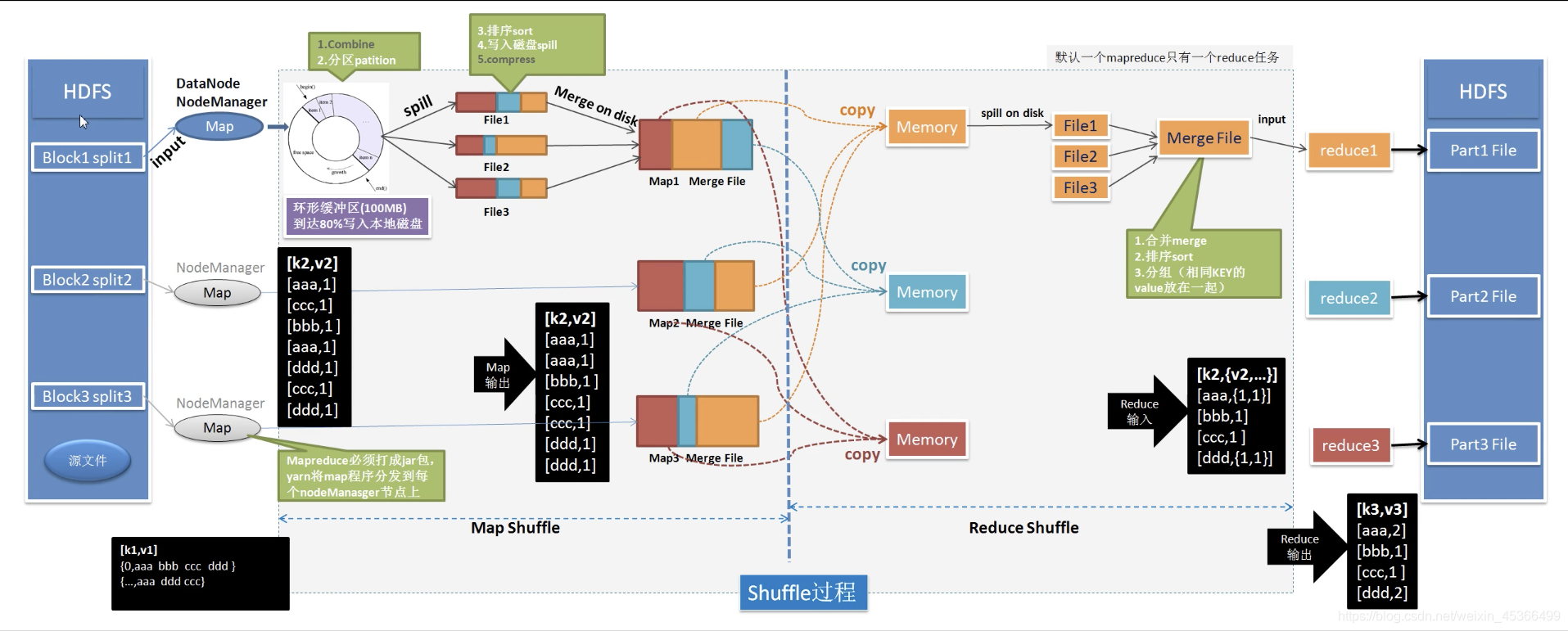
上图是MapReduce的处理流程图,可以看到,MapReduce的整个过程主要分为:
-
Map:
- 输入:来自存储在hdfs上的文件block进行分块(split)后,并且进行读取数据处理的分块数据的键值对(key-value)形式。—— 输入数据被分成一系列的数据块,被称为“input splits”。MapReduce框架尽量保持每个split的大小相同,这样每个Map任务处理的数据量就大致相等。这是负载均衡的第一步。
- 输出:进行扫描后的(单词,词频)的键值对形式
- 分析:Map任务通常在存储相应数据分片的节点上执行,这样可以减少网络传输。如果某些节点因为硬件性能好或者当前负载轻而完成任务更快,MapReduce可以把新的Map任务分配给这些节点,从而提高资源的利用率。MapReduce框架会自动管理数据的分片和分发,无需用户手动干预,从而提高数据分发效率。
-
Shuffle与Sort阶段
- 处理完数据后,Map任务的输出会进入Shuffle阶段。在这个阶段,框架负责将所有Map任务输出的键值对根据键进行排序和分组(还有combine,根据项目需要可选,减少网络io)。只有排序和分组后的数据会被发送到Reduce任务,这减少了网络传输的数据量,从而缓解网络通信瓶颈,同时,由于
shuffle阶段对所有的Map任务进行了排序和分组,也就是说,一组数据只分发给一个reduce,这样也不会来自多个map对同一个reduce同时写入的并发,即消除了并发风险,保证了数据一致性。
- 处理完数据后,Map任务的输出会进入Shuffle阶段。在这个阶段,框架负责将所有Map任务输出的键值对根据键进行排序和分组(还有combine,根据项目需要可选,减少网络io)。只有排序和分组后的数据会被发送到Reduce任务,这减少了网络传输的数据量,从而缓解网络通信瓶颈,同时,由于
-
Reduce任务的智能分配
- Reduce任务是根据Map阶段的输出键值对自动分配(默认是哈希,可以手写更优的分配算法)的。MapReduce尝试均匀地分配负载,确保每个Reduce任务处理相似数量的键值对。如果某个Reduce任务处理得更快,它可以接受更多的数据,从而实现动态的负载均衡。
从上面这个处理流程可以看出,MapReduce还有很多其他优点:
- 容错机制(解决容错和恢复机制问题)
MapReduce具备强大的容错机制。如果一个Map或Reduce任务失败,框架会自动在另一个节点上重新调度这个任务。此外,中间数据会被写入磁盘,这允许在节点故障后从最后一个检查点恢复,而不是从头开始。 - 水平扩展(解决扩展性问题)
MapReduce支持水平扩展。当数据量增加时,可以简单地增加更多的节点到集群中。MapReduce框架会自动利用这些新节点,无需对现有的应用程序做任何修改,这使得扩展性得到了极大的提高。
2.2:设计理念:移动计算而非移动数据
其实在开篇讲到的三种分布式计算统计词频的方法中,它们的想法核心都是移动数据,把数据移动到中央主机进行计算,这样带来很明显的问题:网络IO,带宽。
而MapReduce, 它将计算任务(Map和Reduce操作)分布到存储实际数据的节点上,这样就可以在数据存储的地方直接进行计算。这种方法减少了大量数据在网络中的移动,因为只有中间结果和最终结果需要在节点之间传输,这些比原始数据小得多。
这种做法不仅提高了网络传输的效率,也增强了系统的容错性。因为MapReduce框架会将Map任务的输出写入磁盘(中间结果),在发生故障时,可以从这些已经写入磁盘的中间结果恢复,而不需要从头开始处理数据。这意味着即使在节点失败的情况下,作业的执行仍然可以继续,从而保证了计算的连续性和完整性。
总结来说,MapReduce通过**“移动计算而非移动数据”**的设计理念,有效地解决了传统分布式计算方法中的网络效率和容错性问题。
这篇关于【大数据·Hadoop】从词频统计由浅入深介绍MapReduce分布式计算的设计思想和原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




