分布式计算专题

分布式计算 spark
Apache Spark是一个开源分布式运算框架,最初是由加州大学柏克莱分校AMPLab所开发。 Hadoop MapReduce的每一步完成必须将数据序列化写到分布式文件系统导致效率大幅降低。Spark尽可能地在内存上存储中间结果, 极大地提高了计算速度。 MapReduce是一路计算的优秀解决方案, 但对于多路计算的问题必须将所有作业都转换为MapReduce模式并串行执行。 Spark

MPI分布式计算开发和优化【王老师的嵌入式Linux实战课】
本期课程大纲 多节点运行环境配置多节点编程运行测试 课程详情 MPI分布式计算开发和优化(二) 对课程内容感兴趣或有疑问的小伙伴欢迎点击关注~ 与我起探索嵌入式Linux技术。
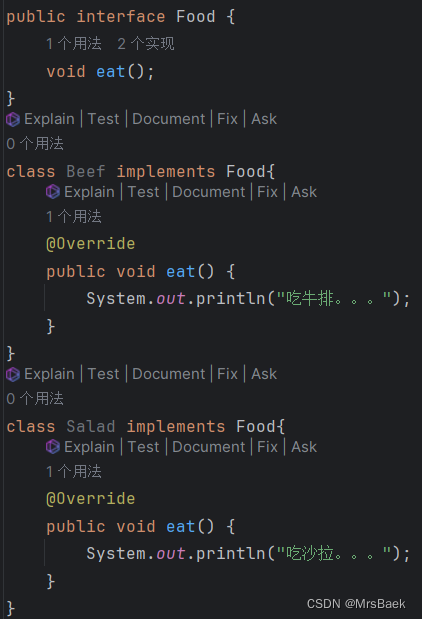
【java分布式计算】控制反转和依赖注入(DI IOC AOP)
考试要求:了解控制反转的基本模式,用依赖注入编写程序 目录 控制反转(Inversion of Control, IOC): 依赖注入(Dependency Injection, DI): 依赖注入的三种实现方式 具体的例子 DI DI 是依赖注入(Dependency Injection)的缩写,它是一种软件设计模式,用于管理组件之间的依赖关系。在依赖注入模式中,依赖关系的创建
2024年大数据领域的主流分布式计算框架有哪些
Apache Spark 适用场景 以批处理闻名,有专门用于机器学习的相关类库进行复杂的计算,有SparkSQL可以进行简单的交互式查询,也可以使用DataSet,RDD,DataFrame进行复杂的ETL操作。 关键词 处理数据量大批计算微批计算(可以理解成支持流计算)机器学习(丰富的类库)SQL查询(操作简单)内存计算(计算效率高,相对MapReduce而言)内存开销大(通过Spark
DASK==python分布式计算
启动调度器 dask-scheduler 启动一个worker并将自己注册到调度器 dask-worker 192.168.0.109:8786 然后编写代码执行 from dask.distributed import Clientif __name__ == "__main__":client = Client("tcp://192.168.0.109:8786")a = c

分布式计算——实现简单的浏览器和web服务器
此次是分布式的第三次作业,作业要求如下: 1、基于TCP通讯(ServerSocket、Socket套接字),编写一个带有图形用户界面的浏览器和 一个支持文档读取并返回给客户浏览器的web服务器。客户端支持超链接事件处理,服务器采用多 线程技术支持并发访问。 2、在此基础上,修改服务器侧设计与实现,使之能够动态地添加客户端请求的类文件,即设计 一个小服务程序容器。 3、试在服务器侧代码
分布式计算——Daytime协议的实现(TCP版)
分布式计算课程的第一个作业是写Daytime协议。 问:什么是Daytime协议? 答:Daytime是一个有用的调试和测量工具。无论输入请求是什么,daytime只是简单地以字符串形式返回当前的日期和时间。 问:Daytime协议返回格式是? 答:Daytime服务没有特别的语法。建议使用Ascii可打印字符,空格、回车和换行。Daytime限制在一行。语法如下: Weekday, M
互联网十万个为什么之什么是分布式计算?
分布式计算是一种计算方法,它将计算任务分散到多个物理或逻辑上分开的计算机(称为节点)上执行,这些节点通过网络互连并协作完成共同的目标。每个节点具备独立的处理能力和存储资源,在分布式系统中,它们共享数据,通过消息传递或更复杂的通信机制进行交互。分布式计算的主要目的是利用多个计算资源处理大规模问题,提高计算效率,增强数据处理能力,提供较高的可靠性和可扩展性。它是现代高性能计算、大数据处理和云计算等众多
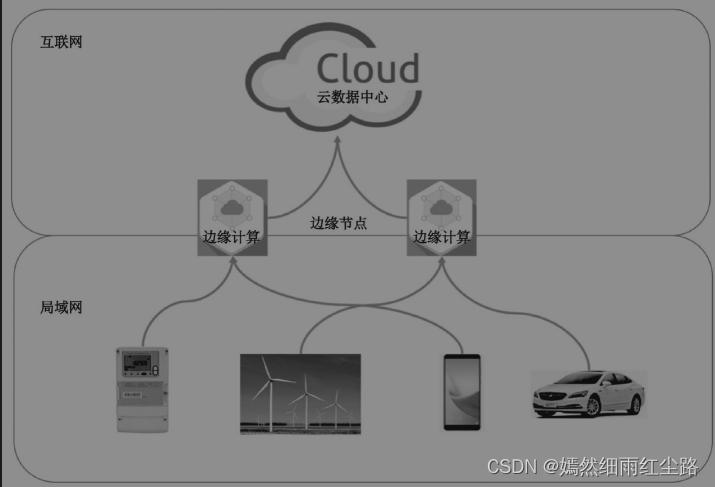
分布式计算、并行计算、网格计算、边缘计算
分布式计算 分布式计算是一种计算方法,它将一个大型的计算任务分解成多个子任务,并将这些子任务分布在网络上的多台计算机(节点)上同时执行。这些节点通过通信网络协同工作,共同完成任务。每个节点可以独立处理自己的那部分数据或计算任务,最终汇总结果。分布式计算特别适用于处理那些需要巨大计算资源或数据处理能力的问题,如大规模数据分析、模拟和科研项目(如SETI@home寻找外星智能项目)。它的优势在于能够
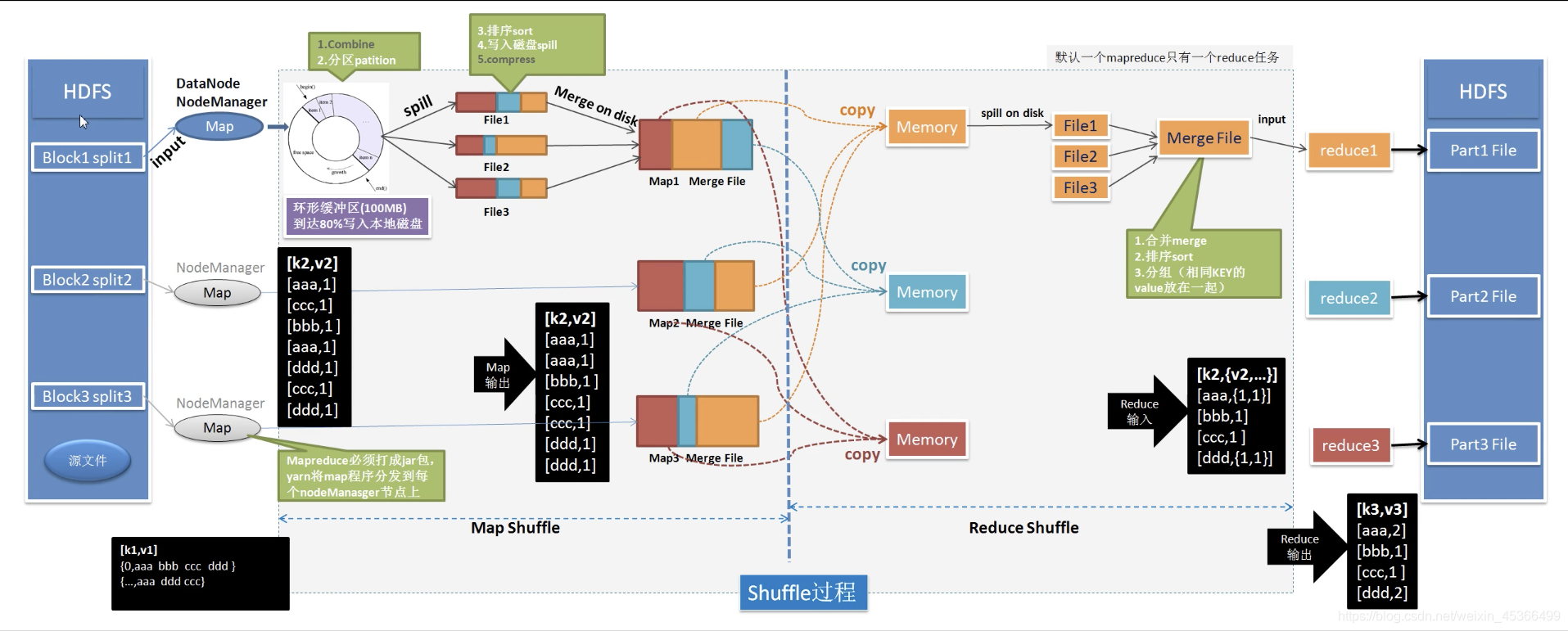
【大数据·Hadoop】从词频统计由浅入深介绍MapReduce分布式计算的设计思想和原理
一、引入:词频统计问题 假如我们有一亿份文档,需要统计这一亿份文档的词频。我们会怎么做,有以下思路 使用单台PC执行:能不能存的下不说,串行计算,一份一份文档读,然后进行词频统计,需要运行很长时间多台PC:把文档分布到多台PC上处理,每个PC处理一部分文件,最后合并。——听起来很简单,但是实际实现的话还是有很多问题的。 对于第二种方法,有以下几种方法,我们来分别分析一下: 可以看到,我

浅谈Java分布式计算
如果所有组件都在同一台计算机的同一个Java虚拟机的同一个堆空间上执行是最简单的,但实际中我们面对的往往不是如此单一的情况,如果用户端只是个能够执行Java的装置怎么办?如果为了安全性的理由只能让服务器上的程序存取数据库怎么办? 我们知道,大多数情况下,方法的调用都是发生在相同堆上的两个对象之间,如果要调用不同机器上的对象的方法呢? 通常,我们从某一台计算机上面取得另一台计算机上
大数据分布式计算引擎用虚拟CPU的核心原因?
两个核心原因: 第一:为了屏蔽不同服务器之间的CPU算力差异。 第二:为了增加集群可提交的任务数量以及提高单个CPU的使用效率。 当我们做大数据开发用分布式计算引擎提交任务时,一般都会给每个提交的任务分配对应的内存和CPU资源。在给一个分布式任务比如spark分配CPU核心数量时,这个核心数其实指的是虚拟核心数。
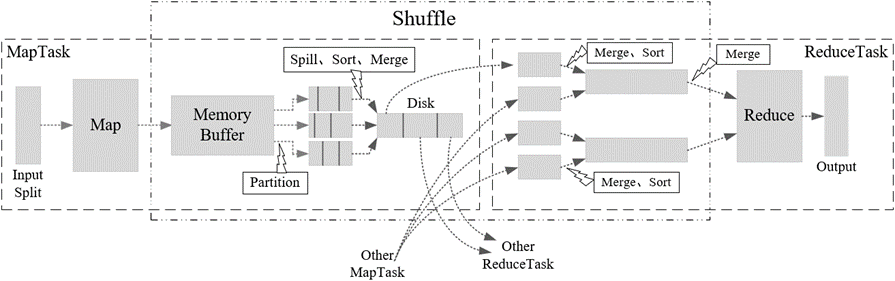
【Hadoop大数据技术】——MapReduce分布式计算框架(学习笔记)
📖 前言:MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算问题,是目前分布式计算模型中应用较为广泛的一种。 目录 🕒 1. MapReduce概述🕘 1.1 核心思想:分而治之🕘 1.2 编程模型🕘 1.3 经典实例——词频统计 🕒 2. MapReduce工作原理🕘 2.1 工作过程🕘 2

分布式计算PHP,什么是分布式计算
分布式计算是近年提出的一种新的计算方式,所谓分布式计算就是在两个或多个软件互相共享信息,这些软件既可以在同一台计算机上运行,也可以在通过网络连接起来的多台计算机上运行。 分布式计算是计算机科学中一个研究方向,它研究如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给多个计算机进行处理,最后把这些计算结果综合起来得到最终的结果。分布式网络存储技术是将数据分散地存储

2.2.11 hadoop体系之离线计算-mapreduce分布式计算-案例:Reduce端实现Join
目录 1.需求分析 2.数据展示 3.实现机制 3.1 ReduceJoinMapper:定义Mapper 3.2 ReduceJoinReducer:定义Reducer 3.3 JobMain:定义Main方法 4.运行并查看结果 4.1 准备数据 4.2 运行结果 1.需求分析 假如数据量巨大,两表的数据是以文件的形式存储在 HDFS 中, 需要用 MapReduce

2.2.9 hadoop体系之离线计算-mapreduce分布式计算-流量统计之手机号码分区
目录 1.需求分析 2.代码方案 2.1 自定义分区 2.2 JobMain添加分区设置 2.3 分区结果 1.需求分析 在需求一的基础上,继续完善,将不同的手机号分到不同的数据文件的当中去,需要自定 义分区来实现,这里我们自定义来模拟分区,将以下数字开头的手机号进行分开 135 开头的数据到一个分区文件136开头的数据到一个分区文件137开头的数据到一个分区文件其他数据到一个

2.2.8 hadoop体系之离线计算-mapreduce分布式计算-流量统计之上行流量倒序排序(递减排序)
目录 1.需求分析 2.代码实现 2.1 定义FlowBean:实现WritableComparable实现比较排序 2.2 定义FlowCountSortMapper 2.3 定义FlowCountSortReducer 2.4 定义JobMain:程序main函数 3.运行及结果分析 1.需求分析 按数据某个字段排序输出:可以写两个MapReduce 以需求一的输出数据

2.2.7 hadoop体系之离线计算-mapreduce分布式计算-流量统计之统计求和
目录 1.需求分析 2.代码实现 2.1 数据展示 2.2 解决思路 2.3 代码结构 2.3.1 FlowBean 2.3.2 FlowCountMapper 2.3.3 FlowCountReduce 2.3.4 JobMain 3.运行及结果分析 3.1 准备工作 3.2 运行代码及结果展示 1.需求分析 统计求和:统计每个手机号的上行流量总和,下行流量总和,
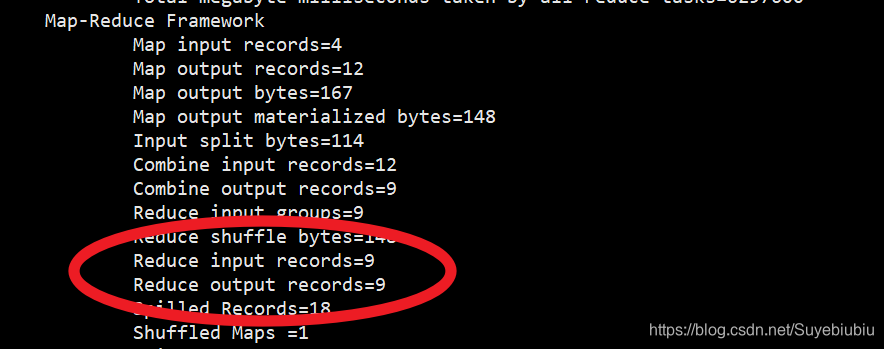
2.2.6 hadoop体系之离线计算-mapreduce分布式计算-规约Combiner
目录 1.规约Combiner概念 2.规约Combiner图示 3.规约Combiner实现步骤 3.1 运行之前的wordcount 3.2 规约代码 3.2.1 MyCombiner 3.2.2 JobMain 1.规约Combiner概念 每一个 map 都可能会产生大量的本地输出,Combiner 的作用就是对 map 端的输出先做 一次合并,以减少在 map 和

2.2.4 hadoop体系之离线计算-mapreduce分布式计算-MapReduce序列化和排序
目录 1.概念 2.需求分析 3.具体代码 3.1 自定义类型和比较器 3.2 Mapper 3.3 Reducer 3.4 Main入口 4.运行并查看结果 4.1 准备工作 4.2 打包jar 4.3 运行jar包,查看结果 1.概念 序列化 (Serialization) 是指把结构化对象转化为字节流反序列化 (Deserialization) 是序列化的逆过程

2.2.3 hadoop体系之离线计算-mapreduce分布式计算-MapReduce分区
目录 1.复习MapReduce的8个步骤 2.MapReduce中的分区 2.1 新需求:需要分别reduce 3.IDEA实现分区-JAVA 3.1 实现自定义Partitioner-MyPartitioner.java 3.2 设置主函数:定义分区+设置分区数目 3.3 打成jar包 4.运行并且查看结果 1.复习MapReduce的8个步骤 2.MapReduc

2.2.2 hadoop体系之离线计算-mapreduce分布式计算-WordCount案例
目录 1.需求 2.数据准备 2.1 创建一个新文件 2.2 其中放入内容并保存 2.3 上传到HDFS系统 3.IDEA写程序 3.1 pom 3.2 Mapper 3.3 Reduce 3.4 定义主类,描述Job并且提交Job 3.5 在IDEA中打包成jar包,上传到node01中的 /export/software中 4.运行jar包,并且查看运行情况 1.

3.1.6 spark体系之分布式计算-scala编程-scala中trait特性
目录 1.概念理解 2.举例:trait中带属性带方法实现 3.举例:trait中带方法不实现 1.概念理解 Scala Trait(特征) 相当于 Java 的接口,实际上它比接口还功能强大。 与接口不同的是,它还可以定义属性和方法的实现。 一般情况下Scala的类可以继承多个Trait,从结果来看就是实现了多重继承。 Trait(特征) 定义的方式与类类似,但它使用的关键字是 t

分布式计算平台Hadoop 发展现状
解读:分布式计算平台Hadoop 发展现状 2012年05月04日01:23 IT168 字号: T| T 【IT168 技术】雅虎开发者Doug Cutting六年前创建了一个用于管理,存储和分析大量数据的分布式计算平台hadoop,现在大家也称云计算平台,用他儿子的玩具大象命名,并把它交给阿帕奇软件基金会。鉴于围绕Hadoop建立的整个行业的迅速,这会使某些人觉得非常惊

共享之力:分布式计算的奇迹
在信息时代的浪潮中,分布式计算作为一种革命性的技术,已经深刻地改变了我们对计算和数据处理的理解方式。其发展历程既是一段精彩的科技史,也是一段充满探索与突破的冒险故事,从最初的概念探索到如今的普及应用,分布式计算一路走来,不断演化,影响着我们的生活与工作。 1. 起源:分布式计算的雏形 分布式计算的起源可以追溯到20世纪70年代,当时的计算机科学家们开始探索如何利用多台计算机共同完成一个任务。分