本文主要是介绍2.2.2 hadoop体系之离线计算-mapreduce分布式计算-WordCount案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.需求
2.数据准备
2.1 创建一个新文件
2.2 其中放入内容并保存
2.3 上传到HDFS系统
3.IDEA写程序
3.1 pom
3.2 Mapper
3.3 Reduce
3.4 定义主类,描述Job并且提交Job
3.5 在IDEA中打包成jar包,上传到node01中的 /export/software中
4.运行jar包,并且查看运行情况
1.需求
在一堆给定的文本文件中统计输出每一个单词出现的总次数
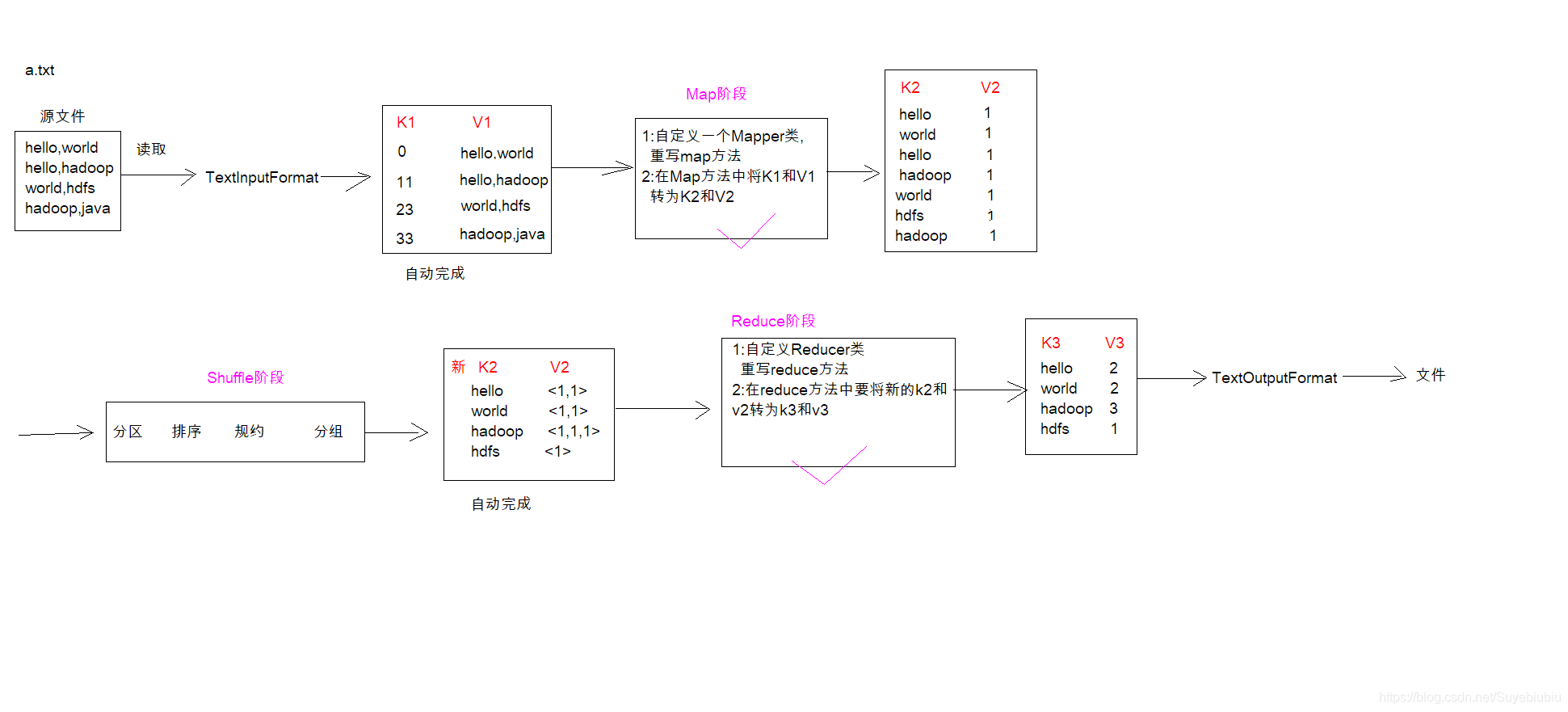
2.数据准备
2.1 创建一个新文件
cd /export/servers
vim wordcount.txt
2.2 其中放入内容并保存
hello,world,hadoop
hive,sqoop,flume,hello
kitty,tom,jerry,world
hadoop
2.3 上传到HDFS系统
hdfs dfs ‐mkdir /wordcount/
hdfs dfs ‐put wordcount.txt /wordcount/3.IDEA写程序

3.1 pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>cn.itcast</groupId><artifactId>day03_mapreduce_wordcount</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>6</source><target>6</target></configuration></plugin></plugins></build><repositories><repository><id>cloudera</id><url>https://repository.cloudera.com/artifactory/cloudera-repos/</url></repository></repositories><dependencies><dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.8</version><scope>system</scope><systemPath>${JAVA_HOME}/lib/tools.jar</systemPath></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.0.0</version><scope>provided</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.0.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs-client</artifactId><version>3.0.0</version><scope>provided</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.0.0</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>RELEASE</version><scope>compile</scope></dependency></dependencies></project>3.2 Mapper
package com.ucas.mapredece;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;/*** @author GONG* @version 1.0* @date 2020/10/8 23:19*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {@Overridepublic void map(LongWritable key, Text value, Context context) throwsIOException, InterruptedException {String line = value.toString();String[] split = line.split(",");for (String word : split) {context.write(new Text(word), new LongWritable(1));}}
}3.3 Reduce
package com.ucas.mapredece;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** @author GONG* @version 1.0* @date 2020/10/8 23:20*/
class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {@Overrideprotected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException {long count = 0;for (LongWritable value : values) {count += value.get();}context.write(key, new LongWritable(count));}
}3.4 定义主类,描述Job并且提交Job
package com.ucas.mapredece;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.conf.Configured;public class JobMain extends Configured implements Tool {@Overridepublic int run(String[] args) throws Exception {Job job = Job.getInstance(super.getConf(), JobMain.class.getSimpleName());//打包到集群上面运行时候,必须要添加以下配置,指定程序的main函数job.setJarByClass(JobMain.class);//第一步:读取输入文件解析成key,value对job.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(job, new Path("hdfs://192.168.0.101:8020/wordcount"));//第二步:设置我们的mapper类job.setMapperClass(WordCountMapper.class);//设置我们map阶段完成之后的输出类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);//第三步,第四步,第五步,第六步,省略//第七步:设置我们的reduce类job.setReducerClass(WordCountReducer.class);//设置我们reduce阶段完成之后的输出类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);//第八步:设置输出类以及输出路径job.setOutputFormatClass(TextOutputFormat.class);TextOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.101:8020/wordcount_out"));//上面那个路径时不允许存在的,会帮我们自动创建这个文件夹boolean b = job.waitForCompletion(true);return b ? 0 : 1;}/*** 程序main函数的入口类** @param args* @throws Exception*/public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();Tool tool = new JobMain();int run = ToolRunner.run(configuration, tool, args);System.exit(run);}
}
3.5 在IDEA中打包成jar包,上传到node01中 /export/software中

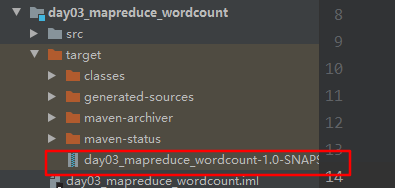
4.运行jar包,并且查看运行情况
进入:cd /export/software
运行命令: hadoop jar day03_mapreduce_wordcount-1.0-SNAPSHOT.jar com.ucas.mapredece.JobMain
[root@node01 software]# hadoop jar day03_mapreduce_wordcount-1.0-SNAPSHOT.jar com.ucas.mapredece.JobMain
2020-10-09 20:47:59,083 INFO client.RMProxy: Connecting to ResourceManager at node01/192.168.0.101:8032
2020-10-09 20:48:00,154 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1602247634978_0001
2020-10-09 20:48:01,299 INFO input.FileInputFormat: Total input files to process : 1
2020-10-09 20:48:01,532 INFO mapreduce.JobSubmitter: number of splits:1
2020-10-09 20:48:01,592 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2020-10-09 20:48:01,892 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1602247634978_0001
2020-10-09 20:48:01,894 INFO mapreduce.JobSubmitter: Executing with tokens: []
2020-10-09 20:48:02,961 INFO conf.Configuration: resource-types.xml not found
2020-10-09 20:48:02,961 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2020-10-09 20:48:03,741 INFO impl.YarnClientImpl: Submitted application application_1602247634978_0001
2020-10-09 20:48:03,825 INFO mapreduce.Job: The url to track the job: http://node01:8088/proxy/application_1602247634978_0001/
2020-10-09 20:48:03,826 INFO mapreduce.Job: Running job: job_1602247634978_0001
2020-10-09 20:48:19,613 INFO mapreduce.Job: Job job_1602247634978_0001 running in uber mode : false
2020-10-09 20:48:19,642 INFO mapreduce.Job: map 0% reduce 0%
2020-10-09 20:48:28,806 INFO mapreduce.Job: map 100% reduce 0%
2020-10-09 20:48:34,851 INFO mapreduce.Job: map 100% reduce 100%
2020-10-09 20:48:35,916 INFO mapreduce.Job: Job job_1602247634978_0001 completed successfully
2020-10-09 20:48:36,200 INFO mapreduce.Job: Counters: 53File System CountersFILE: Number of bytes read=197FILE: Number of bytes written=431667FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=185HDFS: Number of bytes written=70HDFS: Number of read operations=8HDFS: Number of large read operations=0HDFS: Number of write operations=2Job Counters Launched map tasks=1Launched reduce tasks=1Data-local map tasks=1Total time spent by all maps in occupied slots (ms)=6124Total time spent by all reduces in occupied slots (ms)=3936Total time spent by all map tasks (ms)=6124Total time spent by all reduce tasks (ms)=3936Total vcore-milliseconds taken by all map tasks=6124Total vcore-milliseconds taken by all reduce tasks=3936Total megabyte-milliseconds taken by all map tasks=6270976Total megabyte-milliseconds taken by all reduce tasks=4030464Map-Reduce FrameworkMap input records=4Map output records=12Map output bytes=167Map output materialized bytes=197Input split bytes=114Combine input records=0Combine output records=0Reduce input groups=9Reduce shuffle bytes=197Reduce input records=12Reduce output records=9Spilled Records=24Shuffled Maps =1Failed Shuffles=0Merged Map outputs=1GC time elapsed (ms)=168CPU time spent (ms)=2310Physical memory (bytes) snapshot=487010304Virtual memory (bytes) snapshot=4846088192Total committed heap usage (bytes)=302223360Peak Map Physical memory (bytes)=372805632Peak Map Virtual memory (bytes)=2409140224Peak Reduce Physical memory (bytes)=114204672Peak Reduce Virtual memory (bytes)=2436947968Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=71File Output Format Counters Bytes Written=70
[root@node01 software]#


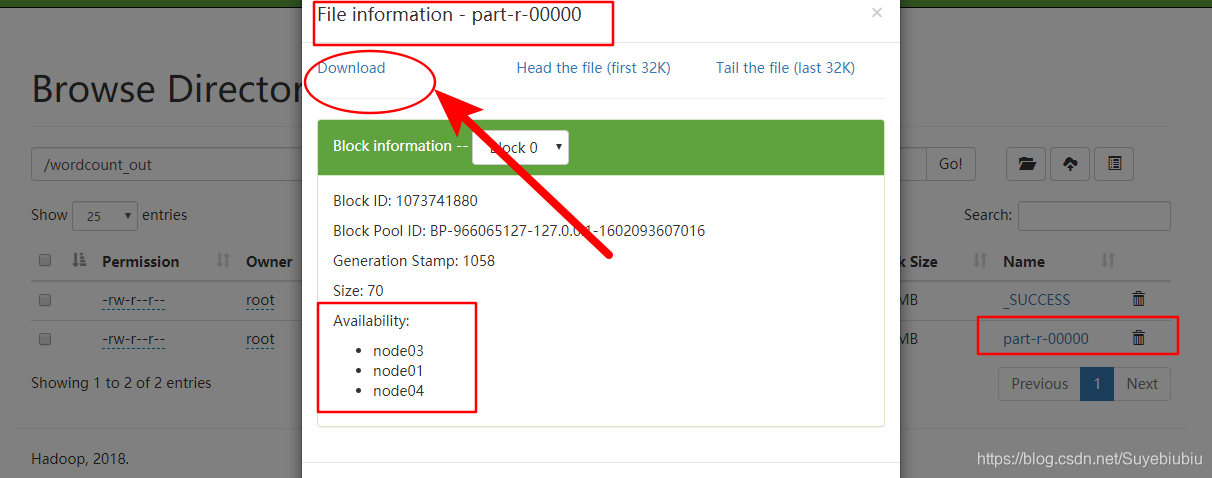
运行结果:

这篇关于2.2.2 hadoop体系之离线计算-mapreduce分布式计算-WordCount案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








