wordcount专题

【硬刚Hadoop】HADOOP入门(4):使用(3)安装(3)Hadoop运行模式(1)本地运行模式(官方WordCount)
本文是对《【硬刚大数据之学习路线篇】从零到大数据专家的学习指南(全面升级版)》的Hadoop部分补充。 0 简介 1)Hadoop官方网站:Apache Hadoop 2)Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。伪分布式模式:也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布

IntelliJ IDEA(Community版本)的下载、安装和WordCount的初步使用(本地模式和集群模式)
不多说,直接上干货! 对于初学者来说,建议你先玩玩这个免费的社区版,但是,一段时间,还是去玩专业版吧,这个很简单哈,学聪明点,去搞到途径激活!可以看我的博客。 包括: IntelliJ IDEA(Community)的下载 IntelliJ IDEA(Community)的安装 IntelliJ IDEA(Community)中

spark下载安装和第一个Wordcount程序
spark环境安装http://www.jianshu.com/p/7b325155edab Java环境搭建 JDK1.7下载,百度网盘 ,http://www.oracle.com/technetwork/java/javase/downloads/index.html Scala下载安装 2.10.0 spark下载 1.6.2 sbt 0.13.8

Spark WordCount使用示例
package com.sparktestimport org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/** * 使用scala开发本地测试的Spark WordCount程序 */object WordCount {def main(args: Array[String]): Unit

高性能并行计算华为云实验二:WordCount算法实验
目录 一、实验目的 二、实验说明 三、实验过程 3.1 创建wordcount源码 3.1.1 实验说明 3.1.2 文件创建 3.2 Makefile文件创建与编译 3.3 主机配置文件建立与运行监测 3.3.1 主机配置文件建立 3.3.2 运行监测 三、实验结果与分析 4.1 实验结果 4.2 结果分析 4.2.1 原始结果分析 4.2.2 改进后的结果分析
Hadoop 自带WordCount 操作步骤
运行一个wordcount 任务的命令:bin/hadoop jar /usr/hddemo/wordcount.jar 包名.WordCount input output 说明:input 指定的是执行map任务是的数据源所在目录,output 是指定reduce任务 执行完后将结果输出的目录 data在配置文件配完后是不需要见这个目录的 name目录是 执行 had
Hadoop WordCount详细分析
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class WordCount{
配置Hadoop2.x的HDFS、MapReduce来运行WordCount程序
主机HDFSMapReducenode1NameNodeResourceManagernode2SecondaryNameNode & DataNodeNodeManagernode3DataNodeNodeManagernode4DataNodeNodeManager 1.配置hadoop-env.sh export JAVA_HOME=/csh/link/jdk 2.配置core-sit
spark与flink的wordcount示例
spark的wordcount示例: package sparkimport org.apache.spark._object TestSparkWordCount {def main(args: Array[String]): Unit = {val sc = new SparkContext(new SparkConf().setAppName("wordcount").setMaster(

hadoop的第一个程序wordcount实现
具体安装步骤请见博客:linux hadoop 2.7 伪分布式安装简单几步实现 1. 在本地新建一个文件,笔者在~/hadoop-2.7.1/local_data文件夹新建了一个文本文件hello.txt,local_data文件夹也是新建的。文件内容是: he wo shi he jing shao wo shi shao jie ni ni shi lu lu 2. 在hdfs文件系

详解 WordCount 运行后历史日志记录
在 《Hadoop-2.5.0-cdh5.3.2 HA 安装》 一文中我们已经详细讲述了如何搭建 HA 模式,同时最后还演示了运行其自带的 wordcount 程序,详情请参考 运行 Hadoop自带 wordcount 程序 。先简要回顾下: 一 Hadoop 日志基本概念 1 运行 wordcount 程序2 控制台输出结果 二 Hadoop History 服务器网页详解 1 Res
Spark安装、解压、配置环境变量、WordCount
Spark 小白的spark学习笔记 2024/5/30 10:14 文章目录 Spark安装解压改名配置spark-env.sh重命名,配置slaves启动查看配置环境变量 工作流程maven创建maven项目配置maven更改pom.xml WordCount按照用户求消费额上传到spark集群上运行 安装 上传,直接拖拽 解压 tar -zxvf spark
spark wordcount 单词统计
spark wordcount 单词统计 文件1.txt hello worldhello tomhello lucytom lucyhello python # -*- coding:utf-8 -*-import osimport shutilfrom pyspark import SparkContextinputpath = '1.txt'outputpath = 'r
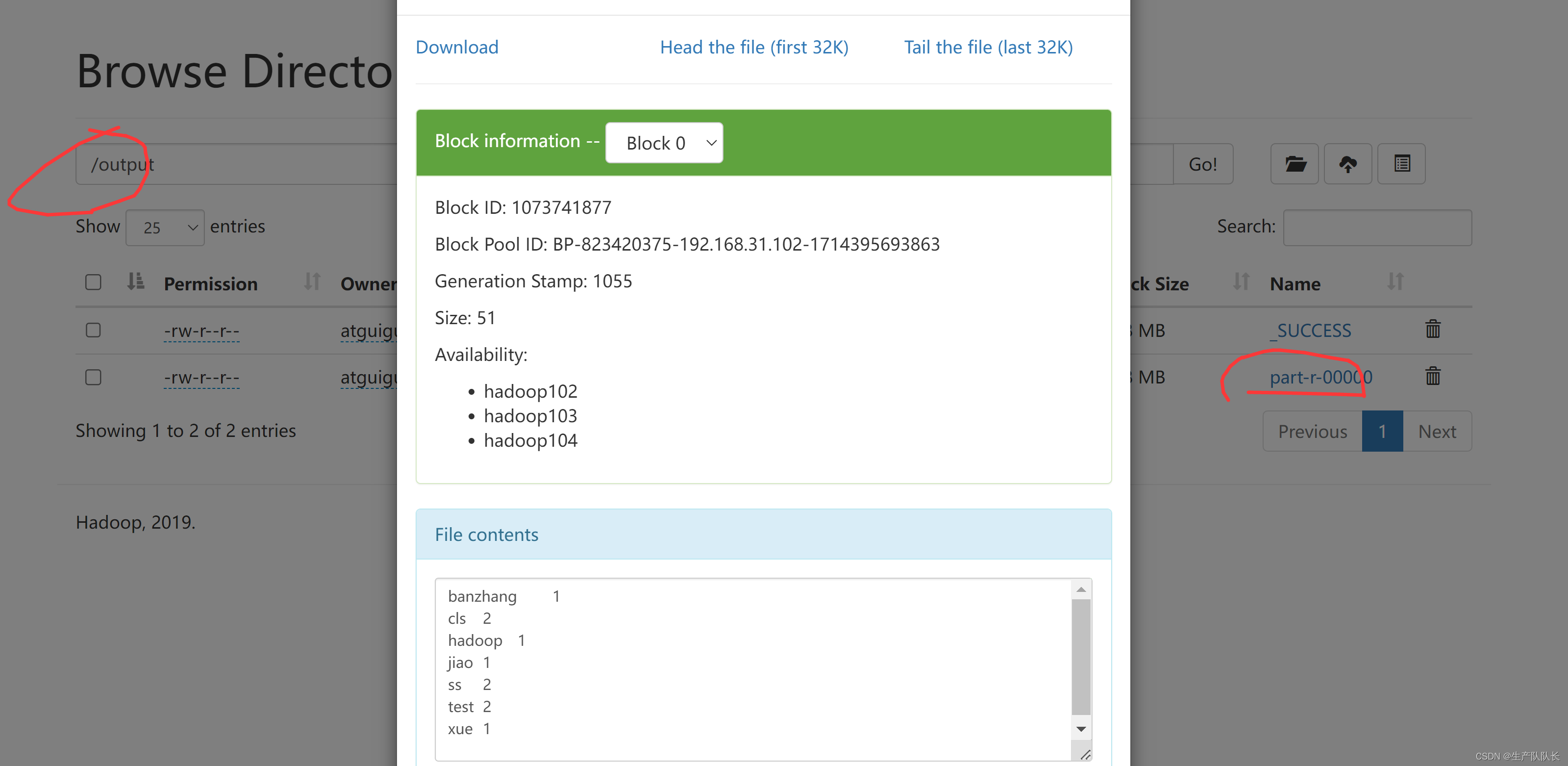
Hadoop3:MapReduce之简介、WordCount案例源码阅读、简单功能开发
一、概念 MapReduce是一个 分布式运算程序 的编程框架,是用户开发“基于 Hadoop的数据分析 应用”的核心框架。 MapReduce核心功能是将 用户编写的业务逻辑代码 和 自带默认组件 整合成一个完整的 分布式运算程序 ,并发运行在一个 Hadoop集群上。 1、MapReduce是集群上的并行计算框架 2、平时开发中只需要基于MapReduce接口,编写业务逻辑代码即可。 二
Hadoop之wordcount有感
Hadoop wordcount的实现和一些问题总结 作者在解决问题过程中遇到的很有帮助的一个博客就是来自如下地址,特别放在文首感谢! http://www.powerxing.com/install-hadoop/ 文件调整 就上篇hadoop配置而言,由于未认识到hadoop2.x的版本配置方面稍有不同,所以在做wordcount的sample之前先进行了改进。 不同在于mapr
Spark Streaming流式计算的WordCount入门
[size=medium] Spark Streaming是一种近实时的流式计算模型,它将作业分解成一批一批的短小的批处理任务,然后并行计算,具有可扩展,高容错,高吞吐,实时性高等一系列优点,在某些场景可达到与Storm一样的处理程度或优于storm,也可以无缝集成多重日志收集工具或队列中转器,比如常见的 kakfa,flume,redis,logstash等,计算完后的数据结果,也可以 存储

wordcount案例的shuffle过程分析
如上图,假设,有个文件为test.log,大小为260mb,内容是一些单词,我们要对这些单词进行统计,统计每个每个单词出现的总次数,称之为:wordcount,下面我们分析分析mapreduce流程是怎么走的 1 Splitting splitting阶段是对我们的文件进行拆分,正常的block块默认是128m,我们文件大小为260m,那么260/128=2余4,那么一般会被拆成2个128

hadoop 自带示例wordcount 详细运行步骤
因为机器学习,接触到了数据挖掘;因为数据挖掘,接触到了大数据;因为大数据,接触到了Hadoop。之前有过hadoop的简单了解,但都是基于别人提供的hadoop来学习和使用,虽然也很好用 ,终究不如自己的使用起来方便 。经过这两天参考大量网上的经验,终于成功的搭建了自己的hadoop完全分布式环境。现在我把所有的安装思路、安装过程中的截图以及对待错误的经验总结出来,相信安装这个思路去做,hadoo

MapReduce简介,结构组成,运行过程,WordCount...
hadoop四大模块 ------------------- common hdfs //namenode + datanode + secondarynamenode mapred yarn //resourcemanager + nodemanager 1.MapReduce简介 Hadoop最主要的两部分Hdfs,MapReduce。其中Hdfs是用来分布式
ODPS MR开发 WordCount
参考: ODPS初始篇--客户端配置和使用:http://blog.itpub.net/26613085/viewspace-1327313/ odps dship客户端使用:http://blog.itpub.net/26613085/viewspace-1328434/ 有了上面两篇文章,就可以使用ODPS的客户端;使用ODPS DSHIP往ODPS上上传数据。 1、 在Eclipse中
hadoop1.2.1运行wordcount报错
安装步骤参见http://www.tuicool.com/articles/NBvMv2 根据上述网站中的步骤安装好hadoop1.2.1,安装过程中一定要细心,文件位置不要随意放。 我就是文件位置设置同上述网站不一样,导致后续执行wordcount不成功,放出日志如下: Meta VERSION=”1” . Job JOBID=”job_201511301937_0004” JOBNA
flink 入门学习 wordcount
概述: Apache Flink 是一个流处理和批处理的开源框架,用于处理无界和有界数据流。如果你想要使用 Flink 来统计文本中文字的数量(例如,字符数、单词数或行数),你可以通过 Flink 的 DataSet API(对于批处理)或 DataStream API(对于流处理)来实现。 以下是一个简单的示例,说明如何使用 Flink 的 DataSet API 来统计文本文件中单词的数量
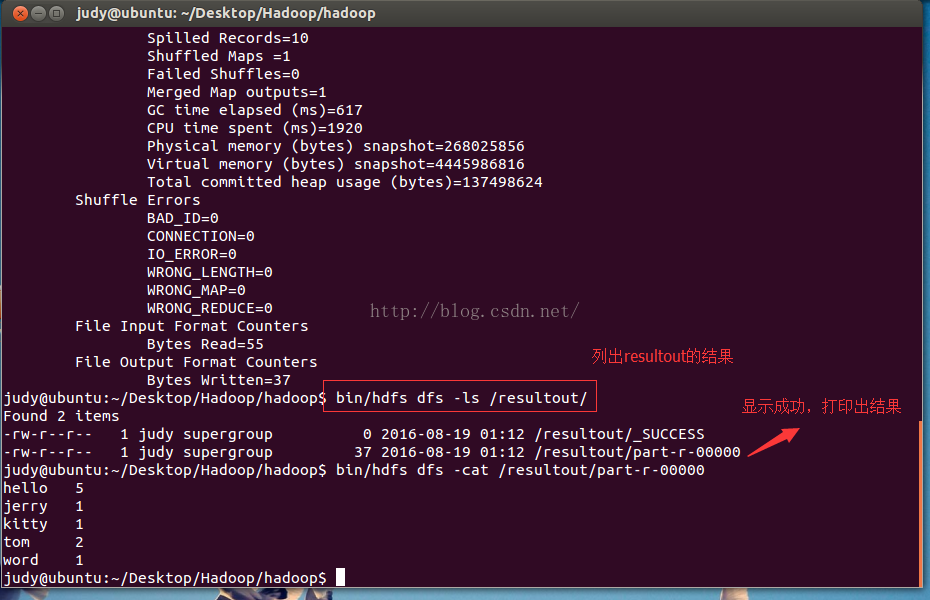
Hadoop(二)WordCount
Hadoop(二)WordCount 运行hadoop自带的wordcount实例,统计一批文本文件中单词出现的次数 1.在Hadoop下建立words文件 2.上传words至hdfs上 3.上传后查看是否成功 4.使用wordcount进行计算 5.列出结果
hadoop执行wordcount例子
1:下载hadoop。http://mirror.esocc.com/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz 2:解压. tar -zxvf 3:修改hadoop-env.sh中的JAVA_HOME配置 4:用hadoop编译wordcount A:代码位置/soft/hadoop/src/examples/
HADOOP MapReduce WordCount案列
1.安装windows hadoop 运行环境 2.IDEA 创建maven项目 导入依赖 <dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency></depend
Hadoop之自写 WordCount.class
不是井里没有水,而是你挖的不够深。不是成功来得慢,而是你努力的不够多。 昨天我们用Hadoop自带的WordCount.class统计了一个文件每个单词出现了几次。 今天我们自己写MapReduce。 第一步:写Map类 import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;imp