本文主要是介绍2.2.11 hadoop体系之离线计算-mapreduce分布式计算-案例:Reduce端实现Join,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.需求分析
2.数据展示
3.实现机制
3.1 ReduceJoinMapper:定义Mapper
3.2 ReduceJoinReducer:定义Reducer
3.3 JobMain:定义Main方法
4.运行并查看结果
4.1 准备数据
4.2 运行结果
1.需求分析
假如数据量巨大,两表的数据是以文件的形式存储在 HDFS 中, 需要用 MapReduce 程 序来实现以下 SQL 查询运算
select a.id,a.date,b.name,b.category_id,b.price from t_order a left
join t_product b on a.pid = b.id2.数据展示

3.实现机制
通过将关联的条件作为map输出的key,将两表满足join条件的数据并携带数据所来源的文件信息,发往同一个reduce task,在reduce中进行数据的串联。

代码结构:
3.1 ReduceJoinMapper:定义Mapper
package ucas.mapreduce_reduce_join;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;import java.io.IOException;public class ReduceJoinMapper extends Mapper<LongWritable,Text,Text,Text> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//首先判断数据来自哪个文件FileSplit fileSplit = (FileSplit) context.getInputSplit();String fileName = fileSplit.getPath().getName();if(fileName.equals("orders.txt")){//获取pidString[] split = value.toString().split(",");context.write(new Text(split[2]), value);}else{//获取pidString[] split = value.toString().split(",");context.write(new Text(split[0]), value);}}
}
3.2 ReduceJoinReducer:定义Reducer
package ucas.mapreduce_reduce_join;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class ReduceJoinReducer extends Reducer<Text, Text, Text, Text> {@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {String first = "";String second = "";for (Text value : values) {if (value.toString().startsWith("p")) {first = value.toString();} else {second = value.toString();}}if (first.equals("")) {context.write(key, new Text("NULL" + "\t" + second));} else {context.write(key, new Text(first + "\t" + second));}}
}
3.3 JobMain:定义Main方法
package ucas.mapreduce_reduce_join;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;public class JobMain extends Configured implements Tool {@Overridepublic int run(String[] strings) throws Exception {//创建一个任务对象Job job = Job.getInstance(super.getConf(), "mapreduce_reduce_join");//打包放在集群运行时,需要做一个配置job.setJarByClass(JobMain.class);//第一步:设置读取文件的类: K1 和V1job.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(job, new Path("hdfs://node01:8020/input/reduce_join"));//第二步:设置Mapper类job.setMapperClass(ReduceJoinMapper.class);//设置Map阶段的输出类型: k2 和V2的类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Text.class);//第三,四,五,六步采用默认方式(分区,排序,规约,分组)//第七步 :设置文的Reducer类job.setReducerClass(ReduceJoinReducer.class);//设置Reduce阶段的输出类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);//第八步:设置输出类job.setOutputFormatClass(TextOutputFormat.class);//设置输出的路径TextOutputFormat.setOutputPath(job, new Path("hdfs://node01:8020/out/reduce_join_out"));boolean b = job.waitForCompletion(true);return b ? 0 : 1;}public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();//启动一个任务int run = ToolRunner.run(configuration, new JobMain(), args);System.exit(run);}}
4.运行并查看结果
4.1 准备数据
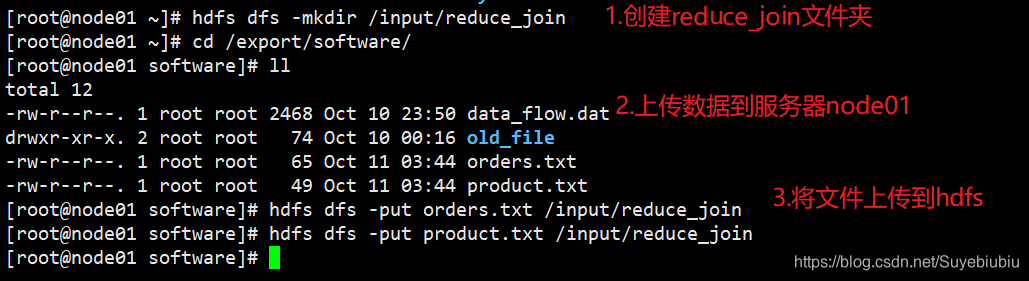
4.2 运行结果
运行命令:hadoop jar day04_mapreduce_combiner-1.0-SNAPSHOT.jar ucas.mapreduce_reduce_join.JobMain

可以看到,我们实现了联合查询操作,还是比较简单的。
这篇关于2.2.11 hadoop体系之离线计算-mapreduce分布式计算-案例:Reduce端实现Join的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


