本文主要是介绍Python人工智能应用---中文分词词频统计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.中文分词
2.循环分别处理列表
(1)分析
(2)代码解决
3.词袋模型的构建
(1)分析需求
(2)处理分析
1.先实现字符串的连接
2.字符串放到新的列表里面
4.提取高频词语
(1)STEP1. 导入模块
(2)STEP2. 创建CountVectorizer对象
(3)STEP3. 使用fit_transform()函数构造词袋模型
(4)STEP4. 使用get_feature_names()提取关键词
1.中文分词
jieba模块是处理中文分词还不错的一种方法,我们需要在自己的终端进行导入;
jieba模块里面含有许多的函数,我们使用lcut()函数,这个函数的参数就是我们要处理的文本内容,把字符串传进去以后,函数会返回列表;

分词上面的英文是jieba模块创建分词模型的过程,
模型创建成功之后,就会以列表的形式返回
2.循环分别处理列表
(1)分析

我们前面已经把评价的内容以列表的形式放到了data这个变量里面,我们进行中文分词的时候,需要取出每个评论进行分词统计,而评论是data里面的小列表的第一个元素,我们可以使用for循环,对里面的每个列表的第一个元素---评论进行分词处理;
(2)代码解决
这个地方文件打开的时候会遇到各种问题,我们可以查阅资料解决,例如编码的方式,范围,忽略,转义字符等等;
open里面的文件路径一定是自己的电脑的文件路径,不可以直接进行复制;
# 导入csv模块
import csv# 使用open()函数打开数据集
file = open("C:\\Users\\32585\\Desktop\\yequ\\TVComments.csv","r",encoding='gb18030',errors="ignore")
# 使用csv.reader()函数读取数据集
reader = csv.reader(file)# 创建一个空列表data
data = []# 使用for循环遍历reader,将遍历的数据存储到变量info中
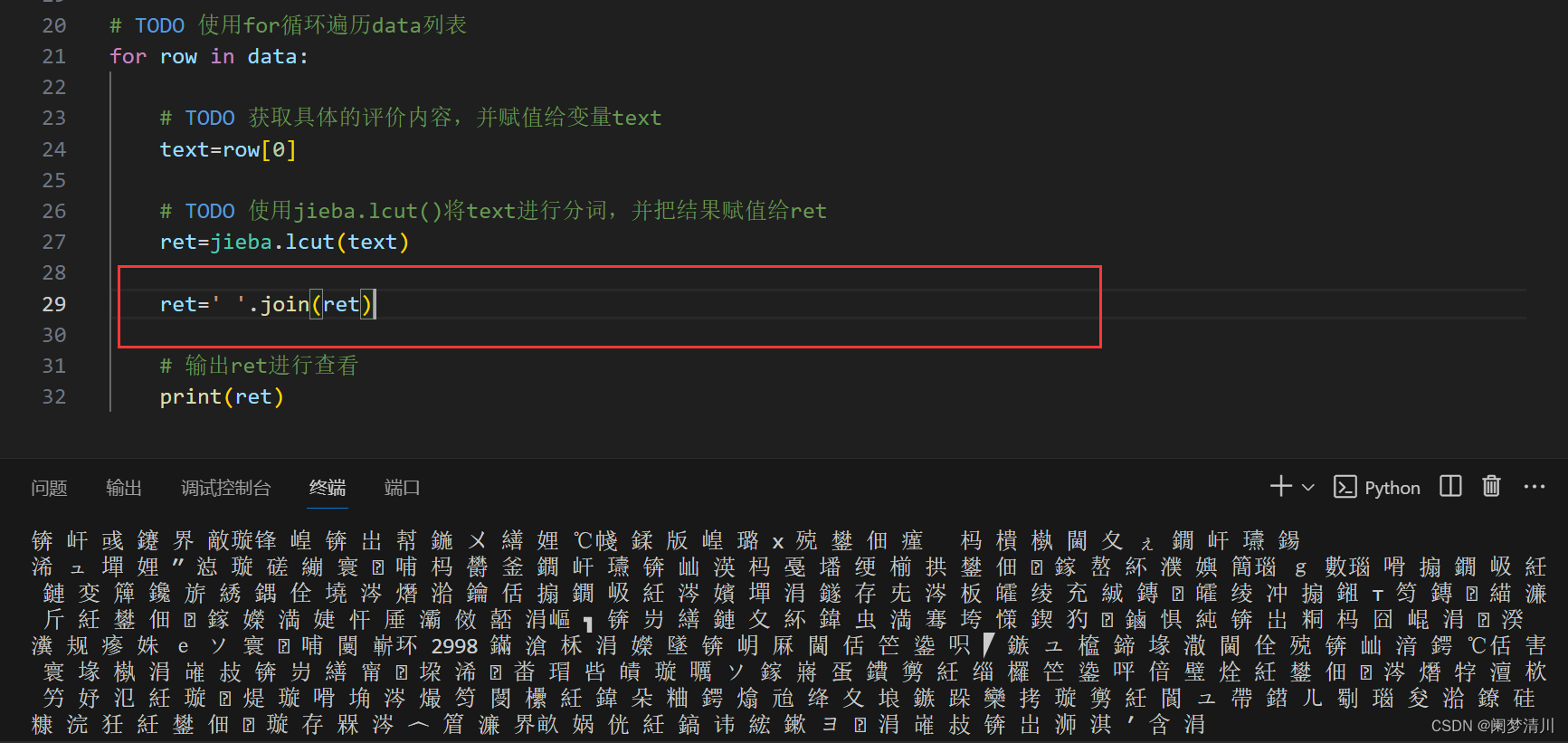
for info in reader:# 使用append()函数,将info逐一添加到data列表中data.append(info)# TODO 导入jieba模块
import jieba# TODO 使用for循环遍历data列表
for row in data:# TODO 获取具体的评价内容,并赋值给变量texttext=row[0]# TODO 使用jieba.lcut()将text进行分词,并把结果赋值给retret=jieba.lcut(text)# 输出ret进行查看print(ret)因为文件容量比较大,所以生成的分词比较多,如图所示:

3.词袋模型的构建
(1)分析需求
经过jieba,lcut函数的处理之后,就生成了一系列的字符串列表:有多少条评论,就会生成多少条评论,但是我们后续的词袋模型只能传进去一个字符串,所以我们要把生成的诸多字符串转换成一个字符串;
(2)处理分析
我们的解决方案就是把每个列表里面的字符串使用空格进行合并,添加到一个新的列表里面;
下面是具体的实现:
1.先实现字符串的连接
把小的列表里面的内容使用空格合并成为一个字符串,我们这里可以使用join()函数:

按照上面的示例,在这个题上面,具体的代码就只需要在原来的基础上面进行修改就可以了:
2.字符串放到新的列表里面

4.提取高频词语
机器学习模块sklearn可以帮助我们处理这个问题,这个模块里面含有许多的函数,可以直接进行评论的提取以及高频词的统计;sklearn不是内置的模块,需要我们在本地进行安装
(1)STEP1. 导入模块
我们需使用
from...import...,从 sklearn.feature_extraction.text 模块中导入 CountVectorizer 类。
(2)STEP2. 创建CountVectorizer对象
导入模块后,需要创建一个CountVectorizer对象,这样才能调用CountVectorizer类里面的某个方法或属性。
由于我们只想从评价中筛选出前15个出现频率最高的词语,所以传入了max_features=15。
# 从sklearn.feature_extraction.text中导入CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer# 创建CountVectorizer对象,并存储在vect中
vect = CountVectorizer(max_features=15)
(3)STEP3. 使用fit_transform()函数构造词袋模型
X = vect.fit_transform(word)这个里面的word就是我们前面新建的列表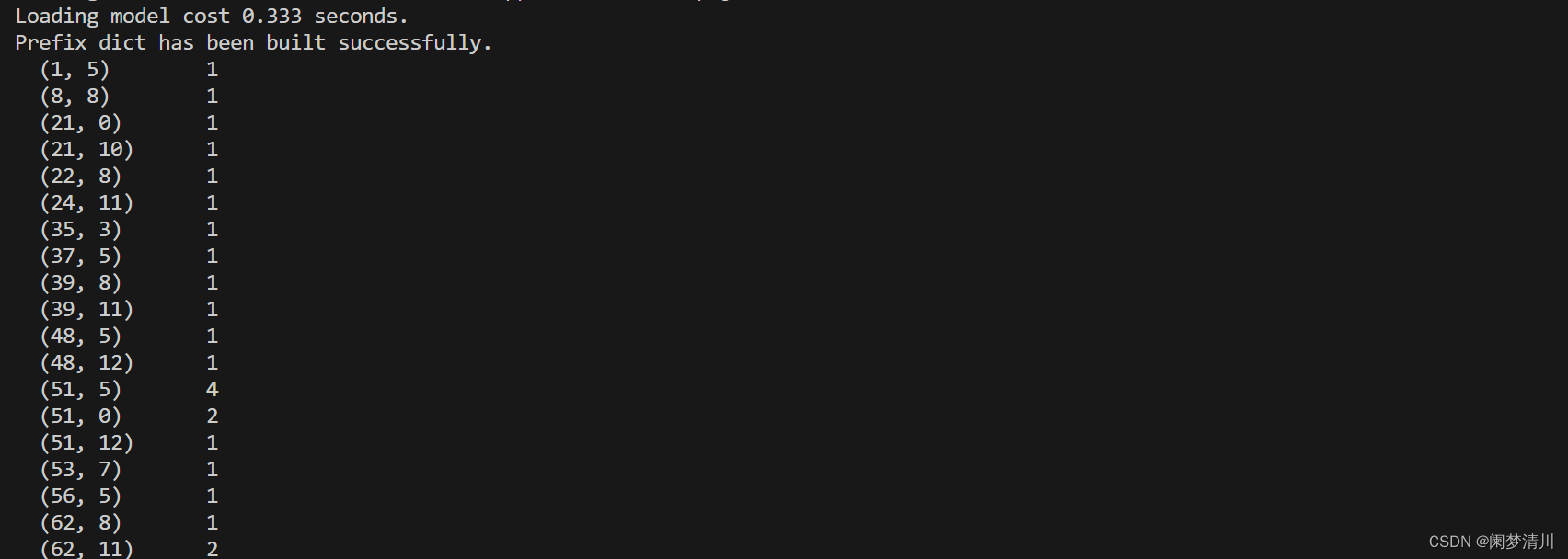
这个里面的生成结果全部是数字,我们来解释一下:

(4)STEP4. 使用get_feature_names()提取关键词
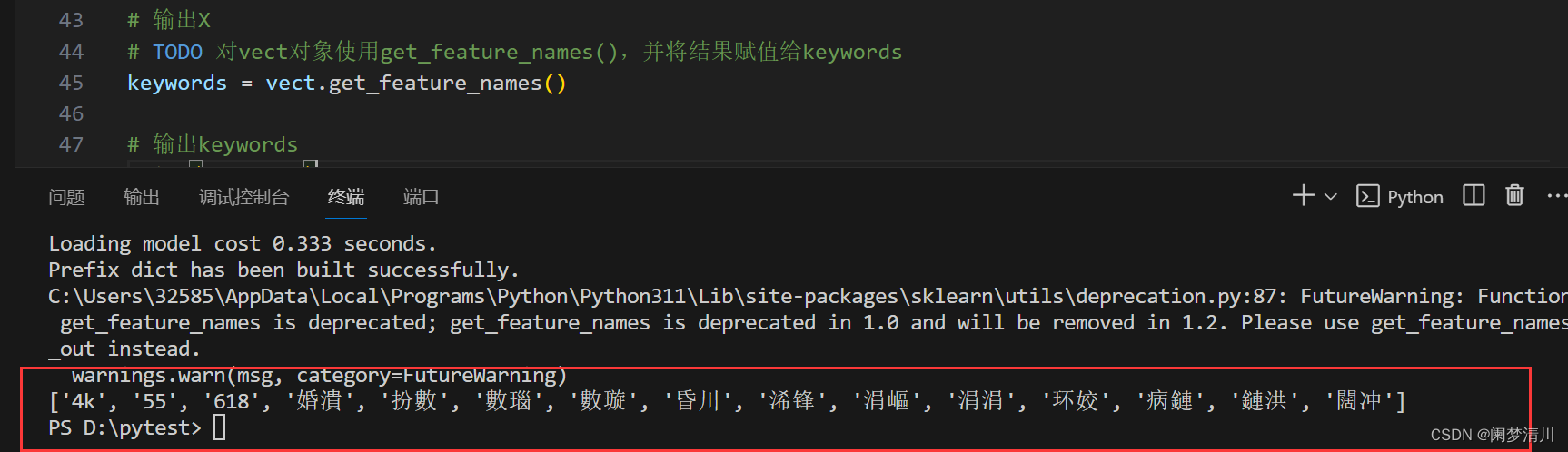
# TODO 对vect对象使用get_feature_names(),并将结果赋值给keywords
keywords = vect.get_feature_names()# 输出keywords
print(keywords)最后的返回结果就是高频词:
这篇关于Python人工智能应用---中文分词词频统计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




