本文主要是介绍hadoop编程之词频统计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据集实例

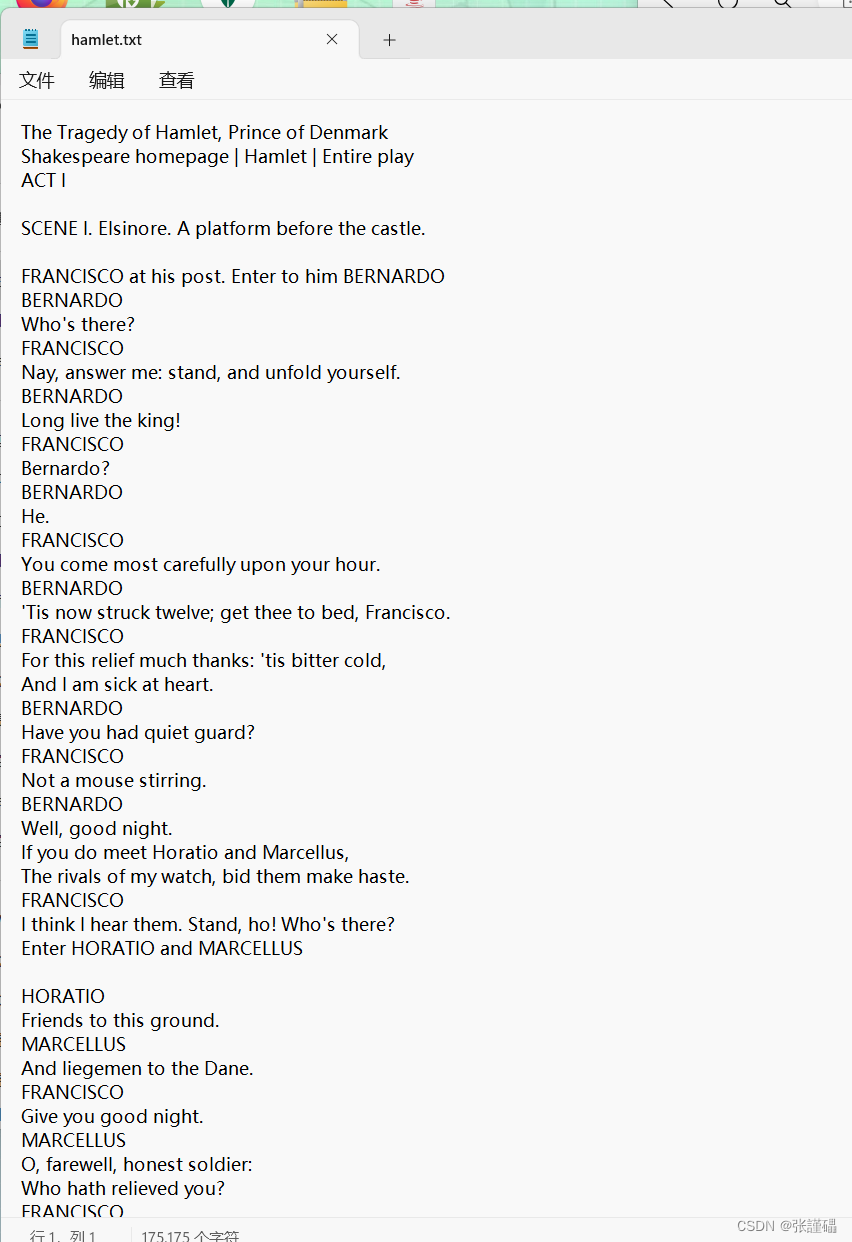
java代码,编程
实例
我们要先创建三个类分别为WordCoutMain、WordCoutMapper、WordCoutReducer这三个类
对应的代码如下
WordCoutMain
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountMain{public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(WordCountMain.class);job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));job.waitForCompletion(true);}}WordCoutMapper
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key1, Text value1, Context context)
throws IOException, InterruptedException {String data = value1.toString();String[] words = data.split(" ");for(String w:words){context.write(new Text(w),new LongWritable(1));}}
}
WordCoutReducer
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;public class WordCountReducer extends Reducer<Text, LongWritable,Text, LongWritable> {
@Override
protected void reduce(Text k3, Iterable<LongWritable> v3,Context context) throws IOException,InterruptedException {long total = 0;for(LongWritable v:v3){total+=v.get();}context.write(k3, new LongWritable(total));}
}对应的使用命令
hadoop jar 1.jar ch01.WordCountMain /user/data/input/hamlet.txt /user/data/output/ch1hadoop jar 包名 引用主类 输入文件路径 输出文件路径结果展示
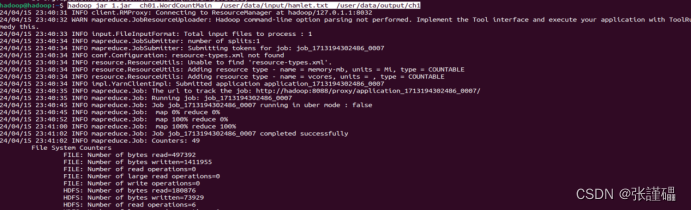
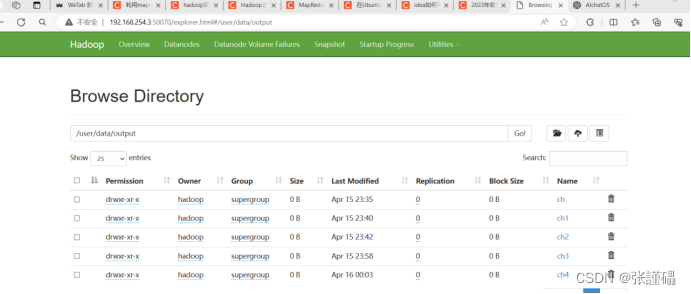

学习链接:
在Ubuntu上用mapreduce进行词频统计(伪分布式)_mapreduce怎么统计txt文件词频终端-CSDN博客
利用mapreduce统计部门的最高工资_使用mapreduce查询某个部门中薪资最高的员工姓名,如果输出结果的格式为“薪资 员-CSDN博客
hadoop编程之工资序列化排序-CSDN博客
hadoop编程之部门工资求和-CSDN博客
hadoop编程之词频统计-CSDN博客
这篇关于hadoop编程之词频统计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






