本文主要是介绍hive词频统计---文件始终上传不来,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
准备工作:
文件内容:
创建数据库及表
将文件上传到:上传到/user/hive/warehouse/db1.db/t_word目录下
hive里面查询,始终报错:(直接查询也是不行)
解决方案:
准备工作:
xshell连接主机,启动hadoop集群,启动MySQL服务已就绪
文件内容:
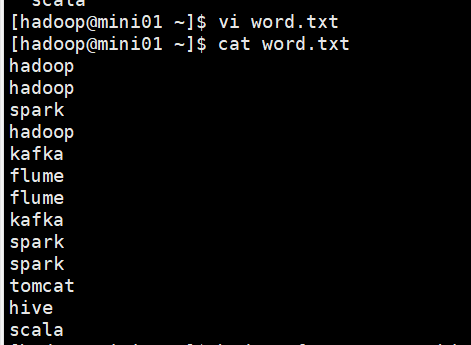
创建数据库及表

将文件上传到:上传到/user/hive/warehouse/db1.db/t_word目录下

尝试使用Hive的LOAD DATA语句加载数据到表:
LOAD DATA INPATH '/user/hive/warehouse/db1.db/t_word/word.txt' INTO TABLE t_word;hive里面查询,始终报错:(直接查询也是不行)
hive> LOAD DATA INPATH '/user/hive/warehouse/db1.db/t_word/word.txt' INTO TABLE t_word;
FAILED: SemanticException Line 1:17 Invalid path ''/user/hive/warehouse/db1.db/t_word/word.txt'': No files matching path hdfs://mini01:8020/user/hive/warehouse/db1.db/t_word/word.txt解决方案:
先创建目录,再将文件上传到目录下,再去加载到数据库表中,最后再去查询即可;
hadoop fs -mkdir -p /user/hive/warehouse/db1.db/t_wordhadoop fs -put word.txt /user/hive/warehouse/db1.db/t_word/LOAD DATA INPATH '/user/hive/warehouse/db1.db/t_word/word.txt' INTO TABLE t_word;
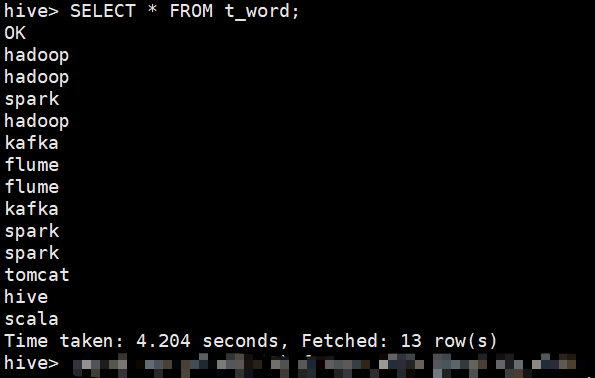
注意:文件重复要删除
这篇关于hive词频统计---文件始终上传不来的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





