维基百科专题
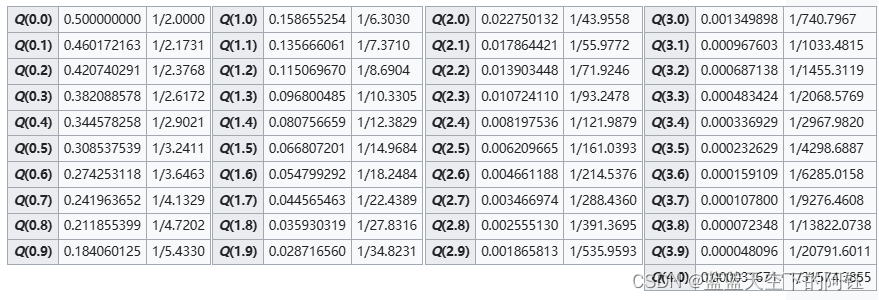
Q-function Q函数 (维基百科)
如有翻译或者理解上的错误烦请指出 Q函数 定义和基本特性边界和近似逆Q函数Q函数的值高维度多一嘴 Marcum Q函数MARCUM Q函数高斯Q函数区别和联系 参考文献 Q函数与正态分布的累积分布函数相关,并且是误差函数的补函数,这使得Q函数在应用数学和物理学中非常重要。 在统计学中,Q函数是标准正态分布的尾部分布函数[1][2]。换句话说,Q(x)是一个正态(高斯)随

究竟什么是CLR(翻译自维基百科)
做.net的事情的时候,都会与CLR打交道,那么究竟什么是CLR呢? CLR的全称是The Common Language Runtime 公共语言运行时,是微软.net框架虚拟机的组成部分,管理.net程序的执行。即时编译进程会把已经编译好的代码转换为CPU的机器指令然后执行。CLR提供了额外的服务包括内存管理、类型安全、异常处理、垃圾回收、安全和线程管理。为.net框架写的所有程序,不管什么

维基百科推广7个数字成功吸引千万流量-华媒舍
维基百科是全球最大的免费在线百科全书,内容丰富全面,几乎每个人都会在上面寻找所需的知识。要让自己的维基百科页面获得高流量和广泛传播,并不是易事。我们将揭秘7个数字成功吸引千万流量的方法,帮助你提升维基百科页面的知名度和影响力。 1. 1000 维基百科页面的质量和内容对于吸引流量来说至关重要。在编辑和编写维基百科页面时,确保你的页面至少有1000个字。较长的页面能提供更详尽的信息,同时也能

维基百科、百度百科和搜狗百科词条的创建流程
随着网络的发展,百度百科、搜狗百科、维基百科等百科网站已经成为大众获取知识的重要途径。因为百科具有得天独厚的平台优势,百科上的信息可信度高,权威性强。所以百科平台也成为商家的必争之地。这里小马识途聊聊如何创建百度百科、搜狗百科和维基百科词条。 一、创建维基百科词条 1.注册维基账号 在创建维基百科词条之前,你需要先注册一个维基账号。如果你已经有了维基账号,可以直接登录维基百科。 2

维基百科推广方法及注意事项解析-华媒舍
1. 维基百科 维基百科是一个自由而开放的在线百科全书,由志愿者共同创建和编辑。它是全球最大的百科全书,包含了广泛的主题和知识。作为一个公共平台,维基百科是广告和宣传的禁区,但它可以是一个有效的推广工具,帮助您获取更多客户。 2. 增加品牌曝光 在维基百科上创建并完善关于您品牌或企业的页面,有助于增加品牌曝光度。页面中包含与品牌相关的详细信息和历史,可以让用户更深入了解您的产品或服务。而

Gensim-维基百科中文语料LDA,LSI实验记录
介绍 本文描述了获取和处理维基百科中文语料过程,以及使用Gensim对语料进行主题建模处理的例子。 准备语料库 首先,从https://dumps.wikimedia.org/zhwiki/latest/下载所有维基百科文章语料库(需要文件zhwiki-latest-pages-articles.xml.bz2或zhwiki-YYYYMMDD-pages-articles.xml)。这个文件

回调函数/Callback(维基百科)
原文: Callback (computer programming) In computer programming, a callback is any executable code that is passed as an argument to other code, which is expected to call back (execute) the argument at a

FAT - 维基百科,自由的百科全书
维基百科,自由的百科全书 文件配置表(英语:File Allocation Table,首字母缩略字:FAT),是一种由微软发明并拥有部分专利[2] 的文档系统,供MS-DOS使用,也是所有非NT核心的微软窗口使用的文件系统。 FAT文档系统考虑当时电脑性能有限,所以未被复杂化,因此几乎所有个人电脑的操作系统都支援。这特性使它成为理想的软碟和记忆卡文件系统,也适合用作不同操作系统中的资料

iptv与ott (转自维基百科)
英语就是准确啊!红色部分是我自己的理解。 OTT (Over the Top Technology) and IPTV (Internet Protocol Television) are two growing technology mediums(实际上就是两种机制) in the media(这个媒体指代媒体内容) distribution industry
把获取的维基百科主页词条及链接存入mysql数据库
wiki2mysql.py from urllib.request import urlopenfrom bs4 import BeautifulSoupimport reimport pymysql.cursors#请求url并把结果用utf-8编码resp = urlopen("https://en.wikipedia.org/wiki/Main_Page").read().dec
获取维基百科主页所有词条及链接
wiki.py from urllib.request import urlopenfrom bs4 import BeautifulSoupimport re# 获取维基百科主页所有词条及链接#请求url并把结果用utf-8编码resp = urlopen("https://en.wikipedia.org/wiki/Main_Page").read().decode("utf-8"
今天编辑了 维基百科 条目
http://en.wikipedia.org/wiki/Bluetooth_stack 添加条目 2.2 BlueCore Host Software (BCHS) PS: 原来iPhone 也是用的 BlueMagic3.0 ...

维基百科文章爬虫和聚类:高级聚类和可视化
一、说明 维基百科是丰富的信息和知识来源。它可以方便地构建为带有类别和其他文章链接的文章,还形成了相关文档的网络。我的 NLP 项目下载、处理和应用维基百科文章上的机器学习算法。 在我的上一篇文章中,KMeans 聚类应用于一组大约 300 篇维基百科文章。如果没有任何预期的标签,则只能通过检查哪些文章被分组在一起以及哪个单词最常出现来接近聚类结果。结果并不令人

维基百科推广的12种方法帮你建立强大的品牌-华媒舍
维基百科是全球最大、最权威的多语言网络百科全书。它是许多人搜索信息、获取知识的首选平台,也是许多品牌建立强大影响力的重要途径。本文将介绍维基百科推广的12种方法,帮助你在维基百科上建立强大的品牌形象。 1. 准备工作 在开始维基百科推广之前,需要做一些准备工作。了解维基百科内容规范和编辑原则,确保你的推广活动符合维基百科的要求。要对品牌进行全面的研究,收集可靠的来源和证据,以支持你在维基百

假设检验(维基百科)
http://zh.wikipedia.org/wiki/Wikipedia:首页 假设检验是推论统计中用于检验统计假设的一种方法。而“统计假设”是可通过观察一组随机变量的模型进行检验的科学假说。[1]我们一旦能估计未知参数,就会希望根据结果对未知的真正参数值做出适当的推论。 统计上对参数的假设,就是对一个或多个参数的论述。而其中我们欲检验其正确性的为零假设(null hypoth
唐|01python数据分析与机器学习|26使用Gensim库构造中文维基百科数据词向量模型
gensim的使用 from gensim.models import word2vec #掉包 sentences = [s.split() for s in raw_sentences] #分词 model = word2vec.Word2Vec(sentences,min_count=1) #引包 min_c
如何显示维基百科图片
方法1: 登陆维基百科->选择“参数设置”->选择“小工具”->勾选“中国大陆专用工具”中的“显示被ISP封锁的图片”。 然后保存设置即可。 方法2: 将下面代码: @echo offfind "91.198.174.234 upload.wikimedia.org" %windir%\system32\drivers\etc\hosts > nulif %errorleve

维基百科文章爬虫和聚类【二】:KMeans
维基百科是丰富的信息和知识来源。它可以方便地构建为带有类别和其他文章链接的文章,还形成了相关文档的网络。我的 NLP 项目下载、处理和应用维基百科文章上的机器学习算法。 一、说明 在我的上一篇文章中,展示了该项目的轮廓,并奠定了其基础。首先,维基百科爬虫对象按名称搜索文章,提取标题、类别、内容和相关页面,并将文章存储为纯文本文件。其次,语料库对象处理完整的文章集,允许方便

语料库技术与应用—基于维基百科构建日语平行语料并爬取谷歌翻译语音(mp3)
准备:wikipedia-parallel-titles项目(老师给的) This document describes how to use these tools to build a parallel corpus (for a specific language pair) based on article titles across languages in Wik

【数据分享】维基百科Wiki负面有害评论(网络暴力)文本数据多标签分类挖掘可视化...
原文链接:http://tecdat.cn/?p=8640 讨论你关心的事情可能很困难。网络暴力骚扰的威胁意味着许多人停止表达自己并放弃寻求不同的意见(查看文末了解数据免费获取方式)。平台努力有效地促进对话,导致许多社区限制或完全关闭用户评论(点击文末“阅读原文”获取完整代码数据)。 数据简介 AI团队正在研究工具,以帮助提高在线评论互动。一个重点领域是研究负面的在线行为,如有害评论(即粗鲁、
Jenkins + Github持续集成构建Docker容器,维基百科人工自能(AI)模块
本文分两部分,第一部分是手动计划任务的方式构建Github上的Docker程序,第二部分是用Github webhook Trigger一个自动构建任务。 Jenkins采用2.5版本Docker采用1.7.1代码托管使用的Github官网系统为IBM Bluemix提供的Cent6.7,服务器地址在美国南加州 1.1 创建一个Freestyle Project, let's say jenki

ARIMA 时间序列5: 维基百科词条EDA
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport re%matplotlib inlinetrain = pd.read_csv('train_1.csv').fillna(0)print(train.shape)train.head() 打印info信息看到数据大小 609.8+
![[NLP]基于维基百科中文语料库的Word2Vec模型训练](https://img-blog.csdnimg.cn/20191205105946298.png)
[NLP]基于维基百科中文语料库的Word2Vec模型训练
说明:该博客代码参考于 参考博客:使用中文维基百科语料库+opencc+jieba+gensim训练一个word2vec模型 参考博客:使用中文维基百科训练word2vec模型 零、 模型训练环境 Windows10-X64 、 python2.7 、 python3.6pip install jiebapip install gensim 一、下载维基百科语料库 数据下载地址 该博客使用