本文主要是介绍Gensim-维基百科中文语料LDA,LSI实验记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
本文描述了获取和处理维基百科中文语料过程,以及使用Gensim对语料进行主题建模处理的例子。
准备语料库
首先,从https://dumps.wikimedia.org/zhwiki/latest/下载所有维基百科文章语料库(需要文件zhwiki-latest-pages-articles.xml.bz2或zhwiki-YYYYMMDD-pages-articles.xml)。这个文件的大小约为1GB多,包含中文维基百科的所有文章(压缩版本)。
将文章转换为纯文本,并将结果存储为稀疏TF-IDF向量。 在Python中,这是很容易做的,我们甚至不需要将整个存档解压缩到磁盘。 在gensim中包含一个脚本,只需执行以下操作:
python -m gensim.scripts.make_wiki zhwiki-latest-pages-articles.xml.bz2 zhwiki在bash中运行下面命令可查看make_wiki脚本的用法:
python -m gensim.scripts.make_wiki然后会生成下面六个文件:
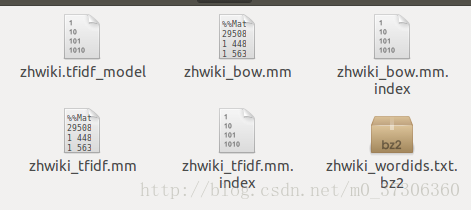
Latent Semantic Analysis实验:
实验用到前面生成的二个文件:zhwiki_wordids.txt和zhwiki_tfidf.mm。
TrainLSI()方法训练模型,然后保存。
LSIShow()方法显示结果。
实验代码
def TrainLSI():# load id->word mapping (the dictionary)zhwiki_id2word = corpora.Dictionary.load_from_text("zhwiki_wordids.txt")# load corpus iterator,即文本库zhwiki_corpus = corpora.MmCorpus("zhwiki_tfidf.mm")zhiwiki_lsi_model = models.lsimodel.LsiModel(corpus=zhwiki_corpus, id2word=zhwiki_id2word, num_topics=400)zhiwiki_lsi_model.save('zhiwiki_lsi_model.model')def LSIShow():zhiwiki_lsi_model = models.lsimodel.LsiModel.load('zhiwiki_lsi_model.model')pp.pprint(zhiwiki_lsi_model.print_topics(5))结果:显示前五个主题的词分布:
[(0,'0.837*"小行星" + 0.271*"林肯近地小行星研究小组" + 0.271*"索科罗" + 0.234*"基特峰" + ''0.232*"太空监视" + 0.096*"萊蒙山巡天" + 0.096*"莱蒙山" + 0.087*"近地小行星追踪" + 0.081*"帕洛马山" ''+ 0.053*"卡特林那巡天系统"'),(1,'0.796*"zh" + 0.280*"jpg" + 0.270*"hans" + 0.254*"file" + 0.251*"hk" + ''0.166*"tw" + 0.102*"hant" + 0.082*"cn" + 0.072*"px" + 0.038*"image"'),(2,'0.665*"jpg" + 0.601*"file" + -0.359*"zh" + -0.123*"hans" + -0.099*"hk" + ''0.087*"image" + -0.072*"tw" + 0.047*"px" + -0.045*"hant" + 0.042*"公里"'),(3,'0.972*"px" + -0.076*"jpg" + -0.064*"file" + 0.062*"公里" + -0.057*"zh" + ''0.042*"isbn" + 0.037*"平成" + 0.031*"align" + 0.028*"飾演" + 0.027*"民国"'),(4,'0.920*"飾演" + 0.196*"mbc" + 0.194*"kbs" + 0.189*"sbs" + 0.050*"tvn" + ''-0.048*"px" + 0.048*"isbn" + 0.043*"電視劇" + 0.040*"電影" + 0.034*"演出作品"')]Process finished with exit code 0Latent Dirichlet Allocation实验:
实验用到前面生成的二个文件:zhwiki_wordids.txt和zhwiki_tfidf.mm。
TrainLda()方法训练模型,然后保存。
LdaShow()方法显示结果。
代码:
def TrainLda():zhwiki_id2word = corpora.Dictionary.load_from_text("zhwiki_wordids.txt")zhwiki_corpus = corpora.MmCorpus("zhwiki_tfidf.mm")zhwiki_lda = models.ldamodel.LdaModel(corpus= zhwiki_corpus, id2word= zhwiki_id2word, num_topics=100)zhwiki_lda.save("zhwiki_lda.model")def LdaShow():zhwiki_ldamodel = models.ldamodel.LdaModel.load('zhwiki_lda.model')pp.pprint(zhwiki_ldamodel.print_topics(5))return zhwiki_ldamodel# zhwiki_ldamodel.print_topic(20)结果:显示前五个主题的词分布:
[(59,'0.096*"每天" + 0.026*"主要演員" + 0.019*"原唱" + 0.012*"level" + 0.011*"夾層" + ''0.011*"note" + 0.009*"total" + 0.009*"smart" + 0.008*"翻譯" + 0.007*"許廷鏗"'),(0,'0.046*"ss" + 0.036*"funet" + 0.025*"hesperioidea" + 0.019*"papiionoidea" + ''0.017*"fruhstorfer" + 0.016*"指名亞種" + 0.014*"tolweb" + 0.013*"nymphalidae" + ''0.012*"分佈於新熱帶界" + 0.011*"ea"'),(99,'0.061*"link" + 0.026*"另见" + 0.023*"制作" + 0.015*"湖南卫视" + 0.015*"巴黎地鐵link" + ''0.015*"巴黎地鐵" + 0.012*"导演" + 0.011*"形式" + 0.011*"規模" + 0.009*"综艺节目"'),(56,'0.172*"jpg" + 0.130*"file" + 0.070*"大字" + 0.037*"image" + 0.026*"区域图" + ''0.017*"svg" + 0.015*"png" + 0.013*"thumb" + 0.010*"公里" + 0.009*"号拍摄"'),(67,'0.041*"正月" + 0.031*"七月" + 0.030*"十一月" + 0.029*"三月" + 0.028*"二月" + ''0.028*"四月" + 0.027*"十月" + 0.026*"五月" + 0.026*"六月" + 0.026*"九月"')]Process finished with exit code 0
使用训练好的LDA模型,对于新来的文档,可以进行主题预测:
代码:
def LDAPredict():lda_model = LdaShow()Dict = corpora.Dictionary.load_from_text("zhwiki_wordids.txt")test_doc = "实验室提供了很多中文语料的下载 全网新闻数据,来自若干新闻站点2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据,提供URL和正文信息。"test_doc = list(jieba.cut(test_doc))# 文档转换成bowdoc_bow = Dict.doc2bow(test_doc)# 得到新文档的主题分布doc_lda = lda_model[doc_bow]pp.pprint(doc_lda)
结果:第一列表示主题,第二列表示属于改主题的概率。
[(5, 0.089595874435511064),
(20, 0.04391304347826077),
(22, 0.084464754997332497),
(23, 0.043913043478260791),
(30, 0.12636274578275353),
(35, 0.044034901794703332),
(38, 0.043913043478260784),
(53, 0.046039943409513104),
(61, 0.26428438827583728),
(77, 0.043913043478260784),
(85, 0.03423113865080693),
(91, 0.043913043478260784),
(93, 0.053594948305714644)]
问题:
刚开始使用zhwiki_wordids.txt训练的时候,遇到错误。
原因是zhwiki_wordids.txt文件的第一行不是id ->map的格式,删掉之后,解决问题。
参考:http://radimrehurek.com/gensim/wiki.html
这篇关于Gensim-维基百科中文语料LDA,LSI实验记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





