语料专题

word2vec 自己训练中文语料
(1) 准备文本 可以用爬虫爬,也可以去下载,必须是全文本。 (2)对数据进行分词处理 因为英文但此只见是空格所以不需要分词,二中文需要分词, 中文分词工具还是很多的,我自己常用的: - 中科院NLPIR - 哈工大LTP - 结巴分词 注意:分词后保存的文件将会作为word2vec的输入文件进行训练 (3)训练与实验 python 需要先安装gensim,参考http://bl

主题模型Gensim入门系列之二:语料和向量空间
系列目录: (1)主题模型Gensim入门系列之一:核心概念 (2)主题模型Gensim入门系列之二:语料和向量空间 (3)主题模型Gensim入门系列之三:主题和变换 (4)主题模型Gensim入门系列之四:文本相似度查询 ———————————————————————————— 本文主要介绍将文档(Document)转换为向量空间,同时介绍语料流(corpus streami

利用AI大模型,将任何文本语料转化为知识图谱,可本地运行!
几个月前,基于知识的问答(KBQA)还是一个新奇事物。 现在,对于任何 AI 爱好者来说,带检索增强生成(RAG)的 KBQA 就像小菜一碟。看到自然语言处理(NLP)的可能性领域由于大型语言模型(LLMs)的发展而如此迅速扩展,真是令人着迷。 而且,它每天都在变得更好。 01 摘 要 知识图谱(KG)或任何图谱由节点和边组成。知识图谱的每个节点代表一个概念,每条边是这样一对概念之间的关系

语料平台开发经验总结
1、表结构设计,尽量不要有冗余字段; 2、在DAO层多表关联操作是,先查询要做NPE的异常处理; 3、在Controller层对业务编码,逻辑尽量简洁,组装数据即可,直接传入Facade接口层,生产者进行功能逻辑处理; 4、在JS上面Long型需要转为String类型处理,不然Long类型会丢失精度;

亮相CCIG2024,合合信息文档解析技术破解大模型语料“饥荒”难题
近日,2024中国图象图形大会在古都西安盛大开幕。本届大会由中国图象图形学学会主办,空军军医大学、西安交通大学、西北工业大学承办,通过二十多场论坛、百余项成果,集中展示了生成式人工智能、大模型、机器学习、类脑计算等多个图像图形领域的进展。 大模型技术正随着科技革新实现广泛应用,满足多行业图像处理需求。大会期间,由CSIG文档图像分析与识别专委会与上海合合信息科技股份有限公司(简称“合合信

《python自然语言处理》笔记---chap2 获得文本语料和词汇资源(续)
---------我可以投诉吗?不知道为什么上午接着写了好多,明明发表了,可是还是没了,是不是不能写那么多?----- 载入你自己的语料库 待续。。。 2.3 更多关于python:代码重用 使用文本编辑器创建程序 函数 局部变量,不能在函数体外访问。函数在被“调用”之前不会做任何事情。 一个Python 函数:这个函数试图生成任何英语名词的复数形式。 #coding:utf-8
ngram模型中文语料实验step by step(1)-分词与统计
ngram模型是统计语言的最基本的模型了,这里将给出用中文语料做实验建立ngram模型的个人总结,主要参考sun拼音2.0的代码以及有点意思拼音输入法,会参考srilmstevejian.cublog.cn。我会尽量逐步完成所有的实验总结。 分词与统计 对于中文语料和英文不同需要我们先进行分词,当然如果是切分好空格隔开的语料就简单许多。假设是普通的语料,sun拼音的做法是采用正向最大匹配分词

ngram模型中文语料实验step by step(2)-ngram模型数据结构表示及建立
n元ngram模型本质上就是trie树的结构 ,逐层状态转移。在sun拼音中是采用的是逐层按照顺序用vector表示,查找的时候逐层二分查找。sun拼音的建立ngram模型的方法也是以按照字典序排好序的<ngram元组,次数>序列作为输入建立起来的。 利用顺序存储+二分查找应该是最节省空间的了。但是效率要受一定影响。其余的trie树实现包括可以利用map(hash_map更耗费空间一点),su

Python数据挖掘项目开发实战:如何把新闻语料分类
注意:本文的下载教程,与以下文章的思路有相同点,也有不同点,最终目标只是让读者从多维度去熟练掌握本知识点。 Python数据挖掘项目开发实战_新闻语料分类_编程案例解析实例详解课程教程.pdf Python数据挖掘项目开发实战:如何把新闻语料分类在这个信息爆炸的时代,我们每天都被海量的新闻所包围。如何从这些纷繁复杂的新闻中快速准确地找到我们感兴趣的内容呢?这就需要我们利用数据挖掘技术,对新
Gensim-维基百科中文语料LDA,LSI实验记录
介绍 本文描述了获取和处理维基百科中文语料过程,以及使用Gensim对语料进行主题建模处理的例子。 准备语料库 首先,从https://dumps.wikimedia.org/zhwiki/latest/下载所有维基百科文章语料库(需要文件zhwiki-latest-pages-articles.xml.bz2或zhwiki-YYYYMMDD-pages-articles.xml)。这个文件

SnowNLP使用自定义语料进行情感分类模型训练
SnowNLP是什么? SnowNLP是一个功能强大的中文文本处理库,它囊括了中文分词、词性标注、情感分析、文本分类、关键字/摘要提取、TF/IDF、文本相似度等诸多功能,像隐马尔科夫模型、朴素贝叶斯、TextRank等算法均在这个库中有对应的应用。 官方源码文档是这样写的: SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现

AI聊天伴侣的语料采集大揭秘:OpenCV如何轻松识别聊天图片?
最近,负责元宇宙中AI聊天伴侣的语料数据采集,这些数据主要用于AI虚拟角色聊天的训练和测试。虽然语料获取有多种渠道,但由于部分数据涉及隐私,这里就不多说了(感兴趣的朋友可以私聊我)。今天,我将详细讲解如何利用OpenCV轻松识别真实的聊天图片。 在这个过程中,我主要涉及了一系列操作,包括OpenCV如何读取PDF多个分页图片、如何对图片进行水印过滤和异常文字剔除、如何识别聊天文本框和聊天角色
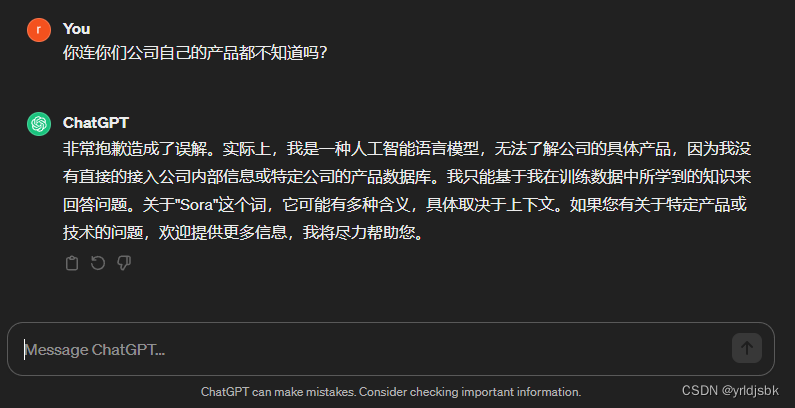
openai公司的chatgpt-3.5参数库内还未增加sora的语料信息
openai公司的chatgpt-3.5参数库内还未增加sora的语料信息!我想通过openai公司的chatgpt3.5来了解一下关于sora的技术信息,结果呢,它竟然回答不知道sora是什么。看来,sora的语料库信息还未来得及加入chatgpt3.5的训练模型中。 如图,chatgpt3.5回答了,说它不知道。 以后我会陆续和大家分享,各种前言的大数据模型技术信息,以及和人工智

一种没有语料字典的分词方法
2019独角兽企业重金招聘Python工程师标准>>> 前几天在网上闲逛,看到一篇美文,说的是怎么在没有语料库的情况下从文本中提取中文词汇,理论部分讲得比较多,但都还是很浅显易懂的,其中涉及一部分信息论的理论,其实只要大学开过信息论这门课的话,看起来还是挺简单的。 信息论我忘得差不多了,但是其中主要的内容还记得,信息论最主要的就是信息其实是可以度量的,一个事件包含的信息和它发
用NLTK对英文语料做预处理,用gensim计算相似度
“这篇是研一自己摸索的代码,当时就有点过时,但还是具有一定的参考价值。仅作记录,意义不大。”——题记 来自这里 提示性信息很赞 参考52nlp(三) (二) (一) 对所有语料进行分词(tokenizing)和词干化(stemming) 利用 tf-idf 将语料库转换为向量空间(vector space)计算每个文档间的余弦距离(cosine distance
python四级词汇采集_python+NLTK 自然语言学习处理四:获取文本语料和词汇资源
在前面我们通过from nltk.book import *的方式获取了一些预定义的文本。本章将讨论各种文本语料库 1 古腾堡语料库 古腾堡是一个大型的电子图书在线网站,网址是http://www.gutenberg.org/。上面有超过36000本免费的电子图书,因此也是一个大型的预料库。NLTK也包含了其中的一部分 。通过nltk.corpus.gutenberg.fileids()就可以查
Wikipedia corpus英文语料处理,获得原文
我们在预训练word vector或其他预训练任务时,需要大量的语料数据,Wikipedia开放了英文语料,大约11G:wiki英文语料下载链接 该语料库是.bz2格式,但是不能直接解压,需要使用工具处理,我们介绍两种常用的处理工具,gensim和wikiextractor。 Gensim gensim提供了处理工具,但是只能够获得文章的词列表,丢失了段落句子以及标点符号。 from g

最全NLP语料资源集合及其构建现状
作者刘焕勇,语言学硕士,目前就职于中国科学院软件研究所,主要从事信息抽取,知识图谱,情感分析, 社会计算等自然语言处理研发工作,兴趣包括:语言资源构建、信息抽取与知识图谱、舆情监测与社会计算。 本项目包含中文自然语言处理的语料集合,包括语义词、领域共时、历时语料库、评测语料库等。本项目简单谈谈自己对语言资源的感想以及目前自己进行语言资源构建的现状。 介绍 语言资源,本身是一个宽泛

语料库技术与应用—基于维基百科构建日语平行语料并爬取谷歌翻译语音(mp3)
准备:wikipedia-parallel-titles项目(老师给的) This document describes how to use these tools to build a parallel corpus (for a specific language pair) based on article titles across languages in Wik

钉钉将独立发展;特斯拉进军数据中心市场;多模态语料数据库“书生·万卷”开源;禾赛科技Q2雷达交付暴涨10倍丨每日大事件...
大数据产业创新服务媒体 ——聚焦数据 · 改变商业 企业动态 特斯拉进军数据中心市场,称将新建同类首个数据中心 8月15日,特斯拉宣布将建造“同类第一个(1st of its kind)”数据中心,该公司正为其招聘相关人员,并收购一些现有的数据中心。特斯拉在上周发布了一个“高级工程项目经理,数据中心”的职位,在职位描述中,特斯拉表示将建造“同类第一个数据中心”:“这个角色将负责特

使用百度AI开放平台进行财经语料用户情感分析
目录 一、实现过程操作步骤 二、遇到的问题与解决 三、详细代码 一、实现过程操作步骤 1、百度AI开放平台上创建应用 详细过程比较简单, 不详细描述 1)到http://ai.baidu.com/上一步步注册账号 2)创建一个自然语言分析下语料情感分析的应用。(根据步骤创建模型、训练、创建即可。其中涉及相关预料的获取,可以写个爬虫弄一下。 具体可以参考 https://b

python NLP ——获得文本语料和词汇资源
一 获取文本语料库 1.Gutenberg >>> from nltk.corpus import gutenberg>>> gutenberg.fileids()['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', ...]>>> emma = gutenberg.words('austen-emma.txt'
聊天机器人语料在开发中的重要性
语料在聊天机器人的开发中起着至关重要的作用,使其能够有效理解和回应用户的查询。语料是聊天机器人的训练数据,通过分析和学习这个语料,聊天机器人可以提高对用户意图的准确理解,并生成恰当的回应。 | 一、聊天机器人语料好在哪? 1.提升聊天机器人的准确性 语料为聊天机器人提供了大量真实世界的例子供其学习。通过使用语料对聊天机器人进行训练,开发者可以确保聊天机器人的回应准确且与用户意图相关。

ACL 2018 | TA-NMT:利用大语种语料,提升小语种神经机器翻译能力
编者按:随着神经机器翻译的快速发展,英语、法语等大语种之间的翻译任务已经能够达到良好的翻译效果,而小语种的翻译仍然是一个难题。与大语种丰富的语料数据相比,小语种机器翻译面临的主要挑战是语料的稀疏性问题。为了更好地解决这一问题,微软亚洲研究院自然语言计算组提出了一个呈三角结构的神经机器翻译模型TA-NMT,利用大语种的丰富语料来提升小语种机器翻译的能力。 近年来,神经机器翻译发展迅速,在诸如

200万条中英对照机器学习及AI语料训练数据库
本机器学习及AI语料训练数据库共200万条中英对照语句,数据格式为Excel,分英文、分隔符、中文三个字段,方便二次加工处理。接受其它数据格式、语言类型语料训练数据库定制。