本文主要是介绍python NLP ——获得文本语料和词汇资源,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一 获取文本语料库
1.Gutenberg
>>> from nltk.corpus import gutenberg
>>> gutenberg.fileids()
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', ...]
>>> emma = gutenberg.words('austen-emma.txt')macbeth_sentences = gutenberg.sents('shakespeare-macbeth.txt')
//words() raw() sents()
raw()没有任何处理的内容2.网络和聊天成本
from nltk.corpus import webtext
from nltk.corpus import nps_chat
3.布朗语料库
from nltk.corpus import brown
print(brown.words(categories='news'))
特定文本计数
import nltk
from nltk.corpus import brown
text= brown.words(categories='news')
fdist=nltk.FreqDist(w.lower() for w in text)
modals=['can','could','may','must','will']
for m in modals:print(m+':',fdist[m],end=' ')
设置end = ’ '以让print函数将其输出放在单独的一行
使用print( , , )输出int和char
4.路透社语料库
from nltk.corpus import reuters
训练 测试
5.就职演说语料库
要从文件名中获得年代,我们使用fileid[:4]提取前四个字符。
>>> from nltk.corpus import inaugural
>>> inaugural.fileids()
['1789-Washington.txt', '1793-Washington.txt', '1797-Adams.txt', ...]
>>> [fileid[:4] for fileid in inaugural.fileids()]
['1789', '1793', '1797', '1801', '1805', '1809', '1813', '1817', '1821', ...]
6.文本语料库的结构
NLTK 中定义的基本语料库函数


二 条件频率分布
1.条件和事件
配对序列(条件,事件)
2.按文体计数词汇
import nltk
from nltk.corpus import brown
cfd=nltk.ConditionalFreqDist((genre,word)for genre in brown.categories()for word in brown.words(categories=genre)
)

3.绘制分布图和分布表
import nltk
from nltk.corpus import inaugural
cfd=nltk.ConditionalFreqDist((target,fileid[:4])for fileid in inaugural.fileids()for w in inaugural.words(fileid)for target in ['america','citizen']if w.lower().startswith(target)
)
print(cfd['america'].most_common(10))cfd.tabulate(conditions=['america','citizen'],samples=['2000','2001','2002','2003','2004','2005'],cumulative=True)

import nltk
from nltk.corpus import udhr
languages = ['Chickasaw', 'English', 'German_Deutsch', 'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']
cfd=nltk.ConditionalFreqDist((lang,len(word))for lang in languagesfor word in udhr.words(lang+'-Latin1')
)
print(cfd['English'].most_common(10))cfd.tabulate(conditions=['English','German_Deutsch'],samples=range(10),cumulative=True)

tabulate直译是制表,让python实现表格化显示。
可以使用conditions=来选择指定哪些条件显示。如果我们忽略它,所有条件都会显示。同样,我们可以使用samples=parameter 来限制要显示的样本。(注意参数是数字还是字符)
cumulative 是否累加
处理布朗语料库的新闻和言情文体,找出一周中最有新闻价值并且是最浪漫的日子。定义一个变量days,包含星期的列表,如[‘Monday’,
…]。然后使用cfd.tabulate(samples=days)为这些词的计数制表。
import nltk
from nltk.corpus import brown
cfd=nltk.ConditionalFreqDist((con,day)for con in ['news','romance']for day in brown.words(categories=con)
)
days=['Monday','Tuesday', 'Wednesday','Thursday', 'Friday', 'Saturday', 'Sunday']
cfd.tabulate(samples=days,cumulative=False)4.使用双连词生成随机文本

//输入变量word的当前值,重新设置word为上下文中最可能的词符(使用max())
def generate_model(cfdist,word,num=15):for i in range(num):print(word,end=" ")word=cfdist[word].max()text=nltk.corpus.genesis.words('english-kjv.txt')
bigrams=nltk.bigrams(text)
cfd=nltk.ConditionalFreqDist(bigrams) //创建后续词的频率分布print(cfd['living'].most_common(10))
generate_model(cfd,'living')


三 词汇资源
1.词汇列表语料库
nltk.corpus.words
停用词 stopwords

字母拼写谜题
import nltk
must_word='r'
wordlist=nltk.corpus.words.words()
words=[w for w in wordlist if len(w)>=6and must_word in wand nltk.FreqDist(w)<=nltk.FreqDist('egivrvonl')]
print(words)
遍历每一个词查看长度以及r是否在单词中,FreqDist比较在单词中出现的频率是否小于等于在字母解密中出现的频率,保证除v以外的字母只出现1次,v最多只出现两次

名字语料库

2.发音的词典
nltk.corpus.cmudict.entries()

每个条目由两部分组成
用两个变量名word, pron替换entry。现在,每次通过循环时,word被分配条目的第一部分,pron被分配条目的第二部分
import nltk
entries=nltk.corpus.cmudict.entries()
for word,pron in entries:if len(pron) == 3 :p1,p2,p3=pron //注意! 将pron的内容分配给三个变量if p1=='P' and p3=='T':print(word,p2,end=' ')
扫描词典中发音包含三个音素的条目

找到所有p开头的三音素词,并按照它们的第一个和最后一个音素来分组
import nltk
entries=nltk.corpus.cmudict.entries()
p3=[(pron[0]+'-'+pron[2],word)for (word,pron) in entriesif pron[0]=='P' and len(pron) ==3]
cfd=nltk.ConditionalFreqDist(p3)
for temp in sorted(cfd.conditions()):if len(cfd[temp])>10:words=sorted(cfd[temp])wordlist=' '.join(words)print(temp,wordlist[:10])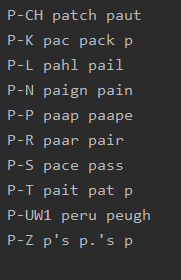
查找特定词汇来访问词典

3.比较词表
五 WordNet
1.意义与同义词
from nltk.corpus import wordnet as wn
print(wn.synsets('motorcar'))

motorcar只有一个可能的含义,它被定义为car.n.01,car的第一个名词意义。car.n.01被称为synset或“同义词集”,意义相同的词(或“词条”)的集合
print(wn.synset('car.n.01').lemma_names()) //访问同义词集

//定义和例句
print(wn.synset('car.n.01').definition())
print(wn.synset('car.n.01').examples())

print(wn.synset('car.n.01').lemmas()) //指定同义词集的所有词条
print(wn.lemma('car.n.01.automobile')) //查找特定的词条
print(wn.lemma('car.n.01.automobile').synset()) //得到一个词条的同义词集
print(wn.lemma('car.n.01.automobile').name()) //得到一个词条的名字

2.层次结构

下位词集 hyponyms()
hypernyms() #得到指定同义词集的上位同义词集
hypernym_paths() #得到指定同义词集的上位词路径(嵌套列表的形式)
root_hypernyms() #得到根上位同义词集
3.词汇关系
part_meronyms() 部分
substance_meronyms() 实质
member_holonyms() 集合
entailments() 蕴含
antonyms() 反义词
使用dir()查看词汇关系和同义词集上定义的其他方法
4.语义相似度
lowest_common_hypernyms
min_depth
path_similarity 基于上位词层次结构中相互连接的概念之间的最短路径在0-1范围的打分(两者之间没有路径就返回-1)。同义词集与自身比较将返回1。
六 作业
1.使用state_union语料库阅读器,访问《国情咨文报告》的文本。计数每个文档中
出现的men、women和people。随时间的推移这些词的用法有什么变化?
import nltk
from nltk.corpus import state_union
cfd=nltk.ConditionalFreqDist((target,fileid[:4])for fileid in state_union.fileids()for w in state_union.words(fileid)for target in ['men','women','people']if w.lower() == target
)
cfd.plot()

2.在名字语料库上定义一个条件频率分布,显示哪个首字母在男性名字中比在女性名字中更常用。
import nltk
from nltk.corpus import names
cfd=nltk.ConditionalFreqDist((fileid,name[0])for fileid in names.fileids()for name in names.words(fileid)
)
cfd.plot()
3.编写一段程序,找出所有在布朗语料库中出现至少3次的词
import nltk
from nltk.corpus import brown
fd=nltk.FreqDist(w.lower() for w in brown.words())
fd_words=[w for w in fd if fd[w]>=3]
print(fd_words)

4.编写一段程序,生成如表1-1所示的词汇多样性得分表(例如:标识符/类型的比例)。包括布朗语料库文体的全集(nltk.corpus.borwn.categories())。哪个文体的词汇多样性最低(每个类型的标识符数最多)?和你预测的结果相同吗?
from nltk.corpus import brown
def per(words):words=[w.lower() for w in words]return len(words)/len(set(words))for category in brown.categories():print(category,per(brown.words(categories=category)))

5.编写一个函数,找出文本中最常出现的50个词,停用词除外。
import nltk
from nltk.corpus import brown
from nltk.corpus import stopwords
def max(words):words=[w.lower() for w in words if w.lower() not in stopwords.words(fileids=u'English')]cfd=nltk.FreqDist(words)max_word=cfd.most_common(50)return max_wordprint("brown",max(brown.words()))
6.编写一个函数word_freq(),用一个词和布朗语料库中的一个部分名字作为参数,计算这部分语料中词的频率。
import nltk
from nltk.corpus import brown
def word_freq(word,name):words=[w.lower() for w in brown.words(fileids=name)]fdist=nltk.FreqDist(words)freq=fdist[word]/len(words)print(word,freq)word_freq('the','ca16')

7.定义一个函数hedge(text),用于处理文本并产生一个在三个词之间插入一个词like的新版本。
def hedge(text):new_text=[]for index in range(3,len(text),3):new_text.extend(text[index-3:index]+['like'])new_text.extend(text[index:])print(new_text)text=['1','2','3','4','5','6','7']
hedge(text)

注意append() 和expend()区别
list.append(object) 向列表中添加一个对象object
list.extend(sequence) 把一个序列seq的内容添加到列表中

8.齐夫定律:f(w)是自由文本中词w的频率。假设一个文本中的所有词都按照它们的频率排名,频率最高的排在最前面。齐夫定律指出一个词类型的频率与它的排名成反比(即f*r=k,k是某个常数)。例如:最常见的第50个词类型出现的频率应该是最常见的第150个词类型出现频率的3倍。
a. 编写一个函数用于处理大文本,使用pylab.plot根据排名画出词的频率,你赞同齐夫定律吗?(提示:使用对数刻度)所绘曲线的极端情况是怎样的?基本符合齐夫定律。
import nltk
from nltk.corpus import brown
words=[w.lower() for w in brown.words(categories='news')]
fdist=nltk.FreqDist(words)
fdist.plot(10)

for word,freq in fdist.most_common(10)
分别获取word 和 对应频率
这篇关于python NLP ——获得文本语料和词汇资源的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




