编者按:随着神经机器翻译的快速发展,英语、法语等大语种之间的翻译任务已经能够达到良好的翻译效果,而小语种的翻译仍然是一个难题。与大语种丰富的语料数据相比,小语种机器翻译面临的主要挑战是语料的稀疏性问题。为了更好地解决这一问题,微软亚洲研究院自然语言计算组提出了一个呈三角结构的神经机器翻译模型TA-NMT,利用大语种的丰富语料来提升小语种机器翻译的能力。
近年来,神经机器翻译发展迅速,在诸如英法、英德、中英等许多大语种(Rich Language)翻译任务上均取得了突破性成果。但因为神经机器翻译的模型参数量庞大,且训练方法为极大似然估计,所以需要大量的对齐语料,比如数百万个句对,才能得到一个比较理想的翻译模型。
研究表明,如果对齐语料数量过少,如只有十几万个句对,那么神经机器翻译模型会在这个小数据集上产生比较严重的过拟合,从而导致其性能低于传统的统计机器翻译模型,这被称为神经机器翻译的数据稀疏性问题(Low-resource Problem)。这个问题普遍存在而且非常关键,尤其是在小语种(Rare Language)的翻译问题上。通常情况下,一个小语种(如蒙古语)和其他任意一种语言之间的双语数据常常是稀疏的,如果稀疏性问题不解决,将会严重影响神经机器翻译在小语种上的翻译应用。
为了解决这一问题,业界已经做出了很多尝试。方法大致分为两类:第一类方法是充分利用容易获取的单语数据,典型的方法为Back-translation。它利用反向的翻译模型,将目标语言端的单语数据翻译成源语言的数据,通过这一方法构造伪双语数据来训练正向的翻译模型。这一方法可以扩展为将两个方向的翻译模型结合起来进行联合训练(Joint Training),利用源语言和目标语言的单语数据来同时提升两个方向的翻译模型;第二类方法为多语言模型方法,典型的有multilingual模型。它针对每种语言分别定义了编码器和解码器,并通过共享的attention机制来完成不同语种之间的翻译。
在本篇论文中,我们提出了第三类方法——充分利用大语种丰富的对齐语料来提升小语种机器翻译的能力。让我们设想图1中的场景,X和Y为两个大语种,如英语和法语,它们之间有很丰富的双语数据。Z为一个小语种,如蒙古语,它和X以及Y之间只有少量的双语数据。而我们的目标是要提升X↔Z和Y↔Z,即四个包含小语种的翻译模型的翻译性能。我们将这一方法称为TA-NMT,即三角结构神经机器翻译模型(Triangular Architecture Neural Machine Translation)。

图1 典型小语种场景
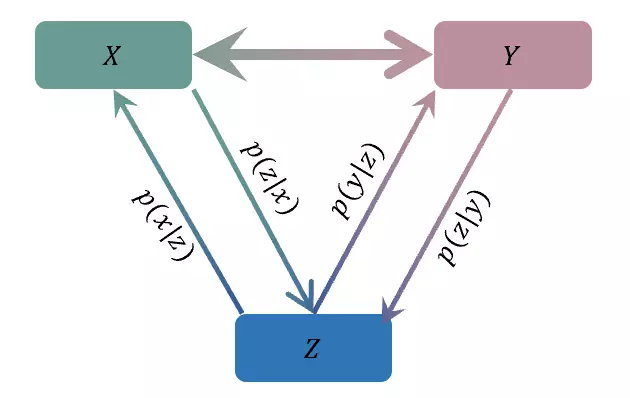
图2 用X和Y之间的丰富语料提升四个包含小语种的翻译模型
广义EM优化
在我们提出的方法中,我们将小语种Z所在的空间作为隐空间,对X→Y和Y→X的翻译进行建模,以充分利用X和Y之间的丰富语料。这样一来,X→Y的翻译过程就可以拆分为两个步骤X→Y和Z→Y,然后就可以用EM算法对这两个过程进行迭代优化。Y→X的翻译过程也是如此。具体来说,以X→Y方向为例,通过将Z作为隐变量,我们利用Jensen不等式,对优化目标log p(y|x)进行重写,得到:
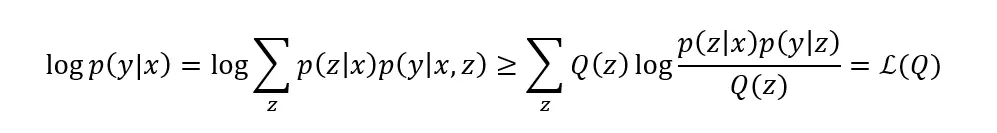
其中Q(z)为隐变量z 的一个任意后验分布,L(Q) 即为我们得到的优化下界。由Q(z)的任意性,我们可以选择Q(z)=p(z|x)作为z的后验,这样一来优化下界就可以显式地写出来,即:
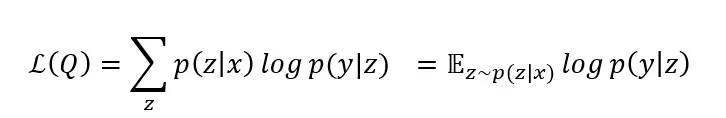
同时,由于Q(z) 的选择,我们也可将log p(y|x)与L(Q) 之间的误差推导出来,即:
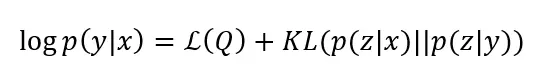
其中KL(·)为Kullback–Leibler divergence。这样,我们便可以用广义EM算法对上式进行最大化优化。在E步骤中,我们最小化KL项,使得从x到z和从y到z的结果尽可能一致,即:
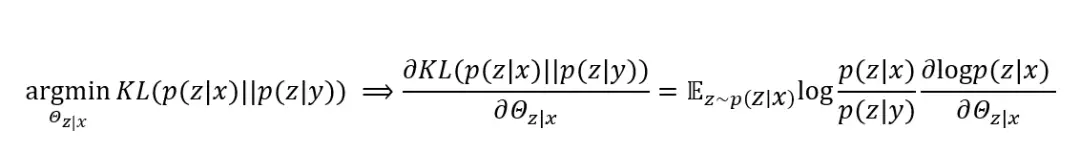
在M步骤中,我们最大化优化下界L(Q),最大化从z到y得到的最终翻译期望,即:
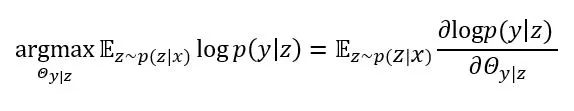
可以看到,在E步中,我们借助p(z|x)和p(z|y)来更新p(z|x),在M步中,我们借助p(z|x)来更新p(y|z)。对于Y→X方向,我们也可以根据上面的推导得到对p(z|y)和p(x|z)的优化方法。这样就可以完成对于四个小语种翻译模型的优化。
联合EM训练
其实在上面的推导中,我们发现,X→Y方向的训练中,也用到了Y→X才会更新的模型p(z|y);反之,在Y→X方向的训练中,也用到了X→Y才会更新的模型p(z|x)。所以我们可以将两个方向结合起来,进行联合的迭代训练,从而可以同时优化四个小语种翻译模型。其过程如下图所示,其中红框表示该步骤负责优化的翻译模型。
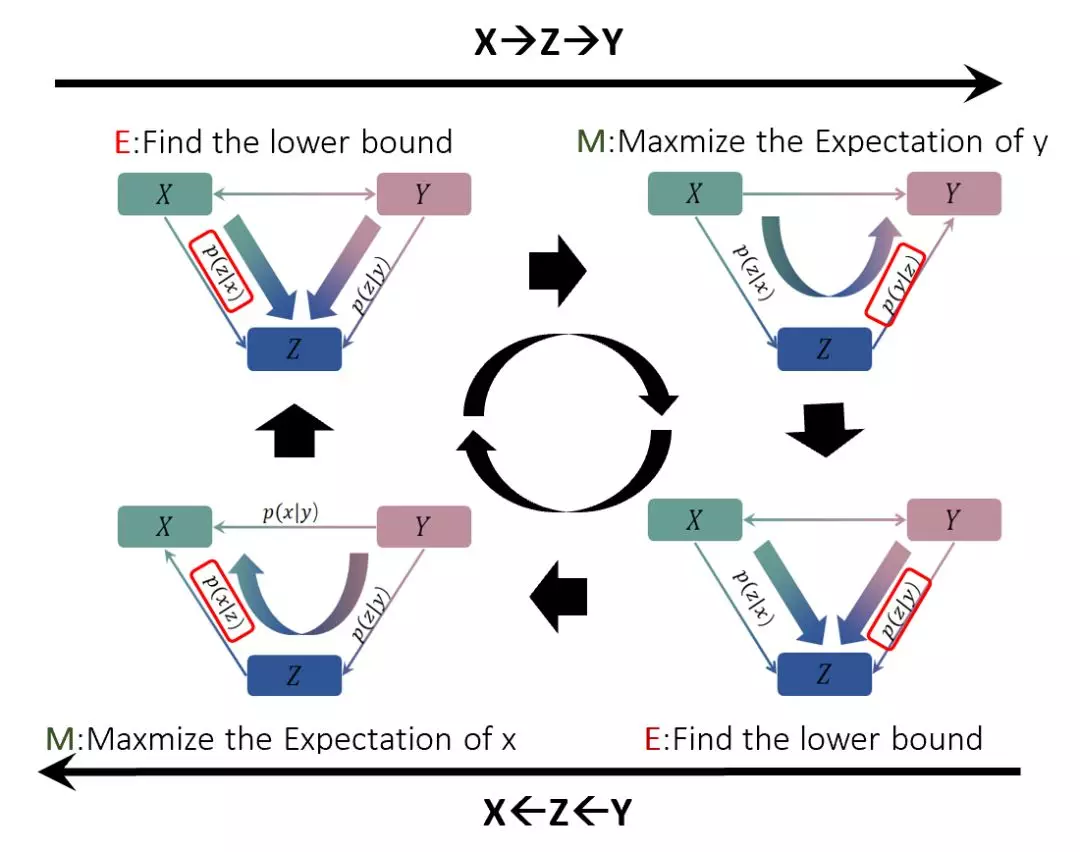
图3 联合EM训练过程
实验
我们的实验用到了MultiUN和IWSLT2012两个数据集,均采用英语和法语作为大语种。在MultiUN数据集中,我们采用阿拉伯语和西班牙语作为模拟的小语种;在IWSLT数据集中,我们采用罗马尼亚语和希伯来语作为真实场景的小语种。
实验中,我们比较了两个baseline模型,一个是经典的神经机器翻译模型RNNSearch,另外一个是Phrase-based统计机器翻译模型。此外,我们还比较了两个teacher student和back-translation两个模型。由于TA-NMT中没有用到Z端的单语数据,所以我们将TA-NMT方法进行了进一步扩展,将back-translation训练的模型作为TA-NMT的初始模型,在此基础上进行进一步联合EM训练,我们称这个扩展方法为TA-NMT(GI)。其中GI表示good initialization。实验结果如下表所示:
可以看到,在没有引入Z 端单语数据的情况下,TA-NMT的性能高于RNNSearch、PBSMT、T-S。在引入Z 端单语数据的情况下,TA-NMT(GI)的性能高于BackTrans。
同时,我们画出了英语-法语-阿拉伯语组和英语-法语-罗马尼亚语组的训练曲线。下图中纵轴为相应验证集上的BLEU值,横轴为训练中的模型参数的更新次数。可以看到,整个过程中,E步和M步中优化的两个模型性能均稳步上升。

总结来说,我们提出的TA-NMT训练模型充分利用大语种语言对之间丰富的双语数据来提升小语种翻译模型的性能。基本思路是在大语种之间的翻译过程中将小语种作为中间隐变量引入,将该翻译过程拆分为两个经由小语种的翻译过程,从而可以用EM方法进行优化。同时我们提出了联合EM训练方法,可以同时对四个小语种翻译模型进行优化。
参考文献:
Shuo Ren, Wenhu Chen, Shujie Liu, Mu Li, Ming Zhou, Shuai Ma, Triangular architecture for rare language translation, ACL 2018.
论文链接:
https://arxiv.org/abs/1805.04813




![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)