nmt专题

NLP-2015:Luong NMT模型【Attention类型:Global Attention、Local Attention(实践中很少用)】
《原始论文:Effective Approaches to Attention-based Neural Machine Translation》 在实际应用中,全局注意力机制比局部注意力机制有着更广泛的应用,因为局部注意力机制需要预测一个位置向量 p t p_t pt,而这个位置向量的预测并不是非常准确的,会影响对齐向量的准确率。同时,在处理不是很长的源端句子时,相比于全局注意力并没有减少

Docker续5:docker部署nmt(mysql,nginx,tomcat)
1.前端(nginx) [root@localhost ~]# docker pull nginx //拉取nginx镜像 [root@localhost ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE nginx

Google NMT 阅读笔记
原文 https://github.com/tensorflow/nmt/ The encoder RNN uses zero vectors as its starting states encoder端的rnn使用零向量作为初始状态
一些Attention在NMT上的论文
http://tech.huanqiu.com/news/2016-11/9735838.html?agt=15438 1、Neural Machine Translation by Jointly Learning to Align and Translate, 2015 2、Effective approaches to attention-based neural machine trans

ACL 2021 | 腾讯AI Lab、港中文杰出论文:用单语记忆实现高性能NMT
来源:机器之心本文约3200字,建议阅读7分钟 在 ACL 2021 的一篇杰出论文中,研究者提出了一种基于单语数据的模型,性能却优于使用双语 TM 的「TM-augmented NMT」基线方法。 自然语言处理(NLP)领域顶级会议 ACL 2021 于 8 月 2 日至 5 日在线上举行。据官方数据, 本届 ACL 共收到 3350 篇论文投稿,其中主会论文录用率为 21.3%。腾讯 A

通过NMT训练的通用语境词向量:NLP中的预训练模型?
转载请注明出处:乐投网-通过NMT训练的通用语境词向量:NLP中的预训练模型? 自然语言处理(NLP)这个领域目前并没有找到合适的初始化方法,它不能像计算机视觉那样可以使用预训练模型获得图像的基本信息,我们在自然语言处理领域更常用的还是随机初始化词向量。本文希望通过 MT-LSTM 先学习一个词向量,该词向量可以表征词汇的基本信息,然后再利用该词向量辅助其它自然语言处理任务以提升性能。本文先

Tensorflow nmt的数据预处理过程
tensorflow nmt的数据预处理过程 在tensorflow/nmt项目中,训练数据和推断数据的输入使用了新的Dataset API,应该是tensorflow 1.2之后引入的API,方便数据的操作。如果你还在使用老的Queue和Coordinator的方式,建议升级高版本的tensorflow并且使用Dataset API。 本教程将从训练数据和推断数据两个方面,详解解析数据
Tensorflow nmt的超参数
Tensorflow nmt的超参数 超参数一般用来定义我们的神经网络的关键参数. 在tensorflow/nmt这个demo中,我们的超参数在 nmt.nmt 模块中配置.这也导致了nmt.py这个文件的代码行数比较多,我们完全可以把参数的配置放到单独的一个文件中去.nmt.py 这个文件也是整个项目的入口文件.如果你想了解这个demo的整体结构,请查看我的另一篇博客tensorfl
Tensorflow nmt的整体结构
Tensorflow nmt的整体结构 tensorflow/nmt项目的入口文件是nmt/nmt.py,通过指定不同的参数,可以从该入口进入到训练或者推断流程。首先来看一看,进入不同流程的时候,做了什么。 程序入口 首先我们可以看到这两个函数: def main(unused_argv):default_hparams = create_hparams(FLAGS)tra

nlp-baseline 7:deep NMT
博客转载自如下地址:https://blog.csdn.net/oldmao_2001/article/details/102653672 文章目录 前言第一课 论文导读BLEU介绍BLEU实例BLEU改进 机器翻译简介机器翻译相关方法前期知识储备 第二课 论文精读论文整体框架传统/经典算法模型1.Encoder-Decoder(见导读)2.基于attention的机器翻译 本文模

NLP学习笔记(七)神经网络机器翻译(NMT)
神经网络机器翻译(Neural Machine Translation) 这节课我们利用RNN来做机器翻译,机器翻译模型有很多种,这节课我们介绍Seq2Seq模型,把英文翻译为德文。机器翻译是一个Many to Many的问题。 首先,我们要处理数据。 机器翻译数据(Machine Translation Data) 这里,我们仅是学习需要,使用一个小规模数据集即可。可以使用http:

ACL 2018 | TA-NMT:利用大语种语料,提升小语种神经机器翻译能力
编者按:随着神经机器翻译的快速发展,英语、法语等大语种之间的翻译任务已经能够达到良好的翻译效果,而小语种的翻译仍然是一个难题。与大语种丰富的语料数据相比,小语种机器翻译面临的主要挑战是语料的稀疏性问题。为了更好地解决这一问题,微软亚洲研究院自然语言计算组提出了一个呈三角结构的神经机器翻译模型TA-NMT,利用大语种的丰富语料来提升小语种机器翻译的能力。 近年来,神经机器翻译发展迅速,在诸如
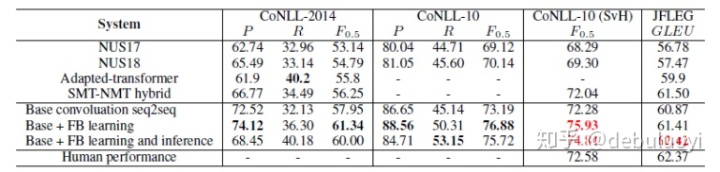
统计机器翻译与神经机器翻译区别_基于神经机器翻译(NMT)的语法纠错算法
摘要 语法纠错(GEC,Grammatical Error Correction,下同)是NLP的一个子领域,在搜索query纠错、语音纠错、舆情文本纠错等诸多直接与普通大众交互的场景得到应用。在深度学习被广泛使用的背景下,研究人员提出了多种方法来解决语法纠错问题,比如基于序列标注融合特征工程的方法[1],基于有限错误类别集合分类及定位的方法(e.g. CUUI:Columbia Un