本文主要是介绍[NLP]基于维基百科中文语料库的Word2Vec模型训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:该博客代码参考于
参考博客:使用中文维基百科语料库+opencc+jieba+gensim训练一个word2vec模型
参考博客:使用中文维基百科训练word2vec模型
零、 模型训练环境
- Windows10-X64 、 python2.7 、 python3.6
- pip install jieba
- pip install gensim
一、下载维基百科语料库
数据下载地址
该博客使用的是 24-Nov-2019 的语料库

二、 利用WikiExtractor.py抽取正文
WikiExtractor.py Copy链接
直接把py文件中的源码直接复制到新的 .py 中即可。
下图是模型训练相关文件:
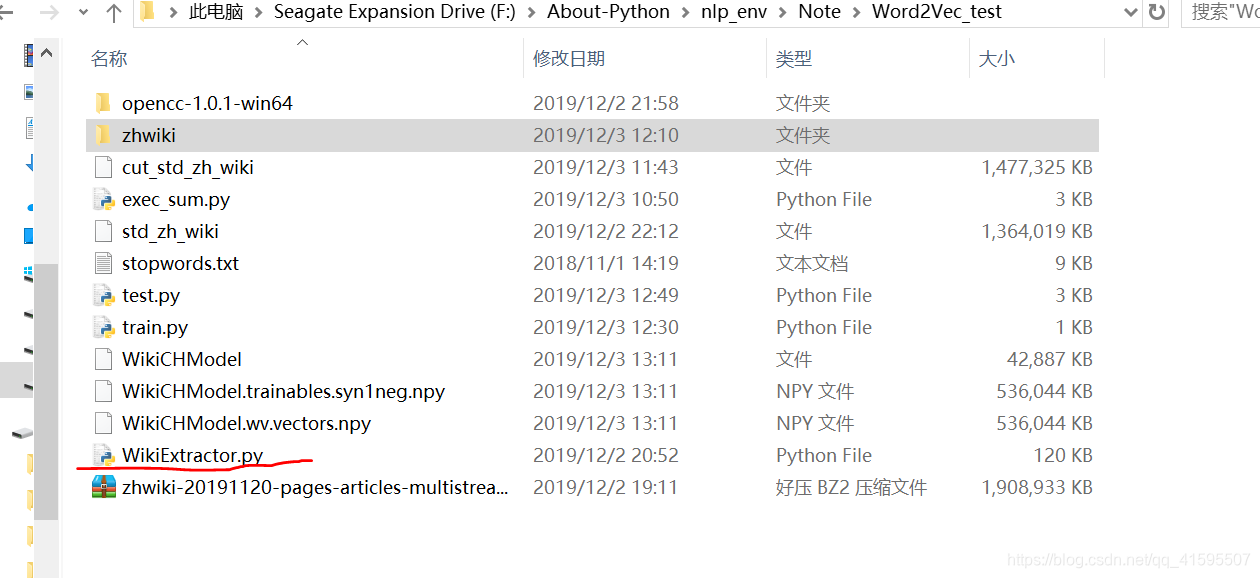
执行命令
python WiKiExtractor.py -b 500M -o zhwiki zhwiki-20191120-pages-articles-multistream.xml.bz2
我们最终会生成zhwiki文件夹

得到三个文本文件
./zhwiki/AA/wiki_00
./zhwiki/AA/wiki_01
./zhwiki/AA/wiki_02
三、 中文繁体转换成简体简体
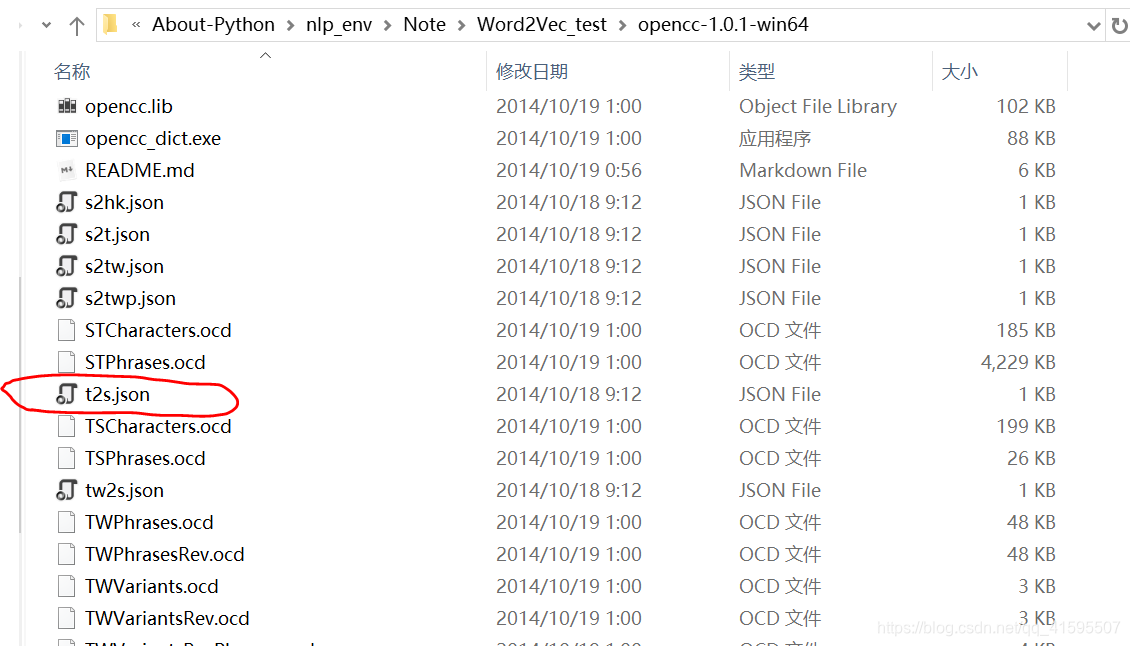
直接使用开源项目转换工具opencc
转换工具下载地址
黑框框起来的是我下载的版本
执行文件添加到环境变量中:
方法1. 解压后将该工具bin目录添加到环境变量中
方法2. 有些工具解压后灭有 bin 目录,我们首先找到opencc.exe可执行文件,将其路径添加到环境变量中

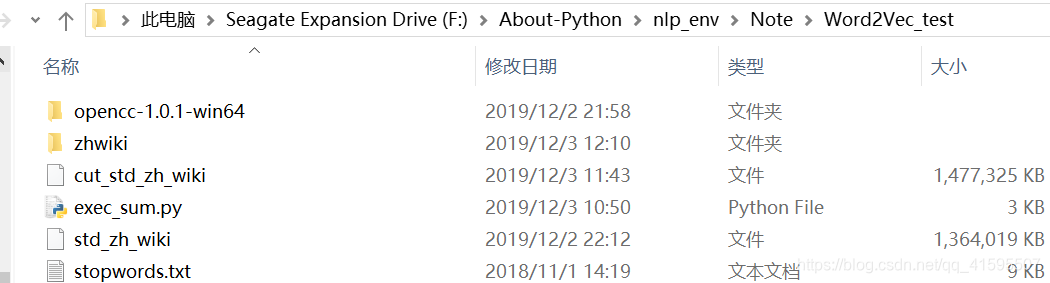
运行命令
我是在该路径中运行的命令,为了方便我先将之前的三个文件拷贝到该路径下,执行完后再拷贝到**./zhwiki/** 下。
.\opencc -i wiki_00 -o zh_wiki_00 -c /path/to/t2s.json
.\opencc -i wiki_01 -o zh_wiki_01 -c /path/to/t2s.json
.\opencc -i wiki_02 -o zh_wiki_02 -c /path/to/t2s.json
最终我把生成的zh_wiki_00等文件拷贝到 /zhwiki/ 中
四、符号处理 ,整合文件
python 2.7 环境中运行
exec_sum.py
#!python2
import re
import sys
import codecs
def myfun(input_file):p1 = re.compile(ur'-\{.*?(zh-hans|zh-cn):([^;]*?)(;.*?)?\}-')p2 = re.compile(ur'[(\(][,;。?!\s]*[)\)]')p3 = re.compile(ur'[「『]')p4 = re.compile(ur'[」』]')outfile = codecs.open('std_zh_wiki', 'a+', 'utf-8')with codecs.open(input_file, 'r', 'utf-8') as myfile:for line in myfile:line = p1.sub(ur'\2', line)line = p2.sub(ur'', line)line = p3.sub(ur'“', line)line = p4.sub(ur'”', line)outfile.write(line)outfile.close()
if __name__ == '__main__':if len(sys.argv) != 2:print("Usage: python script.py inputfile")sys.exit()reload(sys)sys.setdefaultencoding('utf-8')input_file = sys.argv[1]myfun(input_file)
方法一:将三个文件处理后追加到一个文件中即 std_zh_wiki
python .\exec_sum.py zh_wiki_00
python .\exec_sum.py zh_wiki_01
python .\exec_sum.py zh_wiki_02
方法二:我是使用 pycharm IDE 运行了 三次该文件,每次运行修改 input_file(zh_wiki_00、zh_wiki_01、zh_wiki_02) (更改python环境更方便)

五、jieba 分词操作
exec_cut.py
import logging, jieba, os, redef get_stopwords():logging.basicConfig(format='%(asctime)s:%(levelname)s:%(message)s', level=logging.INFO)# 加载停用词表stopword_set = set()with open("stopwords.txt", 'r') as stopwords: for stopword in stopwords:stopword_set.add(stopword.strip("\n"))return stopword_setdef parse_zhwiki(read_file_path, save_file_path):# 过滤掉<doc>regex_str = "[^<doc.*>$]|[^</doc>$]"file = open(read_file_path, "r")output = open(save_file_path, "w+")content_line = file.readline()stopwords = get_stopwords()article_contents = ""while content_line:match_obj = re.match(regex_str, content_line)content_line = content_line.strip("\n")if len(content_line) > 0:if match_obj:words = jieba.cut(content_line, cut_all=False)for word in words:if word not in stopwords:article_contents += word + " "else:if len(article_contents) > 0:output.write(article_contents.encode('utf-8','ignore')+ "\n")article_contents = ""content_line = file.readline()output.close()
parse_zhwiki('./std_zh_wiki', './cut_std_zh_wiki')
- 该操作也是在 python 2.7环境下操作
- 分词时间相对较长,请耐心等待
六、 训练Word2Vec模型
from gensim.models import word2vec
import logginglogging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.LineSentence('./cut_std_zh_wiki')
model = word2vec.Word2Vec(sentences,size=200,window=5,min_count=5,workers=4)
model.save('WikiCHModel')训练完后,会生成三个文件
- 如果python3环境下出现编码问题,请通过某些工具将文件转换成utf-8编码
- 如果无法更改编码,请使用python2.7
七、 模型测试
from gensim.models import word2vec
import logging
from gensim import models
model = word2vec.Word2Vec.load('WikiCHModel')print(model.wv.similarity("儿童", '狗')) #两个词的相关性
若博客中内容存在问题,可在评论处留言,本人将及时更正相关内容
这篇关于[NLP]基于维基百科中文语料库的Word2Vec模型训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







