语料库专题


Python NLP自然语言处理 nltk载入自己语料库的方法以及文本分词处理
一、使用NLTK中的PlaintextCorpusReader 帮助下载入它们 PlaintextCorpusReader 初始化函数的第一个参数是你要加载的文件的路径,第二个参数可以是一个如['a.txt', 'test/b.txt']这样的 fileids链表,或者一个匹配所有fileids的模式 ,如:'[abc]\.txt' 假定你的文件在/usr/share/dict 目录下,匹配该

“弱智贴吧”的数据,居然是最强中文语料库
中国科学院、北大、中国科技大学、滑铁卢大学、01.ai等10家机构联合推出了,专用于中文的高质量指令调优数据集——COIG-CQIA。 在大模型领域英语一直是训练数据最重要的语言,但由于中英文的结构和文化差异,直接将英文数据集翻译成中文并不理想。所以,为了填补高质量中文数据集的空白,研究人员开发出了COIG-CQIA数据集。 COIG-CQIA几乎抓取了中文互联网的论坛、网站、百度贴吧、问答社
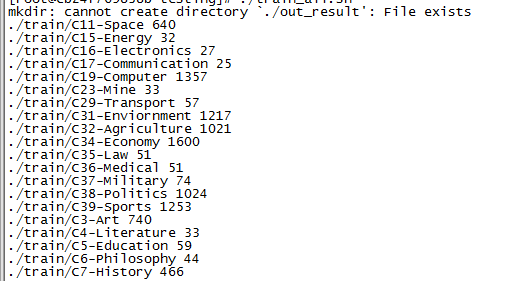
《懒人Shell脚本》之二——语料库的格式化输出
1、引言 在进行自然语言处理(NLP)处理的时候,基本的操作无外乎分词、分类、聚类、命名实体识别、规则过滤、摘要提取、关键字提取、词性标注、拼音标注等。 分类通用的做法就是根据提供的语言库自学习识别成对应的分类。现有的复旦大学提供的语料库有20种分类。(参考:http://www.nlpir.org/?action-viewnews-itemid-103),网上也有提供更多种分类的。 分词网
机器学习笔记 大语言模型是如何运作的?一、语料库和N-gram模型
一、语料库 语言模型、ChatGPT和人工智能似乎无处不在。了解大型语言模型(LLM)“背后”发生的事情将是驾驭数字世界的关键。 首先在提示中键入一个单词,然后点击提交。您可以尝试新的提示,并根据需要多次重新生成响应。 这个我们称之为“T&C”的语言模型是在一组被称为语料库的文本上训练的。该语料库是大型科技公司的条款和条件。
是否有可能从python中的句子语料库重新训练word2vec模型(例如GoogleNews-vectors-negative300.bin)?
是否有可能从python中的句子语料库重新训练word2vec模型(例如GoogleNews-vectors-negative300.bin)? http://www.voidcn.com/article/p-dsovbvsv-bun.html NLP 利器 Gensim 库的使用之 Word2Vec 模型案例演示(基于 word2vec-google-news-300 预训练模型,附下
jieba--做最好用的中文分词组件详解【5】(自定义停止词语料库)
写在最前面: 这回真的是最后一篇关于jieba的用法介绍了 关键词提取所使用停止词(停止词)文本语料库切换成自定义语料库的路径 这是使用自带的停用词语料库,使用TF-IDF算法提取20个关键词。 import jiebaimport jieba.analysejieba.load_userdict("userdict.txt")jieba.analyse.set_id
写作辅助语料库和检索软件
AntConc 语料库建立和检索软件,支持txt格式语料的导入。Search and Replace 建立自己的txt语料库,然后指定搜索路径,用search and replace软件批量搜索关键词对应的句子。coco语料库网站 检索同义词和搭配等。 https://www.english-corpora.org/corpora.asp

关于Reuters Corpora(路透社语料库)
首先在命令行窗口中进入python编辑环境,输入 >>import nltk>>nltk.download() 然后加载出: 在Corpora中所有的文件下载到C:\nltk_data中,大小在2.78G左右。 然后开始对其玩弄啦。 加载 from nltk.corpus import reutersfiles = reuters.fileids()#print(files)wo
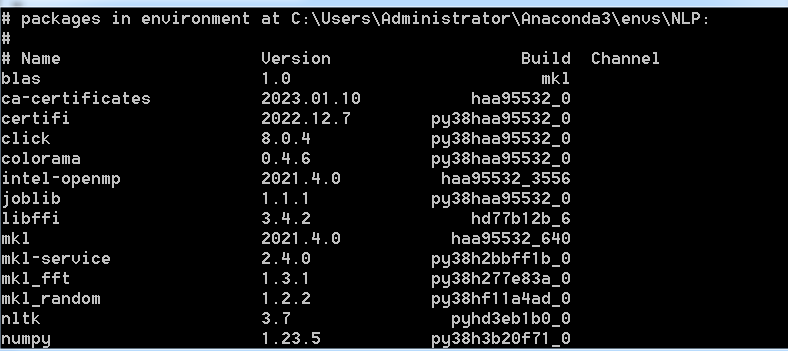
2.3语料库NLTK数据包下载及安装
NLTK(Natural Language Toolkit)是一个用于构建处理自然语言数据的Python应用开源平台。NLTK提供了超过50多个素材库和词库资源的易用接口,涵盖了分词、词性标注、命名实体识别、句法分析等各项NLP领域的功能。NLTK支持NLP和教学研究,它收集的大量公开数据集和文本处理库,可以用于给文本分类、符号化、提取词根、贴标签、解析及语义推理等。NLTK也是当前最为流行的

语料库技术与应用—基于维基百科构建日语平行语料并爬取谷歌翻译语音(mp3)
准备:wikipedia-parallel-titles项目(老师给的) This document describes how to use these tools to build a parallel corpus (for a specific language pair) based on article titles across languages in Wik

《多模态语料库 “书生·万卷” 1.0 详细解读 | 附下载地址》
国产大模型时代,高质量、开源、可信数据的重要性不言而喻,但它的稀缺性也是 AI 同行有目共睹的。为了改变这一现状,OpenDataLab 联合大模型语料数据联盟构建了“书生·万卷”数据集,旨在为学术界及产业界提供更符合主流中文价值对齐的高质量大模型多模态预训练语料。“书生·万卷” 1.0 版本 8 月14日正式发布,跟着小编详细了解一下吧。 一、书生·万卷1.0 书生·万卷1.0 为书生·

基于数据(语料库)的复述粗略综述
基于数据(语料库)的复述粗略综述 By牛力强 2013年9月24日 NLP CS NJU Email:simpleniulq2013@gmail.com 1.复述 1.1复述(paraphrase): 在与原句表达相同的语义内容,同一种语言下的原句的替代形式。 1.2复述产生的层次(level): 词汇复述(lexical paraphrase):个别词汇(individual l

大规模汉语标注语料库的制作与使用
大规模汉语标注语料库的制作与使用 段慧明 松井久仁於 徐国伟 胡国昕 俞士汶 引言 富士通研究开发中心和北京大学计算语言学研究所从1999年4月起,以人民日报1998年上半年的语料为对象,合作制作大规模汉语标注语料库。富士通研究开发中心已使用这个标注语料库的部分成果,尝试研制汉语切分系统。 1999 年11月4日,富士通研究开发中心在北京举行了题为《大规模汉语标注语料库的制作与使用》的研讨
![[NLP]基于维基百科中文语料库的Word2Vec模型训练](https://img-blog.csdnimg.cn/20191205105946298.png)
[NLP]基于维基百科中文语料库的Word2Vec模型训练
说明:该博客代码参考于 参考博客:使用中文维基百科语料库+opencc+jieba+gensim训练一个word2vec模型 参考博客:使用中文维基百科训练word2vec模型 零、 模型训练环境 Windows10-X64 、 python2.7 、 python3.6pip install jiebapip install gensim 一、下载维基百科语料库 数据下载地址 该博客使用

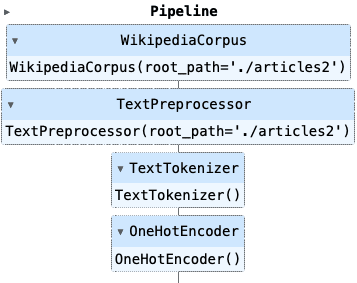
NLP项目:维基百科文章爬虫和分类【02】 - 语料库转换管道
一、说明 我的NLP项目在维基百科条目上下载、处理和应用机器学习算法。相关上一篇文章中,展示了项目大纲,并建立了它的基础。首先,一个 Wikipedia 爬网程序对象,它按名称搜索文章,提取标题、类别、内容和相关页面,并将文章存储为纯文本文件。其次,一个语料库对象,它处理完整的文章集,允许方便地访问单个文件,并提供全局数据,如单个令牌的数量。 二、背景介绍

NLP情感分析和可视化|python实现评论内容的文本清洗、语料库分词、去除停用词、建立TF-IDF矩阵、获取主题词和主题词团
1 文本数据准备 首先文本数据准备,爬取李佳琦下的评论,如下: 2 提出文本数据、获得评论内容 #内容读取import xlrdimport pandas as pdwb=xlrd.open_workbook("评论数据.xlsx")sh=wb.sheet_by_index(0)col=sh.ncolsrow=sh.nrowsText=[]for i in range(r

Pyhon 自然语言处理(一)NLTK及语料库下载
Python 自然语言处理(一)NLTK及语料库下载 参考网站 http://www.nltk.org/ NLTK是用来进行自然语言处理很强大的包,本文介绍Python下安装NLTK及语料下载 1. 安装 NLTK pip install nltk 如果已经安装了 Anaconda 则默认安装了nltk,但是没有安装语料库 2. 自动安装语料库 如果在引入nltk包后,发现没有安装语
NLP项目:维基百科文章爬虫和分类【02】 - 语料库转换管道
一、说明 我的NLP项目在维基百科条目上下载、处理和应用机器学习算法。相关上一篇文章中,展示了项目大纲,并建立了它的基础。首先,一个 Wikipedia 爬网程序对象,它按名称搜索文章,提取标题、类别、内容和相关页面,并将文章存储为纯文本文件。其次,一个语料库对象,它处理完整的文章集,允许方便地访问单个文件,并提供全局数据,如单个令牌的数量。 二、背景介绍