短评专题

Java豆瓣电影爬虫——使用Word2Vec分析电影短评数据
在上篇实现了电影详情和短评数据的抓取。到目前为止,已经抓了2000多部电影电视以及20000多的短评数据。 数据本身没有规律和价值,需要通过分析提炼成知识才有意义。抱着试试玩的想法,准备做一个有关情感分析方面的统计,看看这些评论里面的小伙伴都抱着什么态度来看待自己看过的电影,怀着何种心情写下的短评。 鉴于爬取的是短评数据,少则10来个字,多则百来个字,网上查找了下,发现Google开

我爬了《流浪地球》十万个短评得出以下结论
前言 最近大家讨论最多的就是《流浪地球》了,偶尔刷逼乎,狗血的事情也是层出不穷,各种撕逼大战,有兴趣的小伙伴可以自行搜索。 截止目前,《流浪地球》已上映20天,累计票房43.94亿,豆瓣评分7.9分。博主是正月初七看的,票价有点小贵,整体效果还算可以,虽然剧情有点尴尬,各种镜头切换有时候看的稀里糊涂,但还是给了豆瓣四星好评。 爬取 逼乎上很多高手,对《流浪地球》在豆瓣的评分做了细思缜密的分析,
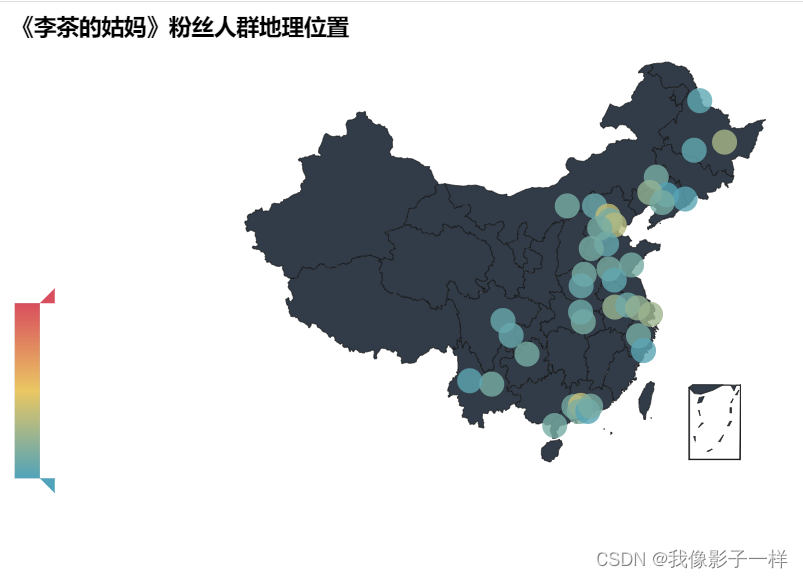
豆瓣爬虫实战:(电影短评)
数据分析实战(豆瓣) 第一章 豆瓣爬虫(爬取电影短评) 1.1 获取一页数据 import requests # 利于解析htmlfrom bs4 import BeautifulSoup # 利于选取html的属性#要爬取的网页start_url = 'https://movie.douban.com/subject/27092785/comments?status=P' # 用
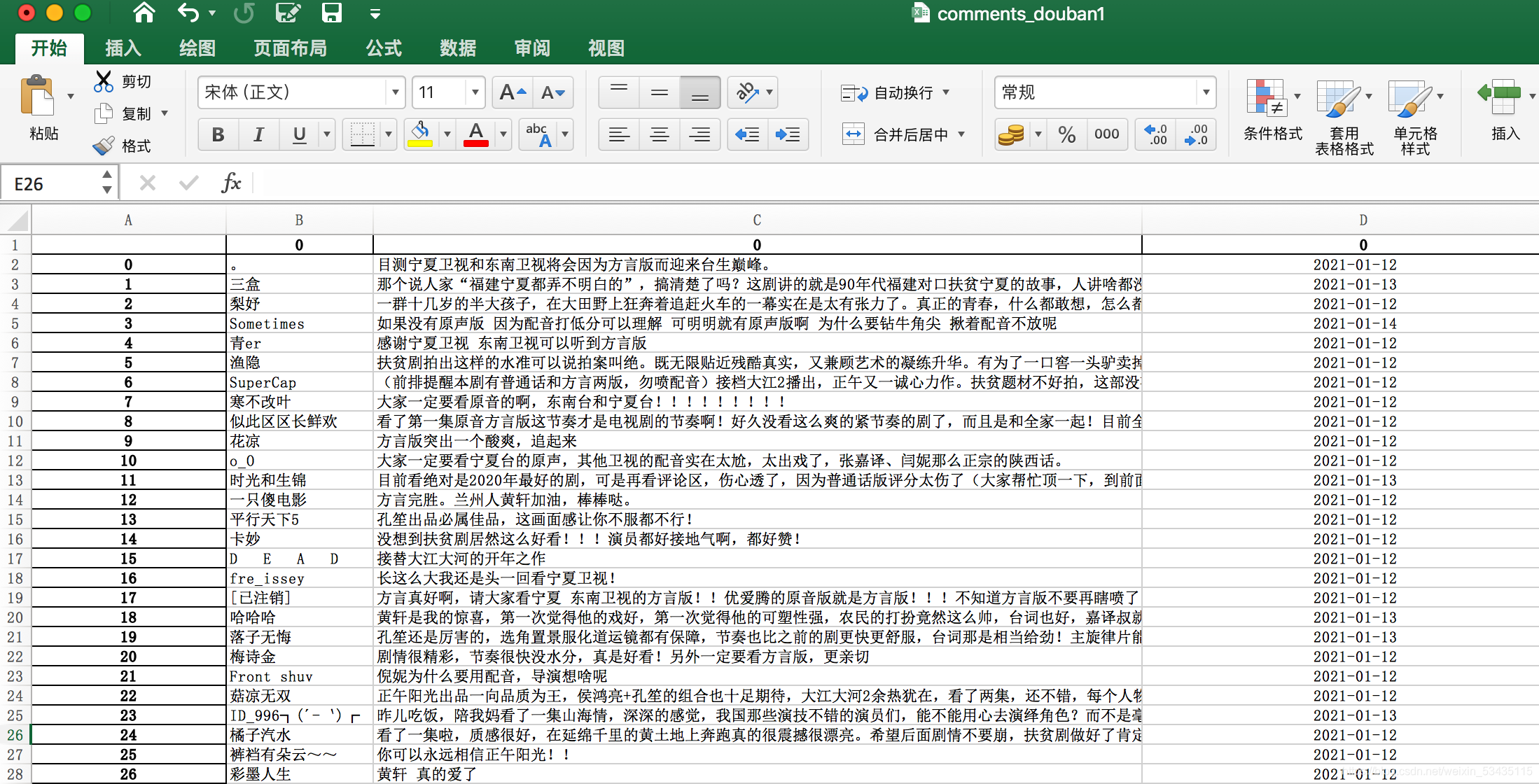
小白 Python爬取豆瓣短评 :以《山海情》为例
Python爬取豆瓣短评:以 《山海情》为例 纯小白一枚,尝试爬取豆瓣短评数据,用的是最简单的方法,别的方法还在学习中,把代码发出来,算是一个记录吧。 完整代码如下: # 加载包import requestsimport pandasfrom lxml import etree# 获取cookie值(略去cookie值则仅能爬取前几页数据)模拟登陆,cookie会随时间有变化# 爬虫

Python 3.6 爬虫爬取豆瓣《孤芳不自赏》短评
使用Python 3.6 进行对《孤芳不自赏》这部作品的短评爬取 这部作品短评在豆瓣中的URL为:https://movie.douban.com/subject/26608228/comments?start=0&limit=20 点击这个连接我们可以进入该作品短评页面 这里还没有登录豆瓣。登录豆瓣之后,才能爬取更多的页面。 因此我们选择登录,最快捷省时的办法,就是在登录时使用F12
入门爬虫示例-爬取豆瓣短评
群里有个小妹妹,让我帮她写的代码,好像是作业什么的。花了几分钟看了一下,随便写写,分享给有需要的童鞋,我用python 3 写的,实现的功能就是:爬取豆瓣短评,然后将数据写入本地的excel表格,数据大概有,电影名称,评分,评论人数,短评四项,稍微修改下也可以爬取其他数据。 这属于入门学习的爬虫,博客里的代码,复制到本地,直接就能跑,有些包需要自己安装一下,安装教程自行百度。代码如下: #-*

根据豆瓣对《流浪地球》的短评数据进行文本分析和挖掘
1背景 2019年2月5日电影《流浪地球》正式在中国内地上映。该电影在举行首映的时候,口德好得出奇,所有去看片的业界大咖都发出了画样赞叹,文化学者能锦说:“中国科幻电影元年开启了。"导演徐峰则说,“里程碑式的电影,绝对是世界级别的”。可是公映之后,《流浪地球》的豆评分却从8.4一路跌到了7.9。影片页面排在第一位的,是一篇一星评《流浪地球,不及格》。文末有2.8万人点了“有用”,3.6万人点

2.Request爬取豆瓣短评
使用Requests爬取豆瓣短评 Python爬虫(入门+进阶) DC学院 本节课程的内容是介绍什么是Requests库、如何安装Requests库以及如何使用Requests库进行实际运用。 Requests库介绍: Requests库官方的介绍有这么一句话:Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。 这句话直接并霸气地宣示了Requests库是p

Python抓取电视剧《天盛长歌》豆瓣短评,并制作成词云。
最近在看《天盛长歌》,才看了30多集,感觉里边的剧情还是很有深度,每个反派都是智商在线,剧情也是环环相扣,以至于每个镜头给了哪些特写我都要细细斟酌一番。不过可能剧情是根据小说改编,所以部分剧情有些老套,而且因为节奏有点慢,剧情过多,光是大皇子领盒饭就用了20集。目前来说不喜欢韶宁公主有关的剧情,不知道她后边的剧情怎么发展,配角选的也是十分用心了,喜欢珠茵姐姐,可惜十几集就领盒饭了,而且还有点不值,

用python 做一个词云图:复仇者联盟4:终局之战。短评分析
#短评网址u1='https://movie.douban.com/subject/26100958/comments?start=40&limit=20&sort=new_score&status=P'u1 输出结果为网址 #因为只有start的值不一样,所以我们可以采用格式化字符串%i来代替u0='https://movie.douban.com/subject/26100958/

利用Python进行简单爬虫(爬取豆瓣《湮灭》短评)
写在最前 (最新更新时间:20190516) 许多初学者想学习爬虫,但是不知道如何上手。其实在百度或者必应搜索用Python进行网页爬虫,会有很多大神的爬取方式与相应的结果。其实很多数据并不是本身就有的,而是需要通过网络爬虫进行爬取获得(例如想要对高分电影或者高分图书进行分析;对一年中某些商品的购买数量的变化情况进行分析等)。所以对网页进行爬虫,是数据分析中一个非常重要的技能。 网络上最多的

爬虫综合大作业---分析《我不是药神》电影短评
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075 《我不是药神》是这几年来我所看的电影里感触最大的,甚至成为豆瓣上多年来仅有的六部9.0评分以上的华语电影之一。 影片讲述了神油店老板程勇从一个交不起房租的男性保健品商贩,一跃成为印度仿制药“格列宁”独家代理商的故事 获取用户名和短评 name=x.