本文主要是介绍豆瓣爬虫实战:(电影短评),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据分析实战(豆瓣)
第一章 豆瓣爬虫(爬取电影短评)
1.1 获取一页数据
import requests # 利于解析html
from bs4 import BeautifulSoup # 利于选取html的属性#要爬取的网页
start_url = 'https://movie.douban.com/subject/27092785/comments?status=P'
# 用户代理
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
# 获取网页内容
res = requests.get(start_url, headers=headers) # 传入网页和用户代理
# 获取网页的html
soup = BeautifulSoup(res.text,'html.parser')# 分析文档
comments = soup.find_all('div',{'class':'comment-item'}) # 指定选取div标签下的类comment-item #soup.find_all找寻所有符合条件的数据# 解析短评# 定义几个列表,方便写入DataFrame
name_list = []
rating_list = []
time_list = []
content_list = []
vote_list = []for comment in comments: # for循环迭代将内容传入comment
# print(comment)# name = comment.find('a')['title'] and comment.find('a')['title'] or '' # 防止数据有空值报错# 用户名信息name = comment.find('a')['title'] # 用find方法找寻相关元素 name_list.append(username)# 评分星级信息
# rating = comment.find('span',{'class':'rating'})['title']# 另一种写法
# rating = comment.find('span',class_='rating')['title']# class类不能直接用,需要加下划线
# rating_list.append(rating)## 因为有的人没有评论,所以有的没有这个标签,我们要对此作出判断,没有这个标签就为空,否则报错try:rating = comment.find('span',class_='rating')['title']if rating:ratings = ratingelse:ratings = ''except Exception:ratings = ''rating_list.append(ratings) # 时间信息# 应对不是很规则的数据时
# time = comment.find('span',class_='comment-time').text.split() # text,只取文本信息 。split()表示只删除空格信息time = comment.find('span',class_='comment-time')['title'].split()[0] # 只取第一个数据time_list.append(time)# s.strip(x):删除s字符串中开头、结尾处、位于x删除序列的字符# split是分割函数,将字符串分割成"字符",保存在一个列表中,默认不带参数为空格分割# 评论信息content = comment.find('span',class_='short').textcontent_list.append(content)# 点赞数信息vote = comment.find('span', class_='vote-count').textvote_list.append(vote)# 把以上所有数据都合并
# data = username + ';' + rating + ';' + time + ';' + content + ';' + vote + '\n'
# print(data)-
# 将上述爬取到的数据写入DataFrame import pandas as pd df = pd.DataFrame({'name':name_list,'rating':rating_list,'time':time_list,'content':content_list,'vote':vote_list}) df.head() #显示前五条##name rating time content vote 0 禾口角刀牛 较差 2018-09-26 开心麻花出品,凡是沈腾主演的,就可以一看,别的暂时不用。 4793 1 朱古力 还行 2018-09-25 不能按主流国际电影标准评价,但作为满足观众的闹剧真心够癫狂,以及是挑战与迎合主流尺限的大开性... 130 2 王小叶儿 推荐 2018-09-26 比预告片好看很多,或者说看完电影才能get到预告里的喜点,和前几部不一样的是,这里面很多是情... 770 3 桃桃林林 较差 2018-09-30 开心麻花最差一部了,最大的问题是不好笑,尤其前半程,特别尬笑,看得人很无聊。后半段因为有些话... 1161 4 亵渎电影 较差 2018-09-30 还是开心麻花一贯的做法,改编自英国话剧《理查的姑妈》,踩在巨人的肩膀上,然后来了一通屎屁尿,... 230df.shape ## (20, 5)
1.2 获取多页数据
-
# 循环读取翻页数据 # https://movie.douban.com/subject/27092785/comments?status=P # 第一页 # https://movie.douban.com/subject/27092785/comments?start=0&limit=20&status=P&sort=new_score # 与第一页相同 # https://movie.douban.com/subject/27092785/comments?start=20&limit=20&status=P&sort=new_score # 第二页 # https://movie.douban.com/subject/27092785/comments?start=40&limit=20&status=P&sort=new_score # 第三页import requests from bs4 import BeautifulSoupheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'} # 定义几个列表,方便写入DataFrame name_list = [] rating_list = [] time_list = [] content_list = [] vote_list = [] def getContent(url):res = requests.get(url, headers=headers) soup = BeautifulSoup(res.text,'html.parser')comments = soup.find_all('div',{'class':'comment-item'})for comment in comments:name = comment.find('a')['title']name_list.append(name)time = comment.find('span',class_='comment-time').text.split()[0]time_list.append(time)content = comment.find('span',class_='short').textcontent_list.append(content)vote = comment.find('span',class_='vote-count').textvote_list.append(vote)try:rating = comment.find('span',class_='rating')['title']if rating:ratings = ratingelse:ratings = ''except Exception:ratings = ''rating_list.append(ratings) ## 循环获取页数 for i in range(10):print('Now the code is printing the page {}'.format(i+1)) # i+1表示从第一页开始num = 20*iurl = 'https://movie.douban.com/subject/27092785/comments?start='+str(num)+'&limit=20&status=P&sort=new_score'getContent(url)## Now the code is printing the page 1 Now the code is printing the page 2 Now the code is printing the page 3 Now the code is printing the page 4 Now the code is printing the page 5 Now the code is printing the page 6 Now the code is printing the page 7 Now the code is printing the page 8 Now the code is printing the page 9 Now the code is printing the page 10import pandas as pd df = pd.DataFrame({'name':name_list,'rating':rating_list,'time':time_list,'content':content_list,'vote':vote_list}) df.shape## (200, 5)
1.3 写入文件
-
# 设置文件路径 path = './data.txt' # 当前路径的data.txt文件可以看到爬取的数据 file = open(path,'w',encoding='utf8') # 设置编码 -
import requests from bs4 import BeautifulSoupheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}def getContent(url):res = requests.get(url, headers=headers) soup = BeautifulSoup(res.text,'html.parser')comments = soup.find_all('div',{'class':'comment-item'})for comment in comments:name = comment.find('a')['title']time = comment.find('span',class_='comment-time').text.split()[0]content = comment.find('span',class_='short').textvote = comment.find('span',class_='vote-count').texttry:rating = comment.find('span',class_='rating')['title']if rating:ratings = ratingelse:ratings = ''except Exception:ratings = ''data = name + ';' + rating + ';' + time + ';' + vote + ';' + content + '\n'# 可能会出现爬取频繁的情况,用try except Exception,try:file.write(data) # 如果可以写进去,就运行except Exception: # 不能就会遇到异常None -
for i in range(10):num = i*20Url = 'https://movie.douban.com/subject/27092785/comments?start='+str(num)+'&limit=20&status=P&sort=new_score'getContent(Url) file.close() # 要关闭资源 print("爬取完毕")
1.4 爬虫脚本与用户的自动化交互
-
movie = input('请输入一个网站:') # https://movie.douban.com/subject/27092785/ table = input('请输入你想保存的文件名') path = './'+table+'.txt' file = open(path,'w',encoding='utf8')## 请输入一个网站:https://movie.douban.com/subject/27092785/ 请输入你想保存的文件名:file -
import requests from bs4 import BeautifulSoupheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}def getContent(url):res = requests.get(url, headers=headers) soup = BeautifulSoup(res.text,'html.parser')comments = soup.find_all('div',{'class':'comment-item'})for comment in comments:name = comment.find('a')['title']time = comment.find('span',class_='comment-time').text.split()[0]content = comment.find('span',class_='short').textvote = comment.find('span',class_='vote-count').texttry:rating = comment.find('span',class_='rating')['title']if rating:ratings = ratingelse:ratings = ''except Exception:ratings = ''data = name + ';' + rating + ';' + time + ';' + vote + ';' + content + '\n'# 可能会出现爬取频繁的情况,用try except Exception,try:file.write(data) # 如果可以写进去,就运行except Exception: # 不能就会遇到异常None -
for i in range(10):num = i*20# https://movie.douban.com/subject/27092785/Url = movie+'/comments?start='+str(num)+'&limit=20&status=P&sort=new_score'getContent(Url) file.close() # 要关闭资源 print("爬取完毕")## 爬取完毕import pandas as pd data = pd.read_csv("./file.txt",error_bad_lines=False) # error_bad_lines=False解决读取文件报错问题 data # 可查看数据
1.5 爬取短评遇到的问题解决办法
-
# 处理爬着爬着突然没有标签的数据的解决办法 try:rating = comment.find('span',class_='rating')['title']if rating:ratings = ratingelse:ratings = ''except Exception:ratings = ''
第二章 数据清洗、分析与数据可视化(数据接上面)
2.1 数据清洗,选取与分析
-
import pandas as pd import matplotlib.pyplot as plt -
# 先把文件读取进来 data = pd.read_csv("file.txt",sep=';') # 用分号隔开 data.columns = ['name','rating','data','likes','comment'] # 给五个元素命名 datadata.count()## name 225 # 225行数据 rating 199 data 199 likes 199 comment 199 dtype: int64data = data.dropna() # 把所有NaN值删掉,这些含NaN的值是无法进行操作的 datadata.count()## name 199 # 删除了为NaN的数据 rating 199 data 199 likes 199 comment 199 dtype: int64# 有多少人给了力荐的评价 data['rating'].value_counts()## 很差 64 较差 58 还行 30 推荐 29 力荐 18 Name: rating, dtype: int64# 将数据画成饼图 # 中文设置 plt.rcParams["font.sans-serif"] = ['KaiTi'] plt.rcParams['axes.unicode_minus'] = False pd.DataFrame(data['rating'].value_counts()).plot(kind='pie',subplots=True) plt.show()# 排序 # 1、按照rating和点赞数来排序 # 默认从力荐往下排序,点赞数从低到高 data = data.sort_values(['rating','likes'],ascending=False) # inplace=True写这种方式就不用赋值给data,#ascending=False把它设置为降序的方式 data.head()# 2、取出所有符合条件的数据 data5 = data.loc[data['rating'] == '力荐'] data5 = data5.sort_values('likes',ascending=False) data5# 分析水军刷榜行为 shuabang = pd.DataFrame(data['comment'].value_counts()) # 取出comment及其对应的数量 # value_counts()记数 shuabang = shuabang.reset_index() # 防止comment当作index,重置一下index shuabangshuabang[shuabang['comment']>1].count() # 查询相同的评论大于1的comment## index 12 comment 12 # 12条大于1的 dtype: int64
2.2 词云图
-
先导入所有包
-
# pip install jieba 先下载这个包 # 再下载wordcloud这个包 # 安装教程 https://zhuanlan.zhihu.com/p/127268741# 导包 import jieba from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator import json import matplotlib as mpl mpl.rcParams['font.sans-serif'] = ['Droid Sans Fallback'] import matplotlib.pyplot as plt import jieba.analyse from PIL import Image,ImageSequence import numpy as py from matplotlib.font_manager import FontProperties
-
-
示例(数据接2.1):
-
# 直接对数据进行词图展示 word = ' '.join(data['comment']) # 将评论全连在一起 # 下载DroidSansFallback.ttf,以便放入WordCloud wc = WordCloud(font_path='DroidSansFallback.ttf').generate(word) # 把拿到的所有数据放进去 plt.figure(figsize=(20,10)) # 设置画布大小 plt.imshow(wc) # 热图绘制 plt.show()
-
# 对词频次数出现最多的进行展示 # 切词 comment_after_split = jieba.cut(str(word),cut_all=False) comment_after_split# <generator object Tokenizer.cut at 0x0000022537615CF0># join 把词连起来 word = ' '.join(comment_after_split) # 将切好的词连起来 wc = WordCloud(font_path='DroidSansFallback.ttf').generate(word) # 把拿到的所有数据放进去 plt.figure(figsize=(20,10)) # 设置画布大小 plt.imshow(wc) # 热图绘制 plt.show() # 展示的是出现的词频次数最多的 -
炫酷的自定义词云图
-
# 可以加多个屏蔽词 stopwords = STOPWORDS.copy() # 对STOPWORDS这个包进行拷贝 stopwords.add("剧情") stopwords.add("一部") stopwords.add("一个") stopwords.add("没有") stopwords.add("什么") stopwords.add("有点") stopwords.add("这部") stopwords.add("这个") stopwords.add("不是") stopwords.add("真的") stopwords.add("感觉") stopwords.add("觉得") stopwords.add("还是") stopwords.add("电影") stopwords.add("就是") stopwords.add("可以")background_Image = plt.imread('cute.jpg') # 把照片引进来wc = WordCloud(background_color = 'White',#背景颜色mask = background_Image,font_path='DroidSansFallback.ttf',stopwords = stopwords # 人工添加停顿词) -
wc.generate(word) # 把切好的词放进去 img_colors = ImageColorGenerator(background_Image) # 用我们已经选好的照片的颜色进行渲染,而不是他自定义的颜色 wc.recolor(color_func=img_colors) # 将渲染的颜色传进来,这样才能给图片的颜色重新上色 wc.to_file('test.jpg') # 生成图片到当前文件夹 plt.figure(figsize=(20,10)) # 设置画布大小 plt.imshow(wc) # 热图绘制 plt.axis('off') plt.show() # 关闭坐标轴
-
2.3 玫瑰图
-
# 先下载pyecharts这个包 #https://www.cnblogs.com/kobewang/p/9400774.html pip install pyecharts-0.1.9.4-py2.py3-none-any.whl# 导包 from pyecharts import Pierate = " ".join(data['rating']) # v1 = (rate) ratev1 = (rate.count('力荐')) v2 = (rate.count('推荐')) v3 = (rate.count('还行')) v4 = (rate.count('较差')) v5 = (rate.count('很差')) v5 ## 64attr = ['五星', '四星', '三星', '二星', '一星'] # 给评价赋星级 v = [v1, v2, v3, v4, v5] pie = Pie('电影评分玫瑰星级图',title_pos='left') pie.add('',attr,v,rosetype='area',is_label_show=True,is_legend_show=False,radius=[30,100]) # is_label_show=True显示比例,rosetype='area'变得像玫瑰一样,is_legend_show=False不展示标签 # radius=[30,50] 设置距离圆心的距离 pie.render("test.html") pie.render("test.html") # 网页查看该图片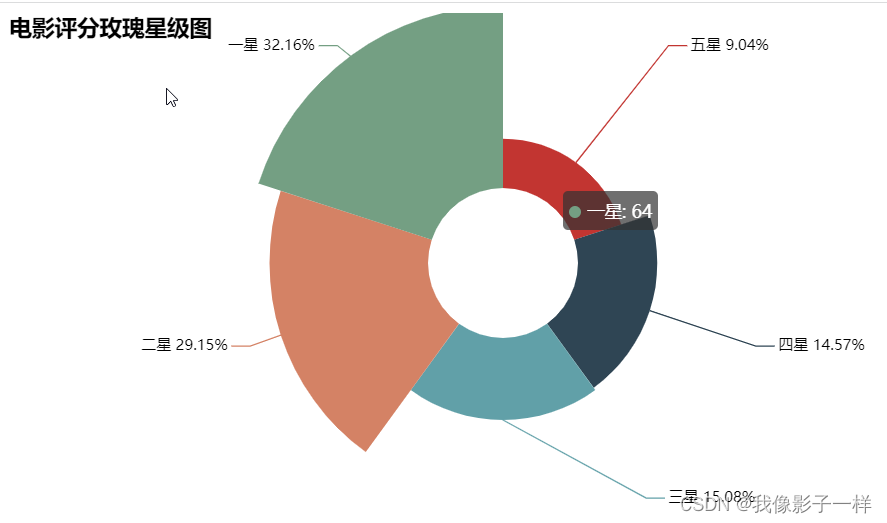
2.4 地图
-
# 需要地图就下载下列包,不然画出来的图职业散点,没地图,或者出现地图显示不全等等问题 # 一个一个安装 pip install echarts-countries-pypkg pip install echarts-china-provinces-pypkg pip install echarts-china-cities-pypkg pip install echarts-china-counties-pypkg pip install echarts-china-misc-pypkg -
# 导包 from pyecharts import Geo import json import io import sys import pandas as pd -
# 拿数据,从本地的cat.txt拿数据 data = pd.read_csv("cat.txt",sep=';') data.columns = ['name','time','city','rating','comment'] # 定义列名称 data.head() ##name time city rating comment 0 yDs777532237 2019-02-24 沈阳 2.0 烂片,没底线 1 LJ倚 2019-02-24 成都 4.0 蛮搞笑的,不过剧情还差了一点,挺好看的 2 zSHUANGI 2019-02-24 通化 5.0 挺好看的,真的挺好 3 WfD214967004 2019-02-24 佳木斯 5.0 非常好看,😃😃😃 4 淸莯a 2019-02-24 黑河 1.0 真的不好看, -
city_list = [] # 定义一个列表 for i in data['city']: # 迭代每个城市city_list.append(i) # 将每个城市传入列表中result = {} for i in set(city_list): # set(city_list) 取一个为一的城市,不重复。例如,10个沈阳他只取一个result[i] = citt_list.count(i) # 把迭代的城市放入result中,再对这些城市记数 print(result) # result是一个字典## {'通化': 4, '丽江': 15, '肇庆': 15, '赣榆': 15, '通辽': 15, '张家口': 10, '孝感': 16, '汝城县': 16, '京山': 14, '呼和浩特': 15, '昆明': 15, '邹城': 16, '成都': 9, '随州': 12, '广州': 45, '北京': 45, '郑州': 15, '遵义': 15, '平顶山': 10, '哈尔滨': 7, '无为': 15, '合肥': 28, '江门': 18, '廊坊': 16, '黑河': 6, '永川': 15, '沈阳': 2, '天津': 40, '诸城': 15, '阜新': 26, '义乌': 15, '南京': 12, '德州': 8, '深圳': 2, '鞍山': 15, '常州': 27, '惠州': 16, '廉江': 15, '保定': 15, '邢台': 15, '上海': 30, '内江': 9, '佳木斯': 34, '温州': 4, '大理': 5, '监利': 15, '徐州': 7}data = [] for item in result:data.append((item,result[item])) print(data) # data是一个大列表,里面有许多小元组## [('通化', 4), ('丽江', 15), ('肇庆', 15), ('赣榆', 15), ('通辽', 15), ('张家口', 10), ('孝感', 16), ('汝城县', 16), ('京山', 14), ('呼和浩特', 15), ('昆明', 15), ('邹城', 16), ('成都', 9), ('随州', 12), ('广州', 45), ('北京', 45), ('郑州', 15), ('遵义', 15), ('平顶山', 10), ('哈尔滨', 7), ('无为', 15), ('合肥', 28), ('江门', 18), ('廊坊', 16), ('黑河', 6), ('永川', 15), ('沈阳', 2), ('天津', 40), ('诸城', 15), ('阜新', 26), ('义乌', 15), ('南京', 12), ('德州', 8), ('深圳', 2), ('鞍山', 15), ('常州', 27), ('惠州', 16), ('廉江', 15), ('保定', 15), ('邢台', 15), ('上海', 30), ('内江', 9), ('佳木斯', 34), ('温州', 4), ('大理', 5), ('监利', 15), ('徐州', 7)]geo = Geo("《李茶的姑妈》粉丝人群地理位置") attr,value = geo.cast(data) print("data:",json.dumps(data, ensure_ascii=False)) #json.dumps将一个Python数据结构转换为JSON print("attr:",json.dumps(attr, ensure_ascii=False)) print("value:",value)## data: [["通化", 4], ["丽江", 15], ["肇庆", 15], ["赣榆", 15], ["通辽", 15], ["张家口", 10], ["孝感", 16], ["汝城县", 16], ["京山", 14], ["呼和浩特", 15], ["昆明", 15], ["邹城", 16], ["成都", 9], ["随州", 12], ["广州", 45], ["北京", 45], ["郑州", 15], ["遵义", 15], ["平顶山", 10], ["哈尔滨", 7], ["无为", 15], ["合肥", 28], ["江门", 18], ["廊坊", 16], ["黑河", 6], ["永川", 15], ["沈阳", 2], ["天津", 40], ["诸城", 15], ["阜新", 26], ["义乌", 15], ["南京", 12], ["德州", 8], ["深圳", 2], ["鞍山", 15], ["常州", 27], ["惠州", 16], ["廉江", 15], ["保定", 15], ["邢台", 15], ["上海", 30], ["内江", 9], ["佳木斯", 34], ["温州", 4], ["大理", 5], ["监利", 15], ["徐州", 7]] attr: ["通化", "丽江", "肇庆", "赣榆", "通辽", "张家口", "孝感", "汝城县", "京山", "呼和浩特", "昆明", "邹城", "成都", "随州", "广州", "北京", "郑州", "遵义", "平顶山", "哈尔滨", "无为", "合肥", "江门", "廊坊", "黑河", "永川", "沈阳", "天津", "诸城", "阜新", "义乌", "南京", "德州", "深圳", "鞍山", "常州", "惠州", "廉江", "保定", "邢台", "上海", "内江", "佳木斯", "温州", "大理", "监利", "徐州"] value: [4, 15, 15, 15, 15, 10, 16, 16, 14, 15, 15, 16, 9, 12, 45, 45, 15, 15, 10, 7, 15, 28, 18, 16, 6, 15, 2, 40, 15, 26, 15, 12, 8, 2, 15, 27, 16, 15, 15, 15, 30, 9, 34, 4, 5, 15, 7]# 画图 miss_city = [] miss_value = []# 手动添加echarts中没有的地理坐标 # geo.add_coordinate("射阳",120.229986,33.758361) # geo.add_coordinate("辽中",122.765409,41.516826) # geo.add_coordinate("共青城",115.808844,29.248316) # geo.add_coordinate("邹平",117.743109,36.862989) # geo.add_coordinate("淮阳",114.886153,33.731561) # geo.add_coordinate("万州", 108.380246, 30.807807) # geo.add_coordinate("牟平", 121.600455, 37.387061) # geo.add_coordinate("宁国", 118.983171, 30.633882) # geo.add_coordinate("黔南", 107.523205, 26.264535) # geo.add_coordinate("泗洪", 33.4761, 118.2236) # geo.add_coordinate("中牟", 34.7189, 113.9763) # geo.add_coordinate("黔西南", 25.0879, 104.9064) # geo.add_coordinate("苍南", 27.5183,120.4258) # geo.add_coordinate("浠水", 30.4519,115.2665) # geo.add_coordinate("泗洪", 33.4761, 118.2236) try:geo.add("",attr,value,visual_range[0,120],visual_text_color="#fff",symbol_size=20,is_visualmap=True,is_piecewise=True) # symbol_size标识标记的大小,visual_range表示图例条范围,is_visualmap显示图例条 # visual_text_color图例条颜色 except Exception:passgeo.render("fans_geo.html") # 可查看地图信息
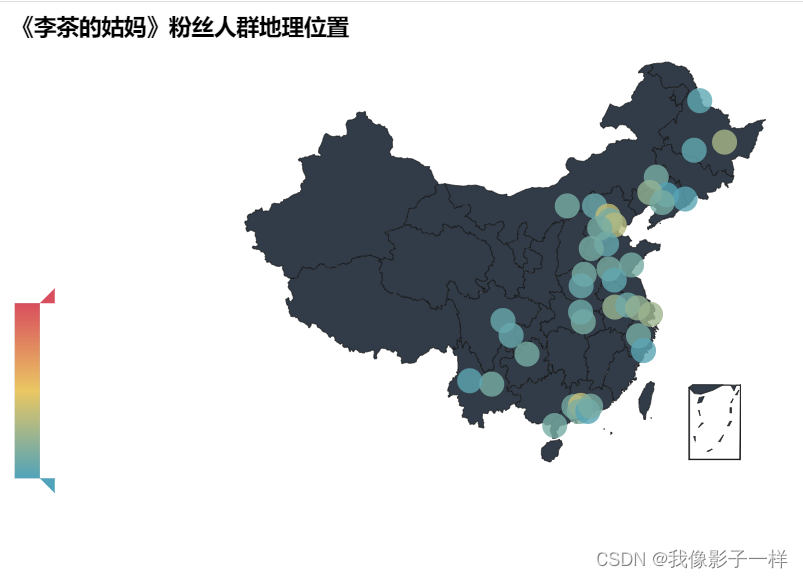
这篇关于豆瓣爬虫实战:(电影短评)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





