本文主要是介绍入门爬虫示例-爬取豆瓣短评,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
群里有个小妹妹,让我帮她写的代码,好像是作业什么的。花了几分钟看了一下,随便写写,分享给有需要的童鞋,我用python 3 写的,实现的功能就是:爬取豆瓣短评,然后将数据写入本地的excel表格,数据大概有,电影名称,评分,评论人数,短评四项,稍微修改下也可以爬取其他数据。
这属于入门学习的爬虫,博客里的代码,复制到本地,直接就能跑,有些包需要自己安装一下,安装教程自行百度。代码如下:
#-*- coding:UTF-8 -*-
#2018/12/24
#made in baiye
#爬取豆瓣短评,然后将数据写入本地的excel表格,数据大概有,电影名称,评分,评论人数,短评四项。import requests
from bs4 import BeautifulSoup
import re
import time
import xlrd
import xlwt
from xlutils.copy import copy#获取页面源码
def getHTMLText(url,k):try:if(k==0):kw={}else: kw={'start':k,'filter':''}r = requests.get(url,params=kw,headers={'User-Agent': 'Mozilla/4.0'})r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:print("Failed!")#通过BeautifulSoup查找所需要的数据
def getData(html,n,files):soup = BeautifulSoup(html, "html.parser")movieList=soup.find('ol',attrs={'class':'grid_view'})#找到第一个class属性值为grid_view的ol标签for movieLi in movieList.find_all('li'):#找到所有li标签n += 1data = []#声明一个list,将得到的数据添加进list#得到电影名字movieHd=movieLi.find('div',attrs={'class':'hd'})#找到第一个class属性值为hd的div标签movieName=movieHd.find('span',attrs={'class':'title'}).getText()#找到第一个class属性值为title的span标签#也可使用.string方法data.append(movieName)#得到电影的评分movieScore=movieLi.find('span',attrs={'class':'rating_num'}).getText()data.append(movieScore)#得到电影的评价人数movieEval=movieLi.find('div',attrs={'class':'star'})movieEvalNum=re.findall(r'\d+',str(movieEval))[-1]data.append(movieEvalNum)# 得到电影的短评movieQuote = movieLi.find('span', attrs={'class': 'inq'})if(movieQuote):data.append(movieQuote.getText())else:data.append("无")#将数据循环写入excel文件c = 0for r in data:rexcel = xlrd.open_workbook(files) # 用wlrd提供的方法读取一个excel文件excel = copy(rexcel) # 用xlutils提供的copy方法将xlrd的对象转化为xlwt的对象table = excel.get_sheet(0) # 用xlwt对象的方法获得要操作的sheetif len(r) > 32767:continuetable.write(n, c, r) # xlwt对象的写方法,参数分别是行、列、值c += 1excel.save(files)
if __name__ == '__main__':k=0n = 0files = 'top100.xls'#保存的位置,默认是当前执行目录下。workbook = xlwt.Workbook()sheet = workbook.add_sheet("sheet1")sheet.write(0,0,"电影名称")sheet.write(0,1,"评分")sheet.write(0,2,"评论人数")sheet.write(0,3,"短评")workbook.save(files)#当前目录下创建test.xls文件basicUrl='https://movie.douban.com/top250'while k<=75:html=getHTMLText(basicUrl,k)time.sleep(2)k+=25#每页25条,循环一次加25getData(html,n,files)n += 25#用于控制excel表的行数
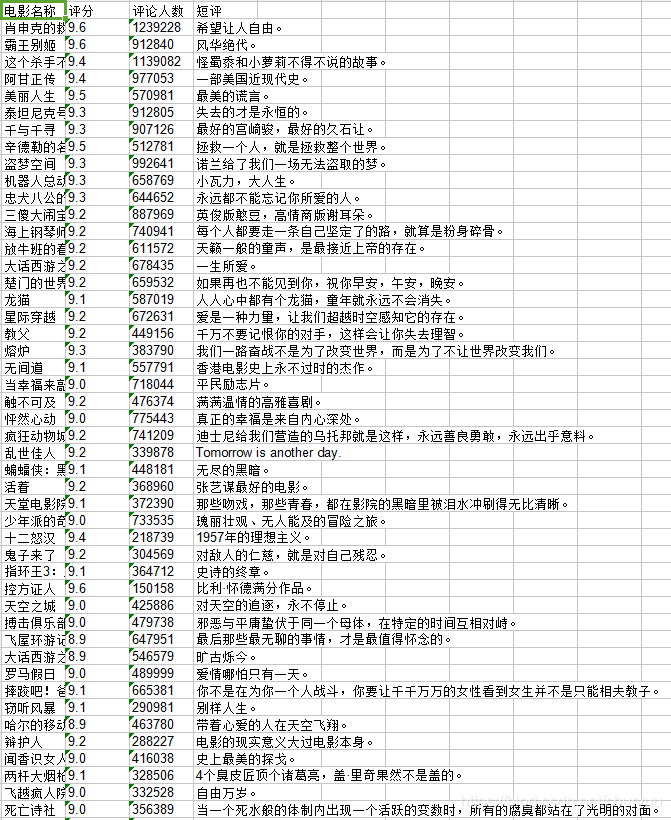
爬取部分结果展示:
有问题可以随时提出,欢迎加群交流。
这篇关于入门爬虫示例-爬取豆瓣短评的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








