相关性专题

【python 相关性分析】Python绘制相关性热力图
在数据分析时,经常会针对两个变量进行相关性分析。在Python中主要用到的方法是pandas中的corr()方法。 corr():如果由数据框调用corr函数,那么将会计算每个列两两之间的相似度,返回DataFrame # -*- coding: utf-8 -*-# 导入包import pandas as pdimport numpy as npimport matplotlib.py


自然语言处理-应用场景-问答系统(知识图谱)【离线:命名实体识别(BiLSTM+CRF>维特比算法预测)、命名实体审核(BERT+RNN);在线:句子相关性判断(BERT+DNN)】【Flask部署】
一、背景介绍 什么是智能对话系统? 随着人工智能技术的发展, 聊天机器人, 语音助手等应用在生活中随处可见, 比如百度的小度, 阿里的小蜜, 微软的小冰等等. 其目的在于通过人工智能技术让机器像人类一样能够进行智能回复, 解决现实中的各种问题. 从处理问题的角度来区分, 智能对话系统可分为: 任务导向型: 完成具有明确指向性的任务, 比如预定酒店咨询, 在线问诊等等.非任务导向型:

跨模态检索研究进展综述【跨模态检索的核心工作在于:①不同模态数据的特征提取、②不同模态数据之间内容的相关性度量】【主流研究方法:基于传统统计分析的技术、基于深度学习的技术】【哈希编码提高检索速度】
随着互联网上多媒体数据的爆炸式增长,单一模态的检索已经无法满足用户需求,跨模态检索应运而生. 跨模态检索旨在以一种模态的数据去检索另一种模态的相关数据。 跨模态检索的核心任务是:数据特征提取 和 不同模态数据之间内容的相关性度量。 文中梳理了跨模态检索领域近期的研究进展,从以下角度归纳论述了跨模态检索领域的研究成果.: 传统方法;深度学习方法;手工特征的哈希编码方法;深度学习的哈希编码方法

Spark Mllib之相关性计算和假设检验
Spark Mllib之相关性计算和假设检验 原创: 小小虫 一、皮尔逊相关性和斯皮尔曼相关性 1.1 皮尔逊相关性 要理解 Pearson 相关系数,首先要理解协方差(Covariance)。协方差表示两个变量 X,Y 间相互关系的数字特征,其计算公式为: Pearson 相关系数公式如下: 由公式可知,Pearson 相关系数是用协方差除以两个变

计算特征相关性的方法,特征提取的方法,如何判断特征是否重要
计算特征相关性可以用皮尔逊系数 (公式及含义解释:表示两组数据的线性关系程度,取值为[-1,1]),衡量的是变量之间的线性相关性,简单快速,但是只对线性关系敏感,非线性不适合;计算特征相关性的指标还有互信息MIC和距离相关系数(Python gist包),取值为[0,1]。 特征工程中包含特征选择和特征提取(区别),特征选择用的是Lasso,OMP,WOMP(特征排序)算法(流程讲清楚),

R 相关与相关性的显著性检验
1.数据说明 R语言的自带的数据包中states.x77(关于美国50个州的某些数据)第1至6列的50份数据从统计的角度以及R语言的角度进行分析,看看R语言是怎么做相关分析的,同时怎么看分析出的结果 首先我们观察一下states.x77中第1至6列的数据及其意义 列名解释单位Population人口人Income人均收入美元/人Illiteracy文盲率%Life Exp预期寿命年Murder

两个基因相关性CPTAC蛋白组数据
目录 蛋白数据下载 ①蛋白数据下载 1,TCGA-选择泛癌数据 2,TCGA-TCPA 3,CPTAC(非TCGA) ②蛋白相关性分析 1,数据整理 2,蛋白相关性分析 PCAS在线分析 蛋白数据下载 CPTAC蛋白组学数据库介绍及数据下载分析 – 王进的个人网站 (jingege.wang) ①蛋白数据下载 可以下载泛癌蛋白数据:UCSC Xena (xena

两个基因相关性细胞系(CCLE)(升级)
目录 单基因CCLE数据 ①细胞系转录组CCLE数据下载 ②单基因泛癌表达 CCLE两个基因相关性 ①进行数据整理 ②相关性分析 单基因CCLE数据 ①细胞系转录组CCLE数据下载 基因在各个细胞系表达情况_ccle expression 23q4-CSDN博客 rm(list = ls())library(tidyverse)library(ggpubr)rt

八-工具包3-pandas数据清洗及相关性
数据清洗概述 数据清洗是对一些没有用的、不合理的数据进行处理的过程。 很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理。 样本数据: from io import StringIOimport pandas as pdcsv_data = """PID,ST_NUM,ST_NAME,OWN_OCCUPIED,NU

文本相关性PM25算法
1. BM25算法 BM25是二元独立模型的扩展,其得分函数有很多形式,最普通的形式如下: ∑ 其中,k1,k2,K均为经验设置的参数,fi是词项在文档中的频率,qfi是词项在查询中的频率。 K1通常为1.2,k2通常为0-1000 K的形式较为复杂 K= 上式中,dl表示文档的长度,avdl表示文档的平均长度,b通常取0

基因相关性(信息学奥赛一本通-T1131)
【题目描述】 为了获知基因序列在功能和结构上的相似性,经常需要将几条不同序列的DNA进行比对,以判断该比对的DNA是否具有相关性。 现比对两条长度相同的DNA序列。定义两条DNA序列相同位置的碱基为一个碱基对,如果一个碱基对中的两个碱基相同的话,则称为相同碱基对。接着计算相同碱基对占总碱基对数量的比例,如果该比例大于等于给定阈值时则判定该两条DNA序列是相关的,否则不相关。 【输入】 有三行,第

搜索引擎优化相关性排名技术浅析
相关度排序技术的产生主要是由搜索引擎的特点决定的。首先,现代搜索引擎能够访问的 Web网页数量已经达到上十亿的规模,哪怕用户只是搜索其中很少的一部分内容,基于全文搜索技术的搜索引擎也能返回成千上万的页面。即便这些结果网页都是用户所需要的,用户也没有可能对所有的网页浏览一遍,所以能够将用户最感兴趣的结果网页放于前面,势必可以增强搜索引擎用户的满意度。其次,搜索引擎用户自身的检索专业能力通常很有限,在
Elastic Search 8.14:更快且更具成本效益的向量搜索,使用 retrievers 和重新排序提升相关性,RAG 和开发工具
作者:来自 Elastic Yaru Lin, Ranjana Devaji 我们致力于突破搜索开发的界限,并专注于为搜索构建者提供强大的工具。通过我们的最新更新,Elastic 对于处理以向量表示的大量数据的客户来说变得更加强大。这些增强功能保证了更快的速度、降低的存储成本以及软件和硬件之间的无缝集成。 Elastic Search 8.14 现已在 Elastic Cloud 上推出,

【Python特征工程系列】基于相关性分析的特征重要性分析(案例+源码)
这是我的第295篇原创文章。 一、引言 相关性分析提供了一种简单而直观的方法来初步筛选特征。通过计算特征与目标变量之间的相关系数,我们能够快速地评估各个特征与预测目标之间的线性关系强度。 在统计学中,最常用的相关系数有两种:皮尔逊相关系数(Pearson correlation coefficient)和斯皮尔曼等级相关系数(Spearman's rank cor
从零开始学统计 04 | 协方差与相关性分析
一、老板的任务 老板今天又给一个任务: 计算肝脏细胞中 X 基因与 Y 基因的关系。 现在,两个基因在各个细胞中的表达值都有了。 绘制不同细胞中 X,Y 基因的表达值在坐标轴上。 计算 X 基因和 Y 基因在5个细胞中的均值,标准差。 因为这些测量值都是来自同一个细胞,所以我们可以成对来看: 那么这样成对的测量可以告诉我们哪些信息呢? 现在,先将一对细胞连接,绘制一个点
Python数据分析之绘制相关性热力图的完整教程
前言 文章将介绍如何使用Python中的Pandas和Seaborn库来读取数据、计算相关系数矩阵,并绘制出直观、易于理解的热力图。我们将逐步介绍代码的编写和执行过程,并提供详细的解释和示例,以便读者能够轻松地跟随和理解。 大家记得需要准备以下条件数据:(大家可以看我上一篇文章) 确保数据集是干净的,没有缺失值或异常值。只选择数值型数据列进行相关性分析。 第一步:导入库 import p

【Excel】excel计算相关性系数R、纳什效率系数NSE、Kling-Gupta系数KGE
对于采用的数据: B2:B10958是观测值的所在范围 C2:C10958是模型计算值的所在范围 一、相关系数R是用来衡量两个变量之间线性关系强度和方向的统计量。在水文学和气象学中,常用的相关系数是皮尔逊相关系数(Pearson correlation coefficient),它的取值范围在 -1 到 1 之间,公式如下: excel计算R的公式如下: =
MATLAB相关性分析
假设有4个特征值,分析4个特征值与因变量相关性 首先分析其各特征值的相关性程度 data=xlsread('data_path.xlsx');% 获取各特征值相关性correlation_matrix = corr(data(:, 1:end-1), data(:, end), 'type', 'Pearson');% 可视化相关性heatmap(correlation_matrix, '
Python相关性分析
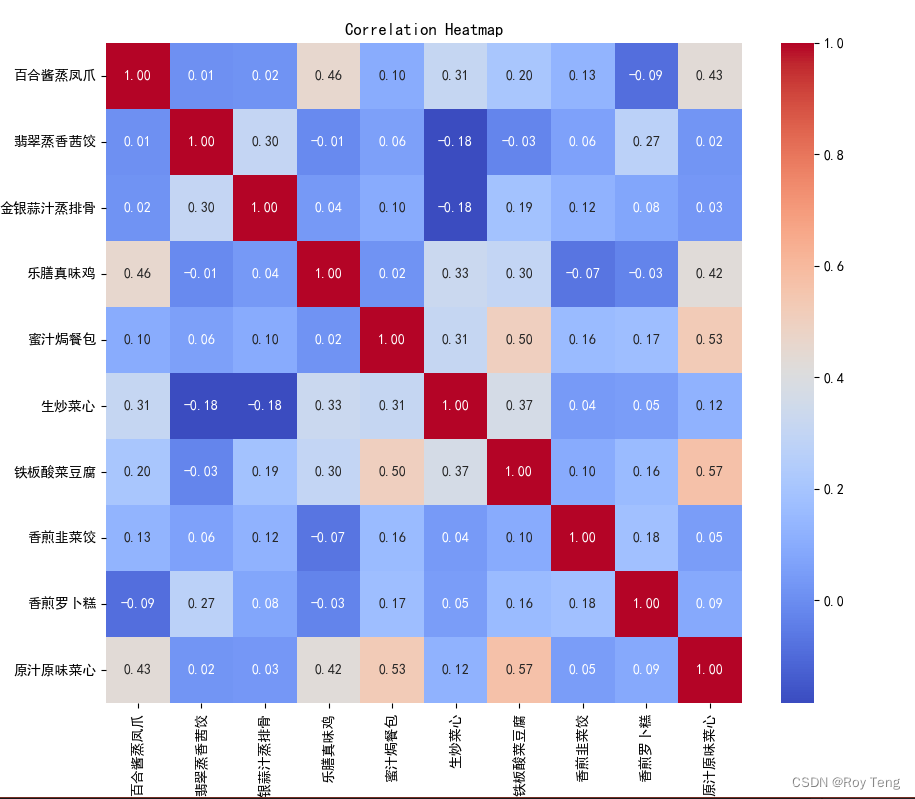
分析连续变量之间线性相关程度的强弱,并用适当的统计指标表示出来的过程称为相关分析。 可以直接绘制散点图,或者绘制散点图矩阵,或者计算相关系数来进行相关分析。 相关系数的计算如下所示: 示例数据: 计算百合酱蒸凤爪与其他几种菜品的相关系数代码如下: import pandas as pdcatering_sale = r'D:\daily\data\catering_sale_a
【概率论】4-6:协方差和相关性(Covariance and Correlation)
原文地址1:https://www.face2ai.com/Math-Probability-4-6-Covariance-and-Correlation转载请标明出处 Abstract: 本文介绍协方差和相关性的基础知识,以及部分性质 Keywords: Covariance,Correlation,Properties of Covariance and Correlation 协方差和相关
R、Python的Copula变量相关性分析及AI大模型应用
在工程、水文和金融等各学科的研究中,总是会遇到很多变量,研究这些相互纠缠的变量间的相关关系是各学科的研究的重点。虽然皮尔逊相关、秩相关等相关系数提供了变量间相关关系的粗略结果,但这些系数都存在着无法克服的困难。例如,皮尔逊相关系数只能反映变量间的线性相关,而秩相关则更多的适用于等级变量。大多数情况下变量间的相关性非常复杂,而且随着变量取值的变化而变化,而这些相关系数都是全局性的,因此无法提供变量
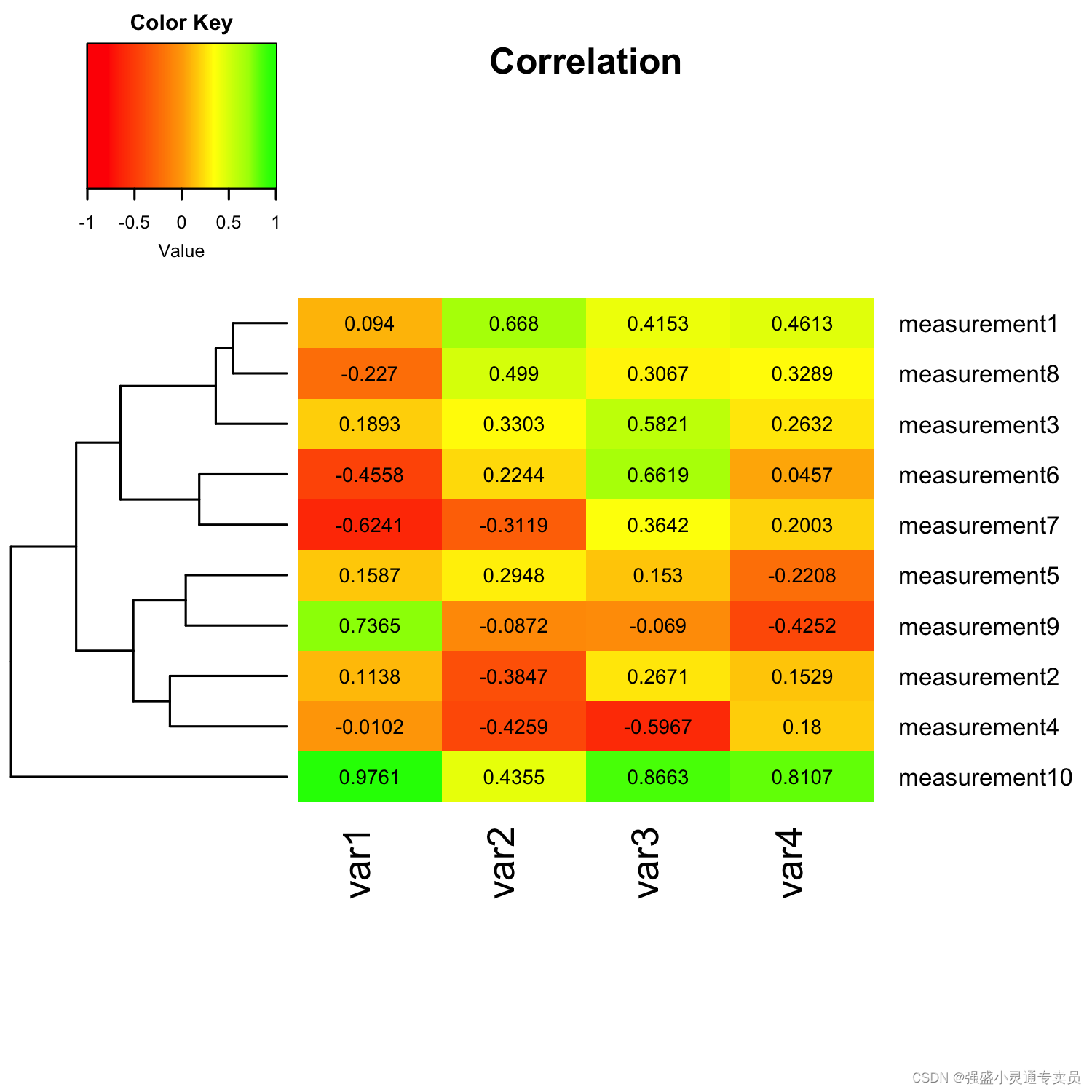
【SCI绘图】【热力图系列1 R】多特征相关性分析热力图R语言实现
SCI,CCF,EI及核心期刊绘图宝典,爆款持续更新,助力科研! 本期分享: 【SCI绘图】【热力图系列1 R】多特征相关性分析热力图R语言实现 1.环境准备 library(gplots)library(RColorBrewer) 2.数据示例 ############################################################ re
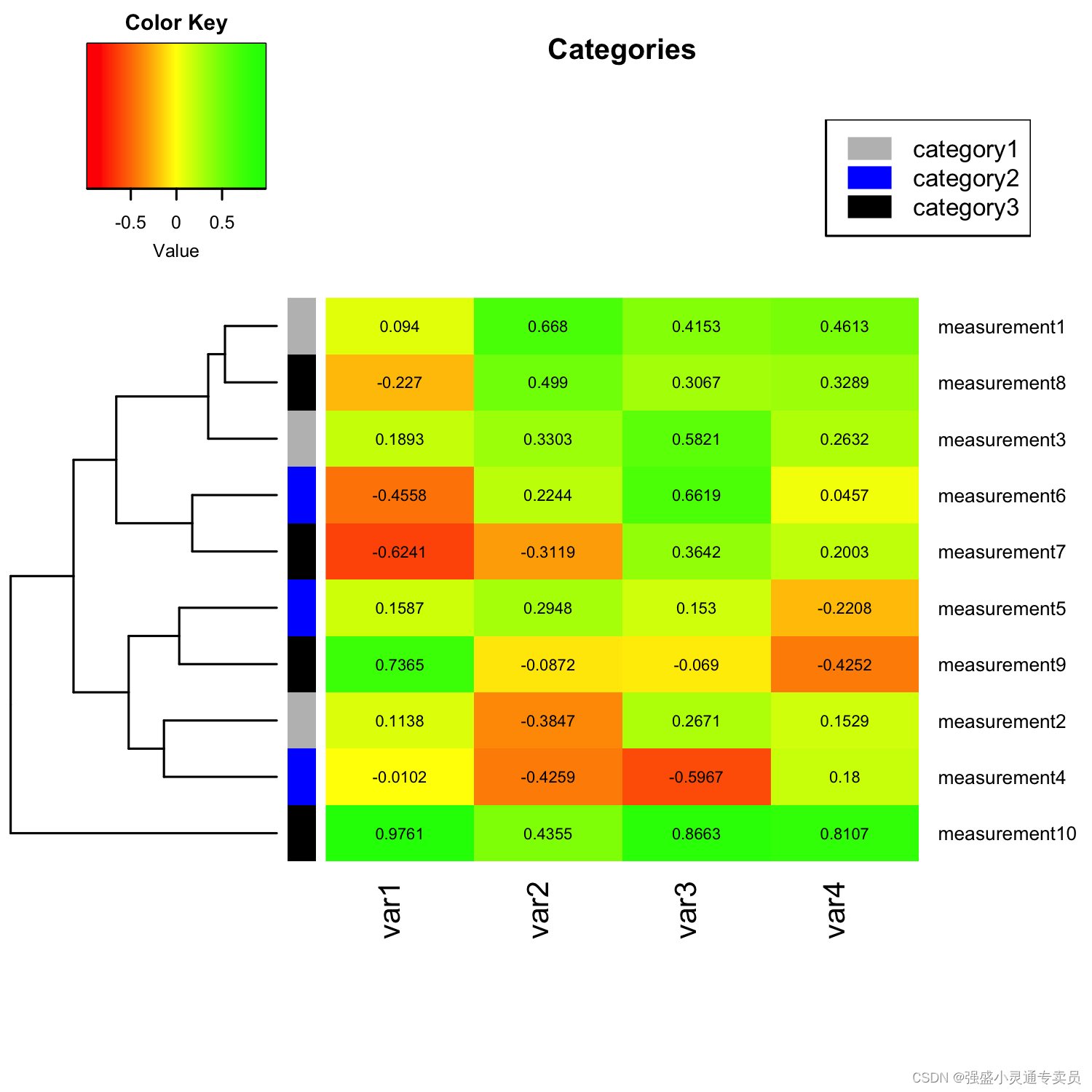
【SCI绘图】【热力图系列2 R】多特征相关性分析热力图指定聚类 R
SCI,CCF,EI及核心期刊绘图宝典,爆款持续更新,助力科研! 本期分享: 【SCI绘图】【热力图系列2 R】多特征相关性分析热力图指定聚类 R 1.环境准备 library(gplots)library(RColorBrewer) 2.数据读取 ############################################################ re
使用阿里云试用Elasticsearch学习:1.6 基础入门——排序与相关性
默认情况下,返回的结果是按照 相关性 进行排序的——最相关的文档排在最前。 在本章的后面部分,我们会解释 相关性 意味着什么以及它是如何计算的, 不过让我们首先看看 sort 参数以及如何使用它。 排序 为了按照相关性来排序,需要将相关性表示为一个数值。在 Elasticsearch 中, 相关性得分 由一个浮点数进行表示,并在搜索结果中通过 _score 参数返回, 默认排序是 _score