相似性专题

【机器学习】4. 相似性比较(二值化数据)与相关度(correlation)
SMC Simple Matching Coefficient 评估两组二进制数组相似性的参数 SMC = (f11 + f00) / (f01+f10+f11+f00) 其中,f11表示两组都为1的组合个数,f10表示第一组为1,第二组为0的组合个数。 这样做会有一个缺点,假设是比较稀疏的数据,如今天去哪一个地区,地区有成千上万个,但是去的只有一个地区。那么就会导致f00非常的大,如此计算

LSHForest进行文本相似性计算
LSH Forest: Locality Sensitive Hashing forest,局部敏感哈希森林, 是最近邻搜索方法的代替,排序实现二进制搜索和32位定长数组和散列,使用hash家族的随机投影方法近似余弦距离。 随机投影树,对所有的数据进行划分,将每次搜索与计算的点的数目减小到一个可接受的范围,然后建立多个随机投影树构成随机投影森林,将森林的综合结果作为最终的结果。 随机投影树的构

【数据挖掘】机器学习中相似性度量方法-余弦相似度
写在前面: 首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。 路虽远,行则将至;事虽难,做则必成。只要有愚公移山的志气、滴水穿石的毅力,脚踏实地,埋头苦干,积跬步以至千里,就一定能够把宏伟目标变为美好现实。 “相似性度量(similarity measurement)”系列文章:、 【数据挖掘】机器学习中
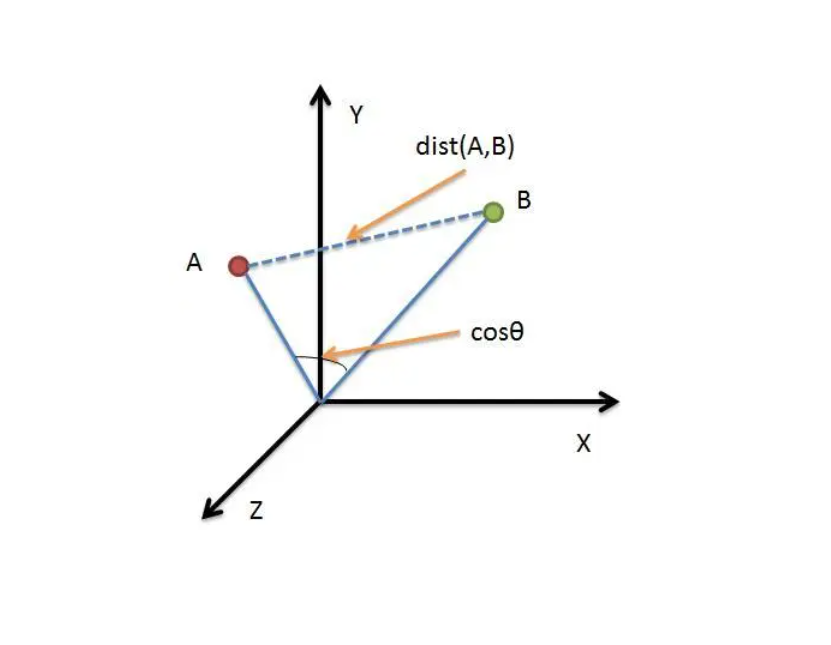
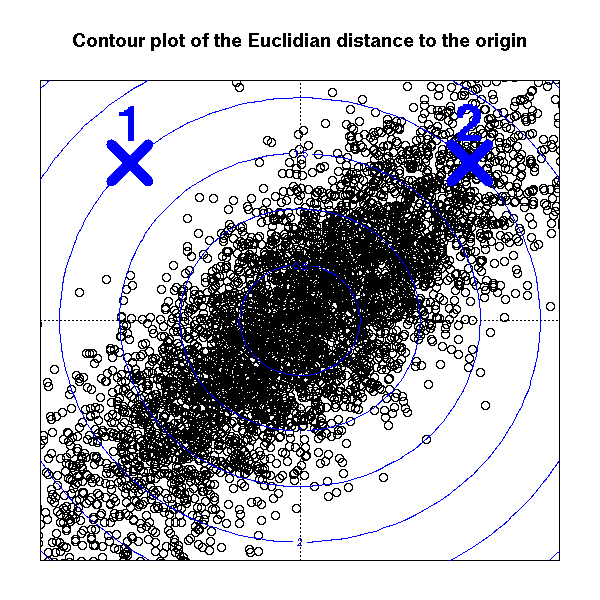
【数据挖掘】机器学习中相似性度量方法-欧式距离
写在前面: 首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大能力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。 路虽远,行则将至;事虽难,做则必成。只要有愚公移山的志气、滴水穿石的毅力,脚踏实地,埋头苦干,积跬步以至千里,就一定能够把宏伟目标变为美好现实。 最近在做实际项目时,遇到需要计算两个向量的相似性,即需要计算不同数据样本之间的相似度。计算样本之间
人脑功能连接与相似性分析:基于Python
文章来源于微信公众号(茗创科技),欢迎有兴趣的朋友搜索关注。 本文将以人脑腹侧颞叶皮层的多体素模式分析(MVPA)来探讨人脑功能连接与相似性分析。MVPA被认为是一个监督分类问题,分类器试图捕捉fMRI活动的空间模式和实验条件之间的关系,从而推断大脑区域和网络的功能作用。从机器学习的角度来看,这里输入(input)的通常是来自神经科学实验的fMRI数据,输出(output)是有关类别的概率分

TF-IDF结合余弦相似性 判断文章相似性
摘自:阮一峰的网络日志(http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html) 为了找出相似的文章,需要用到"余弦相似性"(cosine similiarity)。下面,我举一个例子来说明,什么是"余弦相似性"。 为了简单起见,我们先从句子着手。 句子A:我喜欢看电视,不喜欢看电影。 句子B:我不喜欢看

文本去重第一步:基于内容的文本相似性计算
为何要计算文档相似性 在今年年初的时候,我开始尝试做文本的自动聚类,当时是从网上,找到的一个K-Means算法,稍作了修改。从测试结果来看,分类效果不太好,究其原因,我认为有两个,一个是词库的问题,停用词词库太小,没有噪音词库,也没有近义词词库,最关键的是切出来的词,统计的TFIDF权重不准确,第二个原因则是计算某文档与目标类别的相似度的算法不够合理。第一个问题
两篇文章相似度:TF-IDF与余弦相似性的应用
TF-IDF与余弦相似性的应用(一):自动提取关键词 作者: 阮一峰 日期: 2013年3月15日 这个标题看上去好像很复杂,其实我要谈的是一个很简单的问题。 有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到? 这个问题涉及到数据挖掘、文本处理、信

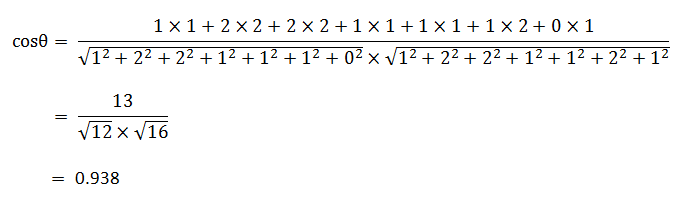
TF-IDF与余弦相似性的应用(二):找出相似文章(转)
作者: 阮一峰 日期: 2013年3月21日 上一次,我用TF-IDF算法自动提取关键词。 今天,我们再来研究另一个相关的问题。有些时候,除了找到关键词,我们还希望找到与原文章相似的其他文章。比如,"Google新闻"在主新闻下方,还提供多条相似的新闻。 为了找出相似的文章,需要用到"余弦相似性"(cosine similiarity)。下面,我举一个例子来说明,什么是"余弦相似性"。
字符串相似性匹配实际问题(一)
背景:很多人都是直接说dp编辑距离,我只想说,凡事都是说起来容易,做起来难。 问题:现有一个Python函数similarity_function,用于计算字符串之间的相似性,可以直接使用该函数完成下面的算法: 给定一个字符串列表List,其中的元素都是字符串string,给定一个substring,求List中哪些string或相邻string的拼接与substring的相似性最大。 解决思

SSIM(Structural Similarity),结构相似性及MATLAB实现
参考文献 Wang, Zhou; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. (2004-04-01). “Image quality assessment: from error visibility to structural similarity”. IEEE Transactions on Image Processing. 13 (4): 6
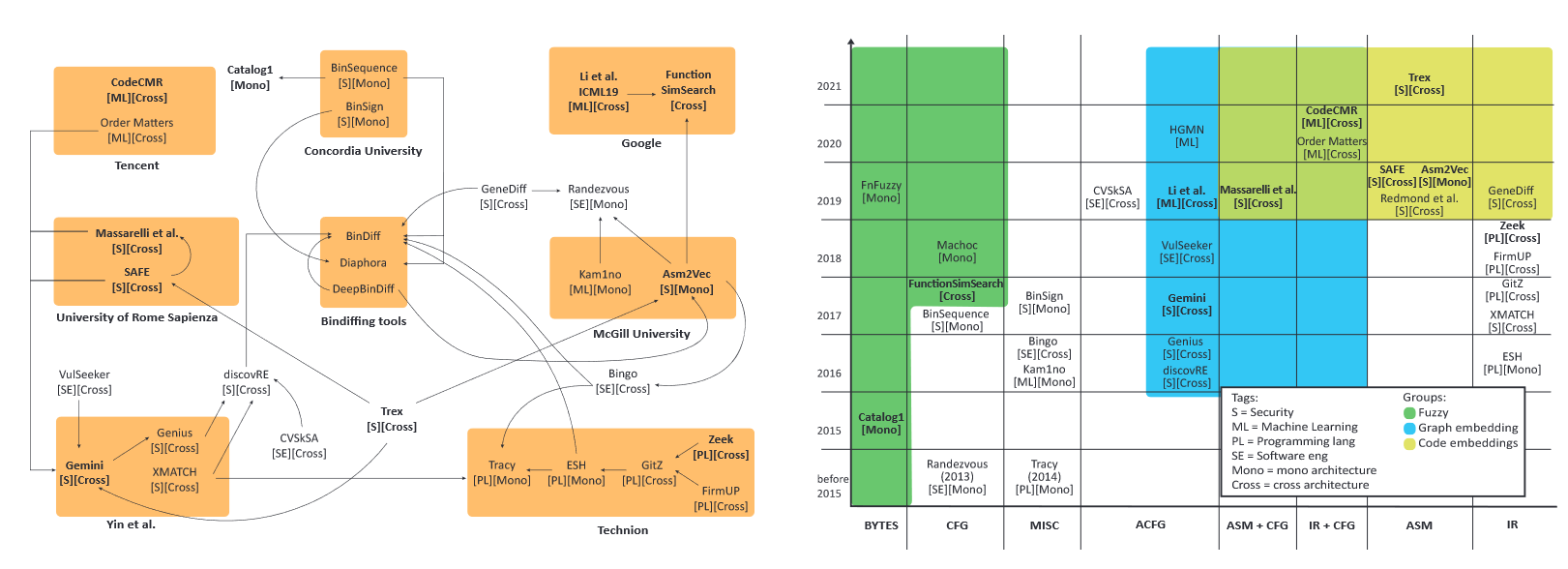
【论文阅读笔记】关于“二进制函数相似性检测”的调研(Security 22)
个人博客链接 注:部分内容参考自GPT生成的内容 [Security 22] 关于”二进制函数相似性检测“的调研(个人阅读笔记) 论文:《How Machine Learning Is Solving the Binary Function Similarity Problem》(Usenix Security 2022) 仓库:https://github.com/Cisco-

政安晨:【Keras机器学习示例演绎】(二十六)—— 图像相似性搜索的度量学习
目录 概述 设置 数据集 嵌入模型 测试 政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras机器学习实战 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 本文目标:在 CIFAR-10 图像上使用相似度量学习的示例。 概述 度量学习旨在训练能将输入嵌入高维空间的模型,从而使训练方案所定义的 "

Faiss使用指南:5步掌握高效相似性搜索【AI写作助手】
首先,这篇文章是基于笔尖AI写作进行文章创作的,喜欢的宝子,也可以去体验下,解放双手,上班直接摸鱼~ 按照惯例,先介绍下这款笔尖AI写作,宝子也可以直接下滑跳过看正文~ 笔尖Ai写作:只要输入简单的要求和描述,就能自动生成各种高质量文稿内容。笔尖Ai写作:内置1000+写作模板,小白也能快速上手。 Ai论文、Ai开题报告、Ai公文写作、Ai商业计划书、文献综述、Ai生成、Ai文献推荐、Ai论
基于视觉的网页结构相似性计算
由于工作学习的安排,一直参与项目课题的工作,期间在计算两个页面之间相似度的时候,寻求到了一个新的思路,于是努力实现了一下,这里简单说一下自己在接到这个问题的时候的思路吧:网页的相似度,分类,聚类之类的工作很多大牛都做了很多的研究,基于文本、内容、图像各个方面的都有,效果也还是可以的,这次出发点是网页的视觉信息但是在真的动手去做的时候却发现视觉信息包含的计算量太过于庞大了,而且需要很多的

python 学习笔记(相似性计算方法)
实在不能理解为啥搜狗输入法每次我打biji的时候总是给我跳出荸荠(qi) (づ ̄ 3 ̄)づ,还有biaoshi,总是出标识(zhi)..╭(╯^╰)╮哼 基于距离的相似度计算 prefs[person][item] 数据集格式如下: example: aaaa={‘WANG’:{‘Lady in the Water’:3,’HAHA story’:2},…} from math i

集成 LlamaIndex 和 Qdrant 相似性搜索以进行患者记录检索
介绍 由于医疗技术、数字健康记录(EHR)和可穿戴健康设备的进步,医疗领域目前正在经历数据的显着激增。有效管理和分析这些复杂多样的数据的能力对于提供定制医疗保健、推进医学研究和改善患者健康结果至关重要。矢量数据库是专门为高效处理和存储多维数据而定制的,作为一系列医疗保健用途的有效工具而得到认可。 例如,目前,医疗专业人员很少实时利用过去的患者记录数据,尽管它们是信息宝库并且可以帮
如何衡量两个分布的相似性(更新中)
文章目录 0. 简介1. 数学定义 https://blog.csdn.net/fengdu78/article/details/114325589 https://www.cnblogs.com/arkenstone/p/5496761.html https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test#

5.5.5、【AI技术新纪元:Spring AI解码】使用PGvector设置向量存储及进行相似性搜索
使用PGvector设置向量存储及进行相似性搜索 本节指导您如何设置PGvector VectorStore来存储文档嵌入并执行相似性搜索。 PGvector是一个开源的PostgreSQL扩展,能够支持存储和搜索机器学习生成的嵌入向量,提供查找精确和近似最近邻的功能。它设计得与PostgreSQL的其他特性无缝配合,包括索引和查询。 前提条件 首先,您需要访问一个已开启vector、hs
计算两张图片的结构相似性指数SSIM
结构相似性指数(SSIM) 主要考虑了人眼的感知特性,比较两幅图像的亮度、对比度和结构等特征。SSIM 取值范围在 [-1, 1] 之间,越接近 1 表示两幅图像越相似。比较一个文件中哪些图像存在相似的代码示例: 安装skimage: pip install scikit-image -i https://mirrors.aliyun.com/pypi/simple/ 完整如下: im
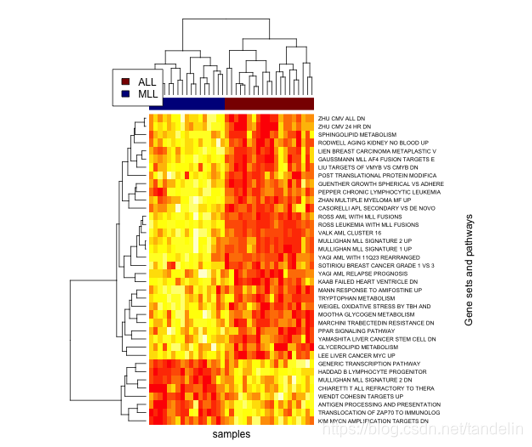
GSVA计算基因样本的相似性
下载包 # source('http://bioconductor.org/biocLite.R')# options(BioC_mirror='http://mirrors.ustc.edu.cn/bioc/')# biocLite('estimate')# library(GSVA)# browseVignettes('GSVA')# browseVignettes('estima
使用huggingface实现ALGN进行图像-文本相似性匹配
目录 引言 使用范例 AlignConfig 参数详解 AlignTextConfig 参数详解 示例 AlignVisionConfig 参数详解 示例 AlignProcessor 参数 主要方法 AlignModel 参数 方法 示例 AlignTextModel 参数 前向传播方法 forward 返回值 示例代码 AlignVisionMo