皮尔逊专题

数学建模--皮尔逊相关系数、斯皮尔曼相关系数
目录 1.总体的皮尔逊相关系数 2.样本的皮尔逊相关系数 3.对于皮尔逊相关系数的认识 4.描述性统计以及corr函数 编辑 5.数据导入实际操作 6.引入假设性检验 6.1简单认识 6.2具体步骤 7.p值判断法 8.检验正态分布 8.1jb检验 8.2威尔克检验:针对于p值进行检验 9.两个求解方法的总结 1.总体的皮尔逊相关系数 我们首先要知道这个
【JAVA实现】基于皮尔逊相关系数的相似度
以下解释摘自于网上, 简单易懂特地摘抄过来 原链接 皮尔逊相关系数理解有两个角度 1. 按照高中数学水平来理解, 它很简单, 可以看做将两组数据首先做Z分数处理之后, 然后两组数据的乘积和除以样本数Z分数一般代表正态分布中, 数据偏离中心点的距离.等于变量减掉平均数再除以标准差.(就是高考的标准分类似的处理)标准差则等于变量减掉平均数的平方和,再除以样本数,最后再开方. 所以, 根据这

相似度的算法(欧几里德距离和皮尔逊算法)
给了我两个东西,每个东西上有不同的特征,那咱们就算算这两个东西的相似的系数吧 先说欧几里德距离,按几何意义来讲就是按n个特征给它建立起来n维坐标系,就先说二维吧,二维上就是两个点咯,xy轴,这两个点相似否,就看他的距离咯,于是 就求一下两个点的距离,三个特征呢?那就是三维坐标系。由此推广,可以推广到n维。 公式:|x| = √( x[1]2 + x[2]2 + … + x[n]2 ) 欧式
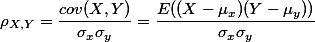
数据分析进阶 - 相关分析(皮尔逊相关系数)
相关分析 相关分析是研究两个或两个以上处于同等地位的随机变量间的相关关系的统计分析方法。通过对不同特征或数据间的关系进行分析,发现其中关键影响及驱动因素。在实际的工作应用中,常常用于特征的发现与选择。针对不同数据类型的变量,需要选用不同的检验方法,具体如下表所示 变量个数变量类型检验方法两个均为连续变量皮尔逊相关系数、简单线性回归两个均为有序分类变量Mantel-Haenszel 趋势检验、
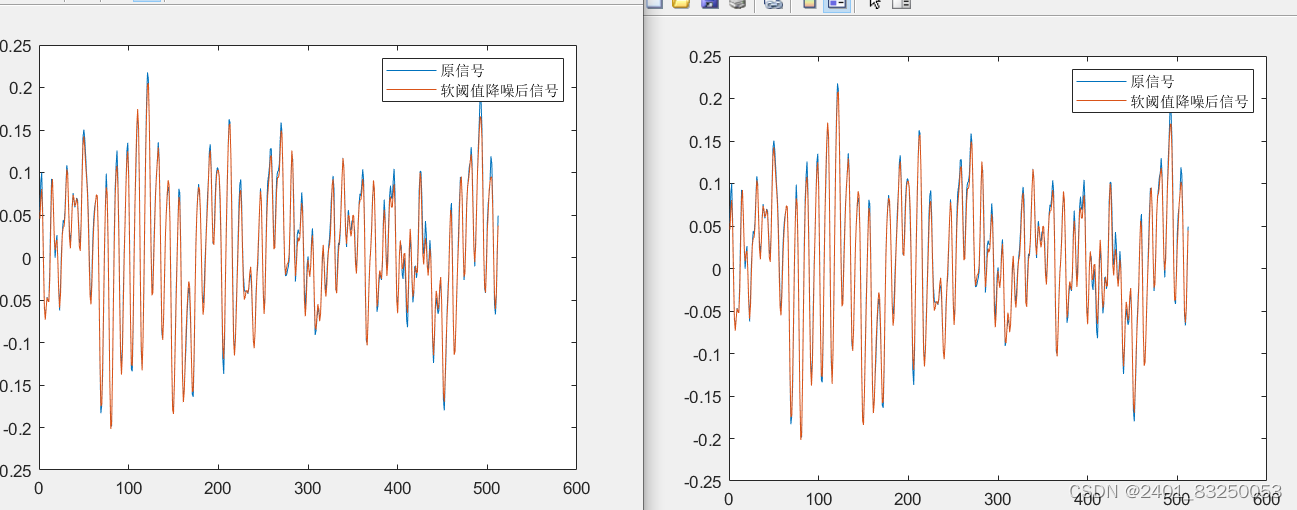
NGO-VMD+皮尔逊系数+小波阈值降噪+重构
NGO-VMD+皮尔逊系数+小波阈值降噪+重构 NGO-VMD+皮尔逊系数+小波阈值降噪+重构代码获取戳此处代码获取戳此处 以西储大学轴承数据为例,进行VMD,且采用NGO进行K a参数寻优 并对分解分量计算皮尔逊相关系数筛选含噪声分量,对其进行小波软硬阈值降噪, 并最后进行重构 NGO-VMD(北方苍鹰优化算法优化变分模态分解): 北方苍鹰优化算法(NGO)是一种模拟鹰
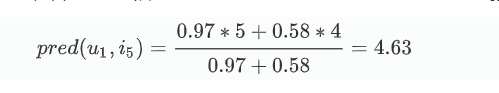
协同过滤算法之连续评分通过皮尔逊相关系数计算相似度原理及代码实现
文章目录 相关算法介绍余弦相似度皮尔逊(Pearson)相关系数 使用协同过滤推荐算法对用户进行评分预测协同过滤推荐算法数据集关于用户-物品评分矩阵代码及实现如何计算评分预测?总结 相关算法介绍 余弦相似度 度量的是两个向量之间的夹角, 用夹角的余弦值来度量相似的情况两个向量的夹角为0是,余弦值为1, 当夹角为90度是余弦值为0,为180度是余弦值为-1余弦相似度在度量文本

拿捏!相关性分析,一键出图!皮尔逊、斯皮尔曼、肯德尔、最大互信息系数(MIC)、滞后相关性分析,直接运行!独家可视化程序!
适用平台:Matlab2020及以上 相关性分析是一种统计方法,用于衡量两个或多个变量之间的关系程度。通过相关性分析,我们可以了解变量之间的相互关系、依赖性,以及它们是如何随着彼此的变化而变化的。相关性分析通常包括计算相关系数或其他衡量关联度的指标。 ①量化特征之间的关联程度:通过相关系数的值,我们可以判断它们的关系是强烈的、中等还是弱。 ②特征降维:在大规模数据集中,相关性分析可以帮助我们
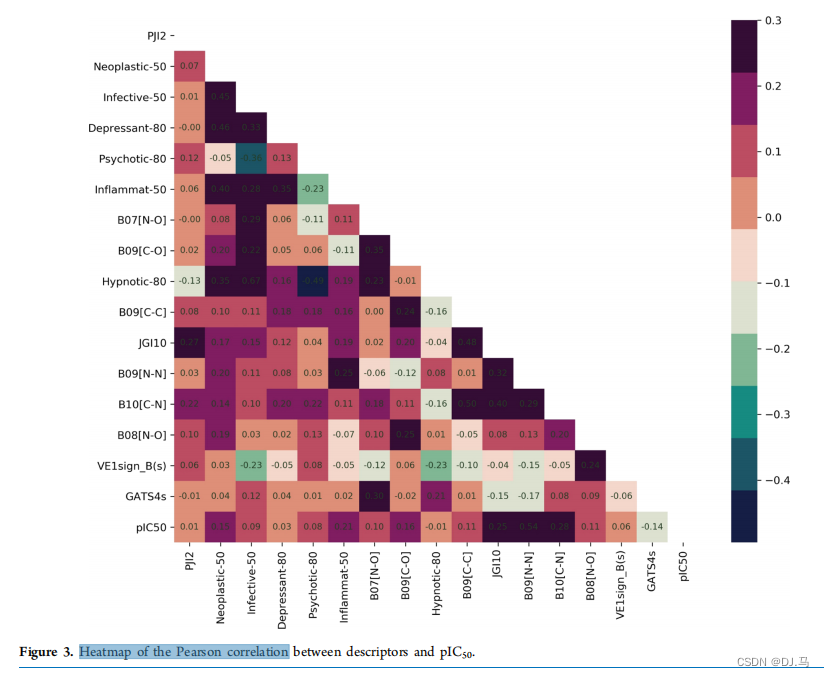
热图分析(这个热力图代表的是不同描述符与pIC50之间的皮尔逊相关系数。)
案例一: 这个热力图代表的是不同描述符与pIC50之间的皮尔逊相关系数。pIC50是一种表示化合物在生物学测定中抑制效果的负对数IC50值,它通常用于药物发现和评估中,用来量化化合物对特定靶标的抑制能力。 要分析这个热力图,你需要关注几个关键点: 相关系数的范围:这个图中,相关系数的范围是-0.4到+0.3。相关系数表示两个变量之间的线性关系的强度和方向。接近+1或-1的值表示

数学建模学习笔记-皮尔逊相关系数
内容:皮尔逊相关系数 一.概念:是一个和线性线关的相关性系数 1.协方差概念: 协方差受到量纲的影响因此需要剔除 2.相关性的误区 根据这个结论,我们在计算该系数之前需要确定是否为线性函数 二.相关性的计算 1.Matlab:只含相关性不含假设检验:下面第三大点讲解假设检验 2.使用Excel美化图表5.1讲中49分 三.对皮尔逊相关系数进行假设检

皮尔逊相关性分析的matlab实现,简介和实例
皮尔逊相关性分析(Pearson correlation analysis)是一种常用的统计方法,用于衡量两个变量之间的线性关系强度和方向。它通过计算两个变量之间的协方差和标准差来衡量它们之间的相关性。皮尔逊相关系数的取值范围为 -1 到 1,其中 -1 表示完全负相关,0 表示无相关性,1 表示完全正相关。 在 MATLAB 中,可以使用 corrcoef 函数来计算皮尔逊相关系数,并且可以使

PairGrid两两关系图皮尔逊相关系数
Pearson相关系数,帮助我们来筛选特征 用PairGrid 可以按我们的需求去自定义下需要展示的部分 plot_data = features[['score', 'A', 'B', 'C']]plot_data = plot_data.replace({np.inf: np.nan, -np.inf<

【JAVA实现】基于皮尔逊相关系数的相似度计算
最近在看《集体智慧编程》,相比其他机器学习的书籍,这本书有许多案例,更贴近实际,而且也很适合我们这种准备学习machine learning的小白。 这本书我觉得不足之处在于,里面没有对算法的公式作讲解,而是直接用代码去实现,所以给想具体了解该算法带来了不便,所以想写几篇文章来做具体的说明。以下是第一篇,对皮尔逊相关系数作讲解,并采用了自己比较熟悉的java语言做实现。

特征选择-皮尔逊相关系数-互信息
特征选择 1.相关性 通过使用相关性,我们很容易看到特征之间的线性关系。这种关系可以用一条直线拟合。 下面通过皮尔逊相关系数(Pearson correlation coefficient)来解释特征的相关性: 下面每幅图上方的相关系数Cor(X1, X2)是计算出来的皮尔逊r值,从图中可以看出不同程度的相关性。 scipy.stats.pearsonr(),给定两个数据序列 ,会返回相关系
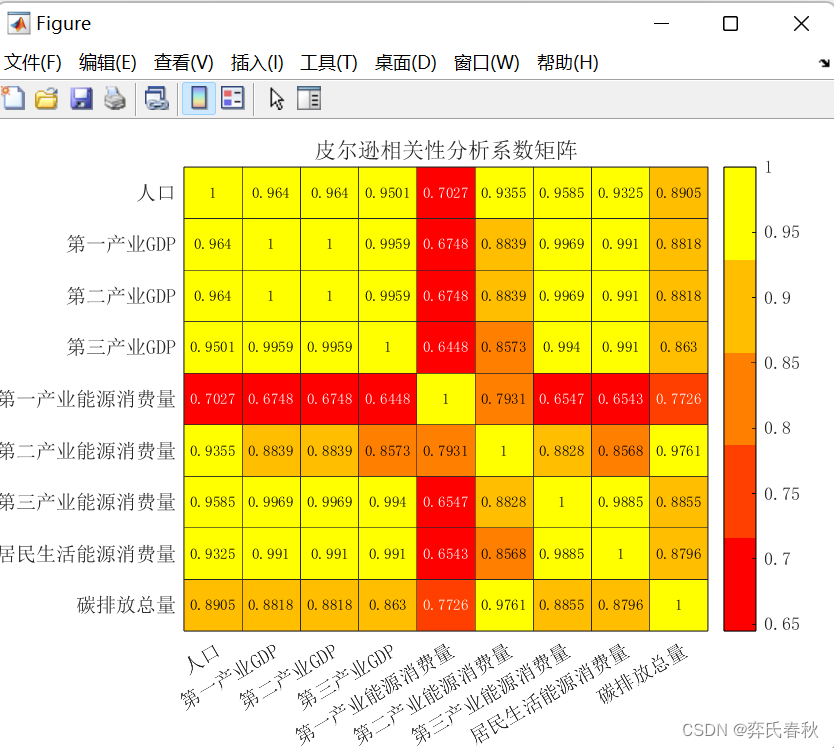
数学建模预测模型MATLAB代码大合集及皮尔逊相关性分析(无需调试、开源)
已知2010-2020数据,预测2021-2060数据 一、Logistic预测人口 %%logistic预测2021-2060年结果clear;clc;X=[7869.34, 8022.99, 8119.81, 8192.44, 8281.09, 8315.11, 8381.47, 8423.50, 8446.19, 8469.09, 8477.26];n=length(X)-1;f
数学建模预测模型MATLAB代码大合集及皮尔逊相关性分析(无需调试、开源)
已知2010-2020数据,预测2021-2060数据 一、Logistic预测人口 %%logistic预测2021-2060年结果clear;clc;X=[7869.34, 8022.99, 8119.81, 8192.44, 8281.09, 8315.11, 8381.47, 8423.50, 8446.19, 8469.09, 8477.26];n=length(X)-1;f
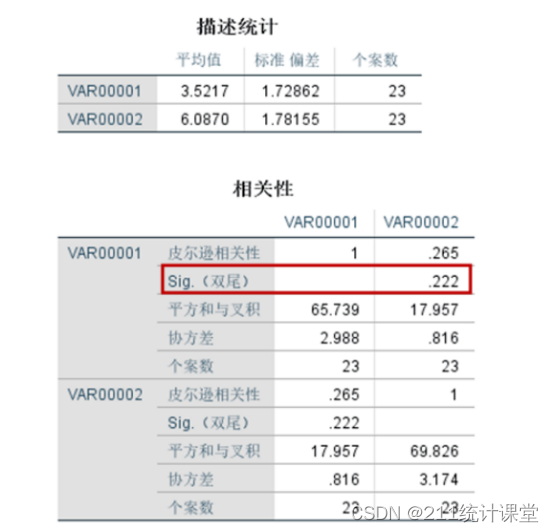
Pearson correlation皮尔逊相关性分析
在参数检验的相关性分析方法主要是皮尔逊相关(Pearson correlation)。既然是参数检验方法,肯定是有一些前提条件。皮尔逊相关的前提是必须满足以下几个条件: 变量是连续变量;比较的两个变量必须来源于同一个总体;没有异常值;两个变量都符合正态分布。 正态分布的呈现是倒“U”型曲线。在实际分析过程中,想要一份数据同时满足以上条件,确实是有一定难度的。毕竟我们是没法保证收上来的数