本文主要是介绍数学建模预测模型MATLAB代码大合集及皮尔逊相关性分析(无需调试、开源),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
已知2010-2020数据,预测2021-2060数据
一、Logistic预测人口
%%logistic预测2021-2060年结果
clear;clc;
X=[7869.34, 8022.99, 8119.81, 8192.44, 8281.09, 8315.11, 8381.47, 8423.50, 8446.19, 8469.09, 8477.26];
n=length(X)-1;
for t=1:nZ(t)=(X(t+1)-X(t))/X(t+1);
end
X1=[ones(n,1) X(1:n)'];
Y=Z';
[B,Bint,r,rint,stats]=regress(Y,X1);%最小二乘(OLS)
gamma=B(1,1);
beta=B(2,1);
b=log(1-gamma);
c=beta/(exp(b)-1);
a=exp((sum(log(1./X(1:n)-c))-n*(n+1)*b/2)/n);
XX=2010:2060;
YY=1./(c+a*exp(b*([XX-2010])));
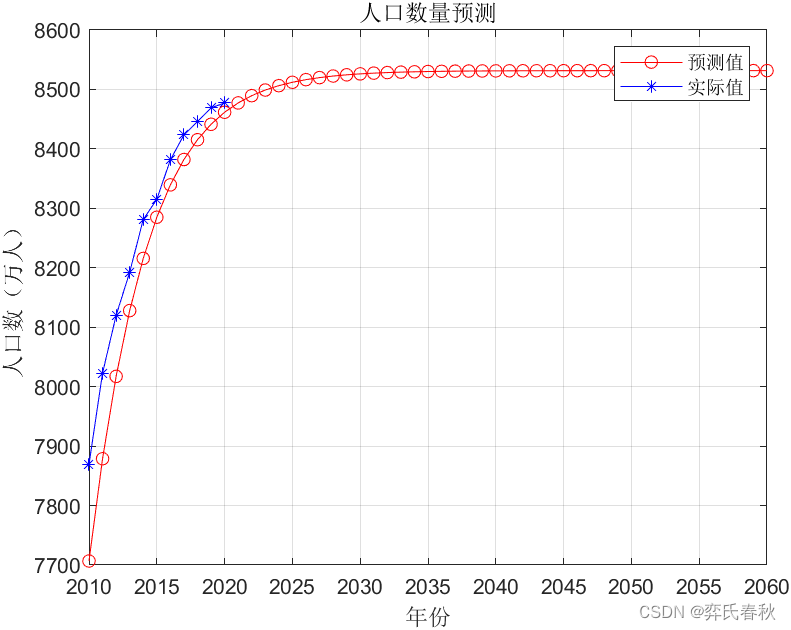
plot(XX,YY,'r-o')
hold on
plot(XX(1:length(X)),X,'b-*')
legend('预测值','实际值')
xlabel('年份');ylabel('人口数(万人)');
title('人口数量预测')
set(gca,'XTick',[2010:5:2060])
grid on
format short;
forecast=YY(end-40:end);%2021-2060人口的预测结果
MAPE=sum(abs(YY(1:n+1)-X)./X)/length(X);%平均相对差值
a,b,c
二、灰色预测GDP
%%灰色预测模型预测某区2021-2060年GDP量变化
clc;clear;
%建立符号变量a(发展系数)和b(灰作用量)
syms a b;
c = [a b]';
%原始数列(这里我们输入历史碳排放数据)
A = [41383.87,45952.65,50660.20,55580.11,60359.43,65552.00,70665.71,75752.20,80827.71,85556.13,88683.21];
%级比检验
n = length(A);
min=exp(-2/(n+1));
max=exp(2/(n+1));
for i=2:n
ans(i)=A(i-1)/A(i);
end
ans(1)=[];
for i=1:(n-1)
if ans(i)<max&ans(i)>min
else
fprintf('第%d个级比不在标准区间内',i)
disp(' ');
end
end
%对原始数列 A 做累加得到数列 B
B = cumsum(A);
%对数列 B 做紧邻均值生成
for i = 2:n
C(i) = (B(i) + B(i - 1))/2;
end
C(1) = [];
%构造数据矩阵
B = [-C;ones(1,n-1)];
Y = A; Y(1) = []; Y = Y';
%使用最小二乘法计算参数 a(发展系数)和b(灰作用量)
c = inv(B*B')*B*Y;
c = c';
a = c(1);
b = c(2);
%预测后续数据
F = []; F(1) = A(1);
for i = 2:(n+40)
F(i) = (A(1)-b/a)/exp(a*(i-1))+ b/a;
end
%对数列 F 累减还原,得到预测出的数据
G = []; G(1) = A(1);
for i = 2:(n+40)
G(i) = F(i) - F(i-1); %得到预测出来的数据
end
disp('预测数据为:');
G
%模型检验
H = G(1:n);
%计算残差序列
epsilon = A - H;
%法一:相对残差Q检验
%计算相对误差序列
delta = abs(epsilon./A);
%计算相对误差平均值Q
disp('相对残差Q检验:')
Q = mean(delta)
%法二:方差比C检验disp('方差比C检验:')
C = std(epsilon, 1)/std(A, 1)
%法三:小误差概率P检验
S1 = std(A, 1);
tmp = find(abs(epsilon - mean(epsilon))< 0.6745 * S1);
disp('小误差概率P检验:')
P = length(tmp)/n
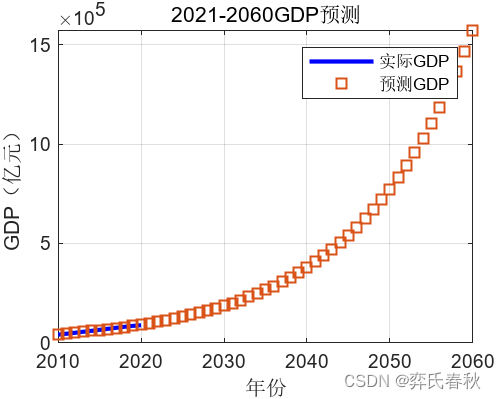
%绘制曲线图
t1 = 2010:2020;
t2 = 2010:2060;
plot(t1, A,'-b','LineWidth',2);
hold on;
plot(t2, G, 's','LineWidth',1);
xlabel('年份'); ylabel('GDP(亿元)');
legend('实际GDP','预测GDP');
title('2021-2060GDP预测');
grid on;
三、BP神经网络预测
选取2000-2017年x省碳排放量为训练集,2018-2022x省碳排放量作为测试集,以此来预测2023-2026年x省碳排放量。设置训练次数为 1000次,学习速率为0.2;对该训练集BP神经网络模型拟合后模型的训练样本、验 证样本和测试样本的均方误差分别是0.000012、0.0023、0.0042,整体的误差为 0.0082203,因此训练好的BP神经网络模型的预测精度较高。训练好的BP神经网络 神经模型的结果如图3所示
clear allclcclf%% 1,读取数据,并做归一化处理
input_1=[2391,2487,2588,2683,3150,3513,3751,3969,4384,4653,4482,5366,6238,6515,6647,6704,6806,6682,6346,6253,6513,7120,7597];n=length(input_1);row=4; %通过前四年数据,预测第五年
input=zeros(4,n-row);for i =1:rowinput(i,:)=input_1(i:n-row+i-1);endoutput=input_1(row+1:end);[inputn,inputps]=mapminmax(input);[outputn,outputps]=mapminmax(output);%% 2,划分训练集和测试集
inputn_train=inputn(:,1:n-row-5);inputn_test=inputn(:,n-row-4:end);outputn_train=outputn(1:n-row-5);outputn_test=outputn(n-row-4:end);%% 3,构建BP神经网络
hiddennum=10;%隐含层节点数量经验公式p=sqrt(m+n)+anet=newff(inputn_train,outputn_train,hiddennum,{'tansig','purelin'},'trainlm'); %tansig :正切 S 型传递函数。purelin:线性传递函数。trainlm:Levenberg-Marquardt 算法
%% 4,网络参数配置
net.trainParam.epochs=1000;net.trainParam.lr=0.2;%% 5,BP神经网络训练
[net,tr]=train(net,inputn_train,outputn_train);%% 6,仿真计算
resultn=sim(net,inputn_test);%% 7,计算与测试集之间误差
result=mapminmax('reverse',resultn,outputps);output_test=mapminmax('reverse',outputn_test,outputps);error=result-output_test;rmse=sqrt(error*error')/length(error);figure(1)plot(output_test,'b')hold onplot(result,'r*');hold on
plot(error,'s','MarkerFaceColor','k')legend('期望值','预测值','误差')xlabel('数据组数')ylabel('值')%% 8,预测未来四年碳排放
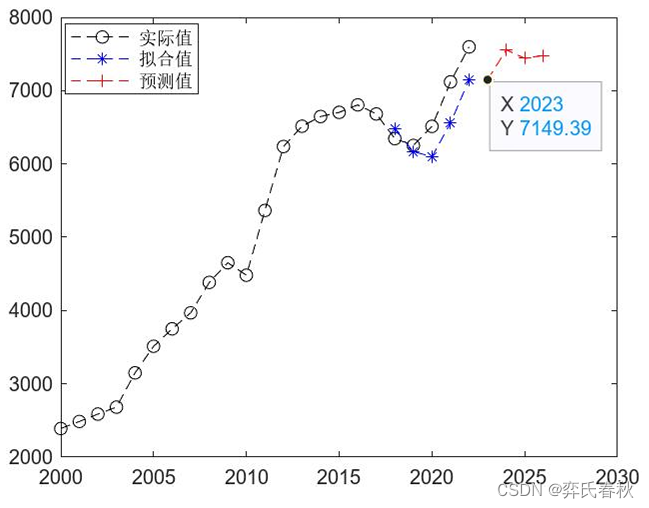
pn=3;[p_in,ps]=mapminmax(input_1(n-row+1:end));p_in=p_in';p_outn=zeros(1,pn);for i = 1:pnp_outn(i)=sim(net,p_in);p_in=[p_in(2:end);p_outn(i)];endp_out=mapminmax('reverse',p_outn,ps)figure(2)plot(2000:2022,input_1,'k--o')hold onplot(2018:2022,result,'b--*')hold onplot(2023:2026,[result(end),p_out],'r--+')legend('实际值','拟合值','预测值')
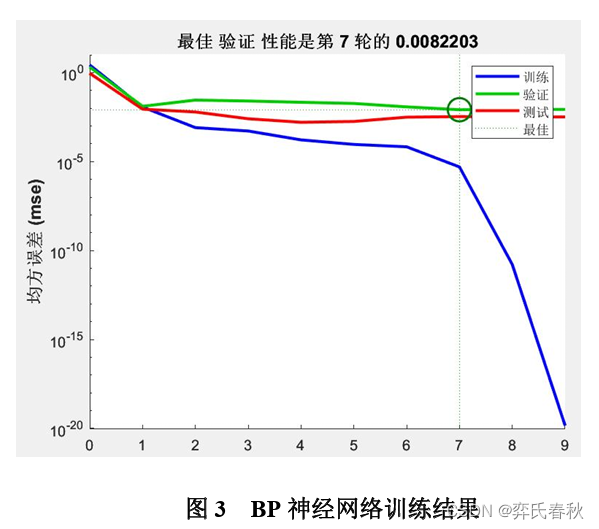
从图3看出,验证样本和测试样本的均方误差收敛到近 时达到最小,这时训练出的BP神经网络模型是最优的。利用BP神经网络模型预测2023-2026 年x省碳排放量分别 是7149.39 万吨、7556.6 万吨、7441.1 万吨、7479.1 万吨。x省碳排放量实际值、拟合值、预测值的变化趋势见下图。
2018-2022 年实际建筑碳排放量和预测得到的全过程碳排放量的误差图,如下图所示:
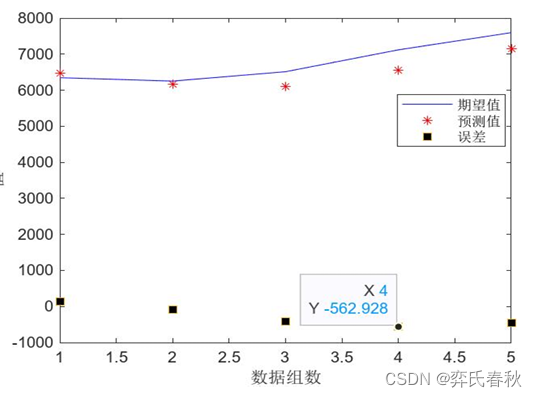
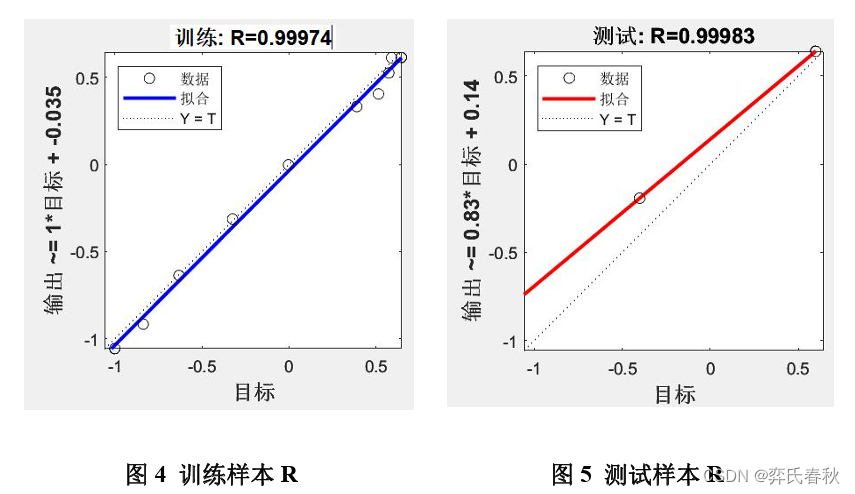
训练完成BP神经网络模型后可以得到训练集、验证集、测试集以及整体结果 的数据相关性。训练样本、验证样本、测试样本的预测输出和目标输出的相关系 数分别为0.99974、0.9935、0.99983,整体的相关系数为0.99238,如图4,5,6,7 所示。BP神经网络拟合结果较好。

四、皮尔逊相关性分析代码
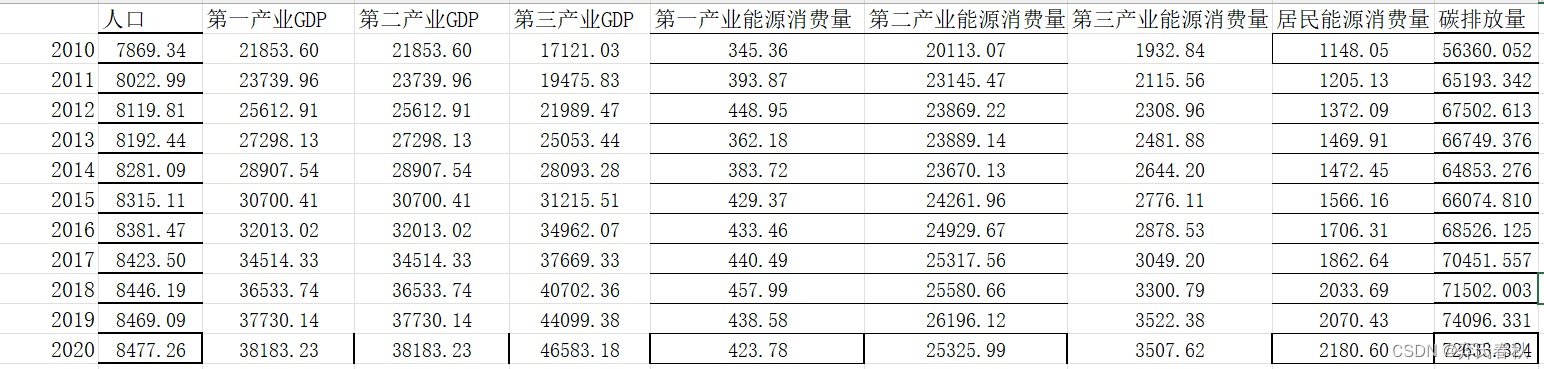
将该xiu.xlsx放到一新建文件夹中,然后在MATLAB中导入该表格(点击绿色箭头文件夹)
%%皮尔逊相关性分析矩阵代码
clc
clear all
data=xlsread('xiu.xlsx',1,'B2:J12');
figure
% 求维度之间的相关系数
rho = corr(data, 'type','pearson');
% 绘制热图
string_name={'人口','第一产业GDP','第二产业GDP','第三产业GDP','第一产业能源消费量','第二产业能源消费量','第三产业能源消费量','居民生活能源消费量','碳排放总量'};
xvalues = string_name;
yvalues = string_name;
h = heatmap(xvalues,yvalues, rho, 'FontSize',10, 'FontName','宋体');
h.Title = '皮尔逊相关性分析系数矩阵';
colormap summerfigure
% 可以自己定义颜色块
H = heatmap(xvalues,yvalues, rho, 'FontSize',10, 'FontName','宋体');
H.Title = '皮尔逊相关性分析系数矩阵';
colormap(autumn(5))%设置颜色个数
colormap函数用于设置当前图形的颜色映射。常见颜色映射有:summer\autumn\winter\spring\cool\hot\hsv\jet
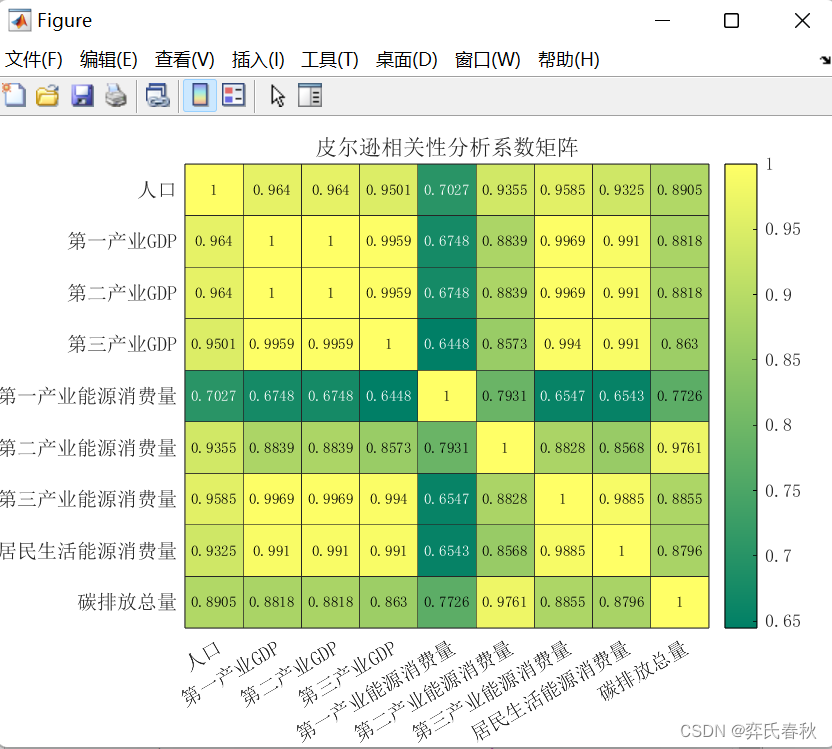
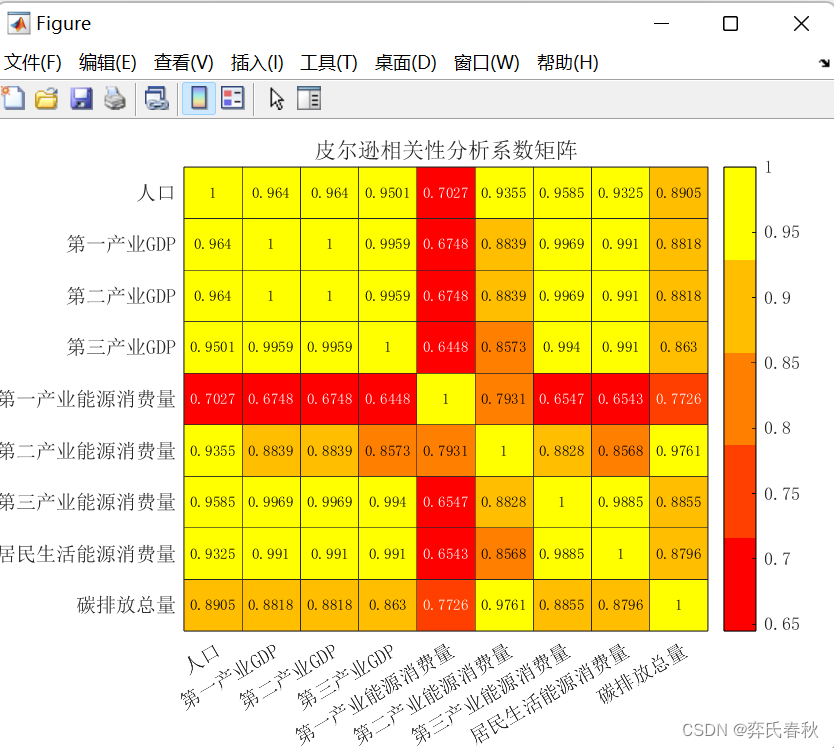
这篇关于数学建模预测模型MATLAB代码大合集及皮尔逊相关性分析(无需调试、开源)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





